MONAI 0.7 : tutorials : 2D 分類 – MedNIST データセットによる医用画像分類 (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 10/05/2021 (0.7.0)
* 本ページは、MONAI の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。

- 人工知能研究開発支援
- 人工知能研修サービス(経営者層向けオンサイト研修)
- テクニカルコンサルティングサービス
- 実証実験(プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
- PoC(概念実証)を失敗させないための支援
- テレワーク & オンライン授業を支援
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |
MONAI 0.7 : tutorials : 2D 分類 – MedNIST データセットによる医用画像分類
このノートブックは MONAI 機能を既存の PyTorch プログラムに容易に統合する方法を示します。それは MedNIST データセットに基づいています、これは初心者のためにチュートリアルとして非常に適切です。このチュートリアルはまた MONAI 組込みのオクルージョン感度の機能も利用しています。
また、このチュートリアルでは、MONAIに内蔵されているオクルージョン感度機能も利用しています。
このチュートリアルでは、MedNIST データセットに基づく end-to-end な訓練と評価サンプルを紹介します。
以下のステップで進めます :
- 訓練とテストのためにデータセットを作成する。
- データを前処理するために MONAI 変換を利用します。
- 分類のために MONAI から DenseNet を利用します。
- モデルを PyTorch プログラムで訓練します。
- テストデータセット上で評価します。
環境のセットアップ
!python -c "import monai" || pip install -q "monai-weekly[pillow, tqdm]"
!python -c "import matplotlib" || pip install -q matplotlib
%matplotlib inline
インポートのセットアップ
# Copyright 2020 MONAI Consortium
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
# http://www.apache.org/licenses/LICENSE-2.0
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import os
import shutil
import tempfile
import matplotlib.pyplot as plt
import PIL
import torch
import numpy as np
from sklearn.metrics import classification_report
from monai.apps import download_and_extract
from monai.config import print_config
from monai.data import decollate_batch
from monai.metrics import ROCAUCMetric
from monai.networks.nets import DenseNet121
from monai.transforms import (
Activations,
AddChannel,
AsDiscrete,
Compose,
LoadImage,
RandFlip,
RandRotate,
RandZoom,
ScaleIntensity,
EnsureType,
)
from monai.utils import set_determinism
print_config()
MONAI version: 0.6.0rc1+15.gf3d436a0
Numpy version: 1.20.3
Pytorch version: 1.9.0a0+c3d40fd
MONAI flags: HAS_EXT = True, USE_COMPILED = False
MONAI rev id: f3d436a09deefcf905ece2faeec37f55ab030003
Optional dependencies:
Pytorch Ignite version: 0.4.5
Nibabel version: 3.2.1
scikit-image version: 0.15.0
Pillow version: 8.2.0
Tensorboard version: 2.5.0
gdown version: 3.13.0
TorchVision version: 0.10.0a0
ITK version: 5.1.2
tqdm version: 4.53.0
lmdb version: 1.2.1
psutil version: 5.8.0
pandas version: 1.1.4
einops version: 0.3.0
For details about installing the optional dependencies, please visit:
https://docs.monai.io/en/latest/installation.html#installing-the-recommended-dependencies
データディレクトリのセットアップ
MONAI_DATA_DIRECTORY 環境変数でディレクトリを指定できます。これは結果をセーブしてダウンロードを再利用することを可能にします。指定されない場合、一時ディレクトリが使用されます。
directory = os.environ.get("MONAI_DATA_DIRECTORY")
root_dir = tempfile.mkdtemp() if directory is None else directory
print(root_dir)
/workspace/data/medical
データセットをダウンロードする
MedMNIST データセットは TCIA, RSNA Bone Age チャレンジ と NIH Chest X-ray データセット からの様々なセットから集められました。
データセットは Dr. Bradley J. Erickson M.D., Ph.D. (Department of Radiology, Mayo Clinic) のお陰により Creative Commons CC BY-SA 4.0 ライセンス のもとで利用可能になっています。
MedNIST データセットを使用する場合、出典を明示してください。
resource = "https://drive.google.com/uc?id=1QsnnkvZyJPcbRoV_ArW8SnE1OTuoVbKE"
md5 = "0bc7306e7427e00ad1c5526a6677552d"
compressed_file = os.path.join(root_dir, "MedNIST.tar.gz")
data_dir = os.path.join(root_dir, "MedNIST")
if not os.path.exists(data_dir):
download_and_extract(resource, compressed_file, root_dir, md5)
再現性のために決定論的訓練を設定する
set_determinism(seed=0)
データセットフォルダから画像ファイル名を読む
まず最初に、データセットファイルを確認して幾つかの統計を表示します。
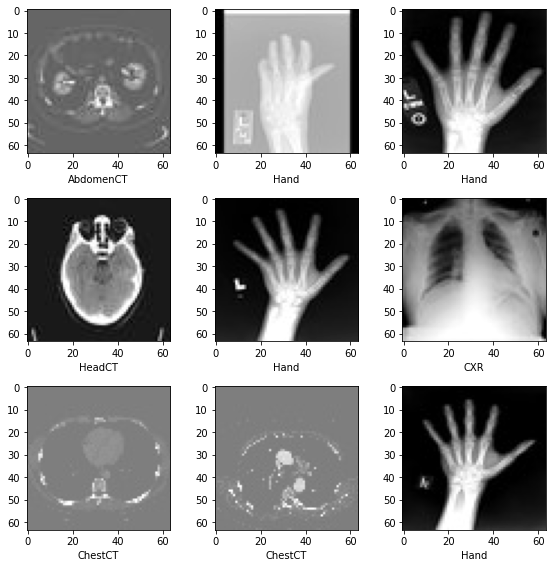
データセットには 6 つのフォルダがあります : Hand, AbdomenCT, CXR, ChestCT, BreastMRI, HeadCT,
これらは分類モデルを訓練するためにラベルとして使用されるべきです。
