MONAI 0.7 : モジュール概要 (2) データセットとデータローダ (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 10/19/2021 (0.7.0)
* 本ページは、MONAI の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。

- 人工知能研究開発支援
- 人工知能研修サービス(経営者層向けオンサイト研修)
- テクニカルコンサルティングサービス
- 実証実験(プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
- PoC(概念実証)を失敗させないための支援
- テレワーク & オンライン授業を支援
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |
MONAI 0.7 : モジュール概要 (2) データセットとデータローダ
Datasets と DataLoader
1. 訓練を高速化するためのキャッシュ IO と変換データ
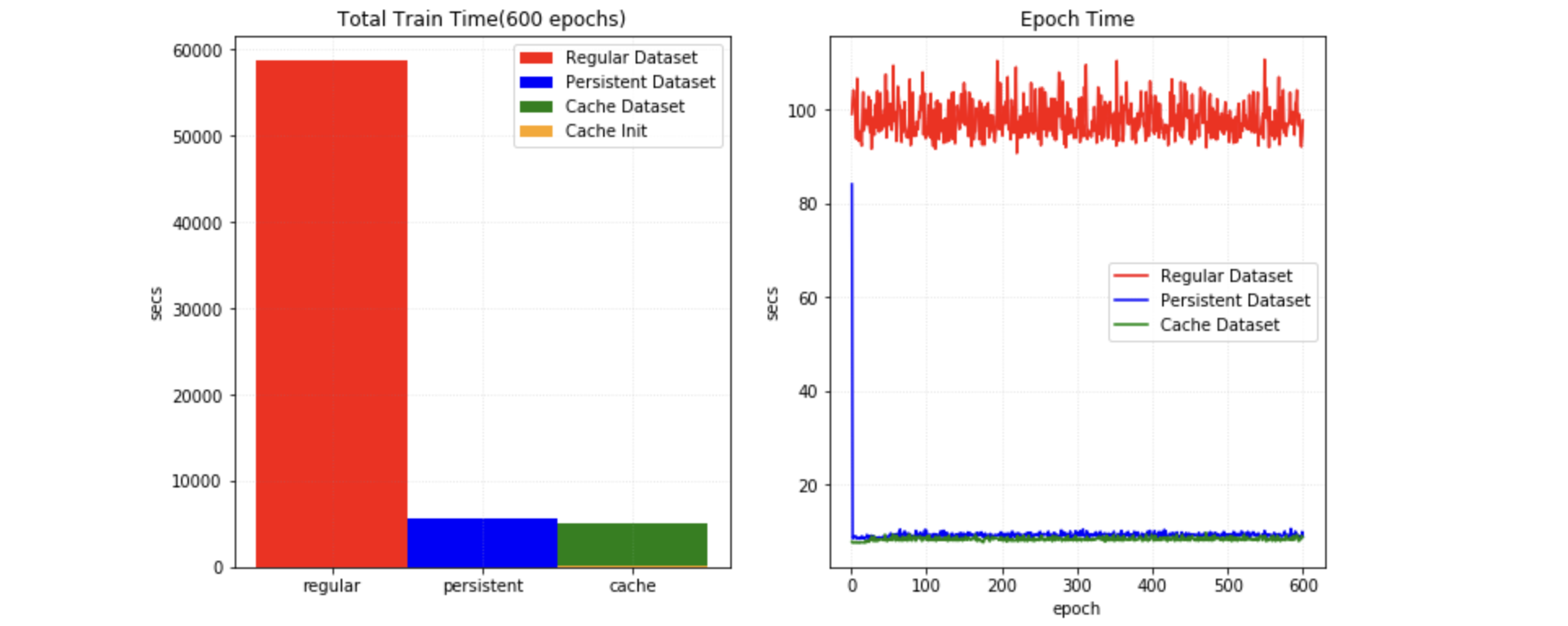
ユーザは望まれるモデル品質を獲得するためにデータに渡り多くの (潜在的には数千の) エポックでモデルを訓練する必要が多くの場合あります。ネイティブ PyTorch 実装はデータを繰り返しロードして訓練の間総てのエポックについて同じ前処理ステップを実行する場合がありますが、これは時間がかかり不必要である可能性があります、特に医用画像ボリュームが大きいときには。
MONAI は、変換チェインの最初のランダム化された変換の前に、中間的な結果をストアして訓練の間これらの変換ステップを高速化するためにマルチスレッド CacheDataset と LMDBDataset を提供しています。この機能を有効にすると Datasets 実験の 10x 訓練スピードアップを潜在的に与えられるでしょう。
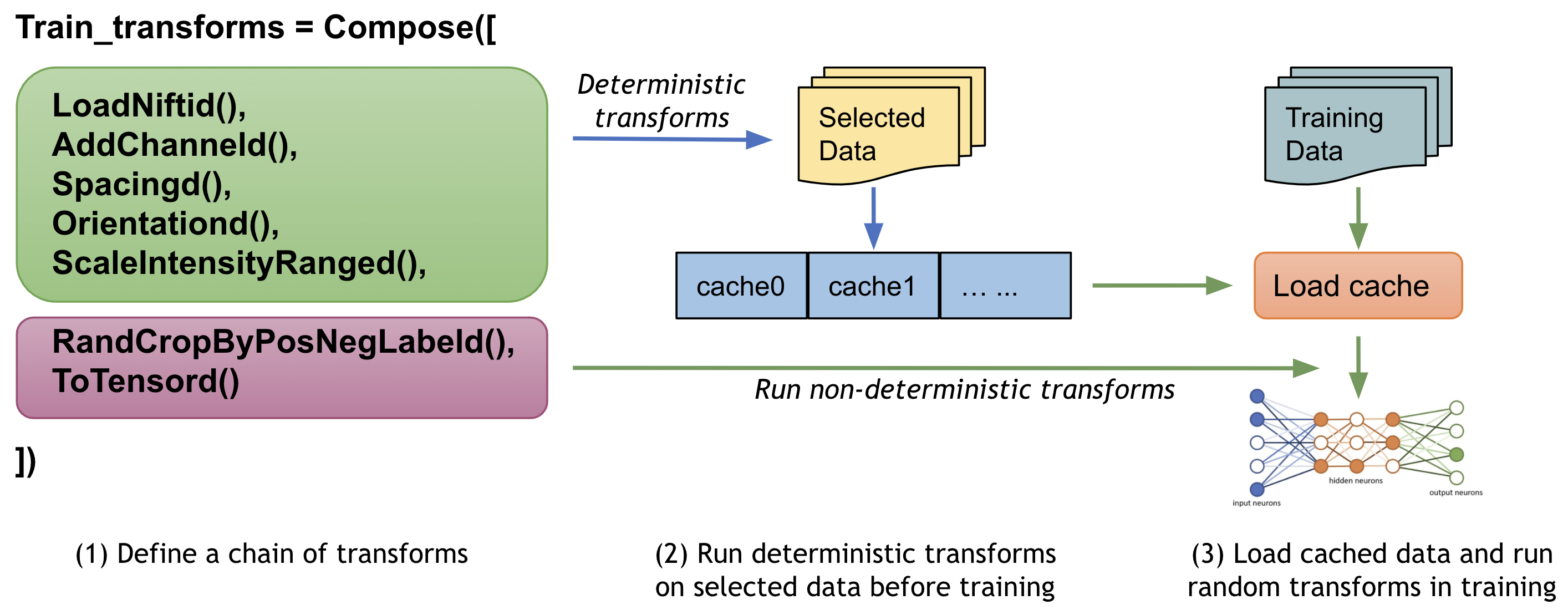
