ホーム » 「MONAI 1.0」タグがついた投稿 (ページ 2)
タグアーカイブ: MONAI 1.0
MONAI 1.0 : MedNIST デモ (画像分類チュートリアル)
MONAI 1.0 : MedNIST デモ (画像分類チュートリアル) (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 10/30/2022 (1.0.1)
* 本ページは、MONAI の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。

- 人工知能研究開発支援
- 人工知能研修サービス(経営者層向けオンサイト研修)
- テクニカルコンサルティングサービス
- 実証実験(プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
- PoC(概念実証)を失敗させないための支援
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
- 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション
- sales-info@classcat.com ; Web: www.classcat.com ; ClassCatJP
MONAI 1.0 : MedNIST デモ (画像分類チュートリアル)
イントロダクション
このチュートリアルでは、MedNIST データセットに基づいて end-to-end な訓練と評価サンプルを紹介します。以下のステップを通り抜けます :
- 訓練とテストのための MONAI データセットを作成します。
- データの前処理のために MONAI 変換を使用します。
- 分類タスクのために MONAI から DenseNet を使用します。
- PyTorch プログラムでモデルを訓練します。
- テストデータセットで評価します。
データセットの取得
MedNIST データセットは TCIA, RSNA Bone Age チャレンジ と NIH Chest X-ray データセット の様々なセットから集められました。
データセットは Dr. Bradley J. Erickson M.D., Ph.D. (Department of Radiology, Mayo Clinic) のお陰により Creative Commons CC BY-SA 4.0 ライセンス のもとで利用可能になっています。MedNIST データセットを使用する場合、出典を明示してください、e.g. https://github.com/Project-MONAI/tutorials/blob/master/2d_classification/mednist_tutorial.ipynb。
以下のコマンドはデータセット (~ 60MB) をダウンロードして unzip します。
!wget -q https://www.dropbox.com/s/5wwskxctvcxiuea/MedNIST.tar.gz
# unzip the '.tar.gz' file to the current directory
import tarfile
datafile = tarfile.open("MedNIST.tar.gz")
datafile.extractall()
datafile.close()
MONAI をインストールします :
!pip install -q "monai-weekly[gdown, nibabel, tqdm, itk]"
import os
import shutil
import tempfile
import matplotlib.pyplot as plt
from PIL import Image
import torch
import numpy as np
from sklearn.metrics import classification_report
from monai.apps import download_and_extract
from monai.config import print_config
from monai.metrics import ROCAUCMetric
from monai.networks.nets import DenseNet121
from monai.transforms import (
Activations,
EnsureChannelFirst,
AsDiscrete,
Compose,
LoadImage,
RandFlip,
RandRotate,
RandZoom,
ScaleIntensity,
ToTensor,
)
from monai.data import Dataset, DataLoader
from monai.utils import set_determinism
print_config()
MONAI version: 1.1.dev2238
Numpy version: 1.21.6
Pytorch version: 1.12.1+cu113
MONAI flags: HAS_EXT = False, USE_COMPILED = False, USE_META_DICT = False
MONAI rev id: 8d72c2b845c8e91aad9a7cf17f2049bdec215f9d
MONAI __file__: /usr/local/lib/python3.7/dist-packages/monai/__init__.py
Optional dependencies:
Pytorch Ignite version: NOT INSTALLED or UNKNOWN VERSION.
Nibabel version: 3.0.2
scikit-image version: 0.18.3
Pillow version: 7.1.2
Tensorboard version: 2.8.0
gdown version: 4.4.0
TorchVision version: 0.13.1+cu113
tqdm version: 4.64.1
lmdb version: 0.99
psutil version: 5.4.8
pandas version: 1.3.5
einops version: NOT INSTALLED or UNKNOWN VERSION.
transformers version: NOT INSTALLED or UNKNOWN VERSION.
mlflow version: NOT INSTALLED or UNKNOWN VERSION.
pynrrd version: NOT INSTALLED or UNKNOWN VERSION.
