MONAI 1.0 : tutorials : 3D セグメンテーション – 脾臓 3D セグメンテーション (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 01/19/2023 (1.1.0)
* 本ページは、MONAI の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。

- 人工知能研究開発支援
- 人工知能研修サービス(経営者層向けオンサイト研修)
- テクニカルコンサルティングサービス
- 実証実験(プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
- PoC(概念実証)を失敗させないための支援
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
- 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション
- sales-info@classcat.com ; Web: www.classcat.com ; ClassCatJP

MONAI 0.7 : tutorials : 3D セグメンテーション – 脾臓 3D セグメンテーション
このノートブックは MSD 脾臓データセット に基づいた 3D セグメンテーションの end-to-end な訓練と評価サンプルです。このサンプルは PyTorch ベースのプログラムで MONAI モジュールの柔軟性を示します :
- 辞書ベースの訓練データ構造のための変換。
- メタデータを含む NIfTI 画像をロードする。
- 想定する範囲で医用画像強度をスケールする。
- ポジティブ/ネガティブ・ラベル比率に基づいてバランスの取れた画像パッチサンプルのバッチをクロップする。
- 訓練と検証を高速化するキャッシュ IO と変換。
- 3D セグメンテーション・タスクのための 3D UNet, Dice 損失関数, Mean Dice メトリック。
- スライディング・ウィンドウ推論。
- 再現性のための決定論的訓練。
このチュートリアルは MONAI を既存の PyTorch 医用 DL プログラムに統合する方法を示します。
そして以下の機能を簡単に使用することができます :
- 辞書形式データのための変換。
- メタデータを含む Nifti 画像をロードする。
- チャネル次元がない場合チャネル dim をデータに追加する。
- 想定される範囲で医用画像強度をスケールする。
- ポジティブ/ネガティブ・ラベル比率に基づいてバランスの取れた画像のバッチをクロップする。
- 訓練と検証を高速化するキャシュ IO と変換。
- 3D セグメンテーション・タスクのための 3D UNet モデル、Dice 損失関数、Mean Dice メトリック。
- スライディング・ウィンドウ推論手法。
- 再現性のための決定論的訓練。
Spleen データセットは http://medicaldecathlon.com/ からダウンロードできます。

- Target: Spleen
- Modality: CT
- Size: 61 3D volumes (41 Training + 20 Testing)
- Source: Memorial Sloan Kettering Cancer Center
- Challenge: Large ranging foreground size
環境のセットアップ
!python -c "import monai" || pip install -q "monai-weekly[gdown, nibabel, tqdm, ignite]"
!python -c "import matplotlib" || pip install -q matplotlib
%matplotlib inline
インポートのセットアップ
from monai.utils import first, set_determinism
from monai.transforms import (
AsDiscrete,
AsDiscreted,
EnsureChannelFirstd,
Compose,
CropForegroundd,
LoadImaged,
Orientationd,
RandCropByPosNegLabeld,
SaveImaged,
ScaleIntensityRanged,
Spacingd,
Invertd,
)
from monai.handlers.utils import from_engine
from monai.networks.nets import UNet
from monai.networks.layers import Norm
from monai.metrics import DiceMetric
from monai.losses import DiceLoss
from monai.inferers import sliding_window_inference
from monai.data import CacheDataset, DataLoader, Dataset, decollate_batch
from monai.config import print_config
from monai.apps import download_and_extract
import torch
import matplotlib.pyplot as plt
import tempfile
import shutil
import os
import glob
print_config()
MONAI version: 1.1.0+2.g97918e46
Numpy version: 1.22.2
Pytorch version: 1.13.0a0+d0d6b1f
MONAI flags: HAS_EXT = True, USE_COMPILED = False, USE_META_DICT = False
MONAI rev id: 97918e46e0d2700c050e678d72e3edb35afbd737
MONAI __file__: /opt/monai/monai/__init__.py
Optional dependencies:
Pytorch Ignite version: 0.4.10
Nibabel version: 4.0.2
scikit-image version: 0.19.3
Pillow version: 9.0.1
Tensorboard version: 2.10.1
gdown version: 4.6.0
TorchVision version: 0.14.0a0
tqdm version: 4.64.1
lmdb version: 1.3.0
psutil version: 5.9.2
pandas version: 1.4.4
einops version: 0.6.0
