ホーム » sales-info の投稿 (ページ 2)
作者アーカイブ: sales-info
MONAI 1.0 : tutorials : 2D 分類 – MedNIST データセットによる医用画像分類
MONAI 1.0 : tutorials : 2D 分類 – MedNIST データセットによる医用画像分類 (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 11/01/2022 (1.0.1)
* 本ページは、MONAI の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。

- 人工知能研究開発支援
- 人工知能研修サービス(経営者層向けオンサイト研修)
- テクニカルコンサルティングサービス
- 実証実験(プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
- PoC(概念実証)を失敗させないための支援
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
- 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション
- sales-info@classcat.com ; Web: www.classcat.com ; ClassCatJP
MONAI 1.0 : tutorials : 2D 分類 – MedNIST データセットによる医用画像分類
このノートブックは MONAI 機能を既存の PyTorch プログラムに容易に統合する方法を示します。それは MedNIST データセットに基づいています、これは初心者のためにチュートリアルとして非常に適切です。このチュートリアルはまた MONAI 組込みのオクルージョン感度の機能も利用しています。
このチュートリアルでは、MedNIST データセットに基づく end-to-end な訓練と評価サンプルを紹介します。
以下のステップで進めます :
- 訓練とテスト用のデータセットを作成する。
- データを前処理するために MONAI 変換を利用します。
- 分類のために MONAI から DenseNet を利用します。
- モデルを PyTorch プログラムで訓練します。
- テストデータセット上で評価します。
環境のセットアップ
!python -c "import monai" || pip install -q "monai-weekly[pillow, tqdm]"
!python -c "import matplotlib" || pip install -q matplotlib
%matplotlib inline
インポートのセットアップ
# Copyright 2020 MONAI Consortium
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
# http://www.apache.org/licenses/LICENSE-2.0
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import os
import shutil
import tempfile
import matplotlib.pyplot as plt
import PIL
import torch
import numpy as np
from sklearn.metrics import classification_report
from monai.apps import download_and_extract
from monai.config import print_config
from monai.data import decollate_batch, DataLoader
from monai.metrics import ROCAUCMetric
from monai.networks.nets import DenseNet121
from monai.transforms import (
Activations,
EnsureChannelFirst,
AsDiscrete,
Compose,
LoadImage,
RandFlip,
RandRotate,
RandZoom,
ScaleIntensity,
)
from monai.utils import set_determinism
print_config()
MONAI version: 0.9.dev2152
Numpy version: 1.19.5
Pytorch version: 1.10.0+cu111
MONAI flags: HAS_EXT = False, USE_COMPILED = False
MONAI rev id: c5bd8aff8ba461d7b349eb92427d452481a7eb72
Optional dependencies:
Pytorch Ignite version: NOT INSTALLED or UNKNOWN VERSION.
Nibabel version: 3.0.2
scikit-image version: 0.18.3
Pillow version: 7.1.2
Tensorboard version: 2.7.0
gdown version: 3.6.4
TorchVision version: 0.11.1+cu111
tqdm version: 4.62.3
lmdb version: 0.99
psutil version: 5.4.8
pandas version: 1.1.5
einops version: NOT INSTALLED or UNKNOWN VERSION.
transformers version: NOT INSTALLED or UNKNOWN VERSION.
mlflow version: NOT INSTALLED or UNKNOWN VERSION.
For details about installing the optional dependencies, please visit:
https://docs.monai.io/en/latest/installation.html#installing-the-recommended-dependencies
データディレクトリのセットアップ
MONAI_DATA_DIRECTORY 環境変数でディレクトリを指定できます。これは結果をセーブしてダウンロードを再利用することを可能にします。指定されない場合、一時ディレクトリが使用されます。
directory = os.environ.get("MONAI_DATA_DIRECTORY")
root_dir = tempfile.mkdtemp() if directory is None else directory
print(root_dir)
/workspace/data/medical
データセットをダウンロードする
MedMNIST データセットは TCIA, RSNA Bone Age チャレンジ と NIH Chest X-ray データセット からの様々なセットから集められました。
データセットは Dr. Bradley J. Erickson M.D., Ph.D. (Department of Radiology, Mayo Clinic) のお陰により Creative Commons CC BY-SA 4.0 ライセンス のもとで利用可能になっています。
MedNIST データセットを使用する場合、出典を明示してください。
resource = "https://github.com/Project-MONAI/MONAI-extra-test-data/releases/download/0.8.1/MedNIST.tar.gz"
md5 = "0bc7306e7427e00ad1c5526a6677552d"
compressed_file = os.path.join(root_dir, "MedNIST.tar.gz")
data_dir = os.path.join(root_dir, "MedNIST")
if not os.path.exists(data_dir):
download_and_extract(resource, compressed_file, root_dir, md5)
再現性のために決定論的訓練を設定する
set_determinism(seed=0)
データセットフォルダから画像ファイル名を読む
まず最初に、データセットファイルを確認して幾つかの統計情報を表示します。
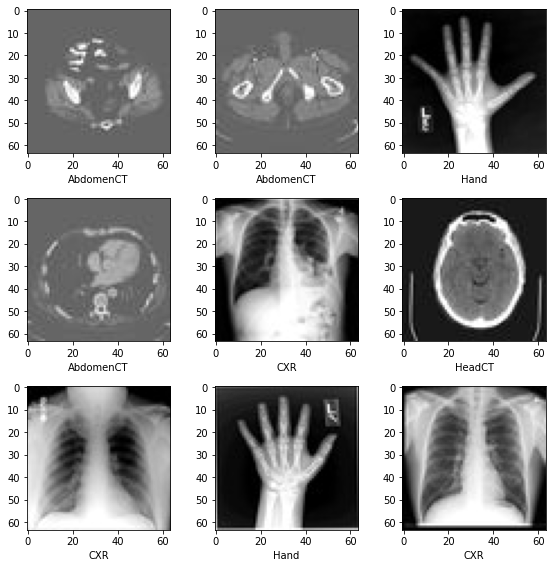
データセットには 6 つのフォルダがあります : Hand, AbdomenCT, CXR, ChestCT, BreastMRI, HeadCT,
これらは分類モデルを訓練するためのラベルとして使用されるべきです。
class_names = sorted(x for x in os.listdir(data_dir)
if os.path.isdir(os.path.join(data_dir, x)))
num_class = len(class_names)
image_files = [
[
os.path.join(data_dir, class_names[i], x)
for x in os.listdir(os.path.join(data_dir, class_names[i]))
]
for i in range(num_class)
]
num_each = [len(image_files[i]) for i in range(num_class)]
image_files_list = []
image_class = []
for i in range(num_class):
image_files_list.extend(image_files[i])
image_class.extend([i] * num_each[i])
num_total = len(image_class)
image_width, image_height = PIL.Image.open(image_files_list[0]).size
print(f"Total image count: {num_total}")
print(f"Image dimensions: {image_width} x {image_height}")
print(f"Label names: {class_names}")
print(f"Label counts: {num_each}")
Total image count: 58954 Image dimensions: 64 x 64 Label names: ['AbdomenCT', 'BreastMRI', 'CXR', 'ChestCT', 'Hand', 'HeadCT'] Label counts: [10000, 8954, 10000, 10000, 10000, 10000]
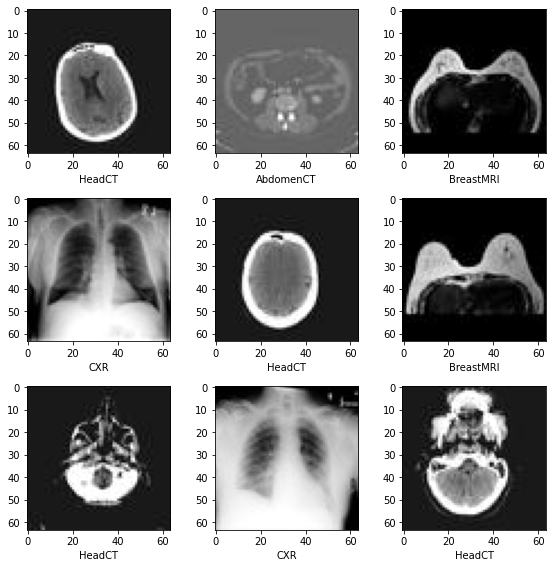
データセットから画像をランダムに選択して可視化して確認する
plt.subplots(3, 3, figsize=(8, 8))
for i, k in enumerate(np.random.randint(num_total, size=9)):
im = PIL.Image.open(image_files_list[k])
arr = np.array(im)
plt.subplot(3, 3, i + 1)
plt.xlabel(class_names[image_class[k]])
plt.imshow(arr, cmap="gray", vmin=0, vmax=255)
plt.tight_layout()
plt.show()
訓練、検証とテストデータのリストを準備する
データセットの 10% を検証用に、そして 10% をテスト用にランダムに選択します。
val_frac = 0.1
test_frac = 0.1
length = len(image_files_list)
indices = np.arange(length)
np.random.shuffle(indices)
test_split = int(test_frac * length)
val_split = int(val_frac * length) + test_split
test_indices = indices[:test_split]
val_indices = indices[test_split:val_split]
train_indices = indices[val_split:]
train_x = [image_files_list[i] for i in train_indices]
train_y = [image_class[i] for i in train_indices]
val_x = [image_files_list[i] for i in val_indices]
val_y = [image_class[i] for i in val_indices]
test_x = [image_files_list[i] for i in test_indices]
test_y = [image_class[i] for i in test_indices]
print(
f"Training count: {len(train_x)}, Validation count: "
f"{len(val_x)}, Test count: {len(test_x)}")
Training count: 47156, Validation count: 5913, Test count: 5885
データを前処理するために MONAI 変換、Dataset と Dataloader を定義する
train_transforms = Compose(
[
LoadImage(image_only=True),
EnsureChannelFirst(),
ScaleIntensity(),
RandRotate(range_x=np.pi / 12, prob=0.5, keep_size=True),
RandFlip(spatial_axis=0, prob=0.5),
RandZoom(min_zoom=0.9, max_zoom=1.1, prob=0.5),
]
)
val_transforms = Compose(
[LoadImage(image_only=True), EnsureChannelFirst(), ScaleIntensity()])
y_pred_trans = Compose([Activations(softmax=True)])
y_trans = Compose([AsDiscrete(to_onehot=num_class)])
class MedNISTDataset(torch.utils.data.Dataset):
def __init__(self, image_files, labels, transforms):
self.image_files = image_files
self.labels = labels
self.transforms = transforms
def __len__(self):
return len(self.image_files)
def __getitem__(self, index):
return self.transforms(self.image_files[index]), self.labels[index]
train_ds = MedNISTDataset(train_x, train_y, train_transforms)
train_loader = DataLoader(
train_ds, batch_size=300, shuffle=True, num_workers=10)
val_ds = MedNISTDataset(val_x, val_y, val_transforms)
val_loader = DataLoader(
val_ds, batch_size=300, num_workers=10)
test_ds = MedNISTDataset(test_x, test_y, val_transforms)
test_loader = DataLoader(
test_ds, batch_size=300, num_workers=10)
ネットワークと optimizer を定義する
- バッチ毎にモデルがどのくらい更新されるかについて学習率を設定します。
- 総エポック数を設定します、シャッフルしてランダムな変換を行ないますので、総てのエポックの訓練データは異なります。
そしてこれは get start チュートリアルに過ぎませんので、4 エポックだけ訓練しましょう。
10 エポック訓練すれば、モデルはテストデータセット上で 100% 精度を達成できます。
- MONAI からの DenseNet を使用して GPU デバイスに移します、この DenseNet は 2D と 3D 分類タスクの両方をサポートできます。
- Adam optimizer を使用します。
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = DenseNet121(spatial_dims=2, in_channels=1,
out_channels=num_class).to(device)
loss_function = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), 1e-5)
max_epochs = 4
val_interval = 1
auc_metric = ROCAUCMetric()
モデル訓練
典型的な PyTorch 訓練を実行します、これはエポック・ループとステップ・ループを実行して、総てのエポック後に検証を行ないます。ベストの検証精度を得た場合、モデル重みをファイルにセーブします。
best_metric = -1
best_metric_epoch = -1
epoch_loss_values = []
metric_values = []
for epoch in range(max_epochs):
print("-" * 10)
print(f"epoch {epoch + 1}/{max_epochs}")
model.train()
epoch_loss = 0
step = 0
for batch_data in train_loader:
step += 1
inputs, labels = batch_data[0].to(device), batch_data[1].to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = loss_function(outputs, labels)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
print(
f"{step}/{len(train_ds) // train_loader.batch_size}, "
f"train_loss: {loss.item():.4f}")
epoch_len = len(train_ds) // train_loader.batch_size
epoch_loss /= step
epoch_loss_values.append(epoch_loss)
print(f"epoch {epoch + 1} average loss: {epoch_loss:.4f}")
if (epoch + 1) % val_interval == 0:
model.eval()
with torch.no_grad():
y_pred = torch.tensor([], dtype=torch.float32, device=device)
y = torch.tensor([], dtype=torch.long, device=device)
for val_data in val_loader:
val_images, val_labels = (
val_data[0].to(device),
val_data[1].to(device),
)
y_pred = torch.cat([y_pred, model(val_images)], dim=0)
y = torch.cat([y, val_labels], dim=0)
y_onehot = [y_trans(i) for i in decollate_batch(y, detach=False)]
y_pred_act = [y_pred_trans(i) for i in decollate_batch(y_pred)]
auc_metric(y_pred_act, y_onehot)
result = auc_metric.aggregate()
auc_metric.reset()
del y_pred_act, y_onehot
metric_values.append(result)
acc_value = torch.eq(y_pred.argmax(dim=1), y)
acc_metric = acc_value.sum().item() / len(acc_value)
if result > best_metric:
best_metric = result
best_metric_epoch = epoch + 1
torch.save(model.state_dict(), os.path.join(
root_dir, "best_metric_model.pth"))
print("saved new best metric model")
print(
f"current epoch: {epoch + 1} current AUC: {result:.4f}"
f" current accuracy: {acc_metric:.4f}"
f" best AUC: {best_metric:.4f}"
f" at epoch: {best_metric_epoch}"
)
print(
f"train completed, best_metric: {best_metric:.4f} "
f"at epoch: {best_metric_epoch}")
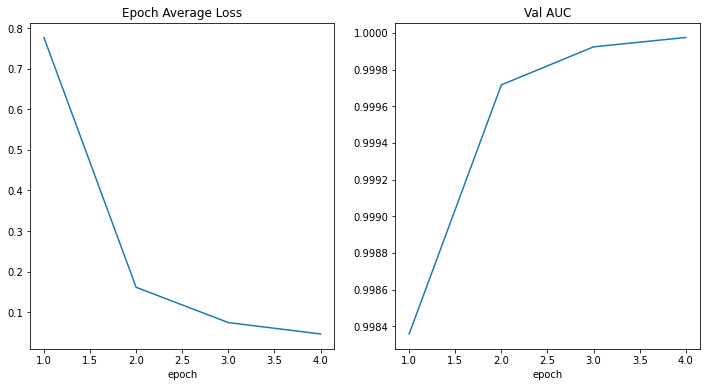
---------- epoch 1/4 (...) epoch 1 average loss: 0.7768 saved new best metric model current epoch: 1 current AUC: 0.9984 current accuracy: 0.9618 best AUC: 0.9984 at epoch: 1 ---------- epoch 2/4 (...) epoch 2 average loss: 0.1612 saved new best metric model current epoch: 2 current AUC: 0.9997 current accuracy: 0.9863 best AUC: 0.9997 at epoch: 2 ---------- epoch 3/4 (...) epoch 3 average loss: 0.0743 saved new best metric model current epoch: 3 current AUC: 0.9999 current accuracy: 0.9924 best AUC: 0.9999 at epoch: 3 ---------- epoch 4/4 (...) epoch 4 average loss: 0.0462 saved new best metric model current epoch: 4 current AUC: 1.0000 current accuracy: 0.9944 best AUC: 1.0000 at epoch: 4 train completed, best_metric: 1.0000 at epoch: 4
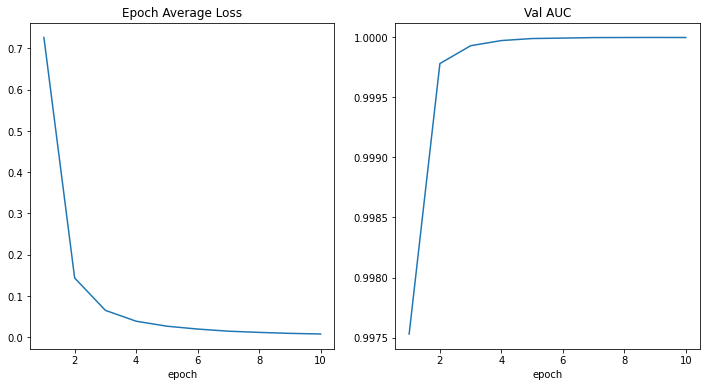
(...) epoch 9 average loss: 0.0094 saved new best metric model current epoch: 9 current AUC: 1.0000 current accuracy: 0.9997 best AUC: 1.0000 at epoch: 9 ---------- epoch 10/10 (...) epoch 10 average loss: 0.0080 current epoch: 10 current AUC: 1.0000 current accuracy: 0.9997 best AUC: 1.0000 at epoch: 9 train completed, best_metric: 1.0000 at epoch: 9
損失とメトリックをプロットする
plt.figure("train", (12, 6))
plt.subplot(1, 2, 1)
plt.title("Epoch Average Loss")
x = [i + 1 for i in range(len(epoch_loss_values))]
y = epoch_loss_values
plt.xlabel("epoch")
plt.plot(x, y)
plt.subplot(1, 2, 2)
plt.title("Val AUC")
x = [val_interval * (i + 1) for i in range(len(metric_values))]
y = metric_values
plt.xlabel("epoch")
plt.plot(x, y)
plt.show()
テストデータセット上でモデルを評価する
訓練と検証の後、検証テスト上のベストモデルを既に得ています。
モデルをテストデータセット上でそれが堅牢で over fitting していないかを確認するために評価する必要があります。
分類レポートを生成するためにこれらの予測を使用します。
model.load_state_dict(torch.load(
os.path.join(root_dir, "best_metric_model.pth")))
model.eval()
y_true = []
y_pred = []
with torch.no_grad():
for test_data in test_loader:
test_images, test_labels = (
test_data[0].to(device),
test_data[1].to(device),
)
pred = model(test_images).argmax(dim=1)
for i in range(len(pred)):
y_true.append(test_labels[i].item())
y_pred.append(pred[i].item())
print(classification_report(
y_true, y_pred, target_names=class_names, digits=4))
Note: you may need to restart the kernel to use updated packages.
precision recall f1-score support
AbdomenCT 0.9816 0.9917 0.9867 969
BreastMRI 0.9968 0.9831 0.9899 944
CXR 0.9979 0.9928 0.9954 973
ChestCT 0.9938 0.9990 0.9964 959
Hand 0.9934 0.9934 0.9934 1055
HeadCT 0.9960 0.9990 0.9975 985
accuracy 0.9932 5885
macro avg 0.9932 0.9932 0.9932 5885
weighted avg 0.9932 0.9932 0.9932 5885
precision recall f1-score support
AbdomenCT 0.9980 0.9990 0.9985 995
BreastMRI 0.9989 1.0000 0.9994 880
CXR 1.0000 0.9969 0.9985 982
ChestCT 0.9990 1.0000 0.9995 1014
Hand 0.9981 0.9990 0.9986 1048
HeadCT 1.0000 0.9990 0.9995 976
accuracy 0.9990 5895
macro avg 0.9990 0.9990 0.9990 5895
weighted avg 0.9990 0.9990 0.9990 5895
データディレクトリのクリーンアップ
一時ディレクトリが使用された場合ディレクトリを削除します。
if directory is None:
shutil.rmtree(root_dir)
以上
MONAI 1.0 : PyTorch ユーザのための MONAI
MONAI 1.0 : PyTorch ユーザのための MONAI (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 11/01/2022 (1.0.1)
* 本ページは、MONAI の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。
- 人工知能研究開発支援
- 人工知能研修サービス(経営者層向けオンサイト研修)
- テクニカルコンサルティングサービス
- 実証実験(プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
- PoC(概念実証)を失敗させないための支援
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
- 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション
- sales-info@classcat.com ; Web: www.classcat.com ; ClassCatJP

MONAI 1.0 : PyTorch ユーザのための MONAI
このチュートリアルは MONAI API を簡単に紹介してその柔軟性と使い易さにハイライトを当てます。それは PyTorch の基本的な理解を前提とし、MONAI がヘルスケア画像処理における深層学習用にドメインに最適化された機能を提供する方法を示します。
パッケージのインストール
MONAI のコア機能は Python で書かれていて Numpy と Pytorch にのみ依存しています。
このセクションは MONAI の最新版をインストールしてインストールを検証します。
# install the latest weekly preview version of MONAI
%pip install -q "monai-weekly[tqdm, nibabel, gdown, ignite]"
import warnings
warnings.filterwarnings("ignore") # remove some scikit-image warnings
import monai
monai.config.print_config()
MONAI version: 0.10.dev2237
Numpy version: 1.21.6
Pytorch version: 1.12.1+cu113
MONAI flags: HAS_EXT = False, USE_COMPILED = False, USE_META_DICT = False
MONAI rev id: 533b9b8f56542f7cbca718e062271fd976c267c1
MONAI __file__: /usr/local/lib/python3.7/dist-packages/monai/__init__.py
Optional dependencies:
Pytorch Ignite version: 0.4.10
Nibabel version: 3.0.2
scikit-image version: 0.18.3
Pillow version: 7.1.2
Tensorboard version: 2.8.0
gdown version: 4.4.0
TorchVision version: 0.13.1+cu113
tqdm version: 4.64.1
lmdb version: 0.99
psutil version: 5.4.8
pandas version: 1.3.5
einops version: NOT INSTALLED or UNKNOWN VERSION.
transformers version: NOT INSTALLED or UNKNOWN VERSION.
mlflow version: NOT INSTALLED or UNKNOWN VERSION.
pynrrd version: NOT INSTALLED or UNKNOWN VERSION.
For details about installing the optional dependencies, please visit:
https://docs.monai.io/en/latest/installation.html#installing-the-recommended-dependencies
数行のコードでパブリックな医用画像データセットへアクセス
公開されているベンチマークの使用はオープンで再現性のある研究のために重要です。MONAI は良く知られた公開データセットへの素早いアクセスを提供することを目的としています。このセクションは医療セグメンテーション・デカスロン (= Medical Segmentation Decathlon ) のデータセットから始めます。
DecathlonDataset オブジェクトは torch.data.utils.Dataset の薄いラッパーです。それは __getitem__ と __len__ を実装していて、PyTorch の組込みデータローダ torch.data.utils.DataLoader と完全に互換です。
PyTorch データセット API と比較して、DecathlonDataset は以下の追加機能を持ちます :
- 自動的なデータのダウンロードと解凍
- データと前処理の中間結果のキャッシング
- 訓練、検証とテストのランダムな分割
from monai.apps import DecathlonDataset
dataset = DecathlonDataset(root_dir="./", task="Task05_Prostate", section="training", transform=None, download=True)
print(f"\nnumber of subjects: {len(dataset)}.\nThe first element in the dataset is {dataset[0]}.")
2022-09-16 06:55:41,150 - INFO - Verified 'Task05_Prostate.tar', md5: 35138f08b1efaef89d7424d2bcc928db.
2022-09-16 06:55:41,152 - INFO - File exists: Task05_Prostate.tar, skipped downloading.
2022-09-16 06:55:41,156 - INFO - Non-empty folder exists in Task05_Prostate, skipped extracting.
Loading dataset: 100%|██████████| 26/26 [00:00<00:00, 186095.40it/s]
number of subjects: 26.
The first element in the dataset is {'image': 'Task05_Prostate/imagesTr/prostate_46.nii.gz', 'label': 'Task05_Prostate/labelsTr/prostate_46.nii.gz'}.