For details about installing the optional dependencies, please visit:
https://docs.monai.io/en/latest/installation.html#installing-the-recommended-dependencies
データセットフォルダから画像ファイル名を読む
最初に、データセットファイルを確認して幾つかの統計情報を示します。データセットには 6 つのフォルダがあります : Hand, AbdomenCT, CXR, ChestCT, BreastMRI, HeadCT, これらは分類モデルを訓練するラベルとして使用されるべきです。
data_dir = './MedNIST/'
class_names = sorted([x for x in os.listdir(data_dir) if os.path.isdir(os.path.join(data_dir, x))])
num_class = len(class_names)
image_files = [[os.path.join(data_dir, class_name, x)
for x in os.listdir(os.path.join(data_dir, class_name))]
for class_name in class_names]
image_file_list = []
image_label_list = []
for i, class_name in enumerate(class_names):
image_file_list.extend(image_files[i])
image_label_list.extend([i] * len(image_files[i]))
num_total = len(image_label_list)
image_width, image_height = Image.open(image_file_list[0]).size
print('Total image count:', num_total)
print("Image dimensions:", image_width, "x", image_height)
print("Label names:", class_names)
print("Label counts:", [len(image_files[i]) for i in range(num_class)])
Total image count: 58954 Image dimensions: 64 x 64 Label names: ['AbdomenCT', 'BreastMRI', 'CXR', 'ChestCT', 'Hand', 'HeadCT'] Label counts: [10000, 8954, 10000, 10000, 10000, 10000]
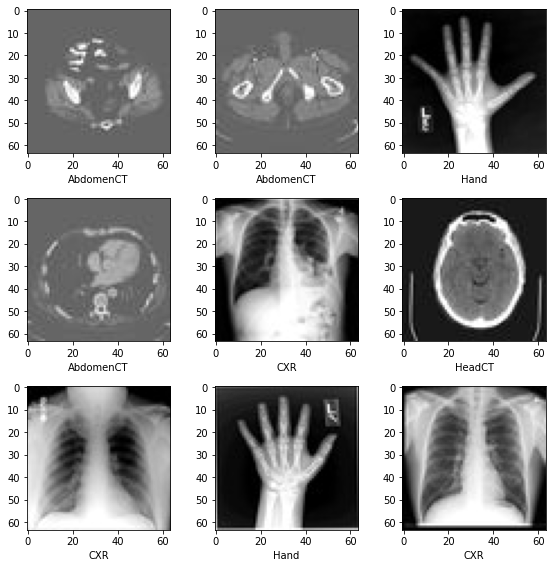
データセットからランダムに選択された幾つかのサンプルを可視化する
plt.subplots(3, 3, figsize=(8, 8))
for i,k in enumerate(np.random.randint(num_total, size=9)):
im = Image.open(image_file_list[k])
arr = np.array(im)
plt.subplot(3, 3, i + 1)
plt.xlabel(class_names[image_label_list[k]])
plt.imshow(arr, cmap='gray', vmin=0, vmax=255)
plt.tight_layout()
plt.show()
訓練、検証とテストデータ・リストの準備
データセットの 10% を検証用に、10% をテスト用にランダムに選択します。
valid_frac, test_frac = 0.1, 0.1
trainX, trainY = [], []
valX, valY = [], []
testX, testY = [], []
for i in range(num_total):
rann = np.random.random()
if rann < valid_frac:
valX.append(image_file_list[i])
valY.append(image_label_list[i])
elif rann < test_frac + valid_frac:
testX.append(image_file_list[i])
testY.append(image_label_list[i])
else:
trainX.append(image_file_list[i])
trainY.append(image_label_list[i])
print("Training count =",len(trainX),"Validation count =", len(valX), "Test count =",len(testX))
Training count = 47197 Validation count = 5900 Test count = 5857
データを前処理するために MONAI 変換, Dataset と Dataloader を定義する
train_transforms = Compose([
LoadImage(image_only=True),
EnsureChannelFirst(),
ScaleIntensity(),
RandRotate(range_x=15, prob=0.5, keep_size=True),
RandFlip(spatial_axis=0, prob=0.5),
RandZoom(min_zoom=0.9, max_zoom=1.1, prob=0.5, keep_size=True),
ToTensor()
])
val_transforms = Compose([
LoadImage(image_only=True),
EnsureChannelFirst(),
ScaleIntensity(),
ToTensor()
])
act = Activations(softmax=True)
to_onehot = AsDiscrete(to_onehot=num_class)