transformers version: 4.21.3
mlflow version: 2.0.1
pynrrd version: 1.0.0
For details about installing the optional dependencies, please visit:
https://docs.monai.io/en/latest/installation.html#installing-the-recommended-dependencies
データディレクトリのセットアップ
MONAI_DATA_DIRECTORY 環境変数でディレクトリを指定できます。
これは結果をセーブしてダウンロードを再利用することを可能にします。
指定されない場合、一時ディレクトリが使用されます。
directory = os.environ.get("MONAI_DATA_DIRECTORY")
root_dir = tempfile.mkdtemp() if directory is None else directory
print(root_dir)
/workspace/data/medical/
データセットのダウンロード
データセットをダウンロードして展開します。データセットは http://medicaldecathlon.com/ に由来します。
resource = "https://msd-for-monai.s3-us-west-2.amazonaws.com/Task09_Spleen.tar"
md5 = "410d4a301da4e5b2f6f86ec3ddba524e"
compressed_file = os.path.join(root_dir, "Task09_Spleen.tar")
data_dir = os.path.join(root_dir, "Task09_Spleen")
if not os.path.exists(data_dir):
download_and_extract(resource, compressed_file, root_dir, md5)
MSD 脾臓データセット・パスの設定
train_images = sorted(
glob.glob(os.path.join(data_dir, "imagesTr", "*.nii.gz")))
train_labels = sorted(
glob.glob(os.path.join(data_dir, "labelsTr", "*.nii.gz")))
data_dicts = [
{"image": image_name, "label": label_name}
for image_name, label_name in zip(train_images, train_labels)
]
train_files, val_files = data_dicts[:-9], data_dicts[-9:]
再現性のための決定論的訓練の設定
set_determinism(seed=0)
訓練と検証のための変換のセットアップ
ここではデータセットを増強するために幾つかの変換を使用します :
- LoadImaged は NIfTI 形式ファイルから脾臓 CT 画像とラベルをロードします。
- EnsureChannelFirstd は元のデータが「チャネル first」shape を構成することを保証します。
- Orientationd はアフィン行列に基づいてデータの向きを統一します。
- Spacingd はアフィン行列に基づいて pixdim=(1.5, 1.5, 2.) による spacing を調整します。
- ScaleIntensityRanged は強度範囲 [-57, 164] を抽出して [0, 1] にスケールします。
- CropForegroundd は画像とラベルの valid body 領域にフォーカスするために総てのゼロ境界 (= border) を削除します。
- RandCropByPosNegLabeld は pos / neg 比率に基づいて大きな画像からランダムにパッチサンプルをクロップします。
ネガティブサンプルの画像中心は valid body 領域になければなりません。
- RandAffined は PyTorch アフィン変換に基づいて回転, スケール, shear, 並行移動等を一緒に効率的に実行します。
train_transforms = Compose(
[
LoadImaged(keys=["image", "label"]),
EnsureChannelFirstd(keys=["image", "label"]),
ScaleIntensityRanged(
keys=["image"], a_min=-57, a_max=164,
b_min=0.0, b_max=1.0, clip=True,
),
CropForegroundd(keys=["image", "label"], source_key="image"),
Orientationd(keys=["image", "label"], axcodes="RAS"),
Spacingd(keys=["image", "label"], pixdim=(
1.5, 1.5, 2.0), mode=("bilinear", "nearest")),
RandCropByPosNegLabeld(
keys=["image", "label"],
label_key="label",
spatial_size=(96, 96, 96),
pos=1,
neg=1,
num_samples=4,
image_key="image",
image_threshold=0,
),
# user can also add other random transforms
# RandAffined(
# keys=['image', 'label'],
# mode=('bilinear', 'nearest'),
# prob=1.0, spatial_size=(96, 96, 96),
# rotate_range=(0, 0, np.pi/15),
# scale_range=(0.1, 0.1, 0.1)),
]
)
val_transforms = Compose(
[
LoadImaged(keys=["image", "label"]),
EnsureChannelFirstd(keys=["image", "label"]),
ScaleIntensityRanged(
keys=["image"], a_min=-57, a_max=164,
b_min=0.0, b_max=1.0, clip=True,
),
CropForegroundd(keys=["image", "label"], source_key="image"),
Orientationd(keys=["image", "label"], axcodes="RAS"),