2. 中間結果を永続的なストレージにキャッシュする
PersistentDataset は CacheDataset に類似しています、そこでは (ハイパーパラメータ調整のときのような) 実験的な実行の間やデータセット全体のサイズが利用可能なメモリを越えるときの迅速な検索のために、中間的なキャッシュ値がディスク・ストレージや LMDB に永続化されます。PersistentDataset は Dataset 実験で CacheDataset と比較したとき同様の性能を獲得できました。
3. 大規模データベースのための SmartCache 機構
大規模なボリュームのデータセットによる訓練の間、効率的なアプローチはエポックでデータセットのサブセットだけを使用して訓練して総てのエポックでサブセットの部分を動的に置き換えることです。それは NVIDIA Clara-train SDK の SmartCache メカニズムです。
MONAI は PyTorch 版 SmartCache を SmartCacheDataset を提供しています。各エポックで、キャッシュの項目だけが訓練に使用され、同時に、別のスレッドがキャシュにない項目に変換シークエンスを提供することにより置換項目を準備しています。1 エポックが完了すれば、SmartCache は置換項目で同じ数の項目を置き換えます。
例えば、5 画像 : [image1, image2, image3, image4, image5] を持ち、そして cache_num=4, replace_rate=0.25 とします。するとキャッシュされて置換される、実際の訓練画像は以下のようになります :
epoch 1: [image1, image2, image3, image4] epoch 2: [image2, image3, image4, image5] epoch 3: [image3, image4, image5, image1] epoch 3: [image4, image5, image1, image2] epoch N: [image[N % 5] ...]