コードセクションは公開レポジトリから "Task05_Prostate.tar" (download=True) をダウンロードして、それを解凍し、そしてアーカイブにより提供される JSON ファイルを解析することにより DecathlonDataset を作成しました。
これは前立腺 (= prostate) 移行 (= transitional) ゾーンと周辺 (= peripheral) ゾーンの輪郭を描く (= delineate) ための 3 クラス・セグメンテーション・タスクです (背景, TZ, PZ クラス)。入力は 2 つの様式、つまり T2 と ADC MRI を持ちます。
len(dataset) と dataset[0] は、それぞれデータセットのサイズを問い合わせ、データセットの最初の要素を取り出します。データセットのためのどのような画像変換も指定していませんので、この iterable なデータセットの出力は画像とセグメンテーション・ファイル名の単なるペアです。
柔軟な画像データ変換
このセクションはファイル名をメモリ内のデータ配列に変換する MONAI 変換を導入します、これにより深層学習モデルにより消費される準備ができます。前処理パイプラインのより多くのサンプルは tutorial レポジトリ と 開発者ガイド で利用可能です。ここでは画像前処理の主要な機能を簡単にカバーします。
配列 vs 辞書ベースの変換
配列変換は MONAI の基本的なビルディングブロックで、それは torchvision.transforms と同様な単純な callable です。2 つの違いがあります :
- MONAI 変換は医用画像特有の処理機能を実装しています。
- MONAI 変換は入力が numpy 配列、pytorch テンソルかテンソル like なオブジェクトであることを前提としています。
以下はローダー変換を開始します、これはファイル名文字列を実際の画像データに変換します。
この変換への より多くのオプションについてのドキュメント を参照してください。
from monai.transforms import LoadImage
loader = LoadImage(image_only=True)
img_array = loader("Task05_Prostate/imagesTr/prostate_02.nii.gz")
print(img_array.shape)
(320, 320, 24, 2)
辞書変換は配列バージョンのラッパーに過ぎません。配列ベースのものと比べて、同じ種類の演算やステートメントを複数のデータ入力に適用することがより簡単です。
以下のセクションは画像とセグメンテーション・マスクのペアを読みます、変換が辞書のどの項目が処理されるべきかを知れるようにキーが指定される必要があることに注意してください。
from monai.transforms import LoadImageD
dict_loader = LoadImageD(keys=("image", "label"))
data_dict = dict_loader({"image": "Task05_Prostate/imagesTr/prostate_02.nii.gz",
"label": "Task05_Prostate/labelsTr/prostate_02.nii.gz"})
print(f"image shape: {data_dict['image'].shape}, \nlabel shape: {data_dict['label'].shape}")
image shape: (320, 320, 24, 2), label shape: (320, 320, 24)
変換の構成
多くの場合、変換のチェインを構築して、前処理パラメータを調整して、高速な前処理パイプラインを作成することは有益です。monai.transforms.Compose はこれらのユースケースのために設計されています。
以下のコードは複数の前処理ステップを行なうために変換チェインを開始しています :
- Nifti 画像を (画像メタデータ情報と共に) ロードします
- 画像とラベルの両方をチャネル first にする (画像を reshape してラベルのためにチャネル次元を追加します)
- 画像とラベルを 1 mm 四方にする
- 画像とラベルの両方を "RAS" 座標系にあるようにする
- 画像強度をスケールする
- 画像とラベルを空間サイズ (64, 64, 32) mm にリサイズする
- 画像をランダムに回転とスケールしますが、出力サイズは (64, 64, 32) mm に保持します。
- 画像とラベルを torch テンソルに変換する
import numpy as np
from monai.transforms import \
LoadImageD, EnsureChannelFirstD, AddChannelD, ScaleIntensityD, ToTensorD, Compose, \
AsDiscreteD, SpacingD, OrientationD, ResizeD, RandAffineD
KEYS = ("image", "label")
xform = Compose([
LoadImageD(KEYS),
EnsureChannelFirstD("image"),
AddChannelD("label"),
OrientationD(KEYS, axcodes='RAS'),
SpacingD(KEYS, pixdim=(1., 1., 1.), mode=('bilinear', 'nearest')),
ScaleIntensityD(keys="image"),
ResizeD(KEYS, (64, 64, 32), mode=('trilinear', 'nearest')),
RandAffineD(KEYS, spatial_size=(-1, -1, -1),
rotate_range=(0, 0, np.pi/2),
scale_range=(0.1, 0.1),
mode=('bilinear', 'nearest'),
prob=1.0),
ToTensorD(KEYS),
])
data_dict = xform({"image": "Task05_Prostate/imagesTr/prostate_02.nii.gz",
"label": "Task05_Prostate/labelsTr/prostate_02.nii.gz"})
print(data_dict["image"].shape, data_dict["label"].shape)
(2, 64, 64, 32) (1, 64, 64, 32)
MONAI には有用な変換のセットがあり、今後更に増えます。詳細は https://docs.monai.io/en/latest/transforms.html を見てください。
データセット、変換とデータローダ
私達が持っているものをまとめると :
- Dataset : torch.utils.data.Dataset の薄いラッパー
- Transform : callable、Compose により作成される変換チェインの一部です。
- データセットへの変換のセッティングはデータロードと前処理パイプラインを可能にします。
パイプラインは pytorch ネイティブのデータローダと連携できて、これはマルチプロセッシングのサポートと柔軟なバッチサンプリング・スキームを提供します。
けれども、MONAI データローダ monai.data.DataLoader と連携することが推奨されます、これは pytorch ネイティブのラッパーです。MONAI データローダは以下の機能を主として追加します :
- マルチプロセスのコンテキストでランダム化された増強を正しく処理します。
- マルチサンプルデータのリストを個々の訓練サンプルに平坦化するためのカスタマイズされた collate 関数
DecathlonDataset の初期化は (非ランダム化) 変換結果のキャッシングを含みます。それは遅いかもしれません、複数エポックの訓練のために初期化されたオブジェクトを使用するとき、遥かに改良された速度のために空間を効果的にトレードオフします。
import torch
from monai.data import DataLoader
# start a chain of transforms
xform = Compose([
LoadImageD(KEYS),
EnsureChannelFirstD("image"),
AddChannelD("label"),
OrientationD(KEYS, axcodes='RAS'),
SpacingD(KEYS, pixdim=(1., 1., 1.), mode=('bilinear', 'nearest')),
ScaleIntensityD(keys="image"),
ResizeD(KEYS, (64, 64, 32), mode=('trilinear', 'nearest')),
RandAffineD(KEYS, spatial_size=(-1, -1, -1),
rotate_range=(0, 0, np.pi/2),
scale_range=(0.1, 0.1),
mode=('bilinear', 'nearest'),
prob=1.0),
ToTensorD(KEYS),
])
# start a dataset
dataset = DecathlonDataset(root_dir="./", task="Task05_Prostate", section="training", transform=xform, download=True)
# start a pytorch dataloader
# data_loader = torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False, num_workers=1)
data_loader = DataLoader(dataset, batch_size=1, shuffle=True, num_workers=1)
2022-09-16 06:55:43,240 - INFO - Verified 'Task05_Prostate.tar', md5: 35138f08b1efaef89d7424d2bcc928db. 2022-09-16 06:55:43,241 - INFO - File exists: Task05_Prostate.tar, skipped downloading. 2022-09-16 06:55:43,246 - INFO - Non-empty folder exists in Task05_Prostate, skipped extracting. Loading dataset: 100%|██████████| 26/26 [00:21<00:00, 1.20it/s]
data_dict で何が起きているか覗いてみましょう (以下のセクションの再実行はデータセットからランダムに増強されたサンプルを生成します) :
import matplotlib.pyplot as plt
import numpy as np
data_dict = next(iter(data_loader))
print(data_dict["image"].shape, data_dict["label"].shape, data_dict["image_meta_dict"]["filename_or_obj"])
plt.subplots(1, 3)
plt.subplot(1, 3, 1); plt.imshow(data_dict["image"][0, 0, ..., 16])
plt.subplot(1, 3, 2); plt.imshow(data_dict["image"][0, 1, ..., 16])
plt.subplot(1, 3, 3); plt.imshow(data_dict["label"][0, 0, ..., 16])
plt.show()
print(f"unique labels: {np.unique(data_dict['label'])}")
(1, 2, 64, 64, 32) (1, 1, 64, 64, 32) ['Task05_Prostate/imagesTr/prostate_25.nii.gz']
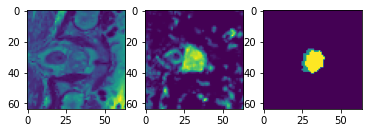
データローダは、深層学習モデルに対応できるように、画像とラベルの両方にバッチ次元を追加しました。
ラベルのために "nearest" 補完モードが使用されますので、変換中に一意のクラスの数が保持されます。
層、ブロック、ネットワークと損失関数
データ入力パイプラインを通り抜けました。適切に前処理されたデータは、2 つの様式の入力を使用して 3 クラス・セグメンテーション・タスクのための準備ができました。
このセクションは UNet モデル、そして損失関数と optimzer を作成します。
これら総てのモジュールは (torch.nn.Module のような) PyTorch インターフェイスの直接的な使用か拡張です。それらは、コードが標準 PyTorch API に従うのであれば、任意のカスタマイズされた Python コードで置き換え可能です。
MONAI のモジュールは医用画像解析のために拡張モジュールを提供することに焦点を当てています :
- 柔軟性とコード可読性の両者を目的とした参照ネットワークの実装
- 1D, 2D と 3D ネットワークと互換な事前定義された層とブロック
- ドメイン固有の損失関数
from monai.networks.nets import UNet
from monai.networks.layers import Norm
from monai.losses import DiceLoss
device = torch.device('cuda:0')
net = UNet(dimensions=3, in_channels=2, out_channels=3, channels=(16, 32, 64, 128, 256),
strides=(2, 2, 2, 2), num_res_units=2, norm=Norm.BATCH).to(device)
loss = DiceLoss(to_onehot_y=True, softmax=True)
opt = torch.optim.Adam(net.parameters(), 1e-2)
UNet は dimensions パラメータで定義されます。それは Conv1d, Conv2d と Conv3d のような、pytorch API の空間次元の数を指定します。同じ実装で、1D, 2D, 3D とマルチモーダル訓練のために容易に構成できます。
torch.nn.Module の拡張としての UNet は特定の方法で体系化された MONAI ブロックと層のセットです。ブロックと層は、"Conv. + Feature Norm. + Activation" のような一般に使用される組合せのように、再利用可能なサブモジュールとして設計されています。
スライディング・ウィンドウ推論
この一般に使用されるモジュールについて、MONAI は単純な PyTorch ベースの実装を提供します、これはウィンドウサイズと入力モデル (これは torch.nn.Module 実装であり得ます) の仕様だけを必要とします。
以下のデモは、総ての空間位置を通して実行される (40, 40) 空間サイズ・ウィンドウを集約することにより、(1, 1, 200, 200) の入力画像上のスライディング・ウィンドウ推論の toy を示します。
roi_size, sw_batch_size と overlap パラメータをそれらのスライディング・ウィンドウ出力上のインパクトを見るために変更することができます。
from monai.inferers import SlidingWindowInferer
class ToyModel:
# A simple model generates the output by adding an integer `pred` to input.
# each call of this instance increases the integer by 1.
pred = 0
def __call__(self, input):
self.pred = self.pred + 1
input = input + self.pred
return input
infer = SlidingWindowInferer(roi_size=(40, 40), sw_batch_size=1, overlap=0)
input_tensor = torch.zeros(1, 1, 200, 200)
output_tensor = infer(input_tensor, ToyModel())
plt.imshow(output_tensor[0, 0]); plt.show()
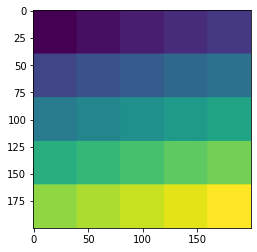
訓練ワークフローの開始 (エポック毎に検証)
入力パイプライン、ネットワーク・アーキテクチャ、損失関数は総て既存の pytorch ベースのワークフローと互換です。様々なユースケースについてはチュートリアルを参照してください : https://github.com/Project-MONAI/tutorials
ここで PyTorch-Ignite ベースで MONAI により構築された、ワークフロー・ユティリティにハイライトを当てたいです。主要な目標は、比較的標準的な訓練ワークフローを構築する際にユーザの労力を軽減することです。
import ignite
print(ignite.__version__)
0.4.10
以下のコマンドは SupervisedTrainer インスタンスを起動します。PyTorch ignite の機能の拡張として、それは前述した総ての要素を結合します。trainer.run() の呼び出しは 2 エポックの間ネットワークを訓練して、総てのエポックの最後に訓練データに基づいて MeadDice メトリックを計算します。
key_train_metric はモデルの品質向上の進捗を追跡するために使用されます。追加のハンドラが早期停止と学習率スケジューリングを行なうために設定できます。
StatsHandler は診断情報を stdout にプリントするために訓練反復毎にトリガーされます。これらはユーザ指定の頻度で詳細な訓練ログを生成するように構成できます。
イベント処理システムの詳細は、ドキュメント https://docs.monai.io/en/latest/handlers.html を参照してください。
注目すべき点は、これらの機能は通常の訓練と検証パイプラインの高速なプロトタイピングを容易にすることです。ユーザは前のセクションで述べたモジュールを利用して、独自のパイプラインを構築することを常に選択できます。
from monai.engines import SupervisedTrainer
from monai.inferers import SlidingWindowInferer
from monai.handlers import StatsHandler, MeanDice, from_engine
from monai.transforms import AsDiscreteD
import sys
import logging
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
trainer = SupervisedTrainer(
device=device,
max_epochs=2,
train_data_loader=data_loader,
network=net,
optimizer=opt,
loss_function=loss,
inferer=SlidingWindowInferer((32, 32, -1), sw_batch_size=2),
postprocessing=AsDiscreteD(keys=["pred", "label"], argmax=(True, False), to_onehot=3),
key_train_metric={"train_meandice": MeanDice(output_transform=from_engine(["pred", "label"]))},
train_handlers=StatsHandler(tag_name="train_loss", output_transform=from_engine(["loss"], first=True)),
)
trainer.run()
INFO:ignite.engine.engine.SupervisedTrainer:Engine run resuming from iteration 0, epoch 0 until 2 epochs INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/2, Iter: 1/26 -- train_loss: 0.8139 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/2, Iter: 2/26 -- train_loss: 0.7707 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/2, Iter: 3/26 -- train_loss: 0.6901 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/2, Iter: 4/26 -- train_loss: 0.6979 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/2, Iter: 5/26 -- train_loss: 0.7192 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/2, Iter: 6/26 -- train_loss: 0.6859 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/2, Iter: 7/26 -- train_loss: 0.6445 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/2, Iter: 8/26 -- train_loss: 0.6273 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/2, Iter: 9/26 -- train_loss: 0.6346 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/2, Iter: 10/26 -- train_loss: 0.6078 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/2, Iter: 11/26 -- train_loss: 0.5424 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/2, Iter: 12/26 -- train_loss: 0.5851 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/2, Iter: 13/26 -- train_loss: 0.5647 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/2, Iter: 14/26 -- train_loss: 0.5551 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/2, Iter: 15/26 -- train_loss: 0.5925 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/2, Iter: 16/26 -- train_loss: 0.5389 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/2, Iter: 17/26 -- train_loss: 0.5662 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/2, Iter: 18/26 -- train_loss: 0.6309 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/2, Iter: 19/26 -- train_loss: 0.6168 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/2, Iter: 20/26 -- train_loss: 0.5556 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/2, Iter: 21/26 -- train_loss: 0.5243 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/2, Iter: 22/26 -- train_loss: 0.5801 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/2, Iter: 23/26 -- train_loss: 0.5132 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/2, Iter: 24/26 -- train_loss: 0.4951 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/2, Iter: 25/26 -- train_loss: 0.4870 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/2, Iter: 26/26 -- train_loss: 0.5108 INFO:ignite.engine.engine.SupervisedTrainer:Got new best metric of train_meandice: 0.4181462824344635 INFO:ignite.engine.engine.SupervisedTrainer:Epoch[1] Metrics -- train_meandice: 0.4181 INFO:ignite.engine.engine.SupervisedTrainer:Key metric: train_meandice best value: 0.4181462824344635 at epoch: 1 INFO:ignite.engine.engine.SupervisedTrainer:Epoch[1] Complete. Time taken: 00:00:08 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/2, Iter: 1/26 -- train_loss: 0.5620 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/2, Iter: 2/26 -- train_loss: 0.5373 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/2, Iter: 3/26 -- train_loss: 0.4764 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/2, Iter: 4/26 -- train_loss: 0.5111 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/2, Iter: 5/26 -- train_loss: 0.5922 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/2, Iter: 6/26 -- train_loss: 0.5519 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/2, Iter: 7/26 -- train_loss: 0.6246 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/2, Iter: 8/26 -- train_loss: 0.4363 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/2, Iter: 9/26 -- train_loss: 0.5052 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/2, Iter: 10/26 -- train_loss: 0.5900 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/2, Iter: 11/26 -- train_loss: 0.5997 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/2, Iter: 12/26 -- train_loss: 0.4996 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/2, Iter: 13/26 -- train_loss: 0.4969 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/2, Iter: 14/26 -- train_loss: 0.5740 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/2, Iter: 15/26 -- train_loss: 0.5852 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/2, Iter: 16/26 -- train_loss: 0.5460 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/2, Iter: 17/26 -- train_loss: 0.5034 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/2, Iter: 18/26 -- train_loss: 0.5233 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/2, Iter: 19/26 -- train_loss: 0.5109 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/2, Iter: 20/26 -- train_loss: 0.4877 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/2, Iter: 21/26 -- train_loss: 0.5745 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/2, Iter: 22/26 -- train_loss: 0.5044 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/2, Iter: 23/26 -- train_loss: 0.4623 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/2, Iter: 24/26 -- train_loss: 0.4399 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/2, Iter: 25/26 -- train_loss: 0.4553 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/2, Iter: 26/26 -- train_loss: 0.5245 INFO:ignite.engine.engine.SupervisedTrainer:Got new best metric of train_meandice: 0.4688393473625183 INFO:ignite.engine.engine.SupervisedTrainer:Epoch[2] Metrics -- train_meandice: 0.4688 INFO:ignite.engine.engine.SupervisedTrainer:Key metric: train_meandice best value: 0.4688393473625183 at epoch: 2 INFO:ignite.engine.engine.SupervisedTrainer:Epoch[2] Complete. Time taken: 00:00:08 INFO:ignite.engine.engine.SupervisedTrainer:Engine run complete. Time taken: 00:00:16
決定論的訓練
決定論的訓練サポートは再現可能な研究のために重要です。MONAI は現在 2 つのメカニズムを提供しています :
- 総てのランダム変換のランダム状態を設定します。これはグローバルなランダム状態には影響しません。例えば :
# define a transform chain for pre-processing train_transforms = monai.transforms.Compose([ LoadImaged(keys=['image', 'label']), RandRotate90d(keys=['image', 'label'], prob=0.2, spatial_axes=[0, 2]), ... ... ]) # set determinism for reproducibility train_transforms.set_random_state(seed=0) - 1 行のコードでグローバルに python, numpy と pytorch のための決定論的訓練を有効にします、例えば :
monai.utils.set_determinism(seed=0, additional_settings=None)
まとめ
MONAI の主要なモジュールを通り抜けてきました。高度に柔軟な拡張とラッパーを作成することにより、MONAI は医用画像解析の観点から pytorch API を強化しています。
以下のような、この短いチュートリアルではカバーされなかったソフトウェア機能があります :
- 後処理変換
- 視覚化インターフェイス
- サードパーティの医用画像ツールキットからの組み込めるデータ変換
- 他の人気のある深層学習フレームワークを使用するワークフローの構築
- MONAI 研究
最新のマイルストーンのハイライトの詳細については、https://docs.monai.io/en/latest/highlights.html にアクセスしてください。
MONAI を深く理解するには、examples レポジトリは良い開始点です : https://github.com/Project-MONAI/tutorials
API ドキュメントについては、https://docs.monai.io にアクセスしてください。
以上
MONAI 1.0 : MedNIST デモ (画像分類チュートリアル)
MONAI 1.0 : MedNIST デモ (画像分類チュートリアル) (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 10/30/2022 (1.0.1)
* 本ページは、MONAI の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。
- 人工知能研究開発支援
- 人工知能研修サービス(経営者層向けオンサイト研修)
- テクニカルコンサルティングサービス
- 実証実験(プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
- PoC(概念実証)を失敗させないための支援
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
- 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション
- sales-info@classcat.com ; Web: www.classcat.com ; ClassCatJP
MONAI 1.0 : MedNIST デモ (画像分類チュートリアル)
イントロダクション
このチュートリアルでは、MedNIST データセットに基づいて end-to-end な訓練と評価サンプルを紹介します。以下のステップを通り抜けます :
- 訓練とテストのための MONAI データセットを作成します。
- データの前処理のために MONAI 変換を使用します。
- 分類タスクのために MONAI から DenseNet を使用します。
- PyTorch プログラムでモデルを訓練します。
- テストデータセットで評価します。
データセットの取得
MedNIST データセットは TCIA, RSNA Bone Age チャレンジ と NIH Chest X-ray データセット の様々なセットから集められました。
データセットは Dr. Bradley J. Erickson M.D., Ph.D. (Department of Radiology, Mayo Clinic) のお陰により Creative Commons CC BY-SA 4.0 ライセンス のもとで利用可能になっています。MedNIST データセットを使用する場合、出典を明示してください、e.g. https://github.com/Project-MONAI/tutorials/blob/master/2d_classification/mednist_tutorial.ipynb。
以下のコマンドはデータセット (~ 60MB) をダウンロードして unzip します。
!wget -q https://www.dropbox.com/s/5wwskxctvcxiuea/MedNIST.tar.gz
# unzip the '.tar.gz' file to the current directory
import tarfile
datafile = tarfile.open("MedNIST.tar.gz")
datafile.extractall()
datafile.close()
MONAI をインストールします :
!pip install -q "monai-weekly[gdown, nibabel, tqdm, itk]"
import os
import shutil
import tempfile
import matplotlib.pyplot as plt
from PIL import Image
import torch
import numpy as np
from sklearn.metrics import classification_report
from monai.apps import download_and_extract
from monai.config import print_config
from monai.metrics import ROCAUCMetric
from monai.networks.nets import DenseNet121
from monai.transforms import (
Activations,
EnsureChannelFirst,
AsDiscrete,
Compose,
LoadImage,
RandFlip,
RandRotate,
RandZoom,
ScaleIntensity,
ToTensor,
)
from monai.data import Dataset, DataLoader
from monai.utils import set_determinism
print_config()
MONAI version: 1.1.dev2238
Numpy version: 1.21.6
Pytorch version: 1.12.1+cu113
MONAI flags: HAS_EXT = False, USE_COMPILED = False, USE_META_DICT = False
MONAI rev id: 8d72c2b845c8e91aad9a7cf17f2049bdec215f9d
MONAI __file__: /usr/local/lib/python3.7/dist-packages/monai/__init__.py
Optional dependencies:
Pytorch Ignite version: NOT INSTALLED or UNKNOWN VERSION.
Nibabel version: 3.0.2
scikit-image version: 0.18.3
Pillow version: 7.1.2
Tensorboard version: 2.8.0
gdown version: 4.4.0
TorchVision version: 0.13.1+cu113
tqdm version: 4.64.1
lmdb version: 0.99
psutil version: 5.4.8
pandas version: 1.3.5
einops version: NOT INSTALLED or UNKNOWN VERSION.
transformers version: NOT INSTALLED or UNKNOWN VERSION.
mlflow version: NOT INSTALLED or UNKNOWN VERSION.
pynrrd version: NOT INSTALLED or UNKNOWN VERSION.
