MONAI 0.7 : モジュール概要 (4) 研究, パフォーマンス最適化と GPU 高速化, アプリケーション (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 11/04/2021 (0.7.0)
* 本ページは、MONAI の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。

- 人工知能研究開発支援
- 人工知能研修サービス(経営者層向けオンサイト研修)
- テクニカルコンサルティングサービス
- 実証実験(プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
- PoC(概念実証)を失敗させないための支援
- テレワーク & オンライン授業を支援
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |

MONAI 0.7 : モジュール概要 (4) 研究, パフォーマンス最適化と GPU 高速化, アプリケーション
研究
MONAI には、高位な研究課題に取り組む最近公開された論文に対応する、幾つかの研究プロトタイプがあります。私達はコメント、提案そしてコード実装の形式での貢献をいつでも歓迎しています。
研究プロトタイプから特定される一般的なパターン/モジュールは MONAI コア機能に統合されます。
1. COVID-19 肺炎病変セグメンテーションのための COPLE-Net
次により元々は提案された COPLE-Net の 再実装 :
G. Wang, X. Liu, C. Li, Z. Xu, J. Ruan, H. Zhu, T. Meng, K. Li, N. Huang, S. Zhang. (2020) “A Noise-robust Framework for Automatic Segmentation of COVID-19 Pneumonia Lesions from CT Images.” IEEE Transactions on Medical Imaging. 2020. DOI: 10.1109/TMI.2020.3000314
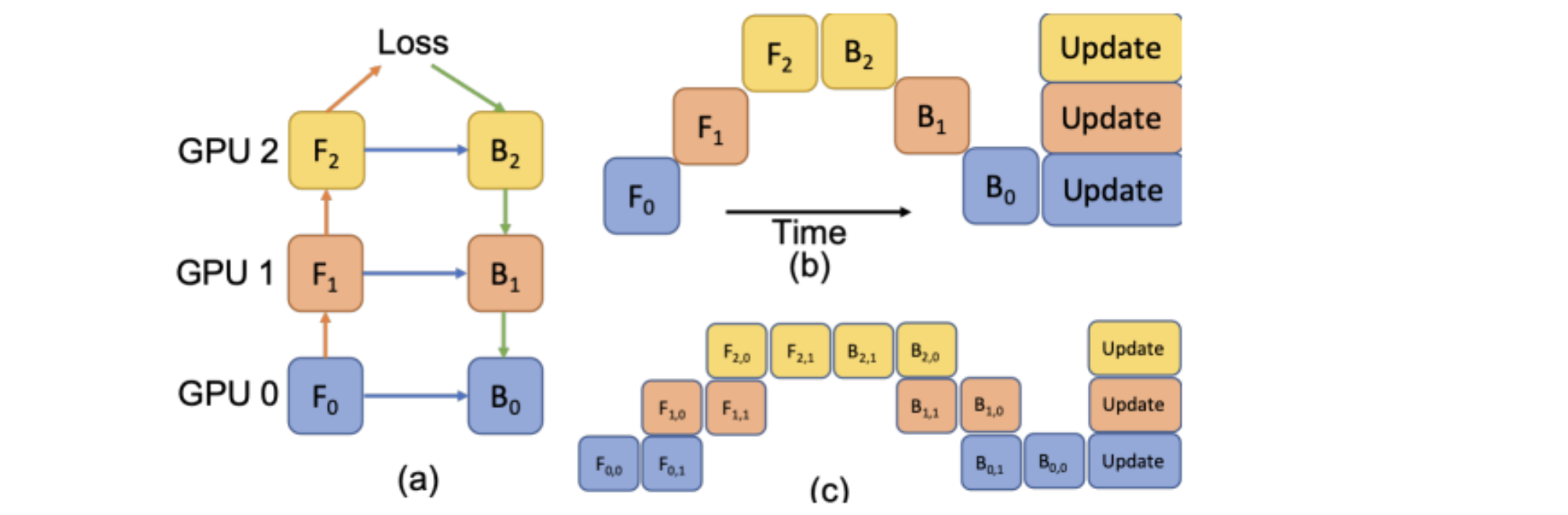
2. LAMP : 画像セグメンテーションのための自動モデル並列化による Large Deep Net
