MONAI 0.7 : tutorials : モジュール – MedNIST データセットによる Autoencoder ネットワーク (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 10/09/2021 (0.7.0)
* 本ページは、MONAI の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。

- 人工知能研究開発支援
- 人工知能研修サービス(経営者層向けオンサイト研修)
- テクニカルコンサルティングサービス
- 実証実験(プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
- PoC(概念実証)を失敗させないための支援
- テレワーク & オンライン授業を支援
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |
MONAI 0.7 : tutorials : モジュール – MedNIST データセットによる Autoencoder ネットワーク
このチュートリアルは MONAI の autoencoder クラスを実演するために MedNIST ハンド CT スキャン・データセットを使用します。autoencoder は恒等エンコード/デコードで使用され (i.e. 入れたものが戻されるべきもの)、そしてぼかしやノイズの除去の使用方法として実演します。
このノートブックは画像のぼかし/ノイズ除去の目的で MONAI で autoencoeder の使用を示します。
学習目標
これは以下のステップを通り抜けます :
- 遠隔ソースからデータをロードする
- 画像の辞書を作成するために lambda を使用する
- MONAI の組込み AutoEncoder を使用する
環境のセットアップ
!python -c "import monai" || pip install -q "monai-weekly[pillow, tqdm]"
1. インポートと設定
import logging
import os
import shutil
import sys
import tempfile
import random
import numpy as np
from tqdm import trange
import matplotlib.pyplot as plt
import torch
from skimage.util import random_noise
from monai.apps import download_and_extract
from monai.config import print_config
from monai.data import CacheDataset, DataLoader
from monai.networks.nets import AutoEncoder
from monai.transforms import (
AddChannelD,
Compose,
LoadImageD,
RandFlipD,
RandRotateD,
RandZoomD,
ScaleIntensityD,
EnsureTypeD,
Lambda,
)
from monai.utils import set_determinism
print_config()
MONAI version: 0.6.0rc1+23.gc6793fd0
Numpy version: 1.20.3
Pytorch version: 1.9.0a0+c3d40fd
MONAI flags: HAS_EXT = True, USE_COMPILED = False
MONAI rev id: c6793fd0f316a448778d0047664aaf8c1895fe1c
Optional dependencies:
Pytorch Ignite version: 0.4.5
Nibabel version: 3.2.1
scikit-image version: 0.15.0
Pillow version: 8.2.0
Tensorboard version: 2.5.0
gdown version: 3.13.0
TorchVision version: 0.10.0a0
ITK version: 5.1.2
tqdm version: 4.53.0
lmdb version: 1.2.1
psutil version: 5.8.0
pandas version: 1.1.4
einops version: 0.3.0
For details about installing the optional dependencies, please visit:
https://docs.monai.io/en/latest/installation.html#installing-the-recommended-dependencies
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
set_determinism(0)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Create small visualistaion function
def plot_ims(ims, shape=None, figsize=(10, 10), titles=None):
shape = (1, len(ims)) if shape is None else shape
plt.subplots(*shape, figsize=figsize)
for i, im in enumerate(ims):
plt.subplot(*shape, i + 1)
im = plt.imread(im) if isinstance(im, str) else torch.squeeze(im)
plt.imshow(im, cmap='gray')
if titles is not None:
plt.title(titles[i])
plt.axis('off')
plt.tight_layout()
plt.show()
データを取得する
MedMNIST データセットは TCIA, RSNA Bone Age チャレンジ と NIH Chest X-ray データセット からの様々なセットから集められました。
データセットは Dr. Bradley J. Erickson M.D., Ph.D. (Department of Radiology, Mayo Clinic) のお陰により Creative Commons CC BY-SA 4.0 ライセンス のもとで利用可能になっています。
directory = os.environ.get("MONAI_DATA_DIRECTORY")
root_dir = tempfile.mkdtemp() if directory is None else directory
print(root_dir)
/workspace/data/medical
resource = "https://drive.google.com/uc?id=1QsnnkvZyJPcbRoV_ArW8SnE1OTuoVbKE"
md5 = "0bc7306e7427e00ad1c5526a6677552d"
compressed_file = os.path.join(root_dir, "MedNIST.tar.gz")
data_dir = os.path.join(root_dir, "MedNIST")
if not os.path.exists(data_dir):
download_and_extract(resource, compressed_file, root_dir, md5)
# scan_type could be AbdomenCT BreastMRI CXR ChestCT Hand HeadCT
scan_type = "Hand"
im_dir = os.path.join(data_dir, scan_type)
all_filenames = [os.path.join(im_dir, filename)
for filename in os.listdir(im_dir)]
random.shuffle(all_filenames)
# Visualise a few of them
rand_images = np.random.choice(all_filenames, 8, replace=False)
plot_ims(rand_images, shape=(2, 4))
# Split into training and testing
test_frac = 0.2
num_test = int(len(all_filenames) * test_frac)
num_train = len(all_filenames) - num_test
train_datadict = [{"im": fname} for fname in all_filenames[:num_train]]
test_datadict = [{"im": fname} for fname in all_filenames[-num_test:]]