For details about installing the optional dependencies, please visit:
https://docs.monai.io/en/latest/installation.html#installing-the-recommended-dependencies
データセットフォルダから画像ファイル名を読む
最初に、データセットファイルを確認して幾つかの統計情報を示します。データセットには 6 つのフォルダがあります : Hand, AbdomenCT, CXR, ChestCT, BreastMRI, HeadCT, これらは分類モデルを訓練するラベルとして使用されるべきです。
data_dir = './MedNIST/'
class_names = sorted([x for x in os.listdir(data_dir) if os.path.isdir(os.path.join(data_dir, x))])
num_class = len(class_names)
image_files = [[os.path.join(data_dir, class_name, x)
for x in os.listdir(os.path.join(data_dir, class_name))]
for class_name in class_names]
image_file_list = []
image_label_list = []
for i, class_name in enumerate(class_names):
image_file_list.extend(image_files[i])
image_label_list.extend([i] * len(image_files[i]))
num_total = len(image_label_list)
image_width, image_height = Image.open(image_file_list[0]).size
print('Total image count:', num_total)
print("Image dimensions:", image_width, "x", image_height)
print("Label names:", class_names)
print("Label counts:", [len(image_files[i]) for i in range(num_class)])
Total image count: 58954 Image dimensions: 64 x 64 Label names: ['AbdomenCT', 'BreastMRI', 'CXR', 'ChestCT', 'Hand', 'HeadCT'] Label counts: [10000, 8954, 10000, 10000, 10000, 10000]
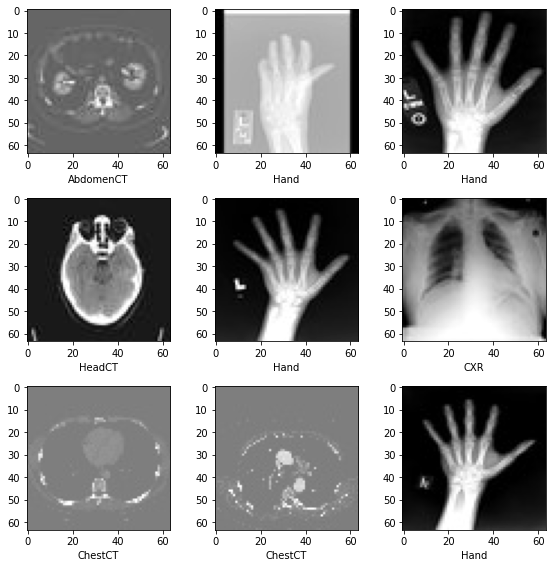
データセットからランダムに選択された幾つかのサンプルを可視化する
plt.subplots(3, 3, figsize=(8, 8))
for i,k in enumerate(np.random.randint(num_total, size=9)):
im = Image.open(image_file_list[k])
arr = np.array(im)
plt.subplot(3, 3, i + 1)
plt.xlabel(class_names[image_label_list[k]])
plt.imshow(arr, cmap='gray', vmin=0, vmax=255)
plt.tight_layout()
plt.show()
訓練、検証とテストデータ・リストの準備
データセットの 10% を検証用に、10% をテスト用にランダムに選択します。
valid_frac, test_frac = 0.1, 0.1
trainX, trainY = [], []
valX, valY = [], []
testX, testY = [], []
for i in range(num_total):
rann = np.random.random()
if rann < valid_frac:
valX.append(image_file_list[i])
valY.append(image_label_list[i])
elif rann < test_frac + valid_frac:
testX.append(image_file_list[i])
testY.append(image_label_list[i])
else:
trainX.append(image_file_list[i])
trainY.append(image_label_list[i])
print("Training count =",len(trainX),"Validation count =", len(valX), "Test count =",len(testX))
Training count = 47197 Validation count = 5900 Test count = 5857
データを前処理するために MONAI 変換, Dataset と Dataloader を定義する
train_transforms = Compose([
LoadImage(image_only=True),
EnsureChannelFirst(),
ScaleIntensity(),
RandRotate(range_x=15, prob=0.5, keep_size=True),
RandFlip(spatial_axis=0, prob=0.5),
RandZoom(min_zoom=0.9, max_zoom=1.1, prob=0.5, keep_size=True),
ToTensor()
])
val_transforms = Compose([
LoadImage(image_only=True),
EnsureChannelFirst(),
ScaleIntensity(),
ToTensor()
])
act = Activations(softmax=True)
to_onehot = AsDiscrete(to_onehot=num_class)
class MedNISTDataset(Dataset):
def __init__(self, image_files, labels, transforms):
self.image_files = image_files
self.labels = labels
self.transforms = transforms
def __len__(self):
return len(self.image_files)
def __getitem__(self, index):
return self.transforms(self.image_files[index]), self.labels[index]
train_ds = MedNISTDataset(trainX, trainY, train_transforms)
train_loader = DataLoader(train_ds, batch_size=300, shuffle=True, num_workers=2)
val_ds = MedNISTDataset(valX, valY, val_transforms)
val_loader = DataLoader(val_ds, batch_size=300, num_workers=2)
test_ds = MedNISTDataset(testX, testY, val_transforms)
test_loader = DataLoader(test_ds, batch_size=300, num_workers=2)
ネットワークと optimizer の定義
- バッチ毎にモデルをどの位更新するか学習率を設定します。
- 総エポック数を設定します、シャッフルとランダム変換を持ちますので、総てのエポックの訓練データは異なります。そしてこれは単なる get start チュートリアルですから、4 エポックだけ訓練しましょう。10 エポック訓練すれば、モデルはテストデータセットで 100% 精度を達成できます。
- MONAI から DenseNet を使用して GPU デバイスに移します、この DenseNet は 2D と 3D 分類タスクの両方をサポートできます。
- Adam optimizer を使用します。
device = torch.device("cuda:0")
model = DenseNet121(
spatial_dims=2,
in_channels=1,
out_channels=num_class
).to(device)
loss_function = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), 1e-5)
epoch_num = 4
val_interval = 1
モデル訓練
エポックループとステップループを実行する典型的な PyTorch 訓練を実行し、そしてエポック毎後に検証を行ないます。ベストな検証精度を得た場合にはモデル重みをファイルにセーブします。
best_metric = -1
best_metric_epoch = -1
epoch_loss_values = list()
auc_metric = ROCAUCMetric()
metric_values = list()
for epoch in range(epoch_num):
print('-' * 10)
print(f"epoch {epoch + 1}/{epoch_num}")
model.train()
epoch_loss = 0
step = 0
for batch_data in train_loader:
step += 1
inputs, labels = batch_data[0].to(device), batch_data[1].to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = loss_function(outputs, labels)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
print(f"{step}/{len(train_ds) // train_loader.batch_size}, train_loss: {loss.item():.4f}")
epoch_len = len(train_ds) // train_loader.batch_size
epoch_loss /= step
epoch_loss_values.append(epoch_loss)
print(f"epoch {epoch + 1} average loss: {epoch_loss:.4f}")
if (epoch + 1) % val_interval == 0:
model.eval()
with torch.no_grad():
y_pred = torch.tensor([], dtype=torch.float32, device=device)
y = torch.tensor([], dtype=torch.long, device=device)
for val_data in val_loader:
val_images, val_labels = val_data[0].to(device), val_data[1].to(device)
y_pred = torch.cat([y_pred, model(val_images)], dim=0)
y = torch.cat([y, val_labels], dim=0)
y_onehot = [to_onehot(i) for i in y]
y_pred_act = [act(i) for i in y_pred]
auc_metric(y_pred_act, y_onehot)
auc_result = auc_metric.aggregate()
auc_metric.reset()
del y_pred_act, y_onehot
metric_values.append(auc_result)
acc_value = torch.eq(y_pred.argmax(dim=1), y)
acc_metric = acc_value.sum().item() / len(acc_value)
if acc_metric > best_metric:
best_metric = acc_metric
best_metric_epoch = epoch + 1
torch.save(model.state_dict(), 'best_metric_model.pth')
print('saved new best metric model')
print(f"current epoch: {epoch + 1} current AUC: {auc_result:.4f}"
f" current accuracy: {acc_metric:.4f} best AUC: {best_metric:.4f}"
f" at epoch: {best_metric_epoch}")
print(f"train completed, best_metric: {best_metric:.4f} at epoch: {best_metric_epoch}")
---------- epoch 1/4 (...) epoch 1 average loss: 0.8157 saved new best metric model current epoch: 1 current AUC: 0.9979 current accuracy: 0.9637 best AUC: 0.9637 at epoch: 1 ---------- epoch 2/4 (...) epoch 2 average loss: 0.1961 saved new best metric model current epoch: 2 current AUC: 0.9997 current accuracy: 0.9837 best AUC: 0.9837 at epoch: 2 ---------- epoch 3/4 (...) epoch 3 average loss: 0.0906 saved new best metric model current epoch: 3 current AUC: 0.9999 current accuracy: 0.9927 best AUC: 0.9927 at epoch: 3 ---------- epoch 4/4 (...) epoch 4 average loss: 0.0545 saved new best metric model current epoch: 4 current AUC: 1.0000 current accuracy: 0.9959 best AUC: 0.9959 at epoch: 4 train completed, best_metric: 0.9959 at epoch: 4
epoch 10 average loss: 0.0155 current epoch: 10 current AUC: 1.0000 current accuracy: 0.9986 best AUC: 0.9990 at epoch: 9 train completed, best_metric: 0.9990 at epoch: 9 CPU times: user 7min 38s, sys: 46.3 s, total: 8min 24s Wall time: 27min 14s
損失とメトリックのプロット
plt.figure('train', (12, 6))
plt.subplot(1, 2, 1)
plt.title("Epoch Average Loss")
x = [i + 1 for i in range(len(epoch_loss_values))]
y = epoch_loss_values
plt.xlabel('epoch')
plt.plot(x, y)
plt.subplot(1, 2, 2)
plt.title("Validation: Area under the ROC curve")
x = [val_interval * (i + 1) for i in range(len(metric_values))]
y = metric_values
plt.xlabel('epoch')
plt.plot(x, y)
plt.show()
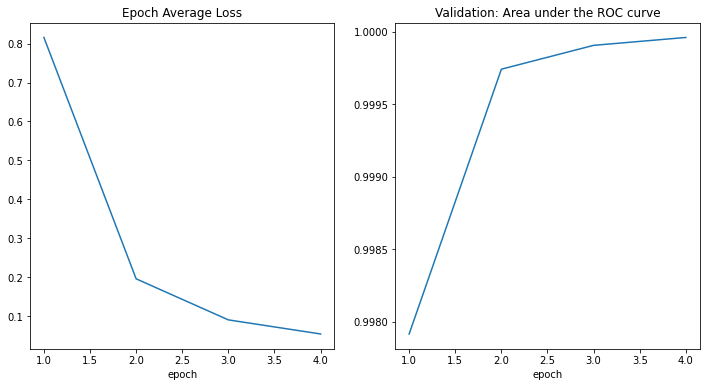
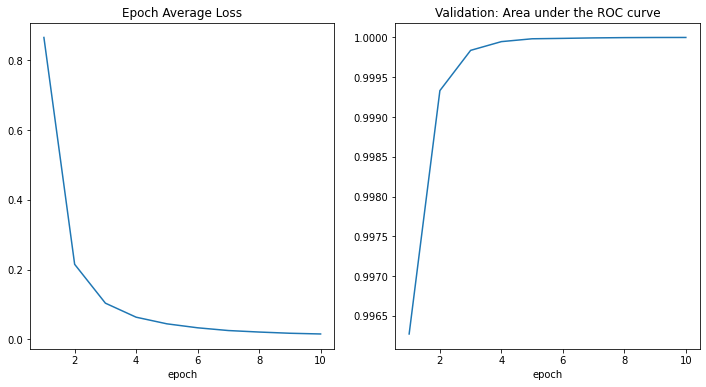
テストデータセットでモデルを評価する
訓練と検証の後、検証テスト上のベストモデルを既に得ています。モデルが堅牢であることと過剰適合 (over-fitting) していないことを確認するためにテストデータセット上で評価する必要があります。分類レポートを生成するためにこれらの予測を使用します。
model.load_state_dict(torch.load('best_metric_model.pth'))
model.eval()
y_true = list()
y_pred = list()
with torch.no_grad():
for test_data in test_loader:
test_images, test_labels = test_data[0].to(device), test_data[1].to(device)
pred = model(test_images).argmax(dim=1)
for i in range(len(pred)):
y_true.append(test_labels[i].item())
y_pred.append(pred[i].item())
from sklearn.metrics import classification_report
print(classification_report(y_true, y_pred, target_names=class_names, digits=4))
precision recall f1-score support
AbdomenCT 0.9941 0.9912 0.9927 1025
BreastMRI 0.9955 0.9921 0.9938 884
CXR 0.9949 0.9959 0.9954 973
ChestCT 0.9922 1.0000 0.9961 1015
Hand 0.9969 0.9889 0.9929 989
HeadCT 0.9908 0.9959 0.9933 971
accuracy 0.9940 5857
macro avg 0.9941 0.9940 0.9940 5857
weighted avg 0.9940 0.9940 0.9940 5857
precision recall f1-score support
AbdomenCT 0.9990 0.9961 0.9976 1031
BreastMRI 0.9977 0.9988 0.9982 851
CXR 0.9990 0.9971 0.9980 1022
ChestCT 0.9971 1.0000 0.9986 1035
Hand 0.9969 0.9969 0.9969 983
HeadCT 0.9980 0.9990 0.9985 1001
accuracy 0.9980 5923
macro avg 0.9980 0.9980 0.9980 5923
weighted avg 0.9980 0.9980 0.9980 5923
以上
MONAI 1.0 : 概要 (README)
MONAI 1.0 : README (概要) (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 10/29/2022 (1.0.1)
* 本ページは、MONAI の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。
- 人工知能研究開発支援
- 人工知能研修サービス(経営者層向けオンサイト研修)
- テクニカルコンサルティングサービス
- 実証実験(プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
- PoC(概念実証)を失敗させないための支援
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
- 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション
- sales-info@classcat.com ; Web: www.classcat.com ; ClassCatJP
![]()
MONAI 1.0 : 概要 (README)
Medical Open Network for AI
MONAI は PyTorch エコシステム の一部で、ヘルスケア画像処理における深層学習のための PyTorch ベース、オープンソース のフレームワークです。その野心は :
- 共通基盤で協力して取り組める学術的、産業的そして臨床的な研究者のコミュニティを構築すること ;
- ヘルスケア画像処理のための最先端で、end-to-end な訓練ワークフローを作成すること ;
- 深層学習モデルを作成して評価するために最適化され標準化された方法を研究者に提供すること。
機能
マイルストーン・リリースの テクニカル・ハイライト と What’s New を参照してください。
- 多次元医用画像処理データのための柔軟な前処理 ;
- 既存のワークフロー内の簡単な統合のための構成的 & 可搬な API ;
- ネットワーク、損失、評価メトリクス等のためのドメイン固有な実装 ;
- 様々なユーザ専門性のためのカスタマイズ可能なデザイン ;
- マルチ GPU データ並列サポート。
インストール
現在のリリース をインストールするには、単純に以下を実行することができます :
pip install monai
他のインストール・オプションについては、インストールガイド を参照してください。
Getting Started
MedNIST デモ と MONAI for PyTorch Users が Colab で利用可能です。
サンプルとノートブック・チュートリアルは Project-MONAI/tutorials にあります。
技術文書は docs.monai.io で利用可能です。
モデル Zoo
MONAI モデル Zoo は研究者とデータサイエンティストがコミュニティからの最新の素晴らしいモデルを共有するための場所です。MONAI バンドル形式 の利用は MONAI でワークフローを構築し始める (Getting Started) ことを容易にします。
Contributing
MONAI への contribution (貢献) を行なうガイダンスについては、contributing ガイドライン を参照してください。
コミュニティ
Twitter @ProjectMONAI の会話に参加するか Slack チャネル に参加してください。
MONAI の GitHub Discussions タブ で質疑応答してください。
リンク
- Website : https://monai.io/
- API ドキュメント (マイルストーン) : https://docs.monai.io
- API ドキュメント (最新 dev) : https://docs.monai.io/en/latest/
- Code: https://github.com/Project-MONAI/MONAI
- Project tracker: https://github.com/Project-MONAI/MONAI/projects
- Issue tracker: https://github.com/Project-MONAI/MONAI/issues
- Wiki : https://github.com/Project-MONAI/MONAI/wiki
- Test status: https://github.com/Project-MONAI/MONAI/actions
- PyPI package: https://pypi.org/project/monai/
- conda-forge: https://anaconda.org/conda-forge/monai
- Weekly previews: https://pypi.org/project/monai-weekly/
- Docker Hub: https://hub.docker.com/r/projectmonai/monai
以上
MONAI 0.7 : tutorials : 3D セグメンテーション – 脳腫瘍 3D セグメンテーション
MONAI 0.7 : tutorials : 3D セグメンテーション – 脳腫瘍 3D セグメンテーション (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 11/08/2021 (0.7.0)
* 本ページは、MONAI の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。
- 人工知能研究開発支援
- 人工知能研修サービス(経営者層向けオンサイト研修)
- テクニカルコンサルティングサービス
- 実証実験(プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
- PoC(概念実証)を失敗させないための支援
- テレワーク & オンライン授業を支援
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |
MONAI 0.7 : tutorials : 3D セグメンテーション – 脳腫瘍 3D セグメンテーション
このチュートリアルは MSD 脳腫瘍データセットに基づくマルチラベル・タスクの訓練ワークフローを構築する方法を示します。
このチュートリアルはマルチラベル・セグメンテーション・タスクの訓練ワークフローを構築する方法を示します。
そしてそれは以下の機能を含みます :
- 辞書形式データのための変換。
- MONAI 変換 API に従って新しい変換を定義する。
- メタデータと共に Nifti 画像をロードし、画像のリストをロードしてそれらをスタックする。
- データ増強のために強度をランダムに調整する。
- 訓練と検証を高速化する Cache IO と変換。
- 3D セグメンテーション・タスクのための 3D SegResNet モデル, Dice 損失関数, 平均 Dice メトリック。
- 再現性のための決定論的訓練。
データセットは http://medicaldecathlon.com/ に由来します。
ターゲット: Gliomas segmentation necrotic/active tumour and oedema
Modality: Multimodal multisite MRI データ (FLAIR, T1w, T1gd,T2w)
サイズ: 750 4D volumes (484 訓練 + 266 テスト)
ソース: BRATS 2016 と 2017 データセット。
チャレンジ: Complex and heterogeneously-located targets
下図は、様々なモダリティでアノテートされている腫瘍部分領域の画像パッチ (左上) とデータセット全体のための最終的なラベル (右) を示します。(図は BraTS IEEE TMI 論文 から引用)
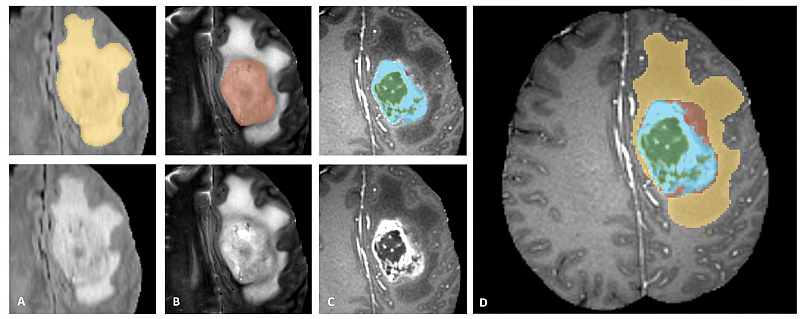
画像パッチは左から右へ以下を示します :
- T2-FLAIR で見える腫瘍全体 (黄色) (Fig.A)。
- T2 で見える腫瘍のコア (赤色) (Fig. B)。
- T1Gd で見える enhancing 腫瘍構造 (ライトブルー)、これはコアの嚢胞 (のうほう) (= cystic) / 壊死 (=necrotic) 成分 (緑色) を取り囲んでいます (Fig. C)。
- セグメンテーションは 腫瘍部分領域の最終的なラベル (Fig.D) を生成するために組み合わされます : 浮腫 (= edema) (黄色), non-enhancing ソリッドコア (赤色), 嚢胞/壊死コア (緑色), enhancing コア (青色) です。
環境のセットアップ
!python -c "import monai" || pip install -q "monai-weekly[nibabel, tqdm]"
!python -c "import matplotlib" || pip install -q matplotlib
#!pip install pytorch-ignite
%matplotlib inline
インポートのセットアップ
# Copyright 2020 MONAI Consortium
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
# http://www.apache.org/licenses/LICENSE-2.0
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import os
import shutil
import tempfile
import time
import matplotlib.pyplot as plt
import numpy as np
from monai.apps import DecathlonDataset
from monai.config import print_config
from monai.data import DataLoader, decollate_batch
from monai.handlers.utils import from_engine
from monai.losses import DiceLoss
from monai.inferers import sliding_window_inference
from monai.metrics import DiceMetric
from monai.networks.nets import SegResNet
from monai.transforms import (
Activations,
Activationsd,
AsDiscrete,
AsDiscreted,
Compose,
Invertd,
LoadImaged,
MapTransform,
NormalizeIntensityd,
Orientationd,
RandFlipd,
RandScaleIntensityd,
RandShiftIntensityd,
RandSpatialCropd,
Spacingd,
EnsureChannelFirstd,
EnsureTyped,
EnsureType,
)
from monai.utils import set_determinism
import torch
print_config()
MONAI version: 0.4.0+618.g69b44596
Numpy version: 1.20.3
Pytorch version: 1.9.0a0+c3d40fd
MONAI flags: HAS_EXT = False, USE_COMPILED = False
MONAI rev id: 69b4459650fb6943b9e729e724254d2db2b2a1f2
Optional dependencies:
Pytorch Ignite version: 0.4.5
Nibabel version: 3.2.1
scikit-image version: 0.15.0
Pillow version: 8.3.1
Tensorboard version: 2.5.0
gdown version: 3.13.0
TorchVision version: 0.10.0a0
tqdm version: 4.53.0
lmdb version: 1.2.1
psutil version: 5.8.0
pandas version: 1.1.4
einops version: 0.3.0
For details about installing the optional dependencies, please visit:
https://docs.monai.io/en/latest/installation.html#installing-the-recommended-dependencies
データディレクトリのセットアップ
MONAI_DATA_DIRECTORY 環境変数でディレクトリを指定できます。これは結果をセーブしてダウンロードを再利用することを可能にします。指定されない場合、一時ディレクトリが使用されます。
directory = os.environ.get("MONAI_DATA_DIRECTORY")
root_dir = tempfile.mkdtemp() if directory is None else directory
print(root_dir)
/workspace/data/medical
再現性のために決定論的訓練を設定する
set_determinism(seed=0)
脳腫瘍のラベルを変換するための新しい変換を定義する
ここでは多クラスラベルを One-Hot 形式のマルチラベルのセグメンテーション・タスクに変換します。
class ConvertToMultiChannelBasedOnBratsClassesd(MapTransform):
"""
Convert labels to multi channels based on brats classes:
label 1 is the peritumoral edema
label 2 is the GD-enhancing tumor
label 3 is the necrotic and non-enhancing tumor core
The possible classes are TC (Tumor core), WT (Whole tumor)
and ET (Enhancing tumor).
"""
def __call__(self, data):
d = dict(data)
for key in self.keys:
result = []
# merge label 2 and label 3 to construct TC
result.append(np.logical_or(d[key] == 2, d[key] == 3))
# merge labels 1, 2 and 3 to construct WT
result.append(
np.logical_or(
np.logical_or(d[key] == 2, d[key] == 3), d[key] == 1
)
)
# label 2 is ET
result.append(d[key] == 2)
d[key] = np.stack(result, axis=0).astype(np.float32)
return d
訓練と検証のための変換のセットアップ
train_transform = Compose(
[
# load 4 Nifti images and stack them together
LoadImaged(keys=["image", "label"]),
EnsureChannelFirstd(keys="image"),
ConvertToMultiChannelBasedOnBratsClassesd(keys="label"),
Spacingd(
keys=["image", "label"],
pixdim=(1.0, 1.0, 1.0),
mode=("bilinear", "nearest"),
),
Orientationd(keys=["image", "label"], axcodes="RAS"),
RandSpatialCropd(keys=["image", "label"], roi_size=[224, 224, 144], random_size=False),
RandFlipd(keys=["image", "label"], prob=0.5, spatial_axis=0),
RandFlipd(keys=["image", "label"], prob=0.5, spatial_axis=1),
RandFlipd(keys=["image", "label"], prob=0.5, spatial_axis=2),
NormalizeIntensityd(keys="image", nonzero=True, channel_wise=True),
RandScaleIntensityd(keys="image", factors=0.1, prob=1.0),
RandShiftIntensityd(keys="image", offsets=0.1, prob=1.0),
EnsureTyped(keys=["image", "label"]),
]
)
val_transform = Compose(
[
LoadImaged(keys=["image", "label"]),
EnsureChannelFirstd(keys="image"),
ConvertToMultiChannelBasedOnBratsClassesd(keys="label"),
Spacingd(
keys=["image", "label"],
pixdim=(1.0, 1.0, 1.0),
mode=("bilinear", "nearest"),
),
Orientationd(keys=["image", "label"], axcodes="RAS"),
NormalizeIntensityd(keys="image", nonzero=True, channel_wise=True),
EnsureTyped(keys=["image", "label"]),
]
)
DecathlonDataset でデータを素早くロードする
ここではデータセットを自動的にダウンロードして抽出するために DecathlonDataset を使用します。それは MONAI CacheDataset を継承し、より少ないメモリを使用したい場合には、訓練のために N 項目をキャッシュするために cache_num=N を設定して検証のために総ての項目をキャッシュするために default args を使用できます、それはメモリサイズに依存します。
# here we don't cache any data in case out of memory issue
train_ds = DecathlonDataset(
root_dir=root_dir,
task="Task01_BrainTumour",
transform=train_transform,
section="training",
download=True,
cache_rate=0.0,
num_workers=4,
)
train_loader = DataLoader(train_ds, batch_size=1, shuffle=True, num_workers=4)
val_ds = DecathlonDataset(
root_dir=root_dir,
task="Task01_BrainTumour",
transform=val_transform,
section="validation",
download=False,
cache_rate=0.0,
num_workers=4,
)
val_loader = DataLoader(val_ds, batch_size=1, shuffle=False, num_workers=4)
Verified 'Task01_BrainTumour.tar', md5: 240a19d752f0d9e9101544901065d872. File exists: /workspace/data/medical/Task01_BrainTumour.tar, skipped downloading. Non-empty folder exists in /workspace/data/medical/Task01_BrainTumour, skipped extracting.
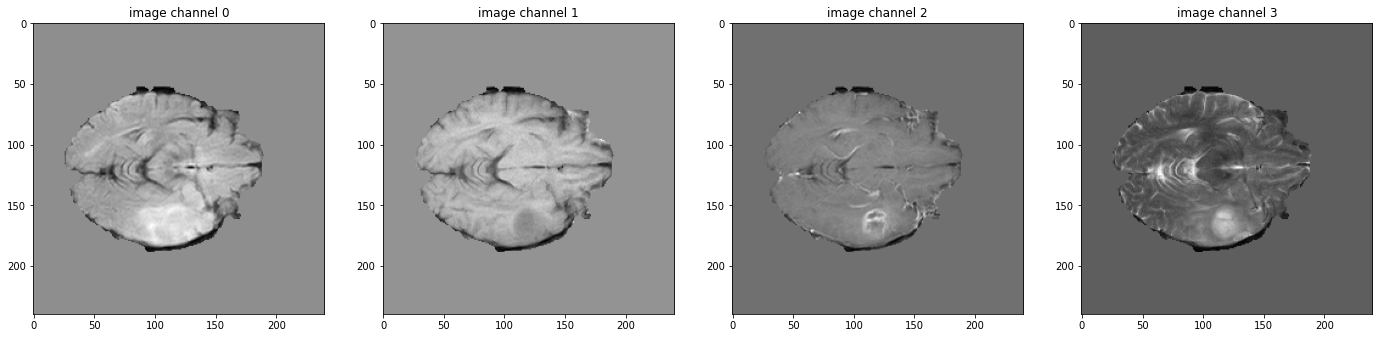
データ shape を確認して可視化する
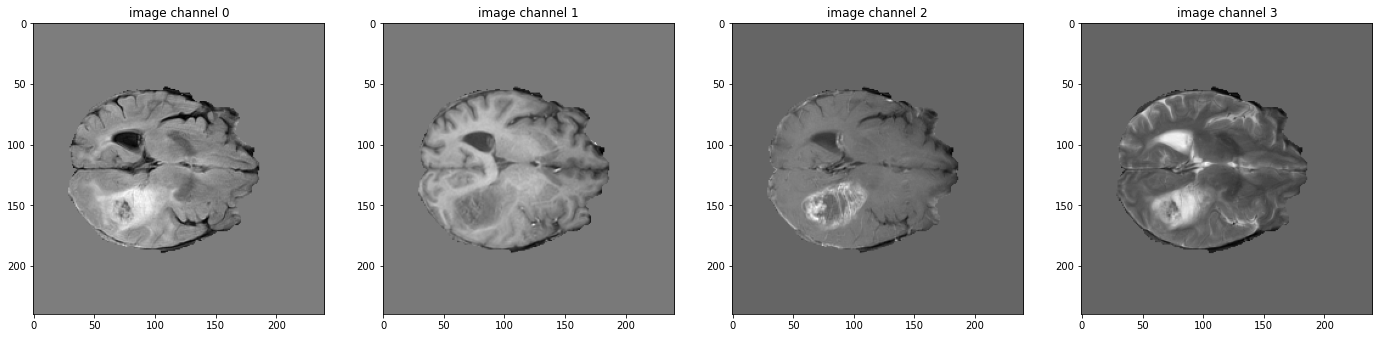
# pick one image from DecathlonDataset to visualize and check the 4 channels
print(f"image shape: {val_ds[2]['image'].shape}")
plt.figure("image", (24, 6))
for i in range(4):
plt.subplot(1, 4, i + 1)
plt.title(f"image channel {i}")
plt.imshow(val_ds[2]["image"][i, :, :, 60].detach().cpu(), cmap="gray")
plt.show()
# also visualize the 3 channels label corresponding to this image
print(f"label shape: {val_ds[2]['label'].shape}")
plt.figure("label", (18, 6))
for i in range(3):
plt.subplot(1, 3, i + 1)
plt.title(f"label channel {i}")
plt.imshow(val_ds[2]["label"][i, :, :, 60].detach().cpu())
plt.show()
image shape: torch.Size([4, 240, 240, 155])

モデル, 損失, Optimizer を作成する
max_epochs = 300
val_interval = 1
VAL_AMP = True
# standard PyTorch program style: create SegResNet, DiceLoss and Adam optimizer
device = torch.device("cuda:0")
model = SegResNet(
blocks_down=[1, 2, 2, 4],
blocks_up=[1, 1, 1],
init_filters=16,
in_channels=4,
out_channels=3,
dropout_prob=0.2,
).to(device)
loss_function = DiceLoss(smooth_nr=0, smooth_dr=1e-5, squared_pred=True, to_onehot_y=False, sigmoid=True)
optimizer = torch.optim.Adam(model.parameters(), 1e-4, weight_decay=1e-5)
lr_scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=max_epochs)
dice_metric = DiceMetric(include_background=True, reduction="mean")
dice_metric_batch = DiceMetric(include_background=True, reduction="mean_batch")
post_trans = Compose(
[EnsureType(), Activations(sigmoid=True), AsDiscrete(threshold_values=True)]
)
# define inference method
def inference(input):
def _compute(input):
return sliding_window_inference(
inputs=input,
roi_size=(240, 240, 160),
sw_batch_size=1,
predictor=model,
overlap=0.5,
)
if VAL_AMP:
with torch.cuda.amp.autocast():
return _compute(input)
else:
return _compute(input)
# use amp to accelerate training
scaler = torch.cuda.amp.GradScaler()
# enable cuDNN benchmark
torch.backends.cudnn.benchmark = True
典型的な PyTorch 訓練プロセスの実行
best_metric = -1
best_metric_epoch = -1
best_metrics_epochs_and_time = [[], [], []]
epoch_loss_values = []
metric_values = []
metric_values_tc = []
metric_values_wt = []
metric_values_et = []
total_start = time.time()
for epoch in range(max_epochs):
epoch_start = time.time()
print("-" * 10)
print(f"epoch {epoch + 1}/{max_epochs}")
model.train()
epoch_loss = 0
step = 0
for batch_data in train_loader:
step_start = time.time()
step += 1
inputs, labels = (
batch_data["image"].to(device),
batch_data["label"].to(device),
)
optimizer.zero_grad()
with torch.cuda.amp.autocast():
outputs = model(inputs)
loss = loss_function(outputs, labels)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
epoch_loss += loss.item()
print(
f"{step}/{len(train_ds) // train_loader.batch_size}"
f", train_loss: {loss.item():.4f}"
f", step time: {(time.time() - step_start):.4f}"
)
lr_scheduler.step()
epoch_loss /= step
epoch_loss_values.append(epoch_loss)
print(f"epoch {epoch + 1} average loss: {epoch_loss:.4f}")
if (epoch + 1) % val_interval == 0:
model.eval()
with torch.no_grad():
for val_data in val_loader:
val_inputs, val_labels = (
val_data["image"].to(device),
val_data["label"].to(device),
)
val_outputs = inference(val_inputs)
val_outputs = [post_trans(i) for i in decollate_batch(val_outputs)]
dice_metric(y_pred=val_outputs, y=val_labels)
dice_metric_batch(y_pred=val_outputs, y=val_labels)
metric = dice_metric.aggregate().item()
metric_values.append(metric)
metric_batch = dice_metric_batch.aggregate()
metric_tc = metric_batch[0].item()
metric_values_tc.append(metric_tc)
metric_wt = metric_batch[1].item()
metric_values_wt.append(metric_wt)
metric_et = metric_batch[2].item()
metric_values_et.append(metric_et)
dice_metric.reset()
dice_metric_batch.reset()
if metric > best_metric:
best_metric = metric
best_metric_epoch = epoch + 1
best_metrics_epochs_and_time[0].append(best_metric)
best_metrics_epochs_and_time[1].append(best_metric_epoch)
best_metrics_epochs_and_time[2].append(time.time() - total_start)
torch.save(
model.state_dict(),
os.path.join(root_dir, "best_metric_model.pth"),
)
print("saved new best metric model")
print(
f"current epoch: {epoch + 1} current mean dice: {metric:.4f}"
f" tc: {metric_tc:.4f} wt: {metric_wt:.4f} et: {metric_et:.4f}"
f"\nbest mean dice: {best_metric:.4f}"
f" at epoch: {best_metric_epoch}"
)
print(f"time consuming of epoch {epoch + 1} is: {(time.time() - epoch_start):.4f}")
total_time = time.time() - total_start
print(f"train completed, best_metric: {best_metric:.4f} at epoch: {best_metric_epoch}, total time: {total_time}.")