class_names = sorted(x for x in os.listdir(data_dir)
if os.path.isdir(os.path.join(data_dir, x)))
num_class = len(class_names)
image_files = [
[
os.path.join(data_dir, class_names[i], x)
for x in os.listdir(os.path.join(data_dir, class_names[i]))
]
for i in range(num_class)
]
num_each = [len(image_files[i]) for i in range(num_class)]
image_files_list = []
image_class = []
for i in range(num_class):
image_files_list.extend(image_files[i])
image_class.extend([i] * num_each[i])
num_total = len(image_class)
image_width, image_height = PIL.Image.open(image_files_list[0]).size
print(f"Total image count: {num_total}")
print(f"Image dimensions: {image_width} x {image_height}")
print(f"Label names: {class_names}")
print(f"Label counts: {num_each}")
Total image count: 58954 Image dimensions: 64 x 64 Label names: ['AbdomenCT', 'BreastMRI', 'CXR', 'ChestCT', 'Hand', 'HeadCT'] Label counts: [10000, 8954, 10000, 10000, 10000, 10000]
データセットから画像をランダムに選択して可視化して確認する
plt.subplots(3, 3, figsize=(8, 8))
for i, k in enumerate(np.random.randint(num_total, size=9)):
im = PIL.Image.open(image_files_list[k])
arr = np.array(im)
plt.subplot(3, 3, i + 1)
plt.xlabel(class_names[image_class[k]])
plt.imshow(arr, cmap="gray", vmin=0, vmax=255)
plt.tight_layout()
plt.show()
訓練、検証とテストデータのリストを準備する
データセットの 10% を検証用に、そして 10% をテスト用にランダムに選択します。
val_frac = 0.1
test_frac = 0.1
length = len(image_files_list)
indices = np.arange(length)
np.random.shuffle(indices)
test_split = int(test_frac * length)
val_split = int(val_frac * length) + test_split
test_indices = indices[:test_split]
val_indices = indices[test_split:val_split]
train_indices = indices[val_split:]
train_x = [image_files_list[i] for i in train_indices]
train_y = [image_class[i] for i in train_indices]
val_x = [image_files_list[i] for i in val_indices]
val_y = [image_class[i] for i in val_indices]
test_x = [image_files_list[i] for i in test_indices]
test_y = [image_class[i] for i in test_indices]
print(
f"Training count: {len(train_x)}, Validation count: "
f"{len(val_x)}, Test count: {len(test_x)}")
Training count: 47156, Validation count: 5913, Test count: 5885
データを前処理するために MONAI 変換、Dataset と Dataloader を定義する
train_transforms = Compose(
[
LoadImage(image_only=True),
AddChannel(),
ScaleIntensity(),
RandRotate(range_x=np.pi / 12, prob=0.5, keep_size=True),
RandFlip(spatial_axis=0, prob=0.5),
RandZoom(min_zoom=0.9, max_zoom=1.1, prob=0.5),
EnsureType(),
]
)
val_transforms = Compose(
[LoadImage(image_only=True), AddChannel(), ScaleIntensity(), EnsureType()])
y_pred_trans = Compose([EnsureType(), Activations(softmax=True)])
y_trans = Compose([EnsureType(), AsDiscrete(to_onehot=True, num_classes=num_class)])
class MedNISTDataset(torch.utils.data.Dataset):
def __init__(self, image_files, labels, transforms):
self.image_files = image_files
self.labels = labels
self.transforms = transforms
def __len__(self):
return len(self.image_files)
def __getitem__(self, index):
return self.transforms(self.image_files[index]), self.labels[index]
train_ds = MedNISTDataset(train_x, train_y, train_transforms)
train_loader = torch.utils.data.DataLoader(
train_ds, batch_size=300, shuffle=True, num_workers=10)
val_ds = MedNISTDataset(val_x, val_y, val_transforms)
val_loader = torch.utils.data.DataLoader(
val_ds, batch_size=300, num_workers=10)
test_ds = MedNISTDataset(test_x, test_y, val_transforms)
test_loader = torch.utils.data.DataLoader(
test_ds, batch_size=300, num_workers=10)
ネットワークと optimizer を定義する
- バッチ毎にモデルがどのくらい更新されるかについて学習率を設定します。
- 合計エポック数を設定します、シャッフルしてランダムな変換を行ないますので、総てのエポックの訓練データは異なります。そしてこれは get start チュートリアルに過ぎませんので、4 エポックだけ訓練しましょう。10 エポック訓練すれば、モデルはテストデータセット上で 100% 精度を達成できます。