print(f"total number of images: {len(all_filenames)}")
print(f"number of images for training: {len(train_datadict)}")
print(f"number of images for testing: {len(test_datadict)}")
total number of images: 10000 number of images for training: 8000 number of images for testing: 2000
3. 画像変換チェインを作成する
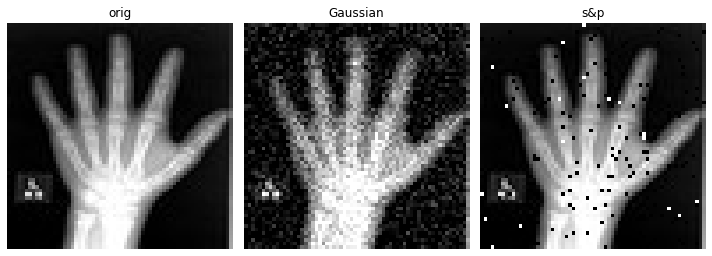
画像のぼやけ/ノイズを除去するために autoencoder を訓練するため、劣化画像をエンコーダに渡すことを望みますが、損失関数では、元の、劣化していないバージョンとの比較を行ないます。この意味で、エンコードとデコードステップが劣化を除去できたときに、損失関数は最小化されます。
画像の一つのバージョンが劣化していて他方がそうではないという事実以外に、それらが同一であるようにすることを望みます、これは同じ変換から生成される必要があることを意味します。これを行なう最も簡単な方法は辞書変換を介することです、そこでは最後に、3 つの画像- オリジナル、ガウスぼかしとノイズのある (画像) を含む辞書を返す lambda 関数をもちます。
NoiseLambda = Lambda(lambda d: {
"orig": d["im"],
"gaus": torch.tensor(
random_noise(d["im"], mode='gaussian'), dtype=torch.float32),
"s&p": torch.tensor(random_noise(d["im"], mode='s&p', salt_vs_pepper=0.1)),
})
train_transforms = Compose(
[
LoadImageD(keys=["im"]),
AddChannelD(keys=["im"]),
ScaleIntensityD(keys=["im"]),
RandRotateD(keys=["im"], range_x=np.pi / 12, prob=0.5, keep_size=True),
RandFlipD(keys=["im"], spatial_axis=0, prob=0.5),
RandZoomD(keys=["im"], min_zoom=0.9, max_zoom=1.1, prob=0.5),
EnsureTypeD(keys=["im"]),
NoiseLambda,
]
)
test_transforms = Compose(
[
LoadImageD(keys=["im"]),
AddChannelD(keys=["im"]),
ScaleIntensityD(keys=["im"]),
EnsureTypeD(keys=["im"]),
NoiseLambda,
]
)
データセットとデーたローダを作成する
データを保持して訓練の間にバッチを提示する
batch_size = 300
num_workers = 10
train_ds = CacheDataset(train_datadict, train_transforms,
num_workers=num_workers)
train_loader = DataLoader(train_ds, batch_size=batch_size,
shuffle=True, num_workers=num_workers)
test_ds = CacheDataset(test_datadict, test_transforms, num_workers=num_workers)
test_loader = DataLoader(test_ds, batch_size=batch_size,
shuffle=True, num_workers=num_workers)
100%|██████████| 8000/8000 [00:02<00:00, 2698.01it/s] 100%|██████████| 2000/2000 [00:02<00:00, 904.36it/s]
# Get image original and its degraded versions
def get_single_im(ds):
loader = torch.utils.data.DataLoader(
ds, batch_size=1, num_workers=10, shuffle=True)
itera = iter(loader)
return next(itera)
data = get_single_im(train_ds)
plot_ims([data['orig'], data['gaus'], data['s&p']],
titles=['orig', 'Gaussian', 's&p'])
def train(dict_key_for_training, max_epochs=10, learning_rate=1e-3):
model = AutoEncoder(
spatial_dims=2,
in_channels=1,
out_channels=1,
channels=(4, 8, 16, 32),
strides=(2, 2, 2, 2),
).to(device)
# Create loss fn and optimiser
loss_function = torch.nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), learning_rate)
epoch_loss_values = []
t = trange(
max_epochs,
desc=f"{dict_key_for_training} -- epoch 0, avg loss: inf", leave=True)
for epoch in t:
model.train()
epoch_loss = 0
step = 0
for batch_data in train_loader:
step += 1
inputs = batch_data[dict_key_for_training].to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = loss_function(outputs, batch_data['orig'].to(device))
loss.backward()
optimizer.step()
epoch_loss += loss.item()
epoch_loss /= step
epoch_loss_values.append(epoch_loss)
t.set_description(
f"{dict_key_for_training} -- epoch {epoch + 1}"
+ f", average loss: {epoch_loss:.4f}")
return model, epoch_loss_values
max_epochs = 50
training_types = ['orig', 'gaus', 's&p']
models = []
epoch_losses = []
for training_type in training_types:
model, epoch_loss = train(training_type, max_epochs=max_epochs)
models.append(model)
epoch_losses.append(epoch_loss)
orig -- epoch 30, average loss: 0.0110: 60%|██████ | 30/50 [01:41<01:08, 3.40s/it]
plt.figure()
plt.title("Epoch Average Loss")
plt.xlabel("epoch")
for y, label in zip(epoch_losses, training_types):
x = list(range(1, len(y) + 1))
line, = plt.plot(x, y)
line.set_label(label)
plt.legend()
data = get_single_im(test_ds)
recons = []
for model, training_type in zip(models, training_types):
im = data[training_type]
recon = model(im.to(device)).detach().cpu()
recons.append(recon)
plot_ims(
[data['orig'], data['gaus'], data['s&p']] + recons,
titles=['orig', 'Gaussian', 'S&P'] +
["recon w/\n" + x for x in training_types],
shape=(2, len(training_types)))
データディレクトリのクリーンアップ
一時ディレクトリが使用された場合ディレクトリを削除します。
if directory is None:
shutil.rmtree(root_dir)
以上