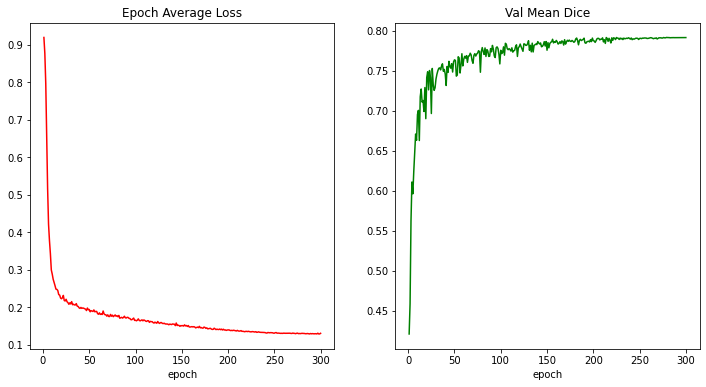
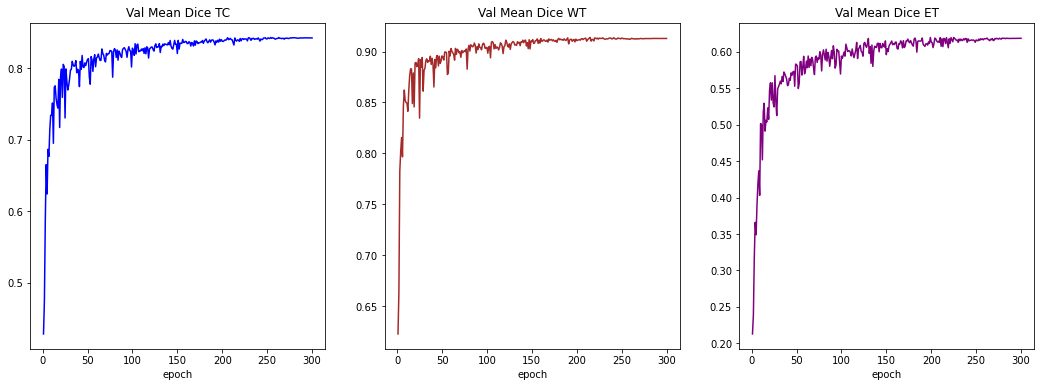
train completed, best_metric: 0.7914 at epoch: 279, total time: 90155.70936012268.
損失とメトリックのプロット
plt.figure("train", (12, 6))
plt.subplot(1, 2, 1)
plt.title("Epoch Average Loss")
x = [i + 1 for i in range(len(epoch_loss_values))]
y = epoch_loss_values
plt.xlabel("epoch")
plt.plot(x, y, color="red")
plt.subplot(1, 2, 2)
plt.title("Val Mean Dice")
x = [val_interval * (i + 1) for i in range(len(metric_values))]
y = metric_values
plt.xlabel("epoch")
plt.plot(x, y, color="green")
plt.show()
plt.figure("train", (18, 6))
plt.subplot(1, 3, 1)
plt.title("Val Mean Dice TC")
x = [val_interval * (i + 1) for i in range(len(metric_values_tc))]
y = metric_values_tc
plt.xlabel("epoch")
plt.plot(x, y, color="blue")
plt.subplot(1, 3, 2)
plt.title("Val Mean Dice WT")
x = [val_interval * (i + 1) for i in range(len(metric_values_wt))]
y = metric_values_wt
plt.xlabel("epoch")
plt.plot(x, y, color="brown")
plt.subplot(1, 3, 3)
plt.title("Val Mean Dice ET")
x = [val_interval * (i + 1) for i in range(len(metric_values_et))]
y = metric_values_et
plt.xlabel("epoch")
plt.plot(x, y, color="purple")
plt.show()
入力画像とラベルでベストモデル出力を確認する
model.load_state_dict(
torch.load(os.path.join(root_dir, "best_metric_model.pth"))
)
model.eval()
with torch.no_grad():
# select one image to evaluate and visualize the model output
val_input = val_ds[6]["image"].unsqueeze(0).to(device)
roi_size = (128, 128, 64)
sw_batch_size = 4
val_output = inference(val_input)
val_output = post_trans(val_output[0])
plt.figure("image", (24, 6))
for i in range(4):
plt.subplot(1, 4, i + 1)
plt.title(f"image channel {i}")
plt.imshow(val_ds[6]["image"][i, :, :, 70].detach().cpu(), cmap="gray")
plt.show()
# visualize the 3 channels label corresponding to this image
plt.figure("label", (18, 6))
for i in range(3):
plt.subplot(1, 3, i + 1)
plt.title(f"label channel {i}")
plt.imshow(val_ds[6]["label"][i, :, :, 70].detach().cpu())
plt.show()
# visualize the 3 channels model output corresponding to this image
plt.figure("output", (18, 6))
for i in range(3):
plt.subplot(1, 3, i + 1)
plt.title(f"output channel {i}")
plt.imshow(val_output[i, :, :, 70].detach().cpu())
plt.show()


元の画像 spacings 上の評価
val_org_transforms = Compose(
[
LoadImaged(keys=["image", "label"]),
EnsureChannelFirstd(keys=["image"]),
ConvertToMultiChannelBasedOnBratsClassesd(keys="label"),
Spacingd(keys=["image"], pixdim=(1.0, 1.0, 1.0), mode="bilinear"),
Orientationd(keys=["image"], axcodes="RAS"),
NormalizeIntensityd(keys="image", nonzero=True, channel_wise=True),
EnsureTyped(keys=["image", "label"]),
]
)
val_org_ds = DecathlonDataset(
root_dir=root_dir,
task="Task01_BrainTumour",
transform=val_org_transforms,
section="validation",
download=False,
num_workers=4,
cache_num=0,
)
val_org_loader = DataLoader(val_org_ds, batch_size=1, shuffle=False, num_workers=4)
post_transforms = Compose([
EnsureTyped(keys="pred"),
Invertd(
keys="pred",
transform=val_org_transforms,
orig_keys="image",
meta_keys="pred_meta_dict",
orig_meta_keys="image_meta_dict",
meta_key_postfix="meta_dict",
nearest_interp=False,
to_tensor=True,
),
Activationsd(keys="pred", sigmoid=True),
AsDiscreted(keys="pred", threshold_values=True),
])
model.load_state_dict(torch.load(
os.path.join(root_dir, "best_metric_model.pth")))
model.eval()
with torch.no_grad():
for val_data in val_org_loader:
val_inputs = val_data["image"].to(device)
val_data["pred"] = inference(val_inputs)
val_data = [post_transforms(i) for i in decollate_batch(val_data)]
val_outputs, val_labels = from_engine(["pred", "label"])(val_data)
dice_metric(y_pred=val_outputs, y=val_labels)
dice_metric_batch(y_pred=val_outputs, y=val_labels)
metric_org = dice_metric.aggregate().item()
metric_batch_org = dice_metric_batch.aggregate()
dice_metric.reset()
dice_metric_batch.reset()
metric_tc, metric_wt, metric_et = metric_batch[0].item(), metric_batch[1].item(), metric_batch[2].item()
print("Metric on original image spacing: ", metric)
print(f"metric_tc: {metric_tc:.4f}")
print(f"metric_wt: {metric_wt:.4f}")
print(f"metric_et: {metric_et:.4f}")
Metric on original image spacing: 0.7912478446960449 metric_tc: 0.8422 metric_wt: 0.9129 metric_et: 0.6187
データディレクトリのクリーンアップ
一時ディレクトリが使用された場合ディレクトリを削除します。
if directory is None:
shutil.rmtree(root_dir)
以上
MONAI 0.7 : tutorials : 3D セグメンテーション – UNet による 3D セグメンテーション
MONAI 0.7 : tutorials : 3D セグメンテーション – UNet による 3D セグメンテーション (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 11/07/2021 (0.7.0)
* 本ページは、MONAI の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。
- 人工知能研究開発支援
- 人工知能研修サービス(経営者層向けオンサイト研修)
- テクニカルコンサルティングサービス
- 実証実験(プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
- PoC(概念実証)を失敗させないための支援
- テレワーク & オンライン授業を支援
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |
MONAI 0.7 : tutorials : 3D セグメンテーション – UNet による 3D セグメンテーション
このノートブックは合成データセットに基づく 3D セグメンテーションの end-to-end な訓練 & 評価サンプルです。サンプルは PyTorch Ignite プログラムで MONAI の幾つかの主要な機能を示します、特に医療ドメイン固有の変換とプロファイリング (ロギング, TensorBoard, MLFlow 等) のためのイベントハンドラを使用します。
環境のセットアップ
!python -c "import monai" || pip install -q "monai-weekly[ignite, nibabel, tensorboard, mlflow]"
インポートのセットアップ
# Copyright 2020 MONAI Consortium
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
# http://www.apache.org/licenses/LICENSE-2.0
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import glob
import logging
import os
from pathlib import Path
import shutil
import sys
import tempfile
import nibabel as nib
import numpy as np
from monai.config import print_config
from monai.data import ArrayDataset, create_test_image_3d, decollate_batch
from monai.handlers import (
MeanDice,
MLFlowHandler,
StatsHandler,
TensorBoardImageHandler,
TensorBoardStatsHandler,
)
from monai.losses import DiceLoss
from monai.networks.nets import UNet
from monai.transforms import (
Activations,
AddChannel,
AsDiscrete,
Compose,
LoadImage,
RandSpatialCrop,
Resize,
ScaleIntensity,
EnsureType,
)
from monai.utils import first
import ignite
import torch
print_config()
データディレクトリのセットアップ
MONAI_DATA_DIRECTORY 環境変数でディレクトリを指定できます。これは結果をセーブしてダウンロードを再利用することを可能にします。指定されない場合、一時ディレクトリが使用されます。
directory = os.environ.get("MONAI_DATA_DIRECTORY")
root_dir = tempfile.mkdtemp() if directory is None else directory
print(root_dir)
/workspace/data/medical
ロギングのセットアップ
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
デモデータのセットアップ
for i in range(40):
im, seg = create_test_image_3d(128, 128, 128, num_seg_classes=1)
n = nib.Nifti1Image(im, np.eye(4))
nib.save(n, os.path.join(root_dir, f"im{i}.nii.gz"))
n = nib.Nifti1Image(seg, np.eye(4))
nib.save(n, os.path.join(root_dir, f"seg{i}.nii.gz"))
images = sorted(glob.glob(os.path.join(root_dir, "im*.nii.gz")))
segs = sorted(glob.glob(os.path.join(root_dir, "seg*.nii.gz")))
変換, データセットのセットアップ
# Define transforms for image and segmentation
imtrans = Compose(
[
LoadImage(image_only=True),
ScaleIntensity(),
AddChannel(),
RandSpatialCrop((96, 96, 96), random_size=False),
EnsureType(),
]
)
segtrans = Compose(
[
LoadImage(image_only=True),
AddChannel(),
RandSpatialCrop((96, 96, 96), random_size=False),
EnsureType(),
]
)
# Define nifti dataset, dataloader
ds = ArrayDataset(images, imtrans, segs, segtrans)
loader = torch.utils.data.DataLoader(
ds, batch_size=10, num_workers=2, pin_memory=torch.cuda.is_available()
)
im, seg = first(loader)
print(im.shape, seg.shape)
torch.Size([10, 1, 96, 96, 96]) torch.Size([10, 1, 96, 96, 96])
モデル, 損失, Optimizer を作成する
# Create UNet, DiceLoss and Adam optimizer
device = torch.device("cuda:0")
net = UNet(
spatial_dims=3,
in_channels=1,
out_channels=1,
channels=(16, 32, 64, 128, 256),
strides=(2, 2, 2, 2),
num_res_units=2,
).to(device)
loss = DiceLoss(sigmoid=True)
lr = 1e-3
opt = torch.optim.Adam(net.parameters(), lr)
ignite を使用して supervised_trainer を作成する
# Create trainer
trainer = ignite.engine.create_supervised_trainer(
net, opt, loss, device, False
)
チェックポインティングとロギングのためのイベントハンドラのセットアップ
# optional section for checkpoint and tensorboard logging
# adding checkpoint handler to save models (network
# params and optimizer stats) during training
log_dir = os.path.join(root_dir, "logs")
checkpoint_handler = ignite.handlers.ModelCheckpoint(
log_dir, "net", n_saved=10, require_empty=False
)
trainer.add_event_handler(
event_name=ignite.engine.Events.EPOCH_COMPLETED,
handler=checkpoint_handler,
to_save={"net": net, "opt": opt},
)
# StatsHandler prints loss at every iteration
# user can also customize print functions and can use output_transform to convert
# engine.state.output if it's not a loss value
train_stats_handler = StatsHandler(name="trainer", output_transform=lambda x: x)
train_stats_handler.attach(trainer)
# TensorBoardStatsHandler plots loss at every iteration
train_tensorboard_stats_handler = TensorBoardStatsHandler(log_dir=log_dir, output_transform=lambda x: x)
train_tensorboard_stats_handler.attach(trainer)
# MLFlowHandler plots loss at every iteration on MLFlow web UI
mlflow_dir = os.path.join(log_dir, "mlruns")
train_mlflow_handler = MLFlowHandler(tracking_uri=Path(mlflow_dir).as_uri(), output_transform=lambda x: x)
train_mlflow_handler.attach(trainer)
N エポック毎の検証の追加
# optional section for model validation during training
validation_every_n_epochs = 1
# Set parameters for validation
metric_name = "Mean_Dice"
# add evaluation metric to the evaluator engine
val_metrics = {metric_name: MeanDice()}
post_pred = Compose(
[EnsureType(), Activations(sigmoid=True), AsDiscrete(threshold_values=True)]
)
post_label = Compose([EnsureType(), AsDiscrete(threshold_values=True)])
# Ignite evaluator expects batch=(img, seg) and
# returns output=(y_pred, y) at every iteration,
# user can add output_transform to return other values
evaluator = ignite.engine.create_supervised_evaluator(
net,
val_metrics,
device,
True,
output_transform=lambda x, y, y_pred: (
[post_pred(i) for i in decollate_batch(y_pred)],
[post_label(i) for i in decollate_batch(y)]
),
)
# create a validation data loader
val_imtrans = Compose(
[
LoadImage(image_only=True),
ScaleIntensity(),
AddChannel(),
Resize((96, 96, 96)),
EnsureType(),
]
)
val_segtrans = Compose(
[
LoadImage(image_only=True),
AddChannel(),
Resize((96, 96, 96)),
EnsureType(),
]
)
val_ds = ArrayDataset(images[21:], val_imtrans, segs[21:], val_segtrans)
val_loader = torch.utils.data.DataLoader(
val_ds, batch_size=5, num_workers=8, pin_memory=torch.cuda.is_available()
)
@trainer.on(
ignite.engine.Events.EPOCH_COMPLETED(every=validation_every_n_epochs)
)
def run_validation(engine):
evaluator.run(val_loader)
# Add stats event handler to print validation stats via evaluator
val_stats_handler = StatsHandler(
name="evaluator",
# no need to print loss value, so disable per iteration output
output_transform=lambda x: None,
# fetch global epoch number from trainer
global_epoch_transform=lambda x: trainer.state.epoch,
)
val_stats_handler.attach(evaluator)
# add handler to record metrics to TensorBoard at every validation epoch
val_tensorboard_stats_handler = TensorBoardStatsHandler(
log_dir=log_dir,
# no need to plot loss value, so disable per iteration output
output_transform=lambda x: None,
# fetch global epoch number from trainer
global_epoch_transform=lambda x: trainer.state.epoch,
)
val_tensorboard_stats_handler.attach(evaluator)
# add handler to record metrics to MLFlow at every validation epoch
val_mlflow_handler = MLFlowHandler(
tracking_uri=Path(mlflow_dir).as_uri(),
# no need to plot loss value, so disable per iteration output
output_transform=lambda x: None,
# fetch global epoch number from trainer
global_epoch_transform=lambda x: trainer.state.epoch,
)
val_mlflow_handler.attach(evaluator)
# add handler to draw the first image and the corresponding
# label and model output in the last batch
# here we draw the 3D output as GIF format along Depth
# axis, at every validation epoch
val_tensorboard_image_handler = TensorBoardImageHandler(
log_dir=log_dir,
batch_transform=lambda batch: (batch[0], batch[1]),
output_transform=lambda output: output[0],
global_iter_transform=lambda x: trainer.state.epoch,
)
evaluator.add_event_handler(
event_name=ignite.engine.Events.EPOCH_COMPLETED,
handler=val_tensorboard_image_handler,
)
訓練ループの実行
# create a training data loader
train_ds = ArrayDataset(images[:20], imtrans, segs[:20], segtrans)
train_loader = torch.utils.data.DataLoader(
train_ds,
batch_size=5,
shuffle=True,
num_workers=8,
pin_memory=torch.cuda.is_available(),
)
max_epochs = 10
state = trainer.run(train_loader, max_epochs)
Tensorboard ログの可視化
%load_ext tensorboard
%tensorboard --logdir=log_dir
MLFlow で訓練ステータスを可視化する
mlflow は IPython コンポーネントではないので、log_dir に切り替えて MLFlow UI を起動するためにコマンド mlflow ui を実行してください。
MLFlow UI で予想される訓練曲線です :
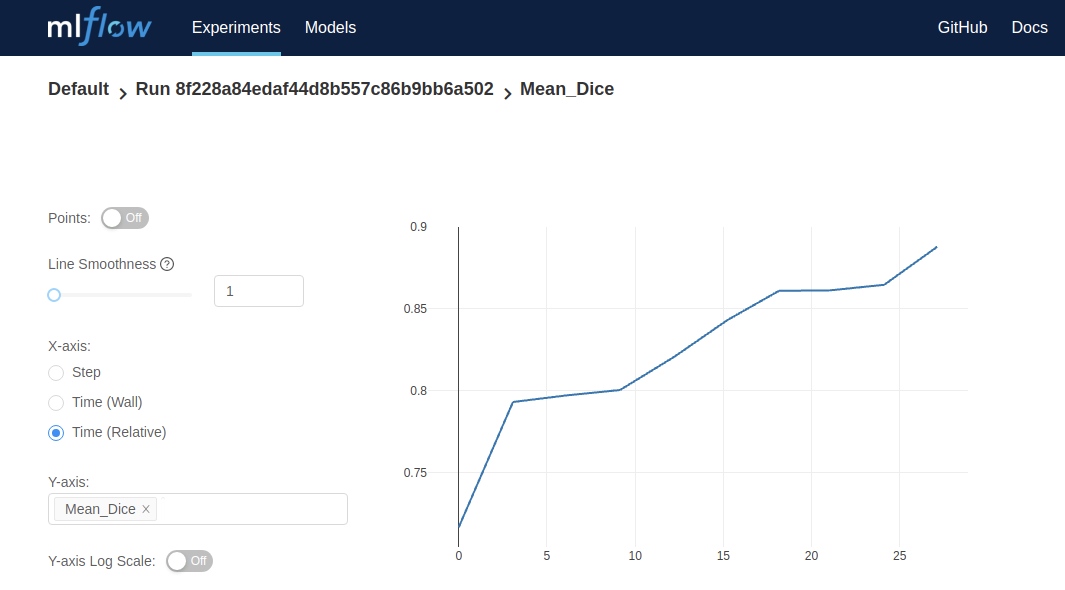
データディレクトリのクリーンアップ
一時ディレクトリが使用された場合ディレクトリを削除します。
if directory is None:
shutil.rmtree(root_dir)
以上
MONAI 0.7 : チュートリアル
MONAI 0.7 : チュートリアル
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 10/09/2021 (0.7.0)
更新日時 : 11/07/2021
- 人工知能研究開発支援
- 人工知能研修サービス(経営者層向けオンサイト研修)
- テクニカルコンサルティングサービス
- 実証実験(プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
- PoC(概念実証)を失敗させないための支援
- テレワーク & オンライン授業を支援
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |
MONAI 0.7 : チュートリアル
2D 分類
- MedNIST データセットによる医用画像分類 (mednist_tutorial) (10/05/2021)
2D セグメンテーション
3D 分類
3D セグメンテーション
- (ignite examples)
- (torch examples)
- 脳腫瘍 3D セグメンテーション (brats_segmentation_3d) (11/08/2021)
- 脾臓 3D セグメンテーション (Lightning 版) (spleen_segmentation_3d_lightning) (10/16/2021)
- 脾臓 3D セグメンテーション (spleen_segmentation_3d) (10/16/2021)
- MONAI と Catalyst による 3D セグメンテーション (unet_segmentation_3d_catalyst) (10/22/2021)
- UNet による 3D セグメンテーション (unet_segmentation_3d_ignite) (11/07/2021)
- (COVID 19-20 challenge baseline)
- (unetr_btcv_segmentation_3d)
- (unetr_btcv_segmentation_3d_lightning)
2D レジストレーション
- 2D XRay レジストレーション・デモ (registration using mednist) (10/10/2021)
3D レジストレーション
deepgrow
配備
- BentoML による MedNIST 分類器の配備 (BentoML) (10/19/2021)
- (Ray)
連合学習
デジタルパソロジー
高速化
- (fast_model_training_guide)
- (distributed_training)
- (automatic_mixed_precision)
- (dataset_type_performance)
- MONAI 機能による高速訓練 (fast_training_tutorial) (10/15/2021)
- (multi_gpu_test)
- (threadbuffer_performance)
- (transform_speed)
モジュール
- (engines)
- 3D 画像変換 (幾何学的変換) (3d_image_transforms) (10/15/2021)
- MedNIST データセットによる Autoencoder ネットワーク (autoencoder_mednist) (10/09/2021)
- (batch_output_transform)
- (compute_metric)
- CSV データセットで CSV ファイルのロード (csv_datasets) (10/20/2021)
- (decollate_batch)
- ImageDataset (image_dataset) (10/20/2021)
- (dynunet_tutorial)
- (integrate_3rd_party_transforms)
- (inverse transformations and test-time augmentations)
- 層単位の学習率設定 (layer wise learning rate) (10/12/2021)
- 最適な学習率 (learning rate finder) (10/13/2021)
- 医用画像のロード (load_medical_images) (10/21/2021)
- MedNIST で GAN (mednist_GAN_tutorial) (10/11/2021)
- GAN ワークフロー・エンジン (辞書版) (mednist_GAN_workflow_dict) (10/14/2021)
- GAN ワークフロー・エンジン (配列版) (mednist_GAN_workflow_array) (10/14/2021)
- (cross_validation_models_ensemble)
- Nifti 読み込み例 (nifti_read_example) (10/21/2021)
- (network_api)
- 脾臓セグメンテーション・タスクの後処理変換 (postprocessing_transforms) (10/17/2021)
- 公開データセットと新しいデータセットのクイックスタート (public_datasets) (11/05/2021)
- (tcia_csv_processing)
- 2D 画像変換デモ (transforms_demo_2d) (10/12/2021)
- (UNet_input_size_constrains)
- (TorchIO, MONAI, PyTorch Lightning)
- (varautoencoder_mednist)
- (interpretability)
- (Transfer learning with MMAR)
以上
MONAI 0.7 : tutorials : モジュール – 公開データセットと新しいデータセットのクイックスタート
MONAI 0.7 : tutorials : モジュール – 公開データセットと新しいデータセットのクイックスタート (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 11/05/2021 (0.7.0)
* 本ページは、MONAI の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。
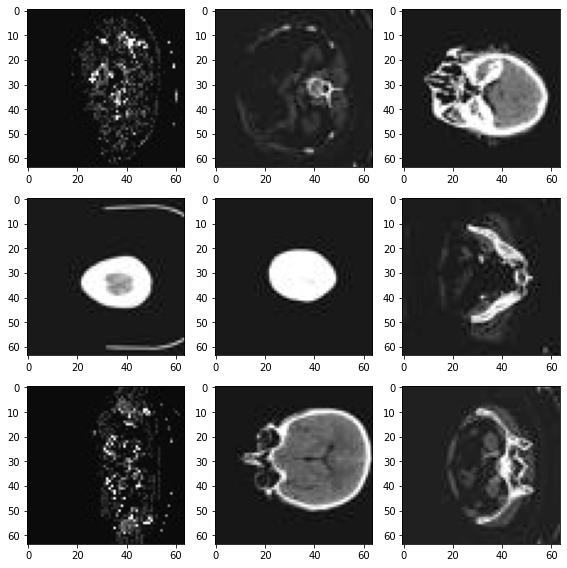
MONAI 0.7 : tutorials : モジュール – 公開データセットと新しいデータセットのクイックスタート
このノートブックは MedNISTDataset と DecathlonDataset に基づいた訓練ワークフローを素早くセットアップする方法と、新しいデータセットを作成する方法を示します。
このチュートリアルでは、MONAI 公開データセットでワークフローを素早くセットアップする方法と新しいデータセットを追加する方法を紹介します。現在、MONAI は MedNISTDataset と DecathlonDataset を提供していて、MedNIST と Decathlon データセットを自動的にダウンロードして抽出し、そして訓練/検証/テストデータを生成する PyTorch データセットとして機能します。
このチュートリアルでは以下のトピックをカバーします :
- MedNISTDataset による訓練実験とワークフローを作成する
- DecathlonDataset による訓練実験とワークフローを作成する
- 他の公開データを共有して MONAI でデータセットを追加する
環境のセットアップ
!python -c "import monai" || pip install -q "monai-weekly[nibabel, pillow, ignite, tqdm]"
!python -c "import matplotlib" || pip install -q matplotlib
%matplotlib inline
from monai.transforms import (
AddChanneld,
AsDiscreted,
Compose,
LoadImaged,
Orientationd,
Randomizable,
Resized,
ScaleIntensityd,
Spacingd,
EnsureTyped,
)
from monai.networks.nets import UNet, DenseNet121
from monai.networks.layers import Norm
from monai.losses import DiceLoss
from monai.inferers import SimpleInferer
from monai.handlers import MeanDice, StatsHandler, from_engine
from monai.engines import SupervisedTrainer
from monai.data import CacheDataset, DataLoader
from monai.config import print_config
from monai.apps import DecathlonDataset, MedNISTDataset, download_and_extract
import torch
import matplotlib.pyplot as plt
import ignite
import tempfile
import sys
import shutil
import os
import logging
インポートのセットアップ
# Copyright 2020 MONAI Consortium
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
# http://www.apache.org/licenses/LICENSE-2.0
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
print_config()
MONAI version: 0.6.0rc1+23.gc6793fd0
Numpy version: 1.20.3
Pytorch version: 1.9.0a0+c3d40fd
MONAI flags: HAS_EXT = True, USE_COMPILED = False
MONAI rev id: c6793fd0f316a448778d0047664aaf8c1895fe1c
Optional dependencies:
Pytorch Ignite version: 0.4.5
Nibabel version: 3.2.1
scikit-image version: 0.15.0
Pillow version: 7.0.0
Tensorboard version: 2.5.0
gdown version: 3.13.0
TorchVision version: 0.10.0a0
ITK version: 5.1.2
tqdm version: 4.53.0
lmdb version: 1.2.1
psutil version: 5.8.0
pandas version: 1.1.4
einops version: 0.3.0
For details about installing the optional dependencies, please visit:
https://docs.monai.io/en/latest/installation.html#installing-the-recommended-dependencies
データディレクトリのセットアップ
MONAI_DATA_DIRECTORY 環境変数でディレクトリを指定できます。これは結果をセーブしてダウンロードを再利用することを可能にします。指定されない場合、一時ディレクトリが使用されます。
directory = os.environ.get("MONAI_DATA_DIRECTORY")
root_dir = tempfile.mkdtemp() if directory is None else directory
print(root_dir)
/workspace/data/medical
ロギングのセットアップ
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
MedNISTDataset による訓練実験とワークフローを作成する
MedMNIST データセットは TCIA, RSNA Bone Age チャレンジ と NIH Chest X-ray データセット からの様々なセットから集められました。
前処理変換のセットアップ
transform = Compose(
[
LoadImaged(keys="image"),
AddChanneld(keys="image"),
ScaleIntensityd(keys="image"),
EnsureTyped(keys="image"),
]
)
訓練のために MedNISTDataset を作成する
MedNISTDataset は MONAI CacheDataset から継承して期待する動作を実現するために豊富なパラメータを提供しています :
- root_dir: MedNIST データセットをダウンロードしてロードするターゲットディレクトリ。
- section: 想定されるデータ・セクション、以下のいずれかです : training, validation or test.