- MONAI からの DenseNet を使用して GPU デバイスに移動します、この DenseNet は 2D と 3D 分類タスクの両方をサポートできます。
- Adam optimizer を使用します。
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") model = DenseNet121(spatial_dims=2, in_channels=1, out_channels=num_class).to(device) loss_function = torch.nn.CrossEntropyLoss() optimizer = torch.optim.Adam(model.parameters(), 1e-5) max_epochs = 4 val_interval = 1 auc_metric = ROCAUCMetric()モデル訓練
典型的な PyTorch 訓練を実行します、これはエポック・ループとステップ・ループを実行して、総てのエポック後に検証を行ないます。ベストの検証精度を得た場合、モデル重みをファイルにセーブします。
best_metric = -1 best_metric_epoch = -1 epoch_loss_values = [] metric_values = [] for epoch in range(max_epochs): print("-" * 10) print(f"epoch {epoch + 1}/{max_epochs}") model.train() epoch_loss = 0 step = 0 for batch_data in train_loader: step += 1 inputs, labels = batch_data[0].to(device), batch_data[1].to(device) optimizer.zero_grad() outputs = model(inputs) loss = loss_function(outputs, labels) loss.backward() optimizer.step() epoch_loss += loss.item() print( f"{step}/{len(train_ds) // train_loader.batch_size}, " f"train_loss: {loss.item():.4f}") epoch_len = len(train_ds) // train_loader.batch_size epoch_loss /= step epoch_loss_values.append(epoch_loss) print(f"epoch {epoch + 1} average loss: {epoch_loss:.4f}") if (epoch + 1) % val_interval == 0: model.eval() with torch.no_grad(): y_pred = torch.tensor([], dtype=torch.float32, device=device) y = torch.tensor([], dtype=torch.long, device=device) for val_data in val_loader: val_images, val_labels = ( val_data[0].to(device), val_data[1].to(device), ) y_pred = torch.cat([y_pred, model(val_images)], dim=0) y = torch.cat([y, val_labels], dim=0) y_onehot = [y_trans(i) for i in decollate_batch(y)] y_pred_act = [y_pred_trans(i) for i in decollate_batch(y_pred)] auc_metric(y_pred_act, y_onehot) result = auc_metric.aggregate() auc_metric.reset() del y_pred_act, y_onehot metric_values.append(result) acc_value = torch.eq(y_pred.argmax(dim=1), y) acc_metric = acc_value.sum().item() / len(acc_value) if result > best_metric: best_metric = result best_metric_epoch = epoch + 1 torch.save(model.state_dict(), os.path.join( root_dir, "best_metric_model.pth")) print("saved new best metric model") print( f"current epoch: {epoch + 1} current AUC: {result:.4f}" f" current accuracy: {acc_metric:.4f}" f" best AUC: {best_metric:.4f}" f" at epoch: {best_metric_epoch}" ) print( f"train completed, best_metric: {best_metric:.4f} " f"at epoch: {best_metric_epoch}")---------- epoch 1/4 1/157, train_loss: 1.7898 2/157, train_loss: 1.7560 3/157, train_loss: 1.7461 4/157, train_loss: 1.7241 5/157, train_loss: 1.6973 6/157, train_loss: 1.6706 7/157, train_loss: 1.6388 8/157, train_loss: 1.6210 9/157, train_loss: 1.5989 10/157, train_loss: 1.5599 11/157, train_loss: 1.5826 12/157, train_loss: 1.5339 13/157, train_loss: 1.5235 14/157, train_loss: 1.5098 15/157, train_loss: 1.4746 16/157, train_loss: 1.4584 17/157, train_loss: 1.4365 18/157, train_loss: 1.4328 19/157, train_loss: 1.4274 20/157, train_loss: 1.4327 21/157, train_loss: 1.4017 22/157, train_loss: 1.3231 23/157, train_loss: 1.3180 24/157, train_loss: 1.3001 25/157, train_loss: 1.2958 26/157, train_loss: 1.3021 27/157, train_loss: 1.2336 28/157, train_loss: 1.2154 29/157, train_loss: 1.2595 30/157, train_loss: 1.2050 31/157, train_loss: 1.2161 32/157, train_loss: 1.2106 33/157, train_loss: 1.1495 34/157, train_loss: 1.1550 35/157, train_loss: 1.1246 36/157, train_loss: 1.1607 37/157, train_loss: 1.1126 38/157, train_loss: 1.0987 39/157, train_loss: 1.0694 40/157, train_loss: 1.1181 41/157, train_loss: 1.0576 42/157, train_loss: 1.0703 43/157, train_loss: 1.0414 44/157, train_loss: 1.0446 45/157, train_loss: 1.0313 