SmartCacheDataset の完全なサンプルは Distributed training with SmartCache で利用可能です。
4. マルチ PyTorch データセットの zip と出力の融合
MONAI は複数の PyTorch データセットを関連付けて出力データを (同じ対応するバッチインデックスで) タプルに連結するための ZipDataset を提供します、これは様々なデータソースに基づいて複雑な訓練プロセスを実行するの役立つことができます。
例えば :
class DatasetA(Dataset):
def __getitem__(self, index: int):
return image_data[index]
class DatasetB(Dataset):
def __getitem__(self, index: int):
return extra_data[index]
dataset = ZipDataset([DatasetA(), DatasetB()], transform)
5. PatchDataset
monai.data.PatchDataset は画像- とパッチ-レベル前処理の両方を組み合わせる柔軟な API を提供します :
image_dataset = Dataset(input_images, transforms=image_transforms)
patch_dataset = PatchDataset(
dataset=image_dataset, patch_func=sampler,
samples_per_image=n_samples, transform=patch_transforms)
それはカスタマイズ可能なパッチサンプリング・ストラテジーを使用してユーザ指定の image_transforms と patch_transforms をサポートします、これはマルチプロセス・コンテキストで 2 レベルの計算を切り離します。
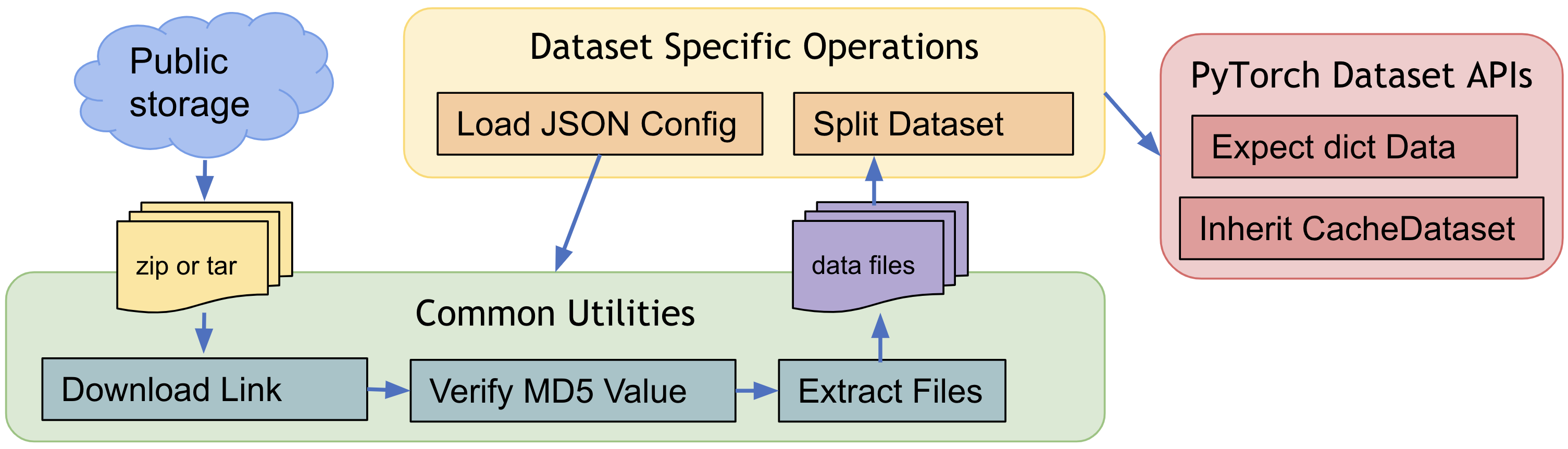
6. 公開医療データの事前定義されたデータセット
医療ドメインのポピュラーな訓練データで素早く始めるために、MONAI は幾つかのデータ固有のデータセットを提供しています、これは AWS ストレージからのダウンロード、データファイルの抽出を含み、変換とともに訓練/評価項目の生成をサポートしています。そしてそれらはデフォルトの動作を変更する JSON config ファイルを簡単に変更できるという点で柔軟です。