Spacingd(keys=["image", "label"], pixdim=(
1.5, 1.5, 2.0), mode=("bilinear", "nearest")),
]
)
DataLoaer で変換を確認する
check_ds = Dataset(data=val_files, transform=val_transforms)
check_loader = DataLoader(check_ds, batch_size=1)
check_data = first(check_loader)
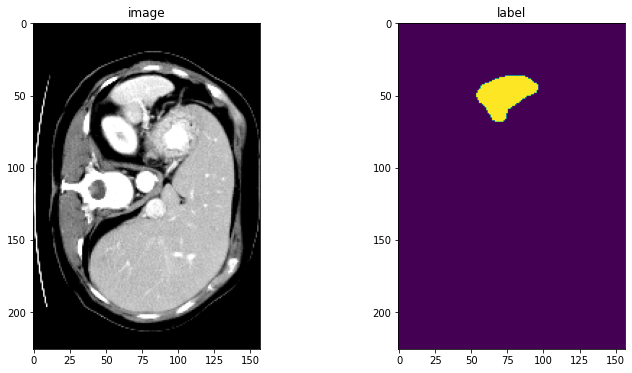
image, label = (check_data["image"][0][0], check_data["label"][0][0])
print(f"image shape: {image.shape}, label shape: {label.shape}")
# plot the slice [:, :, 80]
plt.figure("check", (12, 6))
plt.subplot(1, 2, 1)
plt.title("image")
plt.imshow(image[:, :, 80], cmap="gray")
plt.subplot(1, 2, 2)
plt.title("label")
plt.imshow(label[:, :, 80])
plt.show()
image shape: torch.Size([226, 157, 113]), label shape: torch.Size([226, 157, 113])
訓練と検証のために CacheDataset と DataLoader を定義する
ここで訓練と検証プロセスを高速化するために CacheDataset を使用し、それは通常の Dataset よりも 10x 高速です。ベストなパフォーマンスを得るためには、総てのデータをキャッシュするために cache_rate=1.0 を設定します、メモリが十分でない場合には、低い値を設定してください。ユーザはまた cache_rate の代わりに cache_num を設定することもできて、2 つの設定の最小値を使用します。そしてキャッシュする間にマルチスレッドを有効にするために num_workers を設定します。通常の Dataset を試したい場合は、下でコメントされたコードを単に使用するように変更してください。
train_ds = CacheDataset(
data=train_files, transform=train_transforms,
cache_rate=1.0, num_workers=4)
# train_ds = Dataset(data=train_files, transform=train_transforms)
# use batch_size=2 to load images and use RandCropByPosNegLabeld
# to generate 2 x 4 images for network training
train_loader = DataLoader(train_ds, batch_size=2, shuffle=True, num_workers=4)
val_ds = CacheDataset(
data=val_files, transform=val_transforms, cache_rate=1.0, num_workers=4)
# val_ds = Dataset(data=val_files, transform=val_transforms)
val_loader = DataLoader(val_ds, batch_size=1, num_workers=4)
Loading dataset: 100%|██████████| 32/32 [00:32<00:00, 1.02s/it] Loading dataset: 100%|██████████| 9/9 [00:07<00:00, 1.18it/s]
モデル、損失、Optimizer を作成する
# standard PyTorch program style: create UNet, DiceLoss and Adam optimizer
device = torch.device("cuda:0")
model = UNet(
spatial_dims=3,
in_channels=1,
out_channels=2,
channels=(16, 32, 64, 128, 256),
strides=(2, 2, 2, 2),
num_res_units=2,
norm=Norm.BATCH,
).to(device)
loss_function = DiceLoss(to_onehot_y=True, softmax=True)
optimizer = torch.optim.Adam(model.parameters(), 1e-4)
dice_metric = DiceMetric(include_background=False, reduction="mean")
典型的な PyTorch 訓練プロセスを実行する
max_epochs = 600
val_interval = 2
best_metric = -1
best_metric_epoch = -1
epoch_loss_values = []
metric_values = []
post_pred = Compose([AsDiscrete(argmax=True, to_onehot=2)])
post_label = Compose([AsDiscrete(to_onehot=2)])
for epoch in range(max_epochs):
print("-" * 10)
print(f"epoch {epoch + 1}/{max_epochs}")
model.train()
epoch_loss = 0
step = 0
for batch_data in train_loader:
step += 1
inputs, labels = (
batch_data["image"].to(device),
batch_data["label"].to(device),
)
optimizer.zero_grad()
outputs = model(inputs)
loss = loss_function(outputs, labels)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
print(
f"{step}/{len(train_ds) // train_loader.batch_size}, "
f"train_loss: {loss.item():.4f}")
epoch_loss /= step
epoch_loss_values.append(epoch_loss)