46/157, train_loss: 0.9786 47/157, train_loss: 0.9767 48/157, train_loss: 0.9579 49/157, train_loss: 0.9659 50/157, train_loss: 1.0069 51/157, train_loss: 0.9868 52/157, train_loss: 0.9637 53/157, train_loss: 0.9301 54/157, train_loss: 0.9382 55/157, train_loss: 0.8923 56/157, train_loss: 0.9034 57/157, train_loss: 0.8674 58/157, train_loss: 0.8707 59/157, train_loss: 0.8876 60/157, train_loss: 0.8628 61/157, train_loss: 0.7709 62/157, train_loss: 0.8494 63/157, train_loss: 0.8264 64/157, train_loss: 0.8011 65/157, train_loss: 0.8186 66/157, train_loss: 0.8016 67/157, train_loss: 0.7813 68/157, train_loss: 0.7447 69/157, train_loss: 0.7201 70/157, train_loss: 0.7323 71/157, train_loss: 0.7332 72/157, train_loss: 0.7379 73/157, train_loss: 0.7495 74/157, train_loss: 0.7157 75/157, train_loss: 0.7007 76/157, train_loss: 0.7058 77/157, train_loss: 0.6814 78/157, train_loss: 0.6738 79/157, train_loss: 0.6449 80/157, train_loss: 0.6393 81/157, train_loss: 0.6238 82/157, train_loss: 0.6234 83/157, train_loss: 0.6262 84/157, train_loss: 0.6044 85/157, train_loss: 0.6005 86/157, train_loss: 0.5783 87/157, train_loss: 0.5570 88/157, train_loss: 0.5569 89/157, train_loss: 0.5633 90/157, train_loss: 0.5199 91/157, train_loss: 0.5846 92/157, train_loss: 0.5915 93/157, train_loss: 0.5612 94/157, train_loss: 0.5785 95/157, train_loss: 0.5654 96/157, train_loss: 0.5437 97/157, train_loss: 0.5429 98/157, train_loss: 0.5053 99/157, train_loss: 0.5221 100/157, train_loss: 0.4928 101/157, train_loss: 0.5064 102/157, train_loss: 0.5104 103/157, train_loss: 0.4830 104/157, train_loss: 0.4901 105/157, train_loss: 0.4957 106/157, train_loss: 0.4913 107/157, train_loss: 0.4722 108/157, train_loss: 0.4756 109/157, train_loss: 0.4803 110/157, train_loss: 0.4534 111/157, train_loss: 0.4383 112/157, train_loss: 0.4437 113/157, train_loss: 0.4264 114/157, train_loss: 0.4067 115/157, train_loss: 0.4268 116/157, train_loss: 0.4136 117/157, train_loss: 0.4115 118/157, train_loss: 0.4082 119/157, train_loss: 0.4246 120/157, train_loss: 0.4018 121/157, train_loss: 0.4161 122/157, train_loss: 0.3475 123/157, train_loss: 0.4233 124/157, train_loss: 0.4043 125/157, train_loss: 0.3192 126/157, train_loss: 0.3611 127/157, train_loss: 0.3475 128/157, train_loss: 0.3580 129/157, train_loss: 0.3286 130/157, train_loss: 0.3688 131/157, train_loss: 0.3205 132/157, train_loss: 0.3745 133/157, train_loss: 0.3709 134/157, train_loss: 0.3535 135/157, train_loss: 0.3729 136/157, train_loss: 0.2839 137/157, train_loss: 0.3614 138/157, train_loss: 0.2981 139/157, train_loss: 0.3280 140/157, train_loss: 0.3031 141/157, train_loss: 0.2994 142/157, train_loss: 0.3296 143/157, train_loss: 0.3032 144/157, train_loss: 0.2965 145/157, train_loss: 0.2955 146/157, train_loss: 0.3379 147/157, train_loss: 0.3339 148/157, train_loss: 0.3092 149/157, train_loss: 0.2723 150/157, train_loss: 0.3171 151/157, train_loss: 0.2933 152/157, train_loss: 0.2841 153/157, train_loss: 0.2723 154/157, train_loss: 0.2954 155/157, train_loss: 0.2955 156/157, train_loss: 0.2969 157/157, train_loss: 0.2674 158/157, train_loss: 0.2465 epoch 1 average loss: 0.7768 saved new best metric model current epoch: 1 current AUC: 0.9984 current accuracy: 0.9618 best AUC: 0.9984 at epoch: 1 ---------- epoch 2/4 1/157, train_loss: 0.2618 2/157, train_loss: 0.2525 3/157, train_loss: 0.2640 4/157, train_loss: 0.2566 5/157, train_loss: 0.2526 6/157, train_loss: 0.2337 7/157, train_loss: 0.2311 8/157, train_loss: 0.2351 9/157, train_loss: 0.2332 10/157, train_loss: 0.2783 11/157, train_loss: 0.2521 12/157, train_loss: 0.2458 13/157, train_loss: 0.2261 14/157, train_loss: 0.2362 