class MedNISTDataset(Dataset):
def __init__(self, image_files, labels, transforms):
self.image_files = image_files
self.labels = labels
self.transforms = transforms
def __len__(self):
return len(self.image_files)
def __getitem__(self, index):
return self.transforms(self.image_files[index]), self.labels[index]
train_ds = MedNISTDataset(trainX, trainY, train_transforms)
train_loader = DataLoader(train_ds, batch_size=300, shuffle=True, num_workers=2)
val_ds = MedNISTDataset(valX, valY, val_transforms)
val_loader = DataLoader(val_ds, batch_size=300, num_workers=2)
test_ds = MedNISTDataset(testX, testY, val_transforms)
test_loader = DataLoader(test_ds, batch_size=300, num_workers=2)
ネットワークと optimizer の定義
- バッチ毎にモデルをどの位更新するか学習率を設定します。
- 総エポック数を設定します、シャッフルとランダム変換を持ちますので、総てのエポックの訓練データは異なります。そしてこれは単なる get start チュートリアルですから、4 エポックだけ訓練しましょう。10 エポック訓練すれば、モデルはテストデータセットで 100% 精度を達成できます。
- MONAI から DenseNet を使用して GPU デバイスに移します、この DenseNet は 2D と 3D 分類タスクの両方をサポートできます。
- Adam optimizer を使用します。
device = torch.device("cuda:0")
model = DenseNet121(
spatial_dims=2,
in_channels=1,
out_channels=num_class
).to(device)
loss_function = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), 1e-5)
epoch_num = 4
val_interval = 1
モデル訓練
エポックループとステップループを実行する典型的な PyTorch 訓練を実行し、そしてエポック毎後に検証を行ないます。ベストな検証精度を得た場合にはモデル重みをファイルにセーブします。
best_metric = -1
best_metric_epoch = -1
epoch_loss_values = list()
auc_metric = ROCAUCMetric()
metric_values = list()
for epoch in range(epoch_num):
print('-' * 10)
print(f"epoch {epoch + 1}/{epoch_num}")
model.train()
epoch_loss = 0
step = 0
for batch_data in train_loader:
step += 1
inputs, labels = batch_data[0].to(device), batch_data[1].to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = loss_function(outputs, labels)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
print(f"{step}/{len(train_ds) // train_loader.batch_size}, train_loss: {loss.item():.4f}")
epoch_len = len(train_ds) // train_loader.batch_size
epoch_loss /= step
epoch_loss_values.append(epoch_loss)
print(f"epoch {epoch + 1} average loss: {epoch_loss:.4f}")
if (epoch + 1) % val_interval == 0:
model.eval()
with torch.no_grad():
y_pred = torch.tensor([], dtype=torch.float32, device=device)
y = torch.tensor([], dtype=torch.long, device=device)
for val_data in val_loader:
val_images, val_labels = val_data[0].to(device), val_data[1].to(device)
y_pred = torch.cat([y_pred, model(val_images)], dim=0)
y = torch.cat([y, val_labels], dim=0)
y_onehot = [to_onehot(i) for i in y]
y_pred_act = [act(i) for i in y_pred]
auc_metric(y_pred_act, y_onehot)
auc_result = auc_metric.aggregate()
auc_metric.reset()
del y_pred_act, y_onehot
metric_values.append(auc_result)
acc_value = torch.eq(y_pred.argmax(dim=1), y)
acc_metric = acc_value.sum().item() / len(acc_value)
if acc_metric > best_metric:
best_metric = acc_metric
best_metric_epoch = epoch + 1
torch.save(model.state_dict(), 'best_metric_model.pth')
print('saved new best metric model')
print(f"current epoch: {epoch + 1} current AUC: {auc_result:.4f}"
f" current accuracy: {acc_metric:.4f} best AUC: {best_metric:.4f}"
f" at epoch: {best_metric_epoch}")
print(f"train completed, best_metric: {best_metric:.4f} at epoch: {best_metric_epoch}")
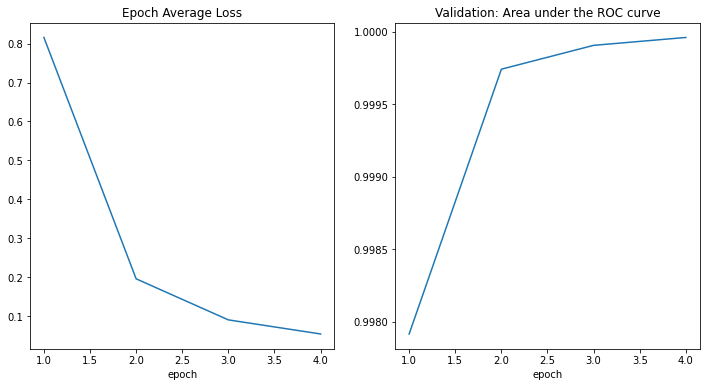
---------- epoch 1/4 (...) epoch 1 average loss: 0.8157 saved new best metric model current epoch: 1 current AUC: 0.9979 current accuracy: 0.9637 best AUC: 0.9637 at epoch: 1 ---------- epoch 2/4 (...) epoch 2 average loss: 0.1961 saved new best metric model current epoch: 2 current AUC: 0.9997 current accuracy: 0.9837 best AUC: 0.9837 at epoch: 2 ---------- epoch 3/4 (...) epoch 3 average loss: 0.0906 saved new best metric model current epoch: 3 current AUC: 0.9999 current accuracy: 0.9927 best AUC: 0.9927 at epoch: 3 ---------- epoch 4/4 (...) epoch 4 average loss: 0.0545 saved new best metric model current epoch: 4 current AUC: 1.0000 current accuracy: 0.9959 best AUC: 0.9959 at epoch: 4 train completed, best_metric: 0.9959 at epoch: 4
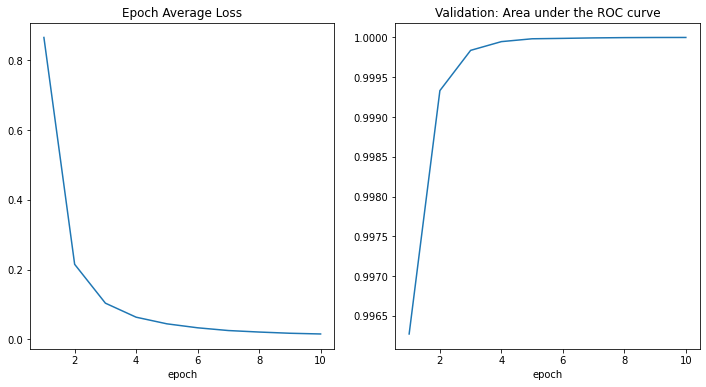
epoch 10 average loss: 0.0155 current epoch: 10 current AUC: 1.0000 current accuracy: 0.9986 best AUC: 0.9990 at epoch: 9 train completed, best_metric: 0.9990 at epoch: 9 CPU times: user 7min 38s, sys: 46.3 s, total: 8min 24s Wall time: 27min 14s
損失とメトリックのプロット
plt.figure('train', (12, 6))
plt.subplot(1, 2, 1)
plt.title("Epoch Average Loss")
x = [i + 1 for i in range(len(epoch_loss_values))]
y = epoch_loss_values
plt.xlabel('epoch')
plt.plot(x, y)
plt.subplot(1, 2, 2)
plt.title("Validation: Area under the ROC curve")
x = [val_interval * (i + 1) for i in range(len(metric_values))]
y = metric_values
plt.xlabel('epoch')
plt.plot(x, y)
plt.show()
テストデータセットでモデルを評価する
訓練と検証の後、検証テスト上のベストモデルを既に得ています。モデルが堅牢であることと過剰適合 (over-fitting) していないことを確認するためにテストデータセット上で評価する必要があります。分類レポートを生成するためにこれらの予測を使用します。
model.load_state_dict(torch.load('best_metric_model.pth'))
model.eval()
y_true = list()
y_pred = list()
with torch.no_grad():
for test_data in test_loader:
test_images, test_labels = test_data[0].to(device), test_data[1].to(device)
pred = model(test_images).argmax(dim=1)
for i in range(len(pred)):
y_true.append(test_labels[i].item())
y_pred.append(pred[i].item())
from sklearn.metrics import classification_report
print(classification_report(y_true, y_pred, target_names=class_names, digits=4))
precision recall f1-score support
AbdomenCT 0.9941 0.9912 0.9927 1025
BreastMRI 0.9955 0.9921 0.9938 884
CXR 0.9949 0.9959 0.9954 973
ChestCT 0.9922 1.0000 0.9961 1015
Hand 0.9969 0.9889 0.9929 989
HeadCT 0.9908 0.9959 0.9933 971
accuracy 0.9940 5857
macro avg 0.9941 0.9940 0.9940 5857