- transform: 入力データ上で操作を実行する変換。デフォルト変換は LoadPNGd と AddChanneld から成り、これはデータを [C, H, W] shape を持つ numpy 配列にロードできます。
- download: リソース・リンクから MedNIST をダウンロードして抽出するか否か、デフォルトは False です。想定されるファイルが既に存在していれば、それが True に設定されていてもダウンロードはスキップします。ユーザは MedNIST.tar.gz ファイルか MedNIST フォルダをルートディレクトリに手動でコピーできます。
- seed: 訓練、検証とテストデータセットをランダムに分割するためのランダムシード、デフォルトは 0 です。
- val_frac: データセット全体の検証比率のパーセンテージ、デフォルトは 0.1 です。
- test_frac: データセット全体のテスト比率のパーセンテージ、デフォルトは 0.1 です。
- cache_num: キャッシュされる項目の数。デフォルトは sys.maxsize です。(cache_num, data_length x cache_rate, data_length) の最小値を取ります。
- cache_rate: トータルでキャッシュされるデータのパーセンテージで、デフォルトは 1.0 (cache all) です。(cache_num, data_length x cache_rate, data_length) の最小値を取ります。
- num_workers: 使用するワーカースレッドの数です。0 であればシングルスレッドが使用されます。デフォルトは 0 です。
“tar フアイル” は最初にダウンロードした後でキャッシュされることに注意してください。self.__getitem__() API は、self.__len__() 内の指定されたインデックスに従って 1 {“image”: XXX, “label”: XXX} 辞書を生成します。
train_ds = MedNISTDataset(
root_dir=root_dir, transform=transform, section="training", download=True)
# the dataset can work seamlessly with the pytorch native dataset loader,
# but using monai.data.DataLoader has additional benefits of mutli-process
# random seeds handling, and the customized collate functions
train_loader = DataLoader(train_ds, batch_size=300,
shuffle=True, num_workers=10)
Verified 'MedNIST.tar.gz', md5: 0bc7306e7427e00ad1c5526a6677552d. file /workspace/data/medical/MedNIST.tar.gz exists, skip downloading. extracted file /workspace/data/medical/MedNIST exists, skip extracting. 100%|██████████| 46946/46946 [00:27<00:00, 1684.89it/s]
可視化して確認するために MedNISTDataset から画像をピックアップする
plt.subplots(3, 3, figsize=(8, 8))
for i in range(9):
plt.subplot(3, 3, i + 1)
plt.imshow(train_ds[i * 5000]["image"][0].detach().cpu(), cmap="gray")
plt.tight_layout()
plt.show()
訓練コンポーネントの作成
device = torch.device("cuda:0")
net = DenseNet121(spatial_dims=2, in_channels=1, out_channels=6).to(device)
loss = torch.nn.CrossEntropyLoss()
opt = torch.optim.Adam(net.parameters(), 1e-5)
最も簡単な訓練ワークフローを定義して実行する
訓練ワークフローを素早くセットアップするために MONAI SupervisedTrainer ハンドラを使用します。
trainer = SupervisedTrainer(
device=device,
max_epochs=5,
train_data_loader=train_loader,
network=net,
optimizer=opt,
loss_function=loss,
inferer=SimpleInferer(),
key_train_metric={
"train_acc": ignite.metrics.Accuracy(
output_transform=from_engine(["pred", "label"]))
},
train_handlers=StatsHandler(
tag_name="train_loss", output_transform=from_engine(["loss"], first=True)),
)
trainer.run()
INFO:ignite.engine.engine.SupervisedTrainer:Engine run resuming from iteration 0, epoch 0 until 5 epochs INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 1/157 -- train_loss: 1.8252 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 2/157 -- train_loss: 1.7637 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 3/157 -- train_loss: 1.7338 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 4/157 -- train_loss: 1.7239 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 5/157 -- train_loss: 1.6950 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 6/157 -- train_loss: 1.6414 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 7/157 -- train_loss: 1.6280 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 8/157 -- train_loss: 1.6190 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 9/157 -- train_loss: 1.5820 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 10/157 -- train_loss: 1.5858 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 11/157 -- train_loss: 1.5342 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 12/157 -- train_loss: 1.4917 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 13/157 -- train_loss: 1.4970 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 14/157 -- train_loss: 1.4540 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 15/157 -- train_loss: 1.4422 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 16/157 -- train_loss: 1.4415 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 17/157 -- train_loss: 1.4168 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 18/157 -- train_loss: 1.4373 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 19/157 -- train_loss: 1.3618 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 20/157 -- train_loss: 1.3188 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 21/157 -- train_loss: 1.3052 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 22/157 -- train_loss: 1.3105 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 23/157 -- train_loss: 1.2936 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 24/157 -- train_loss: 1.2629 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 25/157 -- train_loss: 1.2414 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 26/157 -- train_loss: 1.2488 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 27/157 -- train_loss: 1.1862 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 28/157 -- train_loss: 1.1873 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 29/157 -- train_loss: 1.1685 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 30/157 -- train_loss: 1.1491 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 31/157 -- train_loss: 1.1658 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 32/157 -- train_loss: 1.1465 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 33/157 -- train_loss: 1.1273 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 34/157 -- train_loss: 1.1121 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 35/157 -- train_loss: 1.1016 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 36/157 -- train_loss: 1.0937 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 37/157 -- train_loss: 1.0664 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 38/157 -- train_loss: 1.0472 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 39/157 -- train_loss: 0.9981 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 40/157 -- train_loss: 0.9918 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 41/157 -- train_loss: 0.9644 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 42/157 -- train_loss: 0.9875 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 43/157 -- train_loss: 0.9691 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 44/157 -- train_loss: 0.9285 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 45/157 -- train_loss: 0.9872 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 46/157 -- train_loss: 0.9350 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 47/157 -- train_loss: 0.8944 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 48/157 -- train_loss: 0.9034 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 49/157 -- train_loss: 0.8550 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 50/157 -- train_loss: 0.8690 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 51/157 -- train_loss: 0.8494 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 52/157 -- train_loss: 0.8600 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 53/157 -- train_loss: 0.7888 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 54/157 -- train_loss: 0.8017 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 55/157 -- train_loss: 0.8211 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 56/157 -- train_loss: 0.8050 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 57/157 -- train_loss: 0.7900 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 58/157 -- train_loss: 0.7971 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 59/157 -- train_loss: 0.7693 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 60/157 -- train_loss: 0.7425 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 61/157 -- train_loss: 0.7386 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 62/157 -- train_loss: 0.7208 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 63/157 -- train_loss: 0.7203 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 64/157 -- train_loss: 0.7036 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 65/157 -- train_loss: 0.6863 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 66/157 -- train_loss: 0.6678 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 67/157 -- train_loss: 0.6729 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 68/157 -- train_loss: 0.6435 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 69/157 -- train_loss: 0.6373 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 70/157 -- train_loss: 0.6616 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 71/157 -- train_loss: 0.6325 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 72/157 -- train_loss: 0.6357 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 73/157 -- train_loss: 0.6333 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 74/157 -- train_loss: 0.5840 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 75/157 -- train_loss: 0.6075 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 76/157 -- train_loss: 0.5632 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 77/157 -- train_loss: 0.5624 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 78/157 -- train_loss: 0.5698 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 79/157 -- train_loss: 0.5504 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 80/157 -- train_loss: 0.5456 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 81/157 -- train_loss: 0.5512 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 82/157 -- train_loss: 0.5329 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 83/157 -- train_loss: 0.5306 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 84/157 -- train_loss: 0.5312 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 85/157 -- train_loss: 0.5226 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 86/157 -- train_loss: 0.5166 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 87/157 -- train_loss: 0.5152 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 88/157 -- train_loss: 0.4779 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 89/157 -- train_loss: 0.5044 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 90/157 -- train_loss: 0.5009 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 91/157 -- train_loss: 0.4685 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 92/157 -- train_loss: 0.4510 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 93/157 -- train_loss: 0.4815 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 94/157 -- train_loss: 0.4358 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 95/157 -- train_loss: 0.4570 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 96/157 -- train_loss: 0.4495 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 97/157 -- train_loss: 0.4120 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 98/157 -- train_loss: 0.4414 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 99/157 -- train_loss: 0.4252 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 100/157 -- train_loss: 0.4197 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 101/157 -- train_loss: 0.4312 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 102/157 -- train_loss: 0.4120 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 103/157 -- train_loss: 0.4054 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 104/157 -- train_loss: 0.4341 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 105/157 -- train_loss: 0.3731 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 106/157 -- train_loss: 0.3637 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 107/157 -- train_loss: 0.3850 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 108/157 -- train_loss: 0.3813 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 109/157 -- train_loss: 0.3464 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 110/157 -- train_loss: 0.3810 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 111/157 -- train_loss: 0.3641 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 112/157 -- train_loss: 0.3643 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 113/157 -- train_loss: 0.3592 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 114/157 -- train_loss: 0.3635 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 115/157 -- train_loss: 0.3190 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 116/157 -- train_loss: 0.3745 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 117/157 -- train_loss: 0.3255 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 118/157 -- train_loss: 0.3126 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 119/157 -- train_loss: 0.3331 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 120/157 -- train_loss: 0.3332 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 121/157 -- train_loss: 0.3412 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 122/157 -- train_loss: 0.2994 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 123/157 -- train_loss: 0.3147 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 124/157 -- train_loss: 0.3394 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 125/157 -- train_loss: 0.3133 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 126/157 -- train_loss: 0.3016 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 127/157 -- train_loss: 0.2861 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 128/157 -- train_loss: 0.2973 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 129/157 -- train_loss: 0.2843 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 130/157 -- train_loss: 0.2936 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 131/157 -- train_loss: 0.2902 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 132/157 -- train_loss: 0.2588 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 133/157 -- train_loss: 0.2815 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 134/157 -- train_loss: 0.2529 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 135/157 -- train_loss: 0.2647 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 136/157 -- train_loss: 0.2909 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 137/157 -- train_loss: 0.2883 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 138/157 -- train_loss: 0.3009 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 139/157 -- train_loss: 0.2295 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 140/157 -- train_loss: 0.2391 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 141/157 -- train_loss: 0.2902 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 142/157 -- train_loss: 0.2217 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 143/157 -- train_loss: 0.2387 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 144/157 -- train_loss: 0.2454 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 145/157 -- train_loss: 0.2214 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 146/157 -- train_loss: 0.2477 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 147/157 -- train_loss: 0.2534 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 148/157 -- train_loss: 0.2287 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 149/157 -- train_loss: 0.2381 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 150/157 -- train_loss: 0.2240 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 151/157 -- train_loss: 0.2288 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 152/157 -- train_loss: 0.2337 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 153/157 -- train_loss: 0.2109 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 154/157 -- train_loss: 0.2132 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 155/157 -- train_loss: 0.1772 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 156/157 -- train_loss: 0.2177 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 157/157 -- train_loss: 0.1833 INFO:ignite.engine.engine.SupervisedTrainer:Got new best metric of train_acc: 0.8910450304605291 INFO:ignite.engine.engine.SupervisedTrainer:Epoch[1] Metrics -- train_acc: 0.8910 INFO:ignite.engine.engine.SupervisedTrainer:Key metric: train_acc best value: 0.8910450304605291 at epoch: 1 INFO:ignite.engine.engine.SupervisedTrainer:Epoch[1] Complete. Time taken: 00:00:22 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 1/157 -- train_loss: 0.2187 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 2/157 -- train_loss: 0.1953 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 3/157 -- train_loss: 0.2099 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 4/157 -- train_loss: 0.1911 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 5/157 -- train_loss: 0.1970 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 6/157 -- train_loss: 0.1962 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 7/157 -- train_loss: 0.1935 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 8/157 -- train_loss: 0.2117 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 9/157 -- train_loss: 0.1942 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 10/157 -- train_loss: 0.2168 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 11/157 -- train_loss: 0.1968 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 12/157 -- train_loss: 0.1700 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 13/157 -- train_loss: 0.2183 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 14/157 -- train_loss: 0.2052 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 15/157 -- train_loss: 0.1826 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 16/157 -- train_loss: 0.1790 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 17/157 -- train_loss: 0.2115 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 18/157 -- train_loss: 0.1955 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 19/157 -- train_loss: 0.1888 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 20/157 -- train_loss: 0.1706 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 21/157 -- train_loss: 0.1812 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 22/157 -- train_loss: 0.1542 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 23/157 -- train_loss: 0.1554 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 24/157 -- train_loss: 0.1728 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 25/157 -- train_loss: 0.1681 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 26/157 -- train_loss: 0.1579 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 27/157 -- train_loss: 0.1803 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 28/157 -- train_loss: 0.1819 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 29/157 -- train_loss: 0.1789 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 30/157 -- train_loss: 0.1591 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 31/157 -- train_loss: 0.1464 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 32/157 -- train_loss: 0.1687 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 33/157 -- train_loss: 0.1740 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 34/157 -- train_loss: 0.1438 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 35/157 -- train_loss: 0.1432 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 36/157 -- train_loss: 0.1790 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 37/157 -- train_loss: 0.1615 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 38/157 -- train_loss: 0.1457 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 39/157 -- train_loss: 0.1639 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 40/157 -- train_loss: 0.1887 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 41/157 -- train_loss: 0.1642 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 42/157 -- train_loss: 0.1487 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 43/157 -- train_loss: 0.1519 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 44/157 -- train_loss: 0.1506 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 45/157 -- train_loss: 0.1562 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 46/157 -- train_loss: 0.1436 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 47/157 -- train_loss: 0.1527 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 48/157 -- train_loss: 0.1184 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 49/157 -- train_loss: 0.1562 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 50/157 -- train_loss: 0.1344 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 51/157 -- train_loss: 0.1734 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 52/157 -- train_loss: 0.1416 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 53/157 -- train_loss: 0.1601 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 54/157 -- train_loss: 0.1302 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 55/157 -- train_loss: 0.1560 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 56/157 -- train_loss: 0.1393 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 57/157 -- train_loss: 0.1624 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 58/157 -- train_loss: 0.1227 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 59/157 -- train_loss: 0.1354 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 60/157 -- train_loss: 0.1270 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 61/157 -- train_loss: 0.1595 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 62/157 -- train_loss: 0.1158 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 63/157 -- train_loss: 0.1426 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 64/157 -- train_loss: 0.1158 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 65/157 -- train_loss: 0.1218 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 66/157 -- train_loss: 0.1408 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 67/157 -- train_loss: 0.1318 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 68/157 -- train_loss: 0.1169 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 69/157 -- train_loss: 0.1218 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 70/157 -- train_loss: 0.1448 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 71/157 -- train_loss: 0.1177 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 72/157 -- train_loss: 0.1105 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 73/157 -- train_loss: 0.1308 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 74/157 -- train_loss: 0.1065 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 75/157 -- train_loss: 0.1464 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 76/157 -- train_loss: 0.1296 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 77/157 -- train_loss: 0.1276 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 78/157 -- train_loss: 0.1239 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 79/157 -- train_loss: 0.1269 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 80/157 -- train_loss: 0.1382 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 81/157 -- train_loss: 0.1123 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 82/157 -- train_loss: 0.1223 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 83/157 -- train_loss: 0.1120 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 84/157 -- train_loss: 0.1225 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 85/157 -- train_loss: 0.1137 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 86/157 -- train_loss: 0.1216 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 87/157 -- train_loss: 0.1397 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 88/157 -- train_loss: 0.1087 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 89/157 -- train_loss: 0.1158 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 90/157 -- train_loss: 0.1171 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 91/157 -- train_loss: 0.1165 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 92/157 -- train_loss: 0.1073 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 93/157 -- train_loss: 0.1082 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 94/157 -- train_loss: 0.1055 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 95/157 -- train_loss: 0.1054 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 96/157 -- train_loss: 0.0869 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 97/157 -- train_loss: 0.1184 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 98/157 -- train_loss: 0.1490 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 99/157 -- train_loss: 0.1033 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 100/157 -- train_loss: 0.0991 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 101/157 -- train_loss: 0.1009 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 102/157 -- train_loss: 0.1224 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 103/157 -- train_loss: 0.1098 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 104/157 -- train_loss: 0.0965 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 105/157 -- train_loss: 0.1097 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 106/157 -- train_loss: 0.1287 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 107/157 -- train_loss: 0.1126 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 108/157 -- train_loss: 0.1096 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 109/157 -- train_loss: 0.1235 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 110/157 -- train_loss: 0.0929 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 111/157 -- train_loss: 0.0996 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 112/157 -- train_loss: 0.0982 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 113/157 -- train_loss: 0.0942 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 114/157 -- train_loss: 0.1076 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 115/157 -- train_loss: 0.0978 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 116/157 -- train_loss: 0.1017 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 117/157 -- train_loss: 0.0882 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 118/157 -- train_loss: 0.1133 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 119/157 -- train_loss: 0.0938 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 120/157 -- train_loss: 0.0902 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 121/157 -- train_loss: 0.1098 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 122/157 -- train_loss: 0.0852 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 123/157 -- train_loss: 0.0835 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 124/157 -- train_loss: 0.0857 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 125/157 -- train_loss: 0.0822 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 126/157 -- train_loss: 0.0956 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 127/157 -- train_loss: 0.0966 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 128/157 -- train_loss: 0.1105 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 129/157 -- train_loss: 0.0925 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 130/157 -- train_loss: 0.0875 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 131/157 -- train_loss: 0.0856 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 132/157 -- train_loss: 0.0854 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 133/157 -- train_loss: 0.0728 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 134/157 -- train_loss: 0.0928 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 135/157 -- train_loss: 0.0884 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 136/157 -- train_loss: 0.1160 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 137/157 -- train_loss: 0.0679 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 138/157 -- train_loss: 0.1008 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 139/157 -- train_loss: 0.0959 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 140/157 -- train_loss: 0.0868 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 141/157 -- train_loss: 0.0797 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 142/157 -- train_loss: 0.0869 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 143/157 -- train_loss: 0.0884 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 144/157 -- train_loss: 0.0675 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 145/157 -- train_loss: 0.0856 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 146/157 -- train_loss: 0.1024 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 147/157 -- train_loss: 0.0965 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 148/157 -- train_loss: 0.0864 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 149/157 -- train_loss: 0.0700 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 150/157 -- train_loss: 0.0698 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 151/157 -- train_loss: 0.0871 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 152/157 -- train_loss: 0.0680 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 153/157 -- train_loss: 0.0719 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 154/157 -- train_loss: 0.0706 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 155/157 -- train_loss: 0.0620 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 156/157 -- train_loss: 0.0814 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 157/157 -- train_loss: 0.0689 INFO:ignite.engine.engine.SupervisedTrainer:Got new best metric of train_acc: 0.9833425637967026 INFO:ignite.engine.engine.SupervisedTrainer:Epoch[2] Metrics -- train_acc: 0.9833 INFO:ignite.engine.engine.SupervisedTrainer:Key metric: train_acc best value: 0.9833425637967026 at epoch: 2 INFO:ignite.engine.engine.SupervisedTrainer:Epoch[2] Complete. Time taken: 00:00:23 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 1/157 -- train_loss: 0.0757 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 2/157 -- train_loss: 0.0663 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 3/157 -- train_loss: 0.0792 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 4/157 -- train_loss: 0.0586 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 5/157 -- train_loss: 0.0749 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 6/157 -- train_loss: 0.0906 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 7/157 -- train_loss: 0.0684 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 8/157 -- train_loss: 0.0677 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 9/157 -- train_loss: 0.0870 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 10/157 -- train_loss: 0.0835 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 11/157 -- train_loss: 0.0652 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 12/157 -- train_loss: 0.0805 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 13/157 -- train_loss: 0.0663 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 14/157 -- train_loss: 0.0744 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 15/157 -- train_loss: 0.0653 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 16/157 -- train_loss: 0.0717 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 17/157 -- train_loss: 0.0520 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 18/157 -- train_loss: 0.0743 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 19/157 -- train_loss: 0.0975 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 20/157 -- train_loss: 0.0981 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 21/157 -- train_loss: 0.0632 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 22/157 -- train_loss: 0.0904 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 23/157 -- train_loss: 0.0762 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 24/157 -- train_loss: 0.0700 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 25/157 -- train_loss: 0.0915 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 26/157 -- train_loss: 0.1116 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 27/157 -- train_loss: 0.0731 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 28/157 -- train_loss: 0.0694 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 29/157 -- train_loss: 0.0657 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 30/157 -- train_loss: 0.0826 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 31/157 -- train_loss: 0.0822 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 32/157 -- train_loss: 0.0687 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 33/157 -- train_loss: 0.0553 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 34/157 -- train_loss: 0.0591 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 35/157 -- train_loss: 0.0676 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 36/157 -- train_loss: 0.0588 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 37/157 -- train_loss: 0.0668 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 38/157 -- train_loss: 0.0736 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 39/157 -- train_loss: 0.0560 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 40/157 -- train_loss: 0.0557 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 41/157 -- train_loss: 0.0574 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 42/157 -- train_loss: 0.0946 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 43/157 -- train_loss: 0.0600 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 44/157 -- train_loss: 0.0700 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 45/157 -- train_loss: 0.0600 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 46/157 -- train_loss: 0.0573 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 47/157 -- train_loss: 0.0596 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 48/157 -- train_loss: 0.0803 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 49/157 -- train_loss: 0.0676 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 50/157 -- train_loss: 0.0669 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 51/157 -- train_loss: 0.0731 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 52/157 -- train_loss: 0.0735 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 53/157 -- train_loss: 0.0578 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 54/157 -- train_loss: 0.0675 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 55/157 -- train_loss: 0.0642 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 56/157 -- train_loss: 0.0646 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 57/157 -- train_loss: 0.0613 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 58/157 -- train_loss: 0.0472 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 59/157 -- train_loss: 0.0723 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 60/157 -- train_loss: 0.0661 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 61/157 -- train_loss: 0.0651 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 62/157 -- train_loss: 0.0490 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 63/157 -- train_loss: 0.0557 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 64/157 -- train_loss: 0.0714 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 65/157 -- train_loss: 0.0462 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 66/157 -- train_loss: 0.0475 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 67/157 -- train_loss: 0.0600 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 68/157 -- train_loss: 0.0479 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 69/157 -- train_loss: 0.0484 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 70/157 -- train_loss: 0.0610 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 71/157 -- train_loss: 0.0740 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 72/157 -- train_loss: 0.0574 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 73/157 -- train_loss: 0.0637 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 74/157 -- train_loss: 0.0448 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 75/157 -- train_loss: 0.0600 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 76/157 -- train_loss: 0.0663 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 77/157 -- train_loss: 0.0511 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 78/157 -- train_loss: 0.0641 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 79/157 -- train_loss: 0.0644 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 80/157 -- train_loss: 0.0644 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 81/157 -- train_loss: 0.0608 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 82/157 -- train_loss: 0.0516 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 83/157 -- train_loss: 0.0659 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 84/157 -- train_loss: 0.0429 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 85/157 -- train_loss: 0.0508 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 86/157 -- train_loss: 0.0713 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 87/157 -- train_loss: 0.0608 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 88/157 -- train_loss: 0.0534 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 89/157 -- train_loss: 0.0461 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 90/157 -- train_loss: 0.0522 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 91/157 -- train_loss: 0.0565 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 92/157 -- train_loss: 0.0464 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 93/157 -- train_loss: 0.0716 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 94/157 -- train_loss: 0.0456 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 95/157 -- train_loss: 0.0469 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 96/157 -- train_loss: 0.0645 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 97/157 -- train_loss: 0.0618 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 98/157 -- train_loss: 0.0767 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 99/157 -- train_loss: 0.0418 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 100/157 -- train_loss: 0.0559 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 101/157 -- train_loss: 0.0430 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 102/157 -- train_loss: 0.0373 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 103/157 -- train_loss: 0.0594 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 104/157 -- train_loss: 0.0677 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 105/157 -- train_loss: 0.0366 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 106/157 -- train_loss: 0.0457 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 107/157 -- train_loss: 0.0385 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 108/157 -- train_loss: 0.0568 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 109/157 -- train_loss: 0.0623 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 110/157 -- train_loss: 0.0580 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 111/157 -- train_loss: 0.0548 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 112/157 -- train_loss: 0.0379 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 113/157 -- train_loss: 0.0395 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 114/157 -- train_loss: 0.0444 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 115/157 -- train_loss: 0.0362 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 116/157 -- train_loss: 0.0416 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 117/157 -- train_loss: 0.0429 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 118/157 -- train_loss: 0.0332 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 119/157 -- train_loss: 0.0452 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 120/157 -- train_loss: 0.0638 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 121/157 -- train_loss: 0.0389 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 122/157 -- train_loss: 0.0532 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 123/157 -- train_loss: 0.0561 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 124/157 -- train_loss: 0.0622 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 125/157 -- train_loss: 0.0387 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 126/157 -- train_loss: 0.0620 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 127/157 -- train_loss: 0.0426 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 128/157 -- train_loss: 0.0361 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 129/157 -- train_loss: 0.0439 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 130/157 -- train_loss: 0.0472 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 131/157 -- train_loss: 0.0363 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 132/157 -- train_loss: 0.0461 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 133/157 -- train_loss: 0.0365 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 134/157 -- train_loss: 0.0414 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 135/157 -- train_loss: 0.0546 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 136/157 -- train_loss: 0.0396 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 137/157 -- train_loss: 0.0347 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 