MONAI は公開データセットの新しい寄与を常に歓迎しています、既存のデータセットを参照してダウンロードと抽出 API を活用してください、等々。公開データセット・チュートリアル は MedNISTDataset と DecathlonDataset で訓練ワークフローを素早くセットアップする方法と公開データのために新しいデータセットを作成する方法を示しています。
事前定義されたデータセットの一般的なワークフロー :
7. 交差検証のためにデータセットを分割する
MONAI の partition_dataset は訓練と検証のためあるいは交差検証のために様々なタイプの分割を実行できます。それは指定されたランダムシードに基づくシャッフルをサポートし、各データセットが一つの分割を含む、データセットのセットを返します。そしてそれは指定された比率に基づいてデータセットを分割したり、num_partitions に均等に分割することもできます。与えられたクラスラベルについて、総てのパーティションでクラスの同じ比率を確実にすることもできます。
8. CSV データセットと IterableDataset
CSV テーブルは画像データに加えて患者の人口統計, 検査結果, 画像収集パラメータと他の非画像データのような補助的な情報を組み込むためによく使用され、MONAI は CSV ファイルをロードするために CSVDataset をそしてスケーラブルなデータアクセスにより大規模な CSV ファイルをロードするために CSVIterableDataset をロードするために CSVIterableDataset を提供しています。ロードの間の通常の前処理変換に加えて、それはまた複数の CSV ファイルロード、テーブルの結合、行と列の選択とグループ化もサポートします。CSVDatasets チュートリアル は詳細な使用例を示しています。
9. ThreadDataLoader vs. DataLoader
変換が軽量である場合、特に総てのデータを RAM にキャッシュするとき、PyTorch DataLoader のマルチプロセッシングは不必要な IPC 時間を引き起こして総てのエポックの後に GPU 利用率の低下を引き起こす可能性があります。MONAI は変換を個別のスレッドで実行する ThreadDataLoader を提供しています :
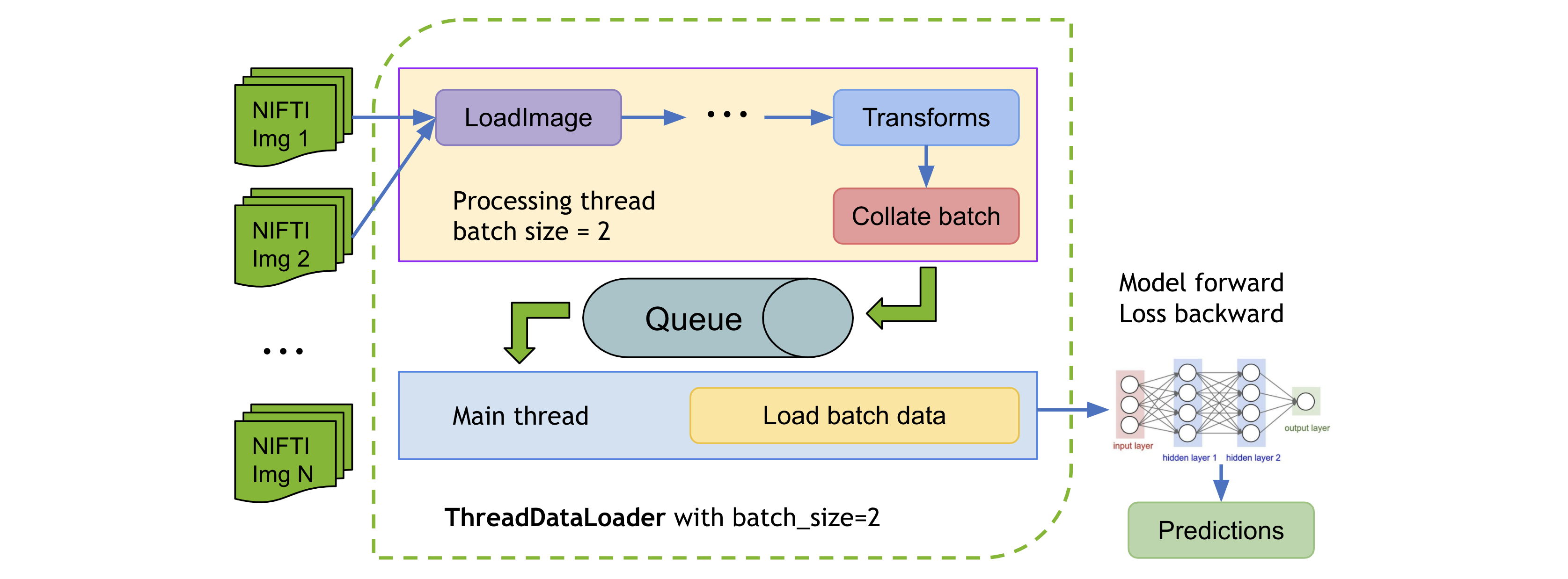
ThreadDataLoader サンプルは 脾臓高速訓練チュートリアル で利用可能です。
以上