print(f"epoch {epoch + 1} average loss: {epoch_loss:.4f}")
if (epoch + 1) % val_interval == 0:
model.eval()
with torch.no_grad():
for val_data in val_loader:
val_inputs, val_labels = (
val_data["image"].to(device),
val_data["label"].to(device),
)
roi_size = (160, 160, 160)
sw_batch_size = 4
val_outputs = sliding_window_inference(
val_inputs, roi_size, sw_batch_size, model)
val_outputs = [post_pred(i) for i in decollate_batch(val_outputs)]
val_labels = [post_label(i) for i in decollate_batch(val_labels)]
# compute metric for current iteration
dice_metric(y_pred=val_outputs, y=val_labels)
# aggregate the final mean dice result
metric = dice_metric.aggregate().item()
# reset the status for next validation round
dice_metric.reset()
metric_values.append(metric)
if metric > best_metric:
best_metric = metric
best_metric_epoch = epoch + 1
torch.save(model.state_dict(), os.path.join(
root_dir, "best_metric_model.pth"))
print("saved new best metric model")
print(
f"current epoch: {epoch + 1} current mean dice: {metric:.4f}"
f"\nbest mean dice: {best_metric:.4f} "
f"at epoch: {best_metric_epoch}"
)
print(
f"train completed, best_metric: {best_metric:.4f} "
f"at epoch: {best_metric_epoch}")
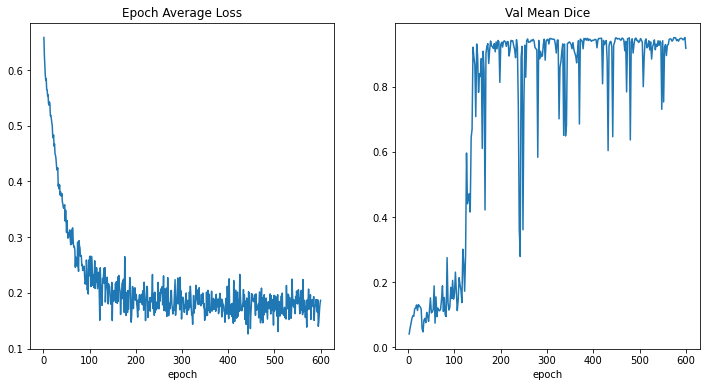
train completed, best_metric: 0.9510 at epoch: 598
損失とメトリックをプロットする
plt.figure("train", (12, 6))
plt.subplot(1, 2, 1)
plt.title("Epoch Average Loss")
x = [i + 1 for i in range(len(epoch_loss_values))]
y = epoch_loss_values
plt.xlabel("epoch")
plt.plot(x, y)
plt.subplot(1, 2, 2)
plt.title("Val Mean Dice")
x = [val_interval * (i + 1) for i in range(len(metric_values))]
y = metric_values
plt.xlabel("epoch")
plt.plot(x, y)
plt.show()
入力画像とラベルでベストなモデル出力を確認する
model.load_state_dict(torch.load(
os.path.join(root_dir, "best_metric_model.pth")))
model.eval()
with torch.no_grad():
for i, val_data in enumerate(val_loader):
roi_size = (160, 160, 160)
sw_batch_size = 4
val_outputs = sliding_window_inference(
val_data["image"].to(device), roi_size, sw_batch_size, model
)
# plot the slice [:, :, 80]
plt.figure("check", (18, 6))
plt.subplot(1, 3, 1)
plt.title(f"image {i}")
plt.imshow(val_data["image"][0, 0, :, :, 80], cmap="gray")
plt.subplot(1, 3, 2)
plt.title(f"label {i}")
plt.imshow(val_data["label"][0, 0, :, :, 80])
plt.subplot(1, 3, 3)
plt.title(f"output {i}")
plt.imshow(torch.argmax(
val_outputs, dim=1).detach().cpu()[0, :, :, 80])
plt.show()
if i == 2:
break


元の画像 spacing 上の評価
val_org_transforms = Compose(
[
LoadImaged(keys=["image", "label"]),
EnsureChannelFirstd(keys=["image", "label"]),
Orientationd(keys=["image"], axcodes="RAS"),
Spacingd(keys=["image"], pixdim=(
1.5, 1.5, 2.0), mode="bilinear"),
ScaleIntensityRanged(
keys=["image"], a_min=-57, a_max=164,
b_min=0.0, b_max=1.0, clip=True,
),
CropForegroundd(keys=["image"], source_key="image"),
]
)
val_org_ds = Dataset(
data=val_files, transform=val_org_transforms)
val_org_loader = DataLoader(val_org_ds, batch_size=1, num_workers=4)
post_transforms = Compose([
Invertd(
keys="pred",
transform=val_org_transforms,
orig_keys="image",
meta_keys="pred_meta_dict",