次により元々は提案された LAMP の 再実装 :
Wentao Zhu, Can Zhao, Wenqi Li, Holger Roth, Ziyue Xu, and Daguang Xu (2020) “LAMP: Large Deep Nets with Automated Model Parallelism for Image Segmentation.” MICCAI 2020 (Early Accept, paper link: https://arxiv.org/abs/2006.12575)
パフォーマンス最適化と GPU アクセラレーション
典型的には、モデル訓練は深層学習開発の間の時間を消費するステップです、特に医用画像アプリケーションでは。ボリュメトリックな医用画像は通常は (多次元配列として) 大きくそしてモデル訓練プロセスは複雑である可能性があります。強力なハードウェア (大きな RAM を持つ CPU/GPU) を使用してさえも、高いパフォーマンスを得るためにそれらを活用することは簡単ではありません。MONAI はベスト・パフォーマンスを得るための高速訓練ガイドを提供しています : https://github.com/Project-MONAI/tutorials/blob/master/acceleration/fast_model_training_guide.md
NVIDIA GPU は深層学習と評価の多くの分野で広く利用されていて、CUDA 並列計算は従来の計算方法と比較したとき明らかな高速化を示します。GPU 機能を完全に活用するため、自動混合精度 (AMP), 分散データ並列 等のような、多くのポピュラーなメカニズムが提示されました。MONAI はこれらの機能をサポートできて、豊富なサンプルを提供しています。
1. パイプラインのプロファイル
最初に、MONAI はパフォーマンス・ボトルネックを特定するためにプログラムを分析する DLProf, Nsight, NVTX と NVML に基づく幾つかの方法をユーザに提供します。分析はモデル訓練の間の演算ベースの GPU アクティビティと GPU 全体のアクティビティです。それらはユーザが計算ボトルネックを管理するのに非常に役立ち、そしてより良い計算効率のために改良されるべき領域のための洞察を与えます。詳細なサンプルは パフォーマンス・プロファイリング・チュートリアル で示されます