15/157, train_loss: 0.2702 16/157, train_loss: 0.2399 17/157, train_loss: 0.2113 18/157, train_loss: 0.2452 19/157, train_loss: 0.2202 20/157, train_loss: 0.2124 21/157, train_loss: 0.2050 22/157, train_loss: 0.2297 23/157, train_loss: 0.2410 24/157, train_loss: 0.2254 25/157, train_loss: 0.2276 26/157, train_loss: 0.2344 27/157, train_loss: 0.1969 28/157, train_loss: 0.2110 29/157, train_loss: 0.2114 30/157, train_loss: 0.2424 31/157, train_loss: 0.2111 32/157, train_loss: 0.1963 33/157, train_loss: 0.1799 34/157, train_loss: 0.1925 35/157, train_loss: 0.2277 36/157, train_loss: 0.2327 37/157, train_loss: 0.1968 38/157, train_loss: 0.2165 39/157, train_loss: 0.1924 40/157, train_loss: 0.1959 41/157, train_loss: 0.1764 42/157, train_loss: 0.2327 43/157, train_loss: 0.1955 44/157, train_loss: 0.1669 45/157, train_loss: 0.1829 46/157, train_loss: 0.1894 47/157, train_loss: 0.2079 48/157, train_loss: 0.1984 49/157, train_loss: 0.2035 50/157, train_loss: 0.1879 51/157, train_loss: 0.1839 52/157, train_loss: 0.1885 53/157, train_loss: 0.1887 54/157, train_loss: 0.1733 55/157, train_loss: 0.1828 56/157, train_loss: 0.1593 57/157, train_loss: 0.1906 58/157, train_loss: 0.1494 59/157, train_loss: 0.1740 60/157, train_loss: 0.1791 61/157, train_loss: 0.1763 62/157, train_loss: 0.1659 63/157, train_loss: 0.1961 64/157, train_loss: 0.1593 65/157, train_loss: 0.1468 66/157, train_loss: 0.1576 67/157, train_loss: 0.1567 68/157, train_loss: 0.1751 69/157, train_loss: 0.1640 70/157, train_loss: 0.1702 71/157, train_loss: 0.1406 72/157, train_loss: 0.1519 73/157, train_loss: 0.1552 74/157, train_loss: 0.1581 75/157, train_loss: 0.1564 76/157, train_loss: 0.1741 77/157, train_loss: 0.1474 78/157, train_loss: 0.1473 79/157, train_loss: 0.1402 80/157, train_loss: 0.1402 81/157, train_loss: 0.1471 82/157, train_loss: 0.1556 83/157, train_loss: 0.1329 84/157, train_loss: 0.1578 85/157, train_loss: 0.1364 86/157, train_loss: 0.1413 87/157, train_loss: 0.1170 88/157, train_loss: 0.1332 89/157, train_loss: 0.1369 90/157, train_loss: 0.1500 91/157, train_loss: 0.1320 92/157, train_loss: 0.1265 93/157, train_loss: 0.1444 94/157, train_loss: 0.1278 95/157, train_loss: 0.1348 96/157, train_loss: 0.1403 97/157, train_loss: 0.1246 98/157, train_loss: 0.1125 99/157, train_loss: 0.1509 100/157, train_loss: 0.1270 101/157, train_loss: 0.1286 102/157, train_loss: 0.1160 103/157, train_loss: 0.1239 104/157, train_loss: 0.1052 105/157, train_loss: 0.1238 106/157, train_loss: 0.1110 107/157, train_loss: 0.1429 108/157, train_loss: 0.1097 109/157, train_loss: 0.1099 110/157, train_loss: 0.1403 111/157, train_loss: 0.1460 112/157, train_loss: 0.1216 113/157, train_loss: 0.1079 114/157, train_loss: 0.1187 115/157, train_loss: 0.1519 116/157, train_loss: 0.1128 117/157, train_loss: 0.1174 118/157, train_loss: 0.1094 119/157, train_loss: 0.1106 120/157, train_loss: 0.1179 121/157, train_loss: 0.1278 122/157, train_loss: 0.1331 123/157, train_loss: 0.1484 124/157, train_loss: 0.1140 125/157, train_loss: 0.1302 126/157, train_loss: 0.1201 127/157, train_loss: 0.1038 128/157, train_loss: 0.1108 129/157, train_loss: 0.1446 130/157, train_loss: 0.0905 131/157, train_loss: 0.1323 132/157, train_loss: 0.0995 133/157, train_loss: 0.0998 134/157, train_loss: 0.0937 135/157, train_loss: 0.1240 136/157, train_loss: 0.0871 137/157, train_loss: 0.1131 138/157, train_loss: 0.1349 139/157, train_loss: 0.1316 140/157, train_loss: 0.0989 141/157, train_loss: 0.1081 142/157, train_loss: 0.1240 143/157, train_loss: 0.1104 144/157, train_loss: 0.0980 145/157, train_loss: 0.1081 146/157, train_loss: 0.0906 147/157, train_loss: 0.1624 148/157, train_loss: 