orig_meta_keys="image_meta_dict",
meta_key_postfix="meta_dict",
nearest_interp=False,
to_tensor=True,
device="cpu",
),
AsDiscreted(keys="pred", argmax=True, to_onehot=2),
AsDiscreted(keys="label", to_onehot=2),
])
model.load_state_dict(torch.load(
os.path.join(root_dir, "best_metric_model.pth")))
model.eval()
with torch.no_grad():
for val_data in val_org_loader:
val_inputs = val_data["image"].to(device)
roi_size = (160, 160, 160)
sw_batch_size = 4
val_data["pred"] = sliding_window_inference(
val_inputs, roi_size, sw_batch_size, model)
val_data = [post_transforms(i) for i in decollate_batch(val_data)]
val_outputs, val_labels = from_engine(["pred", "label"])(val_data)
# compute metric for current iteration
dice_metric(y_pred=val_outputs, y=val_labels)
# aggregate the final mean dice result
metric_org = dice_metric.aggregate().item()
# reset the status for next validation round
dice_metric.reset()
print("Metric on original image spacing: ", metric_org)
Metric on original image spacing: 0.9637420177459717
テストセット上の推論
test_images = sorted(
glob.glob(os.path.join(data_dir, "imagesTs", "*.nii.gz")))
test_data = [{"image": image} for image in test_images]
test_org_transforms = Compose(
[
LoadImaged(keys="image"),
EnsureChannelFirstd(keys="image"),
Orientationd(keys=["image"], axcodes="RAS"),
Spacingd(keys=["image"], pixdim=(
1.5, 1.5, 2.0), mode="bilinear"),
ScaleIntensityRanged(
keys=["image"], a_min=-57, a_max=164,
b_min=0.0, b_max=1.0, clip=True,
),
CropForegroundd(keys=["image"], source_key="image"),
]
)
test_org_ds = Dataset(
data=test_data, transform=test_org_transforms)
test_org_loader = DataLoader(test_org_ds, batch_size=1, num_workers=4)
post_transforms = Compose([
Invertd(
keys="pred",
transform=test_org_transforms,
orig_keys="image",
meta_keys="pred_meta_dict",
orig_meta_keys="image_meta_dict",
meta_key_postfix="meta_dict",
nearest_interp=False,
to_tensor=True,
),
AsDiscreted(keys="pred", argmax=True, to_onehot=2),
SaveImaged(keys="pred", meta_keys="pred_meta_dict", output_dir="./out", output_postfix="seg", resample=False),
])
# # uncomment the following lines to visualize the predicted results
# from monai.transforms import LoadImage
# loader = LoadImage()
model.load_state_dict(torch.load(
os.path.join(root_dir, "best_metric_model.pth")))
model.eval()
with torch.no_grad():
for test_data in test_org_loader:
test_inputs = test_data["image"].to(device)
roi_size = (160, 160, 160)
sw_batch_size = 4
test_data["pred"] = sliding_window_inference(
test_inputs, roi_size, sw_batch_size, model)
test_data = [post_transforms(i) for i in decollate_batch(test_data)]
# # uncomment the following lines to visualize the predicted results
# test_output = from_engine(["pred"])(test_data)
# original_image = loader(test_output[0].meta["filename_or_obj"])
# plt.figure("check", (18, 6))
# plt.subplot(1, 2, 1)
# plt.imshow(original_image[:, :, 20], cmap="gray")
# plt.subplot(1, 2, 2)
# plt.imshow(test_output[0].detach().cpu()[1, :, :, 20])
# plt.show()
データディレクトリのクリーンアップ
一時ディレクトリが使用された場合にはディレクトリを削除します。
if directory is None:
shutil.rmtree(root_dir)
以上