138/157 -- train_loss: 0.0411 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 139/157 -- train_loss: 0.0563 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 140/157 -- train_loss: 0.0579 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 141/157 -- train_loss: 0.0415 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 142/157 -- train_loss: 0.0435 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 143/157 -- train_loss: 0.0674 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 144/157 -- train_loss: 0.0372 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 145/157 -- train_loss: 0.0447 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 146/157 -- train_loss: 0.0427 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 147/157 -- train_loss: 0.0406 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 148/157 -- train_loss: 0.0423 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 149/157 -- train_loss: 0.0391 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 150/157 -- train_loss: 0.0345 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 151/157 -- train_loss: 0.0534 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 152/157 -- train_loss: 0.0304 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 153/157 -- train_loss: 0.0364 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 154/157 -- train_loss: 0.0612 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 155/157 -- train_loss: 0.0383 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 156/157 -- train_loss: 0.0389 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 157/157 -- train_loss: 0.0441 INFO:ignite.engine.engine.SupervisedTrainer:Got new best metric of train_acc: 0.9922464107698207 INFO:ignite.engine.engine.SupervisedTrainer:Epoch[3] Metrics -- train_acc: 0.9922 INFO:ignite.engine.engine.SupervisedTrainer:Key metric: train_acc best value: 0.9922464107698207 at epoch: 3 INFO:ignite.engine.engine.SupervisedTrainer:Epoch[3] Complete. Time taken: 00:00:23 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 1/157 -- train_loss: 0.0391 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 2/157 -- train_loss: 0.0445 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 3/157 -- train_loss: 0.0479 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 4/157 -- train_loss: 0.0516 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 5/157 -- train_loss: 0.0459 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 6/157 -- train_loss: 0.0306 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 7/157 -- train_loss: 0.0654 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 8/157 -- train_loss: 0.0536 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 9/157 -- train_loss: 0.0547 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 10/157 -- train_loss: 0.0461 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 11/157 -- train_loss: 0.0283 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 12/157 -- train_loss: 0.0377 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 13/157 -- train_loss: 0.0543 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 14/157 -- train_loss: 0.0476 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 15/157 -- train_loss: 0.0265 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 16/157 -- train_loss: 0.0320 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 17/157 -- train_loss: 0.0531 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 18/157 -- train_loss: 0.0324 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 19/157 -- train_loss: 0.0416 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 20/157 -- train_loss: 0.0318 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 21/157 -- train_loss: 0.0399 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 22/157 -- train_loss: 0.0348 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 23/157 -- train_loss: 0.0313 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 24/157 -- train_loss: 0.0442 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 25/157 -- train_loss: 0.0339 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 26/157 -- train_loss: 0.0383 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 27/157 -- train_loss: 0.0463 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 28/157 -- train_loss: 0.0483 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 29/157 -- train_loss: 0.0471 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 30/157 -- train_loss: 0.0477 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 31/157 -- train_loss: 0.0327 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 32/157 -- train_loss: 0.0444 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 33/157 -- train_loss: 0.0424 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 34/157 -- train_loss: 0.0361 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 35/157 -- train_loss: 0.0399 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 36/157 -- train_loss: 0.0337 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 37/157 -- train_loss: 0.0505 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 38/157 -- train_loss: 0.0297 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 39/157 -- train_loss: 0.0241 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 40/157 -- train_loss: 0.0298 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 41/157 -- train_loss: 0.0579 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 42/157 -- train_loss: 0.0244 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 43/157 -- train_loss: 0.0372 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 44/157 -- train_loss: 0.0493 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 45/157 -- train_loss: 0.0465 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 46/157 -- train_loss: 0.0396 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 47/157 -- train_loss: 0.0517 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 48/157 -- train_loss: 0.0388 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 49/157 -- train_loss: 0.0513 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 50/157 -- train_loss: 0.0411 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 51/157 -- train_loss: 0.0274 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 52/157 -- train_loss: 0.0413 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 53/157 -- train_loss: 0.0366 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 54/157 -- train_loss: 0.0321 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 55/157 -- train_loss: 0.0336 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 56/157 -- train_loss: 0.0469 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 57/157 -- train_loss: 0.0430 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 58/157 -- train_loss: 0.0381 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 59/157 -- train_loss: 0.0321 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 60/157 -- train_loss: 0.0414 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 61/157 -- train_loss: 0.0393 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 62/157 -- train_loss: 0.0410 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 63/157 -- train_loss: 0.0292 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 64/157 -- train_loss: 0.0327 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 65/157 -- train_loss: 0.0270 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 66/157 -- train_loss: 0.0320 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 67/157 -- train_loss: 0.0384 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 68/157 -- train_loss: 0.0270 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 69/157 -- train_loss: 0.0411 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 70/157 -- train_loss: 0.0295 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 71/157 -- train_loss: 0.0388 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 72/157 -- train_loss: 0.0290 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 73/157 -- train_loss: 0.0374 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 74/157 -- train_loss: 0.0511 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 75/157 -- train_loss: 0.0455 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 76/157 -- train_loss: 0.0369 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 77/157 -- train_loss: 0.0359 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 78/157 -- train_loss: 0.0416 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 79/157 -- train_loss: 0.0287 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 80/157 -- train_loss: 0.0357 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 81/157 -- train_loss: 0.0333 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 82/157 -- train_loss: 0.0307 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 83/157 -- train_loss: 0.0355 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 84/157 -- train_loss: 0.0364 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 85/157 -- train_loss: 0.0355 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 86/157 -- train_loss: 0.0336 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 87/157 -- train_loss: 0.0302 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 88/157 -- train_loss: 0.0312 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 89/157 -- train_loss: 0.0238 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 90/157 -- train_loss: 0.0235 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 91/157 -- train_loss: 0.0381 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 92/157 -- train_loss: 0.0218 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 93/157 -- train_loss: 0.0404 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 94/157 -- train_loss: 0.0338 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 95/157 -- train_loss: 0.0236 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 96/157 -- train_loss: 0.0356 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 97/157 -- train_loss: 0.0354 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 98/157 -- train_loss: 0.0321 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 99/157 -- train_loss: 0.0340 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 100/157 -- train_loss: 0.0281 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 101/157 -- train_loss: 0.0402 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 102/157 -- train_loss: 0.0439 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 103/157 -- train_loss: 0.0291 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 104/157 -- train_loss: 0.0262 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 105/157 -- train_loss: 0.0255 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 106/157 -- train_loss: 0.0483 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 107/157 -- train_loss: 0.0235 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 108/157 -- train_loss: 0.0342 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 109/157 -- train_loss: 0.0294 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 110/157 -- train_loss: 0.0316 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 111/157 -- train_loss: 0.0318 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 112/157 -- train_loss: 0.0307 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 113/157 -- train_loss: 0.0303 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 114/157 -- train_loss: 0.0298 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 115/157 -- train_loss: 0.0254 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 116/157 -- train_loss: 0.0207 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 117/157 -- train_loss: 0.0212 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 118/157 -- train_loss: 0.0233 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 119/157 -- train_loss: 0.0296 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 120/157 -- train_loss: 0.0286 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 121/157 -- train_loss: 0.0424 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 122/157 -- train_loss: 0.0263 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 123/157 -- train_loss: 0.0291 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 124/157 -- train_loss: 0.0218 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 125/157 -- train_loss: 0.0293 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 126/157 -- train_loss: 0.0395 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 127/157 -- train_loss: 0.0274 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 128/157 -- train_loss: 0.0302 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 129/157 -- train_loss: 0.0240 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 130/157 -- train_loss: 0.0281 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 131/157 -- train_loss: 0.0172 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 132/157 -- train_loss: 0.0321 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 133/157 -- train_loss: 0.0272 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 134/157 -- train_loss: 0.0163 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 135/157 -- train_loss: 0.0419 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 136/157 -- train_loss: 0.0296 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 137/157 -- train_loss: 0.0374 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 138/157 -- train_loss: 0.0451 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 139/157 -- train_loss: 0.0190 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 140/157 -- train_loss: 0.0241 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 141/157 -- train_loss: 0.0219 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 142/157 -- train_loss: 0.0354 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 143/157 -- train_loss: 0.0297 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 144/157 -- train_loss: 0.0222 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 145/157 -- train_loss: 0.0282 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 146/157 -- train_loss: 0.0288 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 147/157 -- train_loss: 0.0236 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 148/157 -- train_loss: 0.0301 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 149/157 -- train_loss: 0.0240 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 150/157 -- train_loss: 0.0291 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 151/157 -- train_loss: 0.0379 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 152/157 -- train_loss: 0.0239 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 153/157 -- train_loss: 0.0225 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 154/157 -- train_loss: 0.0254 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 155/157 -- train_loss: 0.0185 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 156/157 -- train_loss: 0.0252 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 157/157 -- train_loss: 0.0317 INFO:ignite.engine.engine.SupervisedTrainer:Got new best metric of train_acc: 0.9951433561964811 INFO:ignite.engine.engine.SupervisedTrainer:Epoch[4] Metrics -- train_acc: 0.9951 INFO:ignite.engine.engine.SupervisedTrainer:Key metric: train_acc best value: 0.9951433561964811 at epoch: 4 INFO:ignite.engine.engine.SupervisedTrainer:Epoch[4] Complete. Time taken: 00:00:23 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 1/157 -- train_loss: 0.0224 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 2/157 -- train_loss: 0.0260 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 3/157 -- train_loss: 0.0490 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 4/157 -- train_loss: 0.0172 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 5/157 -- train_loss: 0.0202 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 6/157 -- train_loss: 0.0324 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 7/157 -- train_loss: 0.0305 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 8/157 -- train_loss: 0.0186 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 9/157 -- train_loss: 0.0262 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 10/157 -- train_loss: 0.0171 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 11/157 -- train_loss: 0.0207 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 12/157 -- train_loss: 0.0129 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 13/157 -- train_loss: 0.0281 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 14/157 -- train_loss: 0.0236 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 15/157 -- train_loss: 0.0233 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 16/157 -- train_loss: 0.0265 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 17/157 -- train_loss: 0.0257 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 18/157 -- train_loss: 0.0246 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 19/157 -- train_loss: 0.0229 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 20/157 -- train_loss: 0.0194 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 21/157 -- train_loss: 0.0141 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 22/157 -- train_loss: 0.0279 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 23/157 -- train_loss: 0.0380 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 24/157 -- train_loss: 0.0220 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 25/157 -- train_loss: 0.0164 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 26/157 -- train_loss: 0.0230 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 27/157 -- train_loss: 0.0185 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 28/157 -- train_loss: 0.0323 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 29/157 -- train_loss: 0.0307 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 30/157 -- train_loss: 0.0435 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 31/157 -- train_loss: 0.0355 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 32/157 -- train_loss: 0.0288 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 33/157 -- train_loss: 0.0358 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 34/157 -- train_loss: 0.0286 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 35/157 -- train_loss: 0.0164 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 36/157 -- train_loss: 0.0358 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 37/157 -- train_loss: 0.0260 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 38/157 -- train_loss: 0.0189 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 39/157 -- train_loss: 0.0420 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 40/157 -- train_loss: 0.0239 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 41/157 -- train_loss: 0.0363 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 42/157 -- train_loss: 0.0280 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 43/157 -- train_loss: 0.0262 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 44/157 -- train_loss: 0.0288 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 45/157 -- train_loss: 0.0512 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 46/157 -- train_loss: 0.0249 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 47/157 -- train_loss: 0.0244 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 48/157 -- train_loss: 0.0218 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 49/157 -- train_loss: 0.0194 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 50/157 -- train_loss: 0.0209 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 51/157 -- train_loss: 0.0280 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 52/157 -- train_loss: 0.0287 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 53/157 -- train_loss: 0.0250 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 54/157 -- train_loss: 0.0183 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 55/157 -- train_loss: 0.0156 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 56/157 -- train_loss: 0.0171 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 57/157 -- train_loss: 0.0230 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 58/157 -- train_loss: 0.0166 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 59/157 -- train_loss: 0.0224 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 60/157 -- train_loss: 0.0192 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 61/157 -- train_loss: 0.0333 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 62/157 -- train_loss: 0.0315 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 63/157 -- train_loss: 0.0229 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 64/157 -- train_loss: 0.0155 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 65/157 -- train_loss: 0.0307 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 66/157 -- train_loss: 0.0289 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 67/157 -- train_loss: 0.0233 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 68/157 -- train_loss: 0.0293 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 69/157 -- train_loss: 0.0194 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 70/157 -- train_loss: 0.0206 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 71/157 -- train_loss: 0.0259 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 72/157 -- train_loss: 0.0241 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 73/157 -- train_loss: 0.0561 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 74/157 -- train_loss: 0.0294 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 75/157 -- train_loss: 0.0353 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 76/157 -- train_loss: 0.0126 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 77/157 -- train_loss: 0.0128 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 78/157 -- train_loss: 0.0187 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 79/157 -- train_loss: 0.0310 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 80/157 -- train_loss: 0.0166 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 81/157 -- train_loss: 0.0184 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 82/157 -- train_loss: 0.0288 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 83/157 -- train_loss: 0.0189 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 84/157 -- train_loss: 0.0292 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 85/157 -- train_loss: 0.0161 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 86/157 -- train_loss: 0.0167 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 87/157 -- train_loss: 0.0239 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 88/157 -- train_loss: 0.0185 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 89/157 -- train_loss: 0.0161 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 90/157 -- train_loss: 0.0214 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 91/157 -- train_loss: 0.0251 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 92/157 -- train_loss: 0.0332 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 93/157 -- train_loss: 0.0324 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 94/157 -- train_loss: 0.0172 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 95/157 -- train_loss: 0.0178 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 96/157 -- train_loss: 0.0195 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 97/157 -- train_loss: 0.0441 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 98/157 -- train_loss: 0.0202 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 99/157 -- train_loss: 0.0158 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 100/157 -- train_loss: 0.0134 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 101/157 -- train_loss: 0.0196 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 102/157 -- train_loss: 0.0286 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 103/157 -- train_loss: 0.0247 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 104/157 -- train_loss: 0.0245 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 105/157 -- train_loss: 0.0146 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 106/157 -- train_loss: 0.0165 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 107/157 -- train_loss: 0.0156 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 108/157 -- train_loss: 0.0221 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 109/157 -- train_loss: 0.0239 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 110/157 -- train_loss: 0.0198 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 111/157 -- train_loss: 0.0227 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 112/157 -- train_loss: 0.0125 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 113/157 -- train_loss: 0.0236 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 114/157 -- train_loss: 0.0132 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 115/157 -- train_loss: 0.0209 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 116/157 -- train_loss: 0.0190 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 117/157 -- train_loss: 0.0330 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 118/157 -- train_loss: 0.0175 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 119/157 -- train_loss: 0.0316 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 120/157 -- train_loss: 0.0182 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 121/157 -- train_loss: 0.0197 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 122/157 -- train_loss: 0.0214 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 123/157 -- train_loss: 0.0177 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 124/157 -- train_loss: 0.0173 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 125/157 -- train_loss: 0.0298 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 126/157 -- train_loss: 0.0126 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 127/157 -- train_loss: 0.0141 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 128/157 -- train_loss: 0.0275 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 129/157 -- train_loss: 0.0158 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 130/157 -- train_loss: 0.0203 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 131/157 -- train_loss: 0.0123 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 132/157 -- train_loss: 0.0263 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 133/157 -- train_loss: 0.0141 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 134/157 -- train_loss: 0.0117 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 135/157 -- train_loss: 0.0192 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 136/157 -- train_loss: 0.0240 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 137/157 -- train_loss: 0.0187 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 138/157 -- train_loss: 0.0209 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 139/157 -- train_loss: 0.0224 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 140/157 -- train_loss: 0.0154 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 141/157 -- train_loss: 0.0277 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 142/157 -- train_loss: 0.0274 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 143/157 -- train_loss: 0.0243 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 144/157 -- train_loss: 0.0132 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 145/157 -- train_loss: 0.0158 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 146/157 -- train_loss: 0.0138 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 147/157 -- train_loss: 0.0167 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 148/157 -- train_loss: 0.0135 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 149/157 -- train_loss: 0.0240 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 150/157 -- train_loss: 0.0194 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 151/157 -- train_loss: 0.0225 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 152/157 -- train_loss: 0.0229 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 153/157 -- train_loss: 0.0226 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 154/157 -- train_loss: 0.0224 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 155/157 -- train_loss: 0.0127 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 156/157 -- train_loss: 0.0165 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 157/157 -- train_loss: 0.0191 INFO:ignite.engine.engine.SupervisedTrainer:Got new best metric of train_acc: 0.9965918289098112 INFO:ignite.engine.engine.SupervisedTrainer:Epoch[5] Metrics -- train_acc: 0.9966 INFO:ignite.engine.engine.SupervisedTrainer:Key metric: train_acc best value: 0.9965918289098112 at epoch: 5 INFO:ignite.engine.engine.SupervisedTrainer:Epoch[5] Complete. Time taken: 00:00:22 INFO:ignite.engine.engine.SupervisedTrainer:Engine run complete. Time taken: 00:01:54
DecathlonDataset による訓練実験とワークフロー
Decathlon データセットは Medical Segmentation Decathlon AI challenge に由来します。
前処理変換のセットアップ
transform = Compose(
[
LoadImaged(keys=["image", "label"]),
AddChanneld(keys=["image", "label"]),
Spacingd(keys=["image", "label"], pixdim=(
1.0, 1.0, 1.0), mode=("bilinear", "nearest")),
Orientationd(keys=["image", "label"], axcodes="RAS"),
ScaleIntensityd(keys="image"),
Resized(keys=["image", "label"], spatial_size=(
32, 64, 32), mode=("trilinear", "nearest")),
EnsureTyped(keys=["image", "label"]),
]
)
訓練のために DeccathlonDataset を作成する
DecathlonDataset は MONAI CacheDataset から継承して期待する動作を実現するために豊富なパラメータを提供しています :
- root_dir: MSD データセットをキャッシュしてロードするためのユーザのローカルディレクトリ。
- task: どのタスクをダウンロードして実行するか : 次のリストの一つです (“Task01_BrainTumour”, “Task02_Heart”, “Task03_Liver”, “Task04_Hippocampus”, “Task05_Prostate”, “Task06_Lung”, “Task07_Pancreas”, “Task08_HepaticVessel”, “Task09_Spleen”, “Task10_Colon”).
- section: 想定されるデータ・セクション、以下のいずれかです : training, validation or test.
- transform: 入力データ上で操作を実行する変換。デフォルト変換は LoadPNGd と AddChanneld から成り、これはデータを [C, H, W, D] shape を持つ numpy 配列にロードできます。
- download: リソース・リンクから Decathlon をダウンロードして抽出するか否か、デフォルトは False です。想定されるファイルが既に存在していれば、それが True に設定されていてもダウンロードはスキップします。ユーザは tar ファイルか dataset フォルダをルートディレクトリに手動でコピーできます。
- seed: 訓練、検証とテストデータセットをランダムに分割するためのランダムシード、デフォルトは 0 です。
- val_frac: 訓練セクションからの検証比率のパーセンテージで、デフォルトは 0.2 です。Decathlon データはラベルを持つ訓練セクションとラベルなしのテストセクションだけを含みますので、検証セクションとして訓練セクションからランダムに一部を選択します。
- cache_num: キャッシュされる項目の数。デフォルトは sys.maxsize です。(cache_num, data_length x cache_rate, data_length) の最小値を取ります。
- cache_rate: トータルでキャッシュされるデータのパーセンテージで、デフォルトは 1.0 (cache all) です。(cache_num, data_length x cache_rate, data_length) の最小値を取ります。
- num_workers: 使用するワーカースレッドの数です。0 であればシングルスレッドが使用されます。デフォルトは 0 です。
“tar フアイル” は最初にダウンロードした後でキャッシュされることに注意してください。self.__getitem__() API は、self.__len__() 内の指定されたインデックスに従って 1 {“image”: XXX, “label”: XXX} 辞書を生成します。
train_ds = DecathlonDataset(
root_dir=root_dir,
task="Task04_Hippocampus",
transform=transform,
section="training",
download=True,
)
# the dataset can work seamlessly with the pytorch native dataset loader,
# but using monai.data.DataLoader has additional benefits of mutli-process
# random seeds handling, and the customized collate functions
train_loader = DataLoader(train_ds, batch_size=32,
shuffle=True, num_workers=16)
Task04_Hippocampus.tar: 100%|██████████| 27.1M/27.1M [01:15<00:00, 377kB/s] Verified 'Task04_Hippocampus.tar.part', md5: 9d24dba78a72977dbd1d2e110310f31b. Verified 'Task04_Hippocampus.tar', md5: 9d24dba78a72977dbd1d2e110310f31b. Verified 'Task04_Hippocampus.tar', md5: 9d24dba78a72977dbd1d2e110310f31b. 0%| | 0/208 [00:00<?, ?it/s]Default upsampling behavior when mode=trilinear is changed to align_corners=False since 0.4.0. Please specify align_corners=True if the old behavior is desired. See the documentation of nn.Upsample for details. 100%|██████████| 208/208 [00:34<00:00, 6.03it/s]
可視化して確認するために DecathlonDataset から画像をピックアップする
plt.subplots(3, 3, figsize=(8, 8))
for i in range(9):
plt.subplot(3, 3, i + 1)
plt.imshow(train_ds[i * 20]["image"]
[0, :, :, 10].detach().cpu(), cmap="gray")
plt.tight_layout()
plt.show()
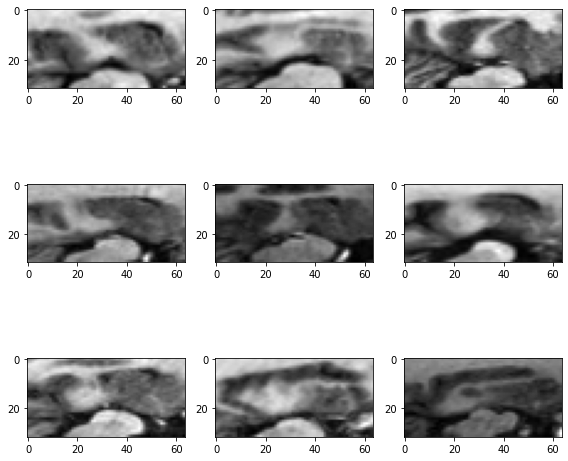
訓練コンポーネントの作成
device = torch.device("cuda:0")
net = UNet(
spatial_dims=3,
in_channels=1,
out_channels=3,
channels=(16, 32, 64, 128, 256),
strides=(2, 2, 2, 2),
num_res_units=2,
norm=Norm.BATCH,
).to(device)
loss = DiceLoss(to_onehot_y=True, softmax=True)
opt = torch.optim.Adam(net.parameters(), 1e-2)
最も簡単な訓練ワークフローを定義して実行する
訓練ワークフローを素早くセットアップするために MONAI SupervisedTrainer ハンドラを使用します。
trainer = SupervisedTrainer(
device=device,
max_epochs=5,
train_data_loader=train_loader,
network=net,
optimizer=opt,
loss_function=loss,
inferer=SimpleInferer(),
postprocessing=AsDiscreted(
keys=["pred", "label"], argmax=(True, False),
to_onehot=True, num_classes=3,
),
key_train_metric={
"train_meandice": MeanDice(
output_transform=from_engine(["pred", "label"]))
},
train_handlers=StatsHandler(
tag_name="train_loss", output_transform=from_engine(["loss"], first=True)),
)
trainer.run()
INFO:ignite.engine.engine.SupervisedTrainer:Engine run resuming from iteration 0, epoch 0 until 5 epochs INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 1/7 -- train_loss: 0.7959 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 2/7 -- train_loss: 0.7505 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 3/7 -- train_loss: 0.7073 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 4/7 -- train_loss: 0.6903 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 5/7 -- train_loss: 0.6436 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 6/7 -- train_loss: 0.5983 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 1/5, Iter: 7/7 -- train_loss: 0.5609 INFO:ignite.engine.engine.SupervisedTrainer:Got new best metric of train_meandice: 0.3706986674895653 INFO:ignite.engine.engine.SupervisedTrainer:Epoch[1] Metrics -- train_meandice: 0.3707 INFO:ignite.engine.engine.SupervisedTrainer:Key metric: train_meandice best value: 0.3706986674895653 at epoch: 1 INFO:ignite.engine.engine.SupervisedTrainer:Epoch[1] Complete. Time taken: 00:00:01 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 1/7 -- train_loss: 0.5261 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 2/7 -- train_loss: 0.5211 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 3/7 -- train_loss: 0.5054 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 4/7 -- train_loss: 0.4820 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 5/7 -- train_loss: 0.4693 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 6/7 -- train_loss: 0.4541 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 2/5, Iter: 7/7 -- train_loss: 0.4388 INFO:ignite.engine.engine.SupervisedTrainer:Got new best metric of train_meandice: 0.5458252521661612 INFO:ignite.engine.engine.SupervisedTrainer:Epoch[2] Metrics -- train_meandice: 0.5458 INFO:ignite.engine.engine.SupervisedTrainer:Key metric: train_meandice best value: 0.5458252521661612 at epoch: 2 INFO:ignite.engine.engine.SupervisedTrainer:Epoch[2] Complete. Time taken: 00:00:03 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 1/7 -- train_loss: 0.4413 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 2/7 -- train_loss: 0.4305 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 3/7 -- train_loss: 0.4200 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 4/7 -- train_loss: 0.4210 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 5/7 -- train_loss: 0.4044 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 6/7 -- train_loss: 0.3963 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 3/5, Iter: 7/7 -- train_loss: 0.3781 INFO:ignite.engine.engine.SupervisedTrainer:Got new best metric of train_meandice: 0.5662448773017297 INFO:ignite.engine.engine.SupervisedTrainer:Epoch[3] Metrics -- train_meandice: 0.5662 INFO:ignite.engine.engine.SupervisedTrainer:Key metric: train_meandice best value: 0.5662448773017297 at epoch: 3 INFO:ignite.engine.engine.SupervisedTrainer:Epoch[3] Complete. Time taken: 00:00:03 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 1/7 -- train_loss: 0.3717 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 2/7 -- train_loss: 0.3557 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 3/7 -- train_loss: 0.3526 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 4/7 -- train_loss: 0.3365 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 5/7 -- train_loss: 0.3163 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 6/7 -- train_loss: 0.3026 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 4/5, Iter: 7/7 -- train_loss: 0.2737 INFO:ignite.engine.engine.SupervisedTrainer:Got new best metric of train_meandice: 0.6949328046578628 INFO:ignite.engine.engine.SupervisedTrainer:Epoch[4] Metrics -- train_meandice: 0.6949 INFO:ignite.engine.engine.SupervisedTrainer:Key metric: train_meandice best value: 0.6949328046578628 at epoch: 4 INFO:ignite.engine.engine.SupervisedTrainer:Epoch[4] Complete. Time taken: 00:00:03 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 1/7 -- train_loss: 0.2623 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 2/7 -- train_loss: 0.2445 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 3/7 -- train_loss: 0.2299 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 4/7 -- train_loss: 0.2190 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 5/7 -- train_loss: 0.2207 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 6/7 -- train_loss: 0.2051 INFO:ignite.engine.engine.SupervisedTrainer:Epoch: 5/5, Iter: 7/7 -- train_loss: 0.1910 INFO:ignite.engine.engine.SupervisedTrainer:Got new best metric of train_meandice: 0.7996270152238699 INFO:ignite.engine.engine.SupervisedTrainer:Epoch[5] Metrics -- train_meandice: 0.7996 INFO:ignite.engine.engine.SupervisedTrainer:Key metric: train_meandice best value: 0.7996270152238699 at epoch: 5 INFO:ignite.engine.engine.SupervisedTrainer:Epoch[5] Complete. Time taken: 00:00:03 INFO:ignite.engine.engine.SupervisedTrainer:Engine run complete. Time taken: 00:00:15
他の公開データを共有して MONAI にデータセットを追加する
MedNISTDataset or DecathlonDataset を参考にして、他の公開データのための新しいデータセットを作成することは簡単です。主として以下のステップを含みます :
- MONAI CacheDataset を継承して、訓練を高速化するためにキャッシング機構を利用します。
- データセットのライセンスが公開アクセスと共有を許容していることを確認してください。
- データセットでデータをダウンロードして抽出するために monai.apps.download_and_extract を使用します。
- 訓練、検証とテストセクションをランダムに分割するロジックを定義します。
- 辞書項目でデータリストを構築します :
[ {'image': image1_path, 'label': label1_path}, {'image': image2_path, 'label': label2_path}, {'image': image3_path, 'label': label3_path}, ... ... ] - データセット固有のロジックを定義します。
例として IXIDataset を定義する
ここでは新しい IXIDataset を作成する方法を示すために例として IXI データセット を使用します。
class IXIDataset(Randomizable, CacheDataset):
resource = "http://biomedic.doc.ic.ac.uk/" \
+ "brain-development/downloads/IXI/IXI-T1.tar"
md5 = "34901a0593b41dd19c1a1f746eac2d58"
def __init__(
self,
root_dir,
section,
transform,
download=False,
seed=0,
val_frac=0.2,
test_frac=0.2,
cache_num=sys.maxsize,
cache_rate=1.0,
num_workers=0,
):
if not os.path.isdir(root_dir):
raise ValueError("Root directory root_dir must be a directory.")
self.section = section
self.val_frac = val_frac
self.test_frac = test_frac
self.set_random_state(seed=seed)
dataset_dir = os.path.join(root_dir, "ixi")
tarfile_name = f"{dataset_dir}.tar"
if download:
download_and_extract(
self.resource, tarfile_name, dataset_dir, self.md5)
# as a quick demo, we just use 10 images to show
self.datalist = [
{"image": os.path.join(
dataset_dir, "IXI314-IOP-0889-T1.nii.gz"), "label": 0},
{"image": os.path.join(
dataset_dir, "IXI249-Guys-1072-T1.nii.gz"), "label": 0},
{"image": os.path.join(
dataset_dir, "IXI609-HH-2600-T1.nii.gz"), "label": 0},
{"image": os.path.join(
dataset_dir, "IXI173-HH-1590-T1.nii.gz"), "label": 1},
{"image": os.path.join(
dataset_dir, "IXI020-Guys-0700-T1.nii.gz"), "label": 0},
{"image": os.path.join(
dataset_dir, "IXI342-Guys-0909-T1.nii.gz"), "label": 0},
{"image": os.path.join(
dataset_dir, "IXI134-Guys-0780-T1.nii.gz"), "label": 0},
{"image": os.path.join(
dataset_dir, "IXI577-HH-2661-T1.nii.gz"), "label": 1},
{"image": os.path.join(
dataset_dir, "IXI066-Guys-0731-T1.nii.gz"), "label": 1},
{"image": os.path.join(
dataset_dir, "IXI130-HH-1528-T1.nii.gz"), "label": 0},
]
data = self._generate_data_list()
super().__init__(
data, transform, cache_num=cache_num,
cache_rate=cache_rate, num_workers=num_workers,
)
def randomize(self, data=None):
self.rann = self.R.random()
def _generate_data_list(self):
data = []
for d in self.datalist:
self.randomize()
if self.section == "training":
if self.rann < self.val_frac + self.test_frac:
continue
elif self.section == "validation":
if self.rann >= self.val_frac:
continue
elif self.section == "test":
if self.rann < self.val_frac or \
self.rann >= self.val_frac + self.test_frac:
continue
else:
raise ValueError(
f"Unsupported section: {self.section}, "
"available options are ['training', 'validation', 'test']."