0.1025 149/157, train_loss: 0.1071 150/157, train_loss: 0.0988 151/157, train_loss: 0.1151 152/157, train_loss: 0.1425 153/157, train_loss: 0.1092 154/157, train_loss: 0.0831 155/157, train_loss: 0.1252 156/157, train_loss: 0.0960 157/157, train_loss: 0.1076 158/157, train_loss: 0.0725 epoch 2 average loss: 0.1612 saved new best metric model current epoch: 2 current AUC: 0.9997 current accuracy: 0.9863 best AUC: 0.9997 at epoch: 2 ---------- epoch 3/4 1/157, train_loss: 0.1095 2/157, train_loss: 0.0810 3/157, train_loss: 0.1085 4/157, train_loss: 0.1033 5/157, train_loss: 0.1527 6/157, train_loss: 0.0988 7/157, train_loss: 0.0935 8/157, train_loss: 0.0903 9/157, train_loss: 0.0941 10/157, train_loss: 0.0742 11/157, train_loss: 0.1127 12/157, train_loss: 0.0803 13/157, train_loss: 0.0937 14/157, train_loss: 0.0810 15/157, train_loss: 0.0965 16/157, train_loss: 0.0705 17/157, train_loss: 0.0802 18/157, train_loss: 0.1040 19/157, train_loss: 0.0940 20/157, train_loss: 0.0758 21/157, train_loss: 0.1002 22/157, train_loss: 0.0720 23/157, train_loss: 0.0773 24/157, train_loss: 0.0906 25/157, train_loss: 0.1002 26/157, train_loss: 0.0948 27/157, train_loss: 0.0731 28/157, train_loss: 0.0938 29/157, train_loss: 0.0731 30/157, train_loss: 0.1004 31/157, train_loss: 0.0829 32/157, train_loss: 0.0864 33/157, train_loss: 0.0729 34/157, train_loss: 0.0773 35/157, train_loss: 0.0719 36/157, train_loss: 0.0875 37/157, train_loss: 0.0897 38/157, train_loss: 0.0740 39/157, train_loss: 0.1091 40/157, train_loss: 0.0652 41/157, train_loss: 0.0899 42/157, train_loss: 0.0853 43/157, train_loss: 0.0727 44/157, train_loss: 0.0843 45/157, train_loss: 0.0878 46/157, train_loss: 0.1135 47/157, train_loss: 0.1041 48/157, train_loss: 0.0935 49/157, train_loss: 0.0879 50/157, train_loss: 0.0922 51/157, train_loss: 0.0862 52/157, train_loss: 0.0692 53/157, train_loss: 0.0784 54/157, train_loss: 0.0986 55/157, train_loss: 0.0707 56/157, train_loss: 0.1013 57/157, train_loss: 0.0598 58/157, train_loss: 0.0639 59/157, train_loss: 0.0587 60/157, train_loss: 0.1027 61/157, train_loss: 0.0711 62/157, train_loss: 0.0775 63/157, train_loss: 0.1045 64/157, train_loss: 0.0655 65/157, train_loss: 0.0621 66/157, train_loss: 0.0636 67/157, train_loss: 0.0774 68/157, train_loss: 0.0875 69/157, train_loss: 0.0664 70/157, train_loss: 0.0707 71/157, train_loss: 0.0814 72/157, train_loss: 0.1022 73/157, train_loss: 0.0820 74/157, train_loss: 0.0829 75/157, train_loss: 0.0809 76/157, train_loss: 0.0975 77/157, train_loss: 0.0684 78/157, train_loss: 0.0686 79/157, train_loss: 0.0831 80/157, train_loss: 0.0671 81/157, train_loss: 0.0647 82/157, train_loss: 0.0574 83/157, train_loss: 0.0611 84/157, train_loss: 0.0886 85/157, train_loss: 0.0674 86/157, train_loss: 0.0609 87/157, train_loss: 0.0582 88/157, train_loss: 0.0584 89/157, train_loss: 0.0751 90/157, train_loss: 0.0720 91/157, train_loss: 0.0727 92/157, train_loss: 0.0664 93/157, train_loss: 0.0681 94/157, train_loss: 0.0791 95/157, train_loss: 0.0880 96/157, train_loss: 0.0746 97/157, train_loss: 0.0730 98/157, train_loss: 0.0818 99/157, train_loss: 0.0617 100/157, train_loss: 0.0646 101/157, train_loss: 0.0607 102/157, train_loss: 0.0749 103/157, train_loss: 0.0656 104/157, train_loss: 0.0607 105/157, train_loss: 0.0713 106/157, train_loss: 0.0725 107/157, train_loss: 0.0711 108/157, train_loss: 0.0642 109/157, train_loss: 0.0624 110/157, train_loss: 0.0685 111/157, train_loss: 0.0542 112/157, train_loss: 0.0771 113/157, train_loss: 0.0786 114/157, train_loss: 0.0580 115/157, train_loss: 0.0698 116/157, train_loss: 0.0847 117/157, train_loss: 0.0542 118/157, train_loss: 0.0760 