2. 自動混合精度 (AMP)
2017 年に、NVIDIA 研究者は混合精度訓練のための手法を開発しました、これはネットワークを訓練するとき、単精度 (FP32) を半精度 (e.g. FP16) 形式と組合せ、そして同じハイパーパラメータを使用する FP32 訓練と同じ精度を獲得するものです。
PyTorch 1.6 リリースについて、NVIDIA と Facebook の開発者は混合精度機能を PyTorch コアに AMP パッケージ, torch.cuda.amp として移しました。
MONAI ワークフローは AMP を有効/無効にするために訓練の間に SupervisedTrainer or SupervisedEvaluator で amp=True/False を簡単に設定できます。そして CUDA 11 と PyTorch 1.6 を使用して NVIDIA V100 上で AMP ON/OFF で訓練スピードを比較することを試し、幾つかのベンチマーク結果を得ました :
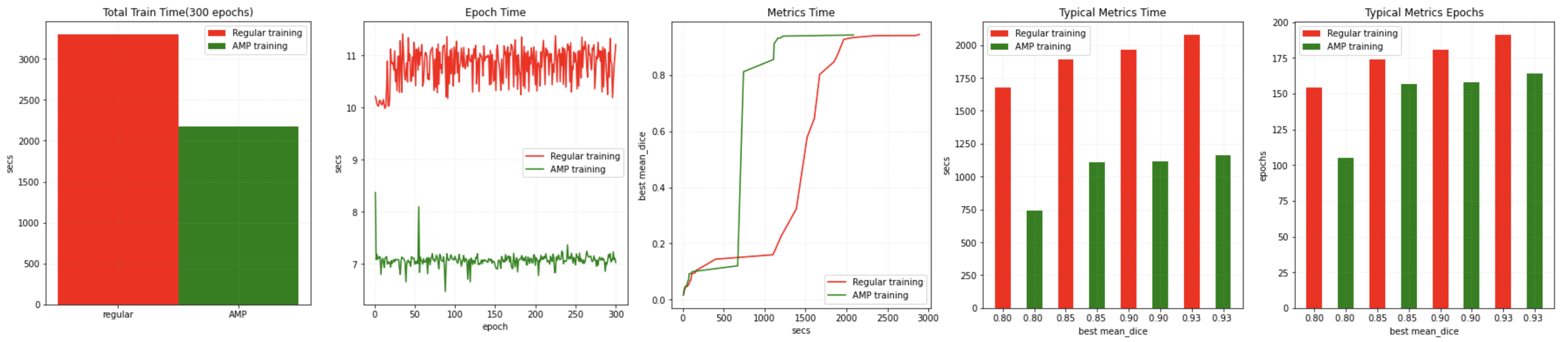
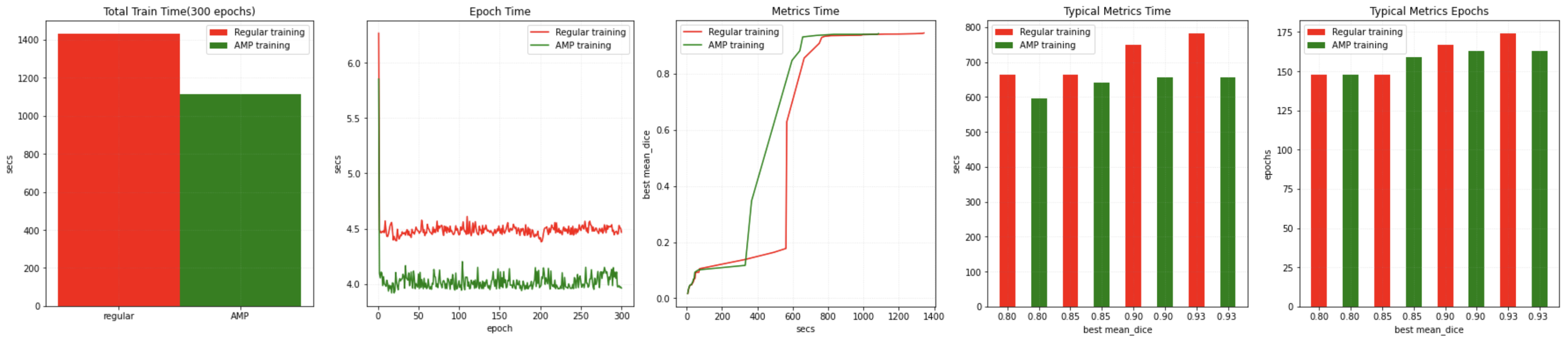
同じソフトウェア環境で同じテストプログラムを NVIDIA A100 GPU 上で実行もしました、より高速な結果を得ました :
詳細は AMP 訓練チュートリアル で利用可能です。AMP をまた、MONAI で高速訓練を獲得するために CacheDataset, GPU キャッシュ, GPU 変換, ThreadDataLoader, DiceCE 損失関数と Novograd optimizer と組合せてもみました。訓練が 0.95 の検証平均 dice で収束するとき PyTorch ネイティブ実装と比較しておよそ 200x のスピードアップを得られました。参考のためのベンチマークです :
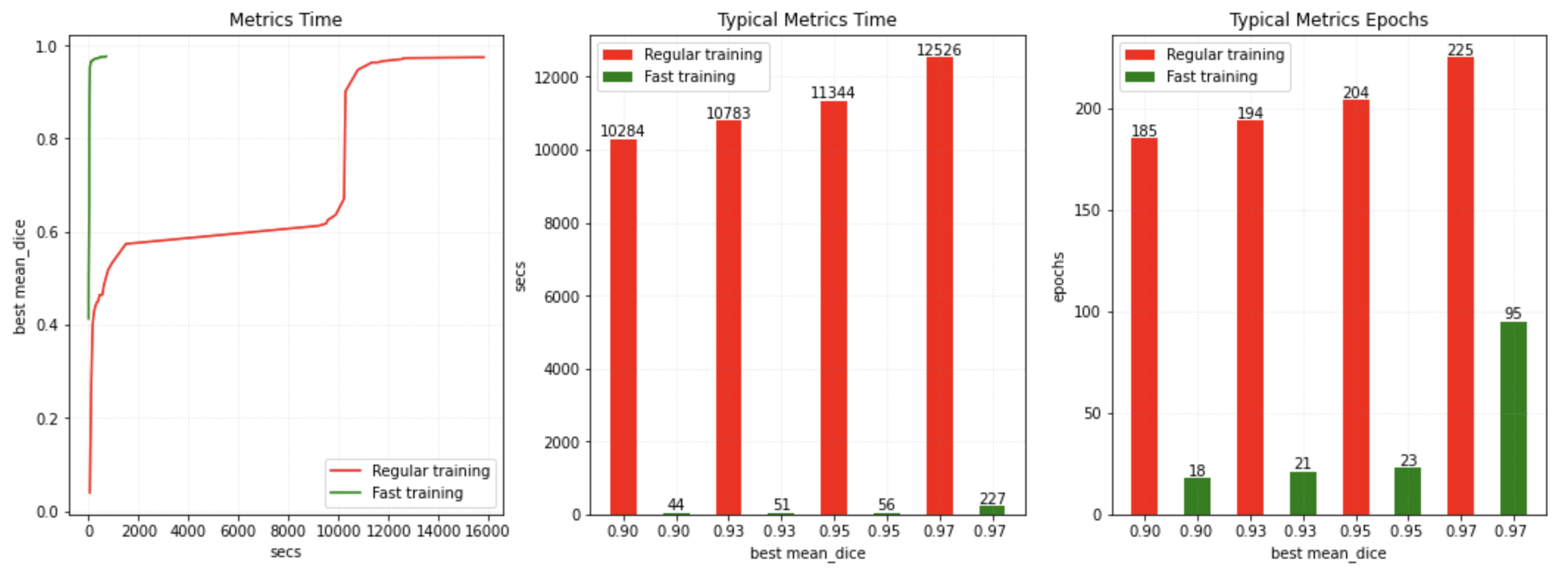
詳細は 高速訓練チュートリアル で利用可能です。
3. 分散データ並列
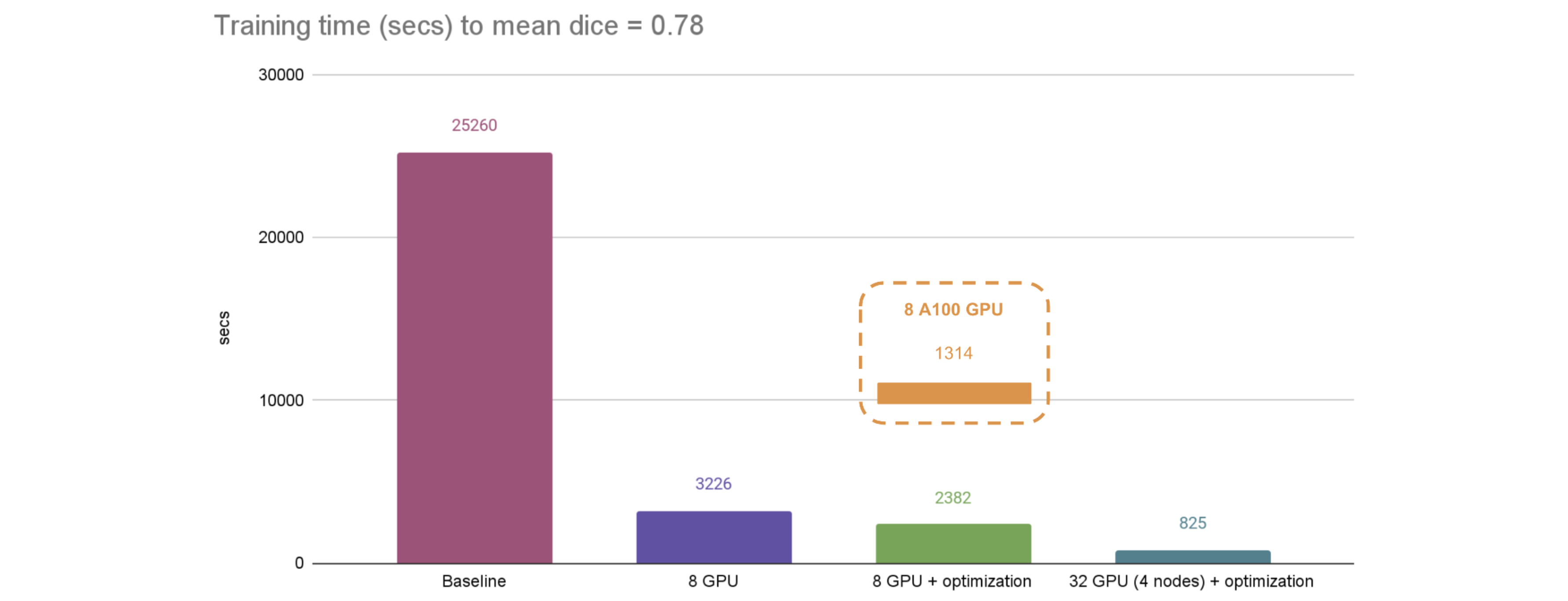