)
data.append(d)
return data
可視化して確認するために IXIDataset から画像をピックアップする
train_ds = IXIDataset(
root_dir=root_dir,
section="training",
transform=Compose([LoadImaged("image"), EnsureTyped("image")]),
download=True,
)
plt.figure("check", (18, 6))
for i in range(3):
plt.subplot(1, 3, i + 1)
plt.imshow(train_ds[i]["image"][:, :, 80].detach().cpu(), cmap="gray")
plt.show()
Verified 'ixi.tar', md5: 34901a0593b41dd19c1a1f746eac2d58. file /workspace/data/medical/ixi.tar exists, skip downloading. Verified 'ixi.tar', md5: 34901a0593b41dd19c1a1f746eac2d58. 100%|██████████| 9/9 [00:02<00:00, 3.51it/s]
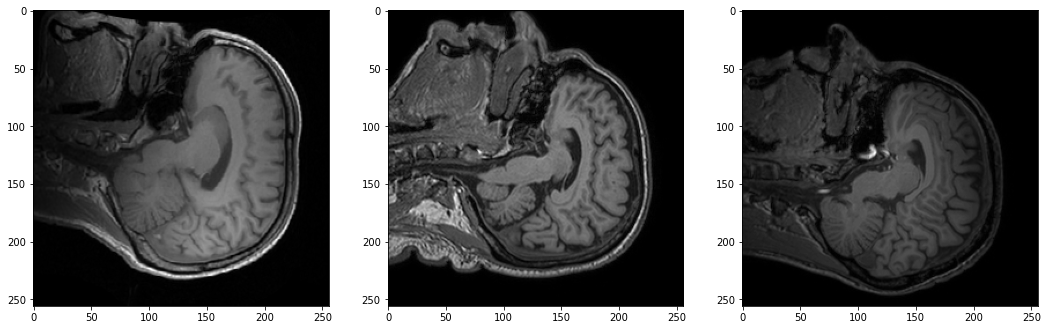
データディレクトリのクリーンアップ
一時ディレクトリが使用された場合にはディレクトリを削除します。
if directory is None:
shutil.rmtree(root_dir)
以上
MONAI 0.7 : モジュール概要 (4) 研究, パフォーマンス最適化と GPU 高速化, アプリケーション
MONAI 0.7 : モジュール概要 (4) 研究, パフォーマンス最適化と GPU 高速化, アプリケーション (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 11/04/2021 (0.7.0)
* 本ページは、MONAI の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。
- 人工知能研究開発支援
- 人工知能研修サービス(経営者層向けオンサイト研修)
- テクニカルコンサルティングサービス
- 実証実験(プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
- PoC(概念実証)を失敗させないための支援
- テレワーク & オンライン授業を支援
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |

MONAI 0.7 : モジュール概要 (4) 研究, パフォーマンス最適化と GPU 高速化, アプリケーション
研究
MONAI には、高位な研究課題に取り組む最近公開された論文に対応する、幾つかの研究プロトタイプがあります。私達はコメント、提案そしてコード実装の形式での貢献をいつでも歓迎しています。
研究プロトタイプから特定される一般的なパターン/モジュールは MONAI コア機能に統合されます。
1. COVID-19 肺炎病変セグメンテーションのための COPLE-Net
次により元々は提案された COPLE-Net の 再実装 :
G. Wang, X. Liu, C. Li, Z. Xu, J. Ruan, H. Zhu, T. Meng, K. Li, N. Huang, S. Zhang. (2020) “A Noise-robust Framework for Automatic Segmentation of COVID-19 Pneumonia Lesions from CT Images.” IEEE Transactions on Medical Imaging. 2020. DOI: 10.1109/TMI.2020.3000314
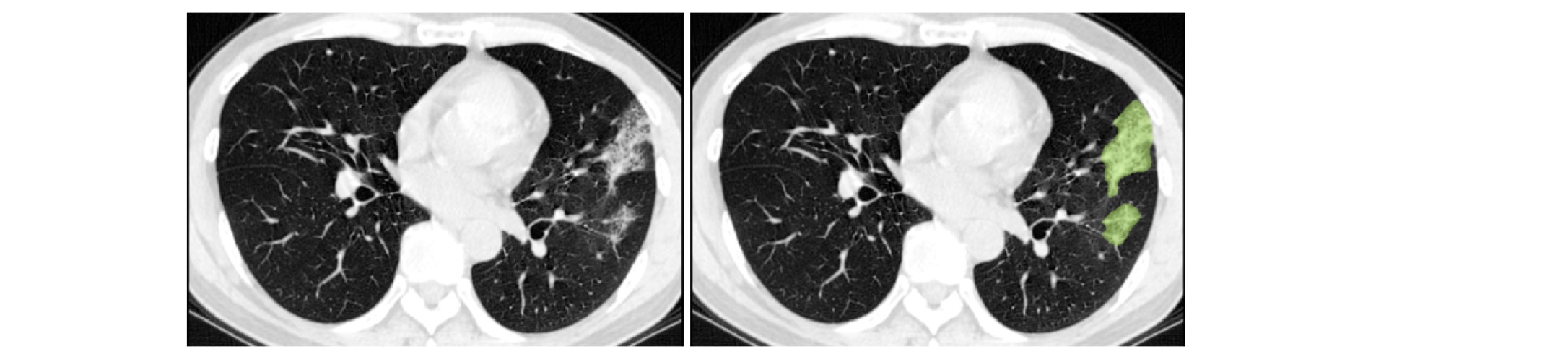
2. LAMP : 画像セグメンテーションのための自動モデル並列化による Large Deep Net
次により元々は提案された LAMP の 再実装 :
Wentao Zhu, Can Zhao, Wenqi Li, Holger Roth, Ziyue Xu, and Daguang Xu (2020) “LAMP: Large Deep Nets with Automated Model Parallelism for Image Segmentation.” MICCAI 2020 (Early Accept, paper link: https://arxiv.org/abs/2006.12575)
パフォーマンス最適化と GPU アクセラレーション
典型的には、モデル訓練は深層学習開発の間の時間を消費するステップです、特に医用画像アプリケーションでは。ボリュメトリックな医用画像は通常は (多次元配列として) 大きくそしてモデル訓練プロセスは複雑である可能性があります。強力なハードウェア (大きな RAM を持つ CPU/GPU) を使用してさえも、高いパフォーマンスを得るためにそれらを活用することは簡単ではありません。MONAI はベスト・パフォーマンスを得るための高速訓練ガイドを提供しています : https://github.com/Project-MONAI/tutorials/blob/master/acceleration/fast_model_training_guide.md
NVIDIA GPU は深層学習と評価の多くの分野で広く利用されていて、CUDA 並列計算は従来の計算方法と比較したとき明らかな高速化を示します。GPU 機能を完全に活用するため、自動混合精度 (AMP), 分散データ並列 等のような、多くのポピュラーなメカニズムが提示されました。MONAI はこれらの機能をサポートできて、豊富なサンプルを提供しています。
1. パイプラインのプロファイル
最初に、MONAI はパフォーマンス・ボトルネックを特定するためにプログラムを分析する DLProf, Nsight, NVTX と NVML に基づく幾つかの方法をユーザに提供します。分析はモデル訓練の間の演算ベースの GPU アクティビティと GPU 全体のアクティビティです。それらはユーザが計算ボトルネックを管理するのに非常に役立ち、そしてより良い計算効率のために改良されるべき領域のための洞察を与えます。詳細なサンプルは パフォーマンス・プロファイリング・チュートリアル で示されます
2. 自動混合精度 (AMP)
2017 年に、NVIDIA 研究者は混合精度訓練のための手法を開発しました、これはネットワークを訓練するとき、単精度 (FP32) を半精度 (e.g. FP16) 形式と組合せ、そして同じハイパーパラメータを使用する FP32 訓練と同じ精度を獲得するものです。
PyTorch 1.6 リリースについて、NVIDIA と Facebook の開発者は混合精度機能を PyTorch コアに AMP パッケージ, torch.cuda.amp として移しました。
MONAI ワークフローは AMP を有効/無効にするために訓練の間に SupervisedTrainer or SupervisedEvaluator で amp=True/False を簡単に設定できます。そして CUDA 11 と PyTorch 1.6 を使用して NVIDIA V100 上で AMP ON/OFF で訓練スピードを比較することを試し、幾つかのベンチマーク結果を得ました :
同じソフトウェア環境で同じテストプログラムを NVIDIA A100 GPU 上で実行もしました、より高速な結果を得ました :
詳細は AMP 訓練チュートリアル で利用可能です。AMP をまた、MONAI で高速訓練を獲得するために CacheDataset, GPU キャッシュ, GPU 変換, ThreadDataLoader, DiceCE 損失関数と Novograd optimizer と組合せてもみました。訓練が 0.95 の検証平均 dice で収束するとき PyTorch ネイティブ実装と比較しておよそ 200x のスピードアップを得られました。参考のためのベンチマークです :
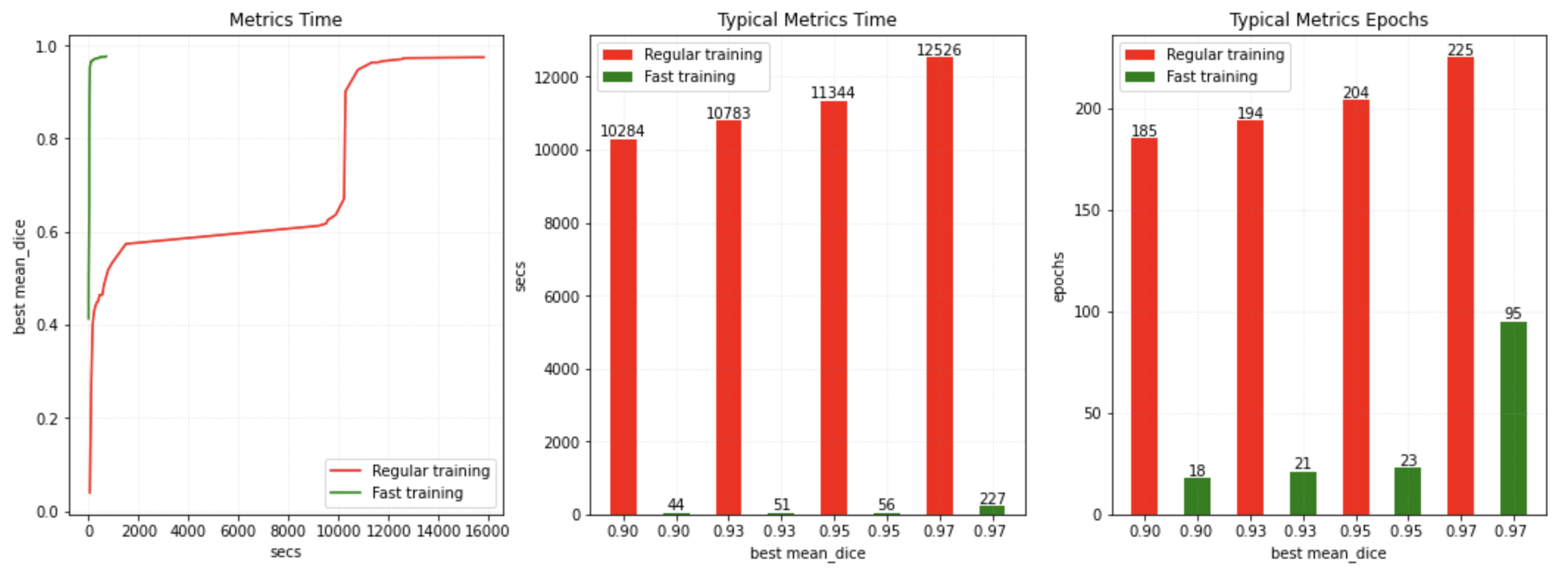
詳細は 高速訓練チュートリアル で利用可能です。
3. 分散データ並列
分散データ並列は、モデルを訓練または評価するためにシングル or マルチノード上で複数の GPU デバイスに接続するための PyTorch の重要な機能です。MONAI の分散データ並列 API はネイティブ PyTorch 分散モジュール、pytorch-ignite 分散モジュール、Horovod、XLA そして SLURM プラットフォームと互換です。MONAI は参考のためのデモを提供しています : PyTorch DDP による訓練/評価、Horovod による訓練/評価、Ignite DDP による訓練/評価、SmartCacheDataset によるデータセットの分割と訓練、そして Decathlon チャンレンジ Task01 に基づく現実世界の訓練サンプル – 脳腫瘍セグメンテーション 等です。チュートリアル は分散キャッシング、訓練と検証を含みます。参考のためにパフォーマンス・ベンチマークを取得しました (PyTorch 1.9.1, CUDA 11.4, NVIDIA V100 GPU に基づいています。最適化は、より多くの GPU リソースにより、データを分割し GPU メモリにキャッシュして GPU 変換を直接実行できるという意味です)。
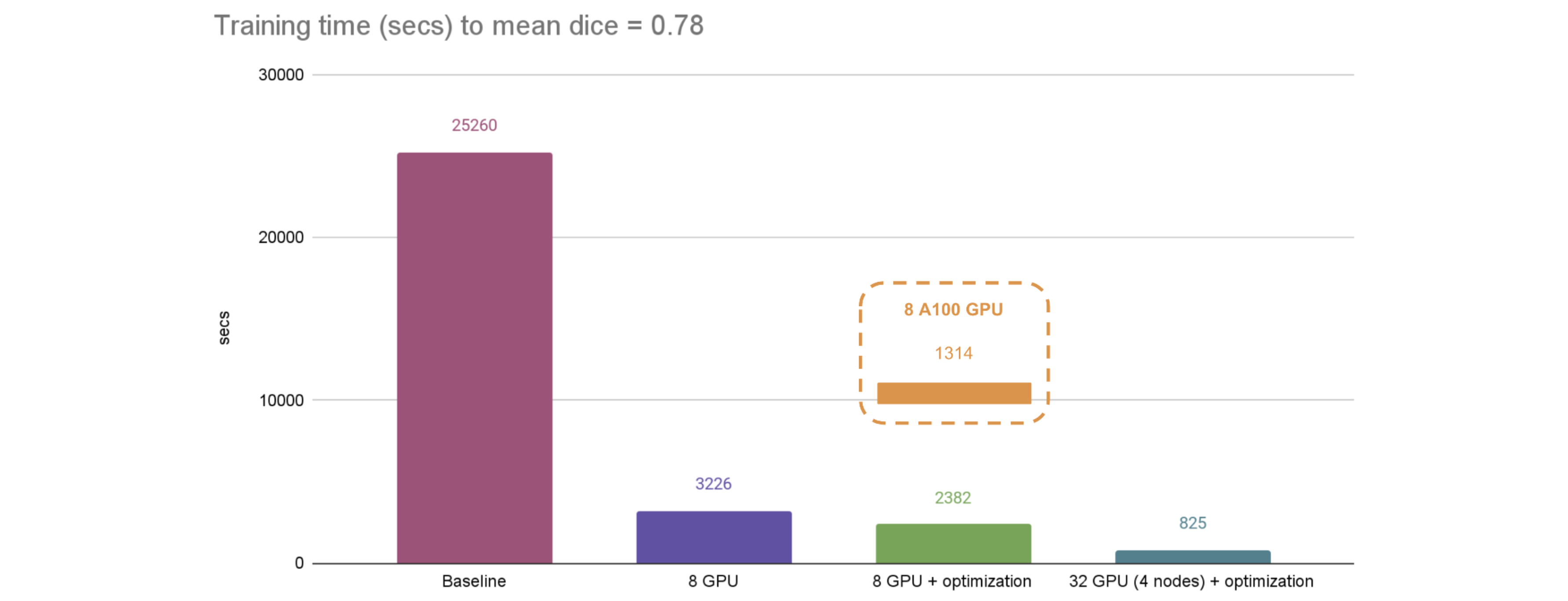
4. C++/CUDA 最適化モジュール
ワークフローのドメイン固有のルーチンを更に高速化するため、MONAI C++/CUDA 実装が PyTorch ネイティブ実装の拡張として導入されました。MONAI は PyTorch から C++ 拡張を構築する 2 つの方法 を使用してモジュールを提供します。
- Resampler, Conditional random field (CRF), permutohedral 格子を使用する Fast bilateral フィルタリングを含むモジュールについては、setuptools を通して。
- Gaussian mixtures (ガウス混合) モジュールについては、just-in-time (JIT) コンパイルを通しています。このアプローチはユーザが指定したパラメータとローカルシステム環境に従って動的最適化を可能にします。次の図は、組織と手術器具のセグメンテーションに適用された MONAI のガウス混合モデルの結果を示しています :
5. Cache IO and transforms data to GPU memory
CacheDataset を使用してさえも、通常はエポック毎に GPU ランダム変換やネットワーク計算のために同じデータを GPU メモリにコピーする必要があります。効率的なアプローチはデータを GPU メモリに直接キャッシュすれば、総てのエポックで GPU 計算を直ちに始められます。
例えば :
train_transforms = [
LoadImaged(...),
AddChanneld(...),
Spacingd(...),
Orientationd(...),
ScaleIntensityRanged(...),
EnsureTyped(..., data_type="tensor"),
ToDeviced(..., device="cuda:0"),
RandCropByPosNegLabeld(...),
]
dataset = CacheDataset(..., transform=train_trans)
ここでは EnsureTyped 変換で PyTorch テンソルに変換して、ToDeviced 変換でデータを GPU に移しています。CacheDataset が変換結果を ToDeviced までキャッシュしますので、それは GPU メモリ内にあります。そしてエポック毎に、プログラムは GPU メモリからキャッシュされたデータを取得して GPU 上でランダム変換 RandCropByPosNegLabeld だけを直接実行します。GPU キャッシング・サンプルは 脾臓高速訓練チュートリアル で利用可能です。
アプリケーション
医用画像深層学習の研究エリアは急速に拡大しています。最新の成果をアプリケーションに応用するため、MONAI は、他の類似のユースケースのために end-to-end なソリューションやプロトタイプを構築するために多くのアプリケーション・コンポーネントを含みます。
1. 対話的セグメンテーションのための DeepGrow モジュール
DeepGrow コンポーネントの再実装です、これは深層学習ベースの半自動のセグメンテーション・アプローチで、医用画像の関心領域描写のための「スマートな」対話的ツールを目的としていて、元は次により提案されました :
Sakinis, Tomas, et al. “Interactive segmentation of medical images through fully convolutional neural networks.” arXiv preprint arXiv:1903.08205 (2019).
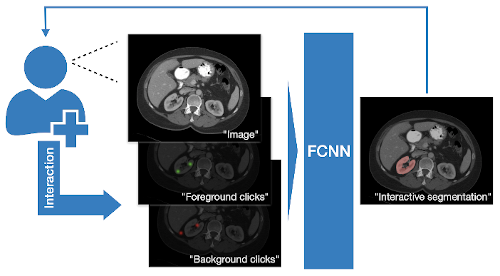
2. デジタルパソロジーの病変検出
パソロジー検出コンポーネントの 実装 で、NVIDIA cuCIM ライブラリと SmartCache メカニズムによる効率的なスライド全体の画像 IO とサンプリング、病変の FROC 測定、そして病変検出のための確率的後処理を含みます。
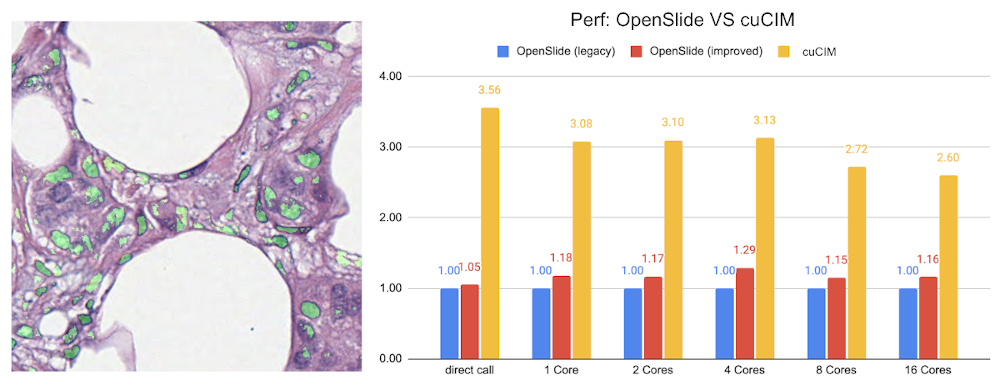
3. 学習ベースの画像レジストレーション
v0.5.0 から、MONAI は学習ベースの 2D/3D レジストレーション・ワークフローを構築するための実験的な機能を提供しています。これらは損失関数として画像類似尺度、モデル正則化として曲げエネルギー (= bending energy)、ネットワーク・アーキテクチャ、ワーピング・モジュールを含みます。コンポーネントは主要な教師なし、弱 (= weakly) 教師ありアルゴリズムを構築するために使用できます。
以下の図は、MONAI を使用して単一の患者の異なる時間点で得られた CT 画像のレジストレーションを示します :

4. 最先端の Kaggle コンペティション・ソリューションの再現
RANZCR CLiP – カテーテルと Line Position チャレンジ in Kaggle: https://www.kaggle.com/c/ranzcr-clip-catheter-line-classification の 4 位のソリューションの 再実装 です。
元のソリューションは Team Watercooled により作成され、そして作者は Dieter (https://www.kaggle.com/christofhenkel) と Psi (https://www.kaggle.com/philippsinger) です。
以上
MONAI 0.7 : モジュール概要 (3) ネットワーク, 評価, ワークフロー 等
MONAI 0.7 : モジュール概要 (3) ネットワーク, 評価, ワークフロー 等 (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 11/01/2021 (0.7.0)
* 本ページは、MONAI の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。
- 人工知能研究開発支援
- 人工知能研修サービス(経営者層向けオンサイト研修)
- テクニカルコンサルティングサービス
- 実証実験(プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
- PoC(概念実証)を失敗させないための支援
- テレワーク & オンライン授業を支援
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |
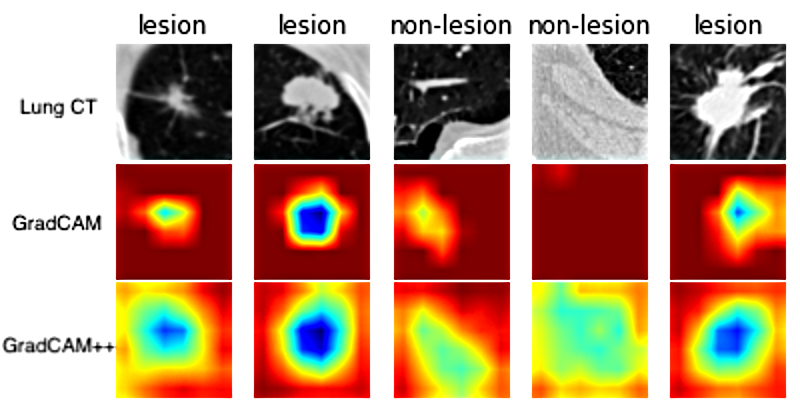
MONAI 0.7 : モジュール概要 (3) ネットワーク, 評価, ワークフロー 等
損失
医用画像の研究では、一般的なコンピュータビジョン・タスクでは通常は使用されない、ドメイン固有の損失関数があります。MONAI の重要なモジュールとして、DiceLoss, GeneralizedDiceLoss, MaskedDiceLoss, TverskyLoss, FocalLoss, DiceCELoss と DiceFocalLoss 等のような、これらの損失関数は PyTorch で実装されています。
Optimizers
MONAI は訓練は再調整の進捗を高速化する手助けをするために optimizer で幾つかの高度な機能を提供しています。例えば、Novograd optimizer は従来の optimizer よりも高速に収束させるために使用できます。そしてユーザは generate_param_groups ユティリティ API に基づいて、モデル層のために異なる学習率を簡単に定義することができます。
もう一つの重要な機能は LearningRateFinder です。学習率の範囲テストは 2 つの境界の間で事前訓練実行の学習率を線形または指数関数的な方法で増加させます。それはネットワークが学習率の範囲でどのくらい上手く訓練できるか、そして最適な学習率が何かについての有益な情報を提供します。LearningRateFinder チュートリアル は API 使用方法のサンプルを示します。
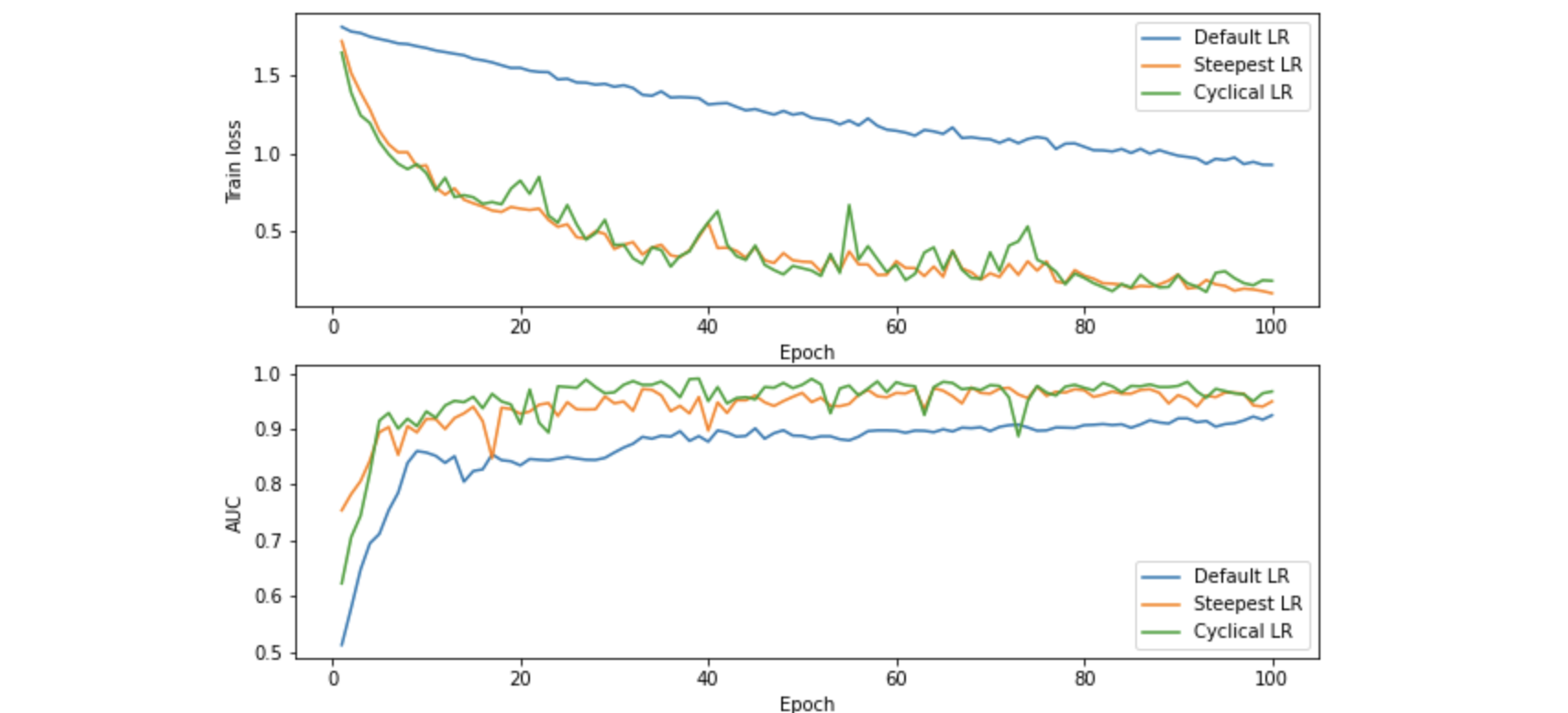
ネットワーク・アーキテクチャ
幾つかの深層ニューラルネットワーク・アーキテクチャが医用画像解析タスクに特に効果的であることを示しています。MONAI は柔軟性とコード可読性の両方を目的とするリファレンス・ネットワークを実装しています。
1. 事前定義された層とブロック
一般的なネットワーク層とブロックを活用するため、MONAI は幾つかの事前定義された層とブロックを提供しています、これらは 1D, 2D と 3D ネットワークと互換です。ユーザは層ファクトリをカスタマイズされたネットワークに簡単に統合できます。
例えば :