119/157, train_loss: 0.0817 120/157, train_loss: 0.0904 121/157, train_loss: 0.0705 122/157, train_loss: 0.0541 123/157, train_loss: 0.0521 124/157, train_loss: 0.0555 125/157, train_loss: 0.0491 126/157, train_loss: 0.0504 127/157, train_loss: 0.0598 128/157, train_loss: 0.0417 129/157, train_loss: 0.0470 130/157, train_loss: 0.0584 131/157, train_loss: 0.0498 132/157, train_loss: 0.0532 133/157, train_loss: 0.0515 134/157, train_loss: 0.0575 135/157, train_loss: 0.0506 136/157, train_loss: 0.0519 137/157, train_loss: 0.0727 138/157, train_loss: 0.0796 139/157, train_loss: 0.0469 140/157, train_loss: 0.0509 141/157, train_loss: 0.0501 142/157, train_loss: 0.0603 143/157, train_loss: 0.0499 144/157, train_loss: 0.0585 145/157, train_loss: 0.0590 146/157, train_loss: 0.0447 147/157, train_loss: 0.0699 148/157, train_loss: 0.0595 149/157, train_loss: 0.0372 150/157, train_loss: 0.0446 151/157, train_loss: 0.0576 152/157, train_loss: 0.0735 153/157, train_loss: 0.0464 154/157, train_loss: 0.0742 155/157, train_loss: 0.0356 156/157, train_loss: 0.0492 157/157, train_loss: 0.0644 158/157, train_loss: 0.0630 epoch 3 average loss: 0.0743 saved new best metric model current epoch: 3 current AUC: 0.9999 current accuracy: 0.9924 best AUC: 0.9999 at epoch: 3 ---------- epoch 4/4 1/157, train_loss: 0.0563 2/157, train_loss: 0.0645 3/157, train_loss: 0.0497 4/157, train_loss: 0.0579 5/157, train_loss: 0.0442 6/157, train_loss: 0.0588 7/157, train_loss: 0.0501 8/157, train_loss: 0.0402 9/157, train_loss: 0.0432 10/157, train_loss: 0.0465 11/157, train_loss: 0.0546 12/157, train_loss: 0.0548 13/157, train_loss: 0.0430 14/157, train_loss: 0.0448 15/157, train_loss: 0.0533 16/157, train_loss: 0.0521 17/157, train_loss: 0.0406 18/157, train_loss: 0.0426 19/157, train_loss: 0.0471 20/157, train_loss: 0.0570 21/157, train_loss: 0.0611 22/157, train_loss: 0.0500 23/157, train_loss: 0.0532 24/157, train_loss: 0.0549 25/157, train_loss: 0.0488 26/157, train_loss: 0.0574 27/157, train_loss: 0.0587 28/157, train_loss: 0.0488 29/157, train_loss: 0.0509 30/157, train_loss: 0.0299 31/157, train_loss: 0.0404 32/157, train_loss: 0.0345 33/157, train_loss: 0.0569 34/157, train_loss: 0.0361 35/157, train_loss: 0.0623 36/157, train_loss: 0.0686 37/157, train_loss: 0.0376 38/157, train_loss: 0.0528 39/157, train_loss: 0.0367 40/157, train_loss: 0.0466 41/157, train_loss: 0.0551 42/157, train_loss: 0.0374 43/157, train_loss: 0.0681 44/157, train_loss: 0.0386 45/157, train_loss: 0.0636 46/157, train_loss: 0.0555 47/157, train_loss: 0.0449 48/157, train_loss: 0.0481 49/157, train_loss: 0.0382 50/157, train_loss: 0.0682 51/157, train_loss: 0.0511 52/157, train_loss: 0.0606 53/157, train_loss: 0.0490 54/157, train_loss: 0.0497 55/157, train_loss: 0.0476 56/157, train_loss: 0.0457 57/157, train_loss: 0.0545 58/157, train_loss: 0.0426 59/157, train_loss: 0.0445 60/157, train_loss: 0.0528 61/157, train_loss: 0.0597 62/157, train_loss: 0.0376 63/157, train_loss: 0.0555 64/157, train_loss: 0.0571 65/157, train_loss: 0.0475 66/157, train_loss: 0.0577 67/157, train_loss: 0.0393 68/157, train_loss: 0.0397 69/157, train_loss: 0.0536 70/157, train_loss: 0.0516 71/157, train_loss: 0.0595 72/157, train_loss: 0.0473 73/157, train_loss: 0.0624 74/157, train_loss: 0.0426 75/157, train_loss: 0.0474 76/157, train_loss: 0.0474 77/157, train_loss: 0.0516 78/157, train_loss: 0.0332 79/157, train_loss: 0.0403 80/157, train_loss: 0.0401 81/157, train_loss: 0.0397 82/157, train_loss: 0.0526 83/157, train_loss: 0.0429 84/157, train_loss: 0.0306 85/157, train_loss: 0.0433 86/157, train_loss: 0.0376 87/157, train_loss: 0.0430 88/157, train_loss: 0.0433 