分散データ並列は、モデルを訓練または評価するためにシングル or マルチノード上で複数の GPU デバイスに接続するための PyTorch の重要な機能です。MONAI の分散データ並列 API はネイティブ PyTorch 分散モジュール、pytorch-ignite 分散モジュール、Horovod、XLA そして SLURM プラットフォームと互換です。MONAI は参考のためのデモを提供しています : PyTorch DDP による訓練/評価、Horovod による訓練/評価、Ignite DDP による訓練/評価、SmartCacheDataset によるデータセットの分割と訓練、そして Decathlon チャンレンジ Task01 に基づく現実世界の訓練サンプル – 脳腫瘍セグメンテーション 等です。チュートリアル は分散キャッシング、訓練と検証を含みます。参考のためにパフォーマンス・ベンチマークを取得しました (PyTorch 1.9.1, CUDA 11.4, NVIDIA V100 GPU に基づいています。最適化は、より多くの GPU リソースにより、データを分割し GPU メモリにキャッシュして GPU 変換を直接実行できるという意味です)。
4. C++/CUDA 最適化モジュール
ワークフローのドメイン固有のルーチンを更に高速化するため、MONAI C++/CUDA 実装が PyTorch ネイティブ実装の拡張として導入されました。MONAI は PyTorch から C++ 拡張を構築する 2 つの方法 を使用してモジュールを提供します。
- Resampler, Conditional random field (CRF), permutohedral 格子を使用する Fast bilateral フィルタリングを含むモジュールについては、setuptools を通して。
- Gaussian mixtures (ガウス混合) モジュールについては、just-in-time (JIT) コンパイルを通しています。このアプローチはユーザが指定したパラメータとローカルシステム環境に従って動的最適化を可能にします。次の図は、組織と手術器具のセグメンテーションに適用された MONAI のガウス混合モデルの結果を示しています :
5. Cache IO and transforms data to GPU memory
CacheDataset を使用してさえも、通常はエポック毎に GPU ランダム変換やネットワーク計算のために同じデータを GPU メモリにコピーする必要があります。効率的なアプローチはデータを GPU メモリに直接キャッシュすれば、総てのエポックで GPU 計算を直ちに始められます。