# import MONAI’s layer factory
from monai.networks.layers import Conv
# adds a transposed convolution layer to the network
# which is compatible with different spatial dimensions.
name, dimension = Conv.CONVTRANS, 3
conv_type = Conv[name, dimension]
add_module('conv1', conv_type(in_channels, out_channels, kernel_size=1, bias=False))
2. 一般的な 2D/3D ネットワークの実装
そして、UNet, DynUNet, DenseNet, GAN, AHNet, VNet, SENet(と SEResNet, SEResNeXt), SegResNet, EfficientNet, Attention ベースのトランスフォーマー・ネットワークのような、中間的なブロックと一般的なネットワークの幾つかの 1D/2D/3D 互換な実装もあります、総てのネットワークは torch.jit.script に基づいた PyTorch シリアライゼーション・パイプラインをサポートできます。
3. 最終層を再調整するためのネットワーク・アダプター
スクラッチから訓練する代わりに、新しい学習タスクのために既存のモデルを活用して、ネットワークの最終層を再調整する場合が良くあります。MONAI はモデルの最終層を畳込み層や完全結合層で簡単に置き換えられる NetAdapter を提供しています。典型的な使用例は ImageNet で訓練された Torchvision モデル を他の学習タスクに適応させることです。
評価
モデル推論を実行してモデル品質を評価するために、MONAI は広く使用されている関連アプローチのためのリファレンス実装を提供しています。現在、幾つかのポピュラーな評価メトリクスと推論パターンが含まれています :
1. スライディング・ウィンドウ推論
大きなボリューム上のモデル推論のためには、スライディングウィンドウ・アプローチは、柔軟なメモリ要件を持ちながら、高い性能を獲得するためのポピュラーな選択です (代わりに、MONAI を使用する モデル並列訓練 についての最新の研究もチェックしてください)。それはまたより良い性能のためにオーバーラップされたウィンドウを処理するために overlap と blending_mode configuration もサポートします。
典型的なプロセスは :
- 元の画像上で連続するウィンドウを選択する。
- 総てのウィンドウが解析されるまでバッチ処理されたウィンドウ推論を反復的に実行する。
- 推論出力を単一のセグメンテーション・マップに集約する。
- 結果をファイルに保存するか評価メトリクスを計算する。
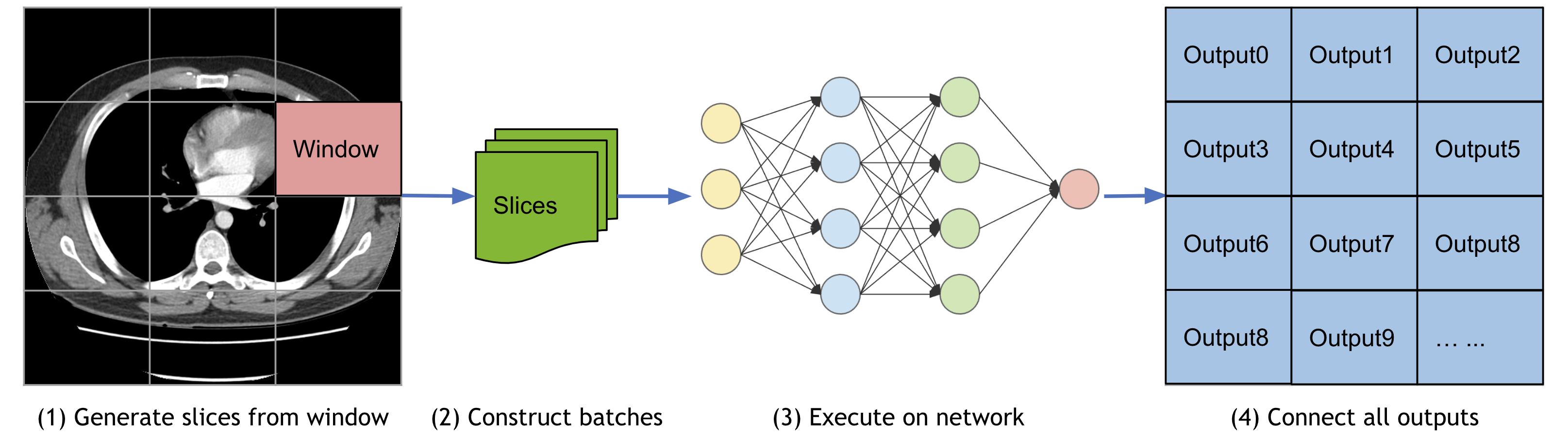
脾臓 3D セグメンテーション・チュートリアル は検証のために SlidingWindow 推論を利用しています。
2. 医療タスクのためのメトリクス
医用画像固有のモデルの品質を測定するために様々な有用な評価メトリクスが使用されています。MONAI は既に多くの医療ドメイン固有のメトリクスを実装しています、次のようなものです : 平均 Dice, ROCAUC, 混同行列, ハウスドルフ距離, サーフェス距離, オクルージョン感度。
例えば、セグメンテーション・タスクのために平均 Dice スコアが、分類タスクのために ROC 曲線の下の面積 (ROCAUC) が使用できます。より多くのオプションを統合し続けます。
- MONAI はメトリクスのための柔軟な基底 API を提供しています。MONAI メトリクスの基底クラスは反復とエポックベースのメトリクスの両方のための基本計算ロジックを実装しています。それらはカスタマイズされたメトリクスのための良い開始点です。
- 総てのメトリクスはデータ並列計算をサポートします。Cumulative 基底クラスでは、中間的なメトリックの結果を自動的にバッファリングし、累積し、分散プロセスに渡り同期し、そして最終結果のために集約できます。マルチプロセス計算サンプル は、マルチプロセス環境で保存された予測とラベルに基づいてメトリクスを計算する方法を示します。
- 総てのメトリクスモジュールはバッチ first テンソルとチャネル first テンソルのリストを扱うことができます。
3. メトリクス・レポート生成
評価の間、ユーザは通常は総ての入力画像のメトリクスを保存してから、深層学習パイプラインを改良するために悪いケースを分析します。
メトリクスの詳細情報をセーブするため、MONAI はハンドラ MetricsSaver を提供しました、これは最終的なメトリック値、総ての入力画像の総てのモデル出力チャネルの raw メトリック、(平均, 中央値, max, min <int>パーセンタイル, std 等の) 演算のメトリクス要約レポートをセーブすることができます。前立腺データセットによる検証の MeanDice レポートは以下のようなものです :
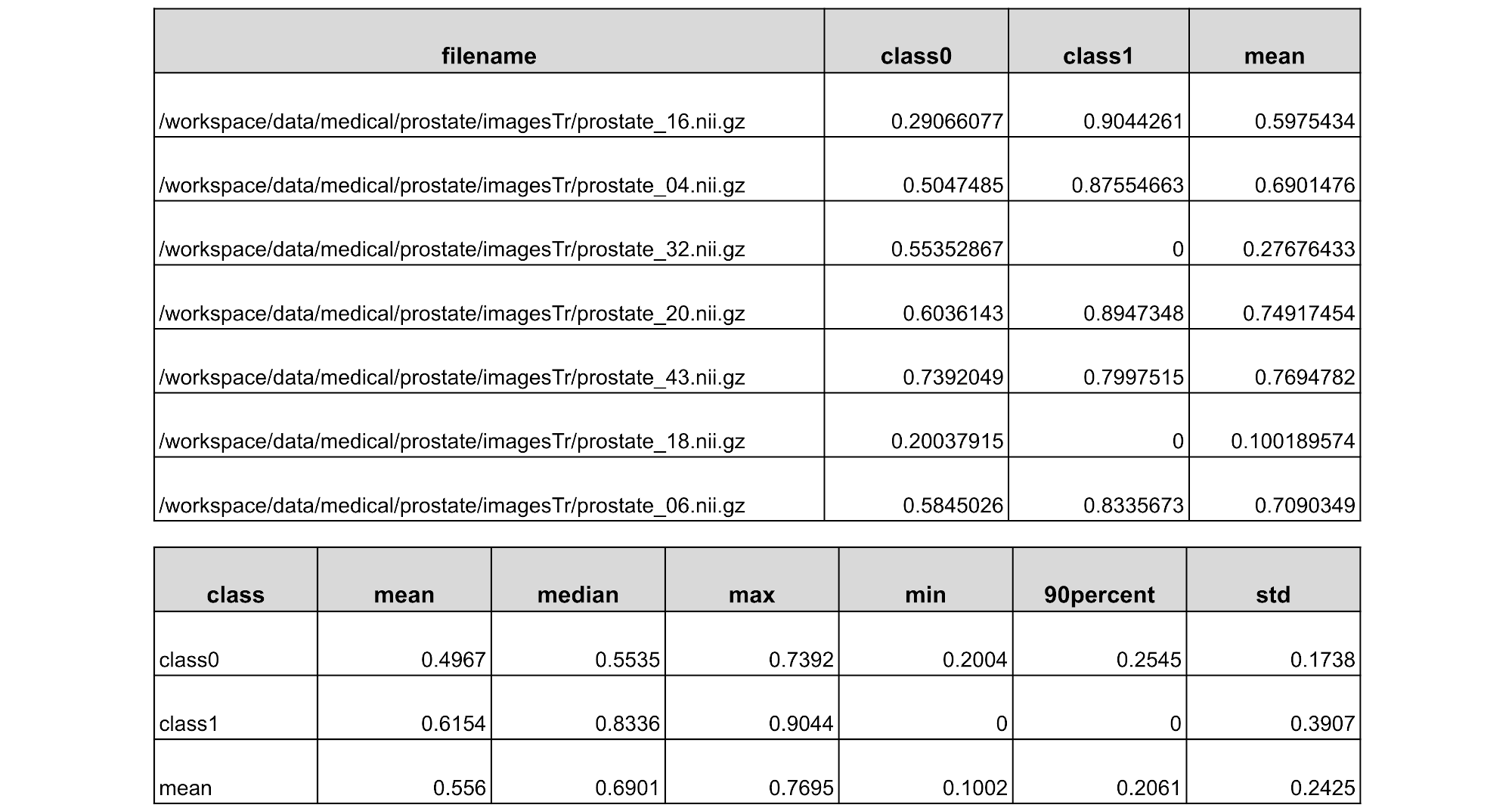
視覚化
単純な点と曲線プロットとは別に、MONAI は多次元データを TensorBoard でGIF アニメとして可視化するために直感的なインターフェイスを提供します。これは、例えば、ボリュメトリック入力、セグメンテーションマップと中間的な特徴マップを可視化することによりモデルの素早い定性的な評価を提供できるでしょう。可視化の実行可能なサンプルは UNet 訓練サンプル で利用可能です。
そして訓練済みの分類モデルのためのクラス活性マッピングを可視化するため、MONAI は 2D と 3D モデルの両方のための CAM, GradCAM, GradCAM++ API を提供します :
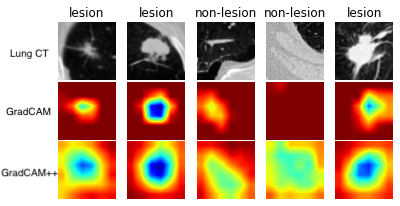
上のサンプルは、肺 CT 病変分類モデルから GradCAM/GradCAM++ を計算することにより生成されます。
結果の書き出し
現在、MONAI はモデル出力をセグメンテーション・タスクのためには NIfTI ファイルや PNG ファイル、そして分類タスクのためには CSV ファイルとして書き出すことをサポートしています。そして writer は入力画像の original_shape or original_affine 情報に従ってデータ spacing, 向きや shape を復元することができます。
形式の豊富なセットもまた、出力から自動的に計算される関連する統計情報と評価メトリクスと一緒に間もなくサポートされます。
ワークフロー
訓練と評価実験を素早くセットアップするため、MONAI はモジュールを大幅に単純化して高速なプロトタイピングを可能にするワークフローのセットを提供します。
これらの機能はドメイン固有のコンポーネントと一般的な機械学習プロセスを切り離します。それらはまた (AutoML, 連合学習のような) 高位アプリケーションのための unify API のセットも提供します。ワークフローの trainer と evaluator は pytorch-ignite エンジンとイベントハンドラ・メカニズムと互換です。MONAI には独立に trainer や evaluator に装着する豊富なイベントハンドラがあり、ユーザはワークフローに追加のカスタムイベントを登録できます。
1. 一般的なワークフロー・パイプライン
ワークフローと MONAI イベントハンドラの幾つかは以下で示されます :
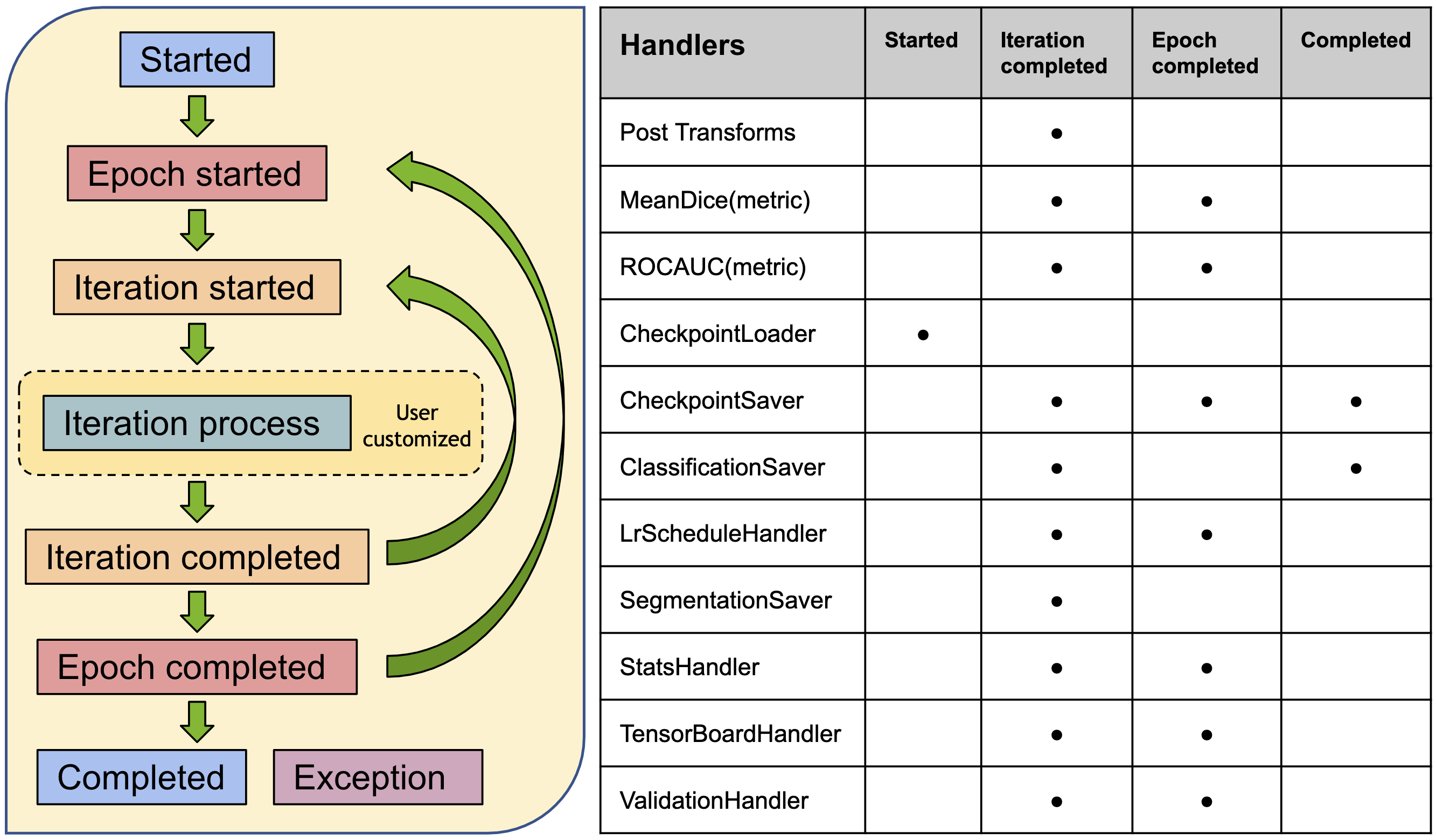
end-to-end な訓練と評価サンプルは Workflow サンプル で利用可能です。
2. EnsembleEvaluator
モデル・アンサンブルはより正確でより安定した出力を獲得するために機械学習と深層学習領域でポピュラーなストラテジーです。典型的な実践は :
- 総ての訓練データセットを K folds に分割します。
- 総ての K-1 folds データで K 個のモデルを訓練します。
- 総ての K 個のモデルでテストデータ上の推論を実行します。
- 最終結果として重み付けて平均値を計算するか、最も一般的な値を投票で決定します。
実践の詳細は モデルアンサンブル・チュートリアル にあります。
異なる入力/出力クラスのための転移学習
転移学習は一般的で効率的な訓練アプローチで、特に訓練のための大規模なデータセットを得ることが困難である可能性がある医療固有ドメインで。従って事前訓練済みのチェックポイントからの転移学習はモデルメトリクスを大幅に改善して訓練時間を短縮できます。
MONAI は訓練の前のワークフローのためにチェックポイントをロードする CheckpointLoader を提供しました、そしてそれは現在のネットワークの幾つかの層名がチェックポイントと一致しなかったり、幾つかの層 shape がチェックポイントに一致しないことを許容します、それは現在のタスクが異なる画像クラスや出力クラスを持つ場合に有用である可能性があります。
4. NVIDIA Clara MMAR に基づく転移学習
MMAR (医療モデル ARchive) はモデル開発ライフサイクルの間に生成される総てのアーティファクトを体系化するためのデータ構造を定義します。NVIDIA Clara は医療ドメイン固有のモデルの豊富な既存の MMAR を提供しています。そしてこれらの MMAR は、総ての開発タスクを実行するワークスペースを提供する configuration とスクリプトを含む、モデルについての総ての情報を含みます。Nvidia GPU クラウド上でリリースされた事前訓練済みの MMAR をより良く利用するために、MONAI は MMAR にアクセスするために pythonic API を提供しています。
以下の図は損失曲線と検証スコアを訓練エポック数に従って、次のために比較しています : (1) スクラッチからの訓練 (緑色のライン), (2) 事前訓練済みのモデルの適用 (マゼンタ色のライン), (3) 事前訓練済みモデルからの訓練 (青色のライン) (チュートリアルは transfer_mmar で利用可能です) :
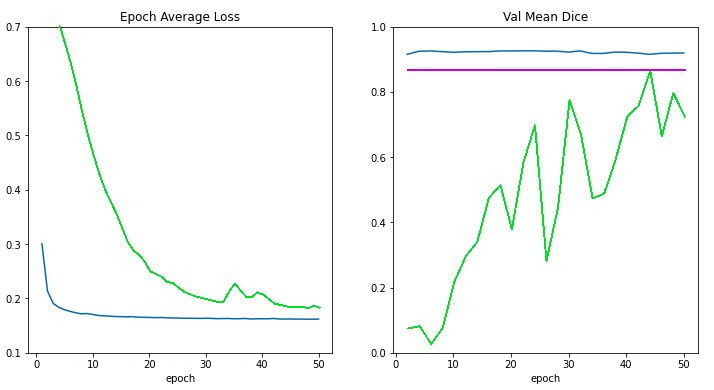
5. 柔軟な後処理のためにバッチデータを分離する (= Decollate)
decollate batch が MONAI v0.6 で導入されました、これは後処理変換を単純化して、様々なデータ shape のデータのバッチ上で柔軟な後に続く演算を提供します。それはバッチ化データをテンソルのリストに分離できます、以下のようなメリットのためにです :
- 各項目に対して独立に後処理変換を可能にします – ランダム化された変換がバッチの各予測された項目のために異なって適用できます。
- 変換 API を単純化して入力検証の負荷を軽減します、何故なら今では前処理と後処理変換は「チャネル first」入力形式をサポートする必要があるだけだからです。
- 予測のための Invertd と異なる shape を持つ反転したデータを可能にします、データ項目がリストにあり単一のテンソルにスタックされていないからです。
- 柔軟なメトリック計算でバッチ first テンソルとチャネル first テンソルのリストの両方を可能にします。
decollate batch の典型的なプロセスは以下のように図示されます (例として batch_size=N モデル予測とラベルによる) :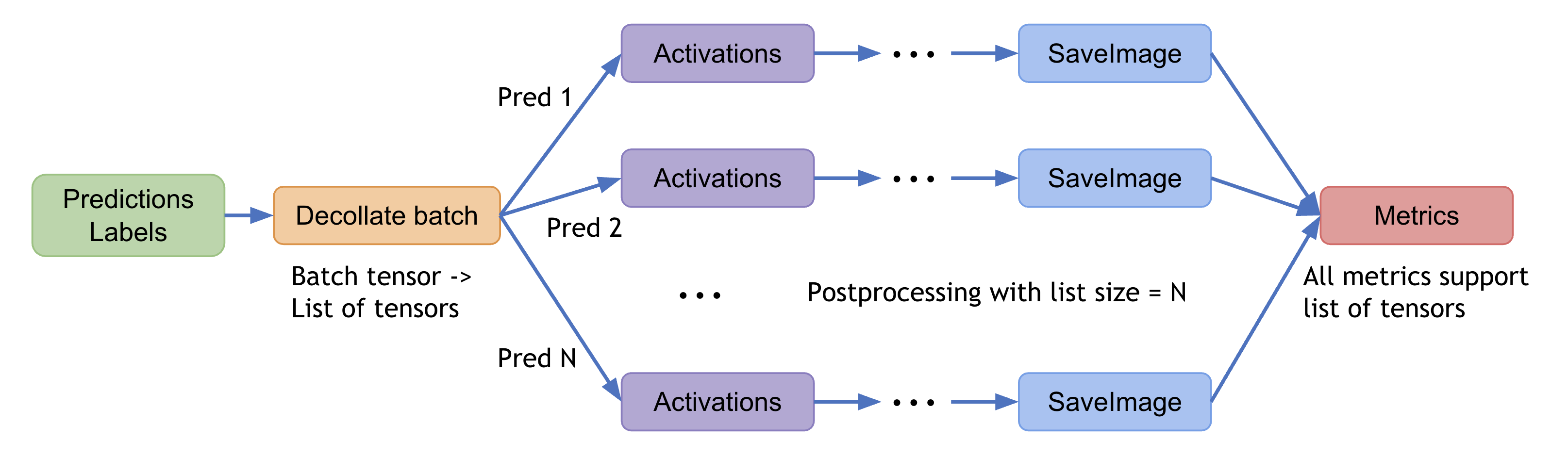
decollate batch チュートリアル は PyTorch ネイティブ・ワークフローに基づく詳細な使用例を示します。
6. ポピュラーなワークフローへの統合が簡単
pytorch-ignite ベースの monai.engines を除いて、MONAI モジュールの殆どは独立に使用できて他のソフトウェア・パッケージと組み合わせることもできます。例えば、MONAI は PyTorch-Lightning と Catalyst のようなポピュラーなフレームワークに容易に統合できます : Lightning セグメンテーション と Lightning + TorchIO チュートリアルは MONAI モジュールを使用する PyTorch Lightning を示し、そして Catalyst セグメンテーション は MONAI モジュールを使用する Catalyst プログラムを示します。
以上
- 各項目に対して独立に後処理変換を可能にします – ランダム化された変換がバッチの各予測された項目のために異なって適用できます。
ClassCat® Chatbot
人工知能開発支援
- テクニカルコンサルティングサービス
- 実証実験 (プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
クラスキャット
セールス・インフォメーション
E-Mail:sales-info@classcat.com