weighted avg 0.9940 0.9940 0.9940 5857
precision recall f1-score support
AbdomenCT 0.9990 0.9961 0.9976 1031
BreastMRI 0.9977 0.9988 0.9982 851
CXR 0.9990 0.9971 0.9980 1022
ChestCT 0.9971 1.0000 0.9986 1035
Hand 0.9969 0.9969 0.9969 983
HeadCT 0.9980 0.9990 0.9985 1001
accuracy 0.9980 5923
macro avg 0.9980 0.9980 0.9980 5923
weighted avg 0.9980 0.9980 0.9980 5923
以上
MONAI 1.0 : 概要 (README)
MONAI 1.0 : README (概要) (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 10/29/2022 (1.0.1)
* 本ページは、MONAI の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。
- 人工知能研究開発支援
- 人工知能研修サービス(経営者層向けオンサイト研修)
- テクニカルコンサルティングサービス
- 実証実験(プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
- PoC(概念実証)を失敗させないための支援
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
- 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション
- sales-info@classcat.com ; Web: www.classcat.com ; ClassCatJP
![]()
MONAI 1.0 : 概要 (README)
Medical Open Network for AI
MONAI は PyTorch エコシステム の一部で、ヘルスケア画像処理における深層学習のための PyTorch ベース、オープンソース のフレームワークです。その野心は :
- 共通基盤で協力して取り組める学術的、産業的そして臨床的な研究者のコミュニティを構築すること ;
- ヘルスケア画像処理のための最先端で、end-to-end な訓練ワークフローを作成すること ;
- 深層学習モデルを作成して評価するために最適化され標準化された方法を研究者に提供すること。
機能
マイルストーン・リリースの テクニカル・ハイライト と What’s New を参照してください。
- 多次元医用画像処理データのための柔軟な前処理 ;
- 既存のワークフロー内の簡単な統合のための構成的 & 可搬な API ;
- ネットワーク、損失、評価メトリクス等のためのドメイン固有な実装 ;
- 様々なユーザ専門性のためのカスタマイズ可能なデザイン ;
- マルチ GPU データ並列サポート。
インストール
現在のリリース をインストールするには、単純に以下を実行することができます :
pip install monai
他のインストール・オプションについては、インストールガイド を参照してください。
Getting Started
MedNIST デモ と MONAI for PyTorch Users が Colab で利用可能です。
サンプルとノートブック・チュートリアルは Project-MONAI/tutorials にあります。
技術文書は docs.monai.io で利用可能です。
モデル Zoo
MONAI モデル Zoo は研究者とデータサイエンティストがコミュニティからの最新の素晴らしいモデルを共有するための場所です。MONAI バンドル形式 の利用は MONAI でワークフローを構築し始める (Getting Started) ことを容易にします。
Contributing
MONAI への contribution (貢献) を行なうガイダンスについては、contributing ガイドライン を参照してください。
コミュニティ
Twitter @ProjectMONAI の会話に参加するか Slack チャネル に参加してください。
MONAI の GitHub Discussions タブ で質疑応答してください。
リンク
- Website : https://monai.io/
- API ドキュメント (マイルストーン) : https://docs.monai.io
- API ドキュメント (最新 dev) : https://docs.monai.io/en/latest/
- Code: https://github.com/Project-MONAI/MONAI
- Project tracker: https://github.com/Project-MONAI/MONAI/projects
- Issue tracker: https://github.com/Project-MONAI/MONAI/issues
- Wiki : https://github.com/Project-MONAI/MONAI/wiki
- Test status: https://github.com/Project-MONAI/MONAI/actions
- PyPI package: https://pypi.org/project/monai/
- conda-forge: https://anaconda.org/conda-forge/monai
- Weekly previews: https://pypi.org/project/monai-weekly/
- Docker Hub: https://hub.docker.com/r/projectmonai/monai
以上
ClassCat® Chatbot
人工知能開発支援
- テクニカルコンサルティングサービス
- 実証実験 (プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
クラスキャット
セールス・インフォメーション
E-Mail:sales-info@classcat.com