例えば :
train_transforms = [
LoadImaged(...),
AddChanneld(...),
Spacingd(...),
Orientationd(...),
ScaleIntensityRanged(...),
EnsureTyped(..., data_type="tensor"),
ToDeviced(..., device="cuda:0"),
RandCropByPosNegLabeld(...),
]
dataset = CacheDataset(..., transform=train_trans)
ここでは EnsureTyped 変換で PyTorch テンソルに変換して、ToDeviced 変換でデータを GPU に移しています。CacheDataset が変換結果を ToDeviced までキャッシュしますので、それは GPU メモリ内にあります。そしてエポック毎に、プログラムは GPU メモリからキャッシュされたデータを取得して GPU 上でランダム変換 RandCropByPosNegLabeld だけを直接実行します。GPU キャッシング・サンプルは 脾臓高速訓練チュートリアル で利用可能です。
アプリケーション
医用画像深層学習の研究エリアは急速に拡大しています。最新の成果をアプリケーションに応用するため、MONAI は、他の類似のユースケースのために end-to-end なソリューションやプロトタイプを構築するために多くのアプリケーション・コンポーネントを含みます。
1. 対話的セグメンテーションのための DeepGrow モジュール
DeepGrow コンポーネントの再実装です、これは深層学習ベースの半自動のセグメンテーション・アプローチで、医用画像の関心領域描写のための「スマートな」対話的ツールを目的としていて、元は次により提案されました :
Sakinis, Tomas, et al. “Interactive segmentation of medical images through fully convolutional neural networks.” arXiv preprint arXiv:1903.08205 (2019).