89/157, train_loss: 0.0575 90/157, train_loss: 0.0349 91/157, train_loss: 0.0273 92/157, train_loss: 0.0395 93/157, train_loss: 0.0474 94/157, train_loss: 0.0464 95/157, train_loss: 0.0310 96/157, train_loss: 0.0597 97/157, train_loss: 0.0403 98/157, train_loss: 0.0684 99/157, train_loss: 0.0371 100/157, train_loss: 0.0570 101/157, train_loss: 0.0468 102/157, train_loss: 0.0317 103/157, train_loss: 0.0322 104/157, train_loss: 0.0472 105/157, train_loss: 0.0351 106/157, train_loss: 0.0430 107/157, train_loss: 0.0319 108/157, train_loss: 0.0459 109/157, train_loss: 0.0448 110/157, train_loss: 0.0486 111/157, train_loss: 0.0538 112/157, train_loss: 0.0290 113/157, train_loss: 0.0567 114/157, train_loss: 0.0455 115/157, train_loss: 0.0502 116/157, train_loss: 0.0338 117/157, train_loss: 0.0541 118/157, train_loss: 0.0496 119/157, train_loss: 0.0461 120/157, train_loss: 0.0353 121/157, train_loss: 0.0569 122/157, train_loss: 0.0282 123/157, train_loss: 0.0299 124/157, train_loss: 0.0366 125/157, train_loss: 0.0397 126/157, train_loss: 0.0339 127/157, train_loss: 0.0417 128/157, train_loss: 0.0515 129/157, train_loss: 0.0433 130/157, train_loss: 0.0435 131/157, train_loss: 0.0310 132/157, train_loss: 0.0497 133/157, train_loss: 0.0366 134/157, train_loss: 0.0436 135/157, train_loss: 0.0387 136/157, train_loss: 0.0291 137/157, train_loss: 0.0480 138/157, train_loss: 0.0377 139/157, train_loss: 0.0346 140/157, train_loss: 0.0265 141/157, train_loss: 0.0497 142/157, train_loss: 0.0352 143/157, train_loss: 0.0264 144/157, train_loss: 0.0349 145/157, train_loss: 0.0409 146/157, train_loss: 0.0488 147/157, train_loss: 0.0541 148/157, train_loss: 0.0506 149/157, train_loss: 0.0451 150/157, train_loss: 0.0280 151/157, train_loss: 0.0349 152/157, train_loss: 0.0344 153/157, train_loss: 0.0307 154/157, train_loss: 0.0550 155/157, train_loss: 0.0521 156/157, train_loss: 0.0478 157/157, train_loss: 0.0295 158/157, train_loss: 0.1089 epoch 4 average loss: 0.0462 saved new best metric model current epoch: 4 current AUC: 1.0000 current accuracy: 0.9944 best AUC: 1.0000 at epoch: 4 train completed, best_metric: 1.0000 at epoch: 4
損失とメトリックをプロットする
plt.figure("train", (12, 6)) plt.subplot(1, 2, 1) plt.title("Epoch Average Loss") x = [i + 1 for i in range(len(epoch_loss_values))] y = epoch_loss_values plt.xlabel("epoch") plt.plot(x, y) plt.subplot(1, 2, 2) plt.title("Val AUC") x = [val_interval * (i + 1) for i in range(len(metric_values))] y = metric_values plt.xlabel("epoch") plt.plot(x, y) plt.show()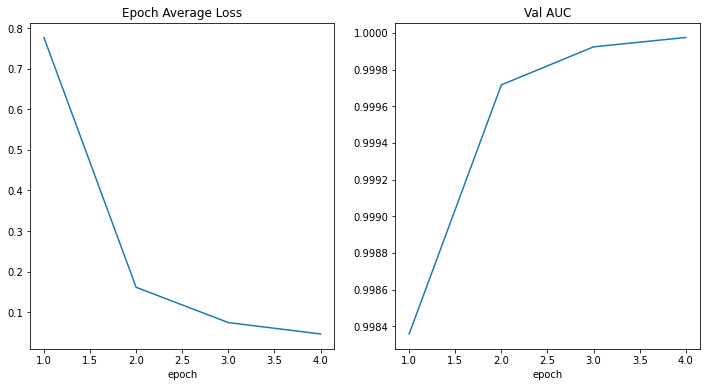
テストデータセット上でモデルを評価する
訓練と検証の後、検証テスト上のベストモデルを既に得ています。モデルをテストデータセット上でそれが堅牢で over fitting していないかを確認するために評価する必要があります。分類レポートを生成するためにこれらの予測を使用します。
model.load_state_dict(torch.load( os.path.join(root_dir, "best_metric_model.pth"))) model.eval() y_true = [] y_pred = [] with torch.no_grad(): for test_data in test_loader: test_images, test_labels = ( test_data[0].to(device), test_data[1].to(device), ) pred = model(test_images).argmax(dim=1) for i in range(len(pred)): y_true.append(test_labels[i].item()) y_pred.append(pred[i].item())print(classification_report( y_true, y_pred, target_names=class_names, digits=4))Note: you may need to restart the kernel to use updated packages. precision recall f1-score support AbdomenCT 0.9816 0.9917 0.9867 969 BreastMRI 0.9968 0.9831 0.9899 944 CXR 0.9979 0.9928 0.9954 973 ChestCT 0.9938 0.9990 0.9964 959 Hand 0.9934 0.9934 0.9934 1055 HeadCT 0.9960 0.9990 0.9975 985 accuracy 0.9932 5885 macro avg 0.9932 0.9932 0.9932 5885 weighted avg 0.9932 0.9932 0.9932 5885データディレクトリのクリーンアップ
一時ディレクトリが使用された場合ディレクトリを削除します。
if directory is None: shutil.rmtree(root_dir)以上