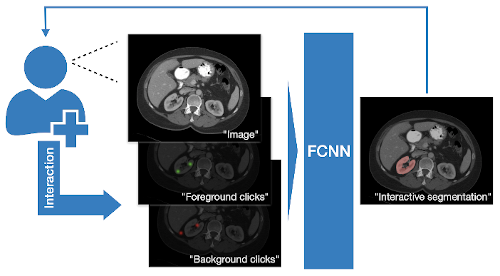
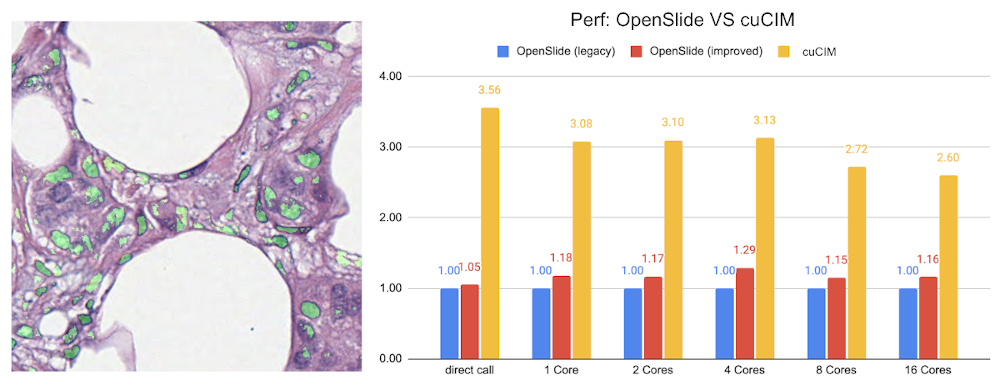
2. デジタルパソロジーの病変検出
パソロジー検出コンポーネントの 実装 で、NVIDIA cuCIM ライブラリと SmartCache メカニズムによる効率的なスライド全体の画像 IO とサンプリング、病変の FROC 測定、そして病変検出のための確率的後処理を含みます。
3. 学習ベースの画像レジストレーション
v0.5.0 から、MONAI は学習ベースの 2D/3D レジストレーション・ワークフローを構築するための実験的な機能を提供しています。これらは損失関数として画像類似尺度、モデル正則化として曲げエネルギー (= bending energy)、ネットワーク・アーキテクチャ、ワーピング・モジュールを含みます。コンポーネントは主要な教師なし、弱 (= weakly) 教師ありアルゴリズムを構築するために使用できます。
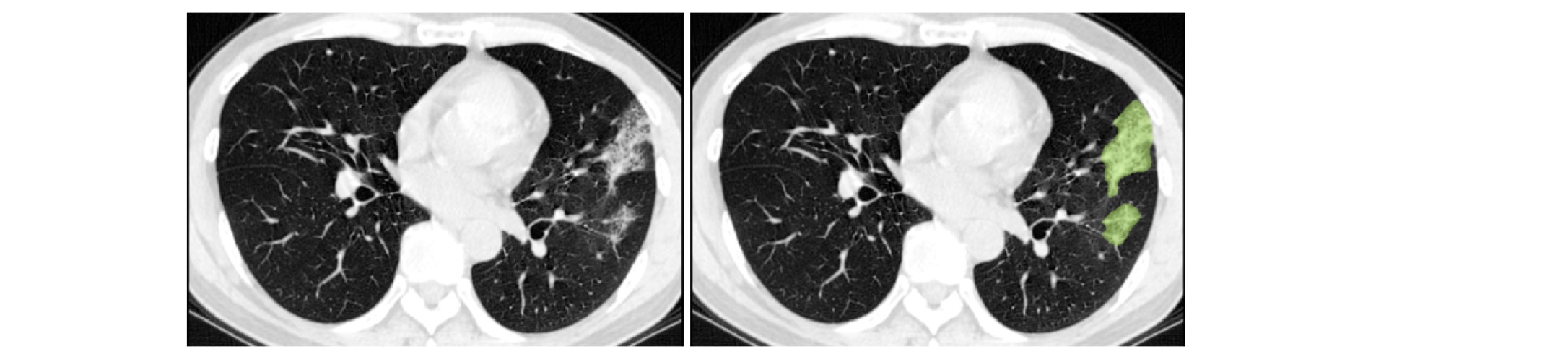
以下の図は、MONAI を使用して単一の患者の異なる時間点で得られた CT 画像のレジストレーションを示します :

4. 最先端の Kaggle コンペティション・ソリューションの再現
RANZCR CLiP – カテーテルと Line Position チャレンジ in Kaggle: https://www.kaggle.com/c/ranzcr-clip-catheter-line-classification の 4 位のソリューションの 再実装 です。
元のソリューションは Team Watercooled により作成され、そして作者は Dieter (https://www.kaggle.com/christofhenkel) と Psi (https://www.kaggle.com/philippsinger) です。
以上