ホーム » 「Prophet 1.1」タグがついた投稿
タグアーカイブ: Prophet 1.1
Prophet 1.1 : 季節性、休日効果とリグレッサー
Prophet 1.1 : 季節性、休日効果とリグレッサー (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 08/31/2023 (1.1.4)
* 本ページは、Prophet の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。

- 人工知能研究開発支援
- 人工知能研修サービス(経営者層向けオンサイト研修)
- テクニカルコンサルティングサービス
- 実証実験(プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
- PoC(概念実証)を失敗させないための支援
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
- 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション
- sales-info@classcat.com ; Web: www.classcat.com ; ClassCatJP
Prophet 1.1 : 季節性、休日効果とリグレッサー
休日と特殊イベントのモデル化
モデル化したい休日や他の繰り返し発生する (循環性の, recurring) イベントを持つ場合、それらに対してデータフレームを作成しなければなりません。それは 2 つのカラム (holiday と ds) と休日の各々の発生のに対して行を持ちます。それは過去 (後方に履歴データがある限り) と未来 (予測が行なわれている限り) の両者の、休日の総ての発生を含まなければなりません、それらが未来に繰り返されない場合、Prophet はそれらをモデル化して予測ではそれらを含めません。
カラムに lower_window と upper_window を含めることもできます、これらは休日を日付周りの [lower_window, upper_window] days に拡張します。例えば、クリスマスに加えてクリスマス・イブを含めることを望んだ場合、lower_window=-1,upper_window=0 を含めます。感謝祭に加えてブラックフライデーを使用したい場合には、lower_window=0,upper_window=1 を含めます。下で説明されるように、各休日のために prior scale を個別に設定するためにカラム prior_scale を含めることもできます。
ここでは Peyton Manning のプレーオフ出場の総ての日付を含むデータフレームを作成します :
playoffs = pd.DataFrame({
'holiday': 'playoff',
'ds': pd.to_datetime(['2008-01-13', '2009-01-03', '2010-01-16',
'2010-01-24', '2010-02-07', '2011-01-08',
'2013-01-12', '2014-01-12', '2014-01-19',
'2014-02-02', '2015-01-11', '2016-01-17',
'2016-01-24', '2016-02-07']),
'lower_window': 0,
'upper_window': 1,
})
superbowls = pd.DataFrame({
'holiday': 'superbowl',
'ds': pd.to_datetime(['2010-02-07', '2014-02-02', '2016-02-07']),
'lower_window': 0,
'upper_window': 1,
})
holidays = pd.concat((playoffs, superbowls))
上記ではスーパーボウル days をプレーオフゲームとスーパーボウルゲームの両方として含めました。これは、スパーボウル効果はプレーオフ効果の上に追加の加算的ボーナスであることを意味します。
ひとたびテーブルが作成されれば、休日効果はそれらを holidays 引数で渡すことにより予測に含まれます。ここでは クイックスタート からの Peyton Manning データでそれを行ないます :
m = Prophet(holidays=holidays)
forecast = m.fit(df).predict(future)
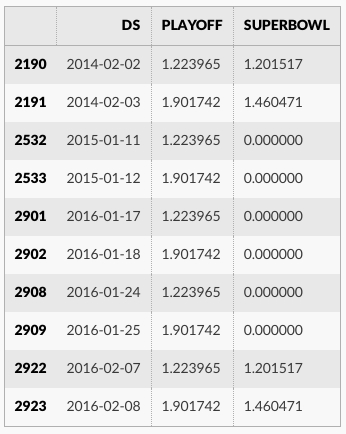
休日効果は予測データフレーム内で見ることができます :
forecast[(forecast['playoff'] + forecast['superbowl']).abs() > 0][
['ds', 'playoff', 'superbowl']][-10:]
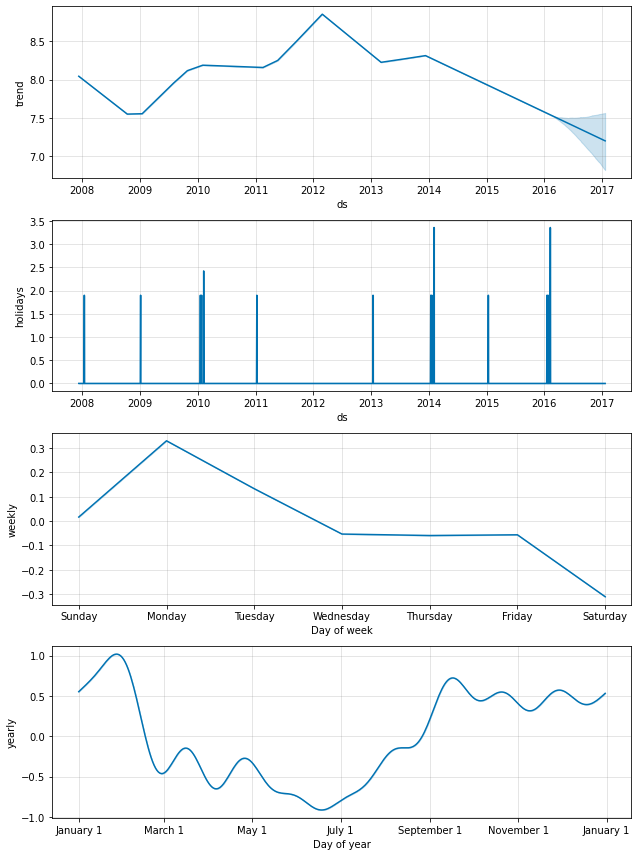
休日効果はまた成分プロット内にも現れます、そこではプレーオフ出場周りの日々でスパイクがあり、スーパーボウルに対しては特に巨大なスパイクがあります :
fig = m.plot_components(forecast)
スーパボウル休日成分だけをプロットする plot_forecast_component(m, forecast, ‘superbowl’) のように、(Python で prophet.plot からインポートされる) plot_forecast_component 関数を使用して個々の休日をプロットできます。
組込みの国の休日
add_country_holidays メソッド (Python) や関数 (R) を使用して国固有の休日の組込みコレクションを使用できます。国の名前が指定されると、上述の holidays 引数を通して指定された任意の休日に加えて、その国のための主要な休日が含まれます :
m = Prophet(holidays=holidays)
m.add_country_holidays(country_name='US')
m.fit(df)
モデルの train_holiday_names (Python) か train.holiday.names (R) 属性を見ることによりどの休日が含まれたかを見ることができます :
m.train_holiday_names
0 playoff 1 superbowl 2 New Year's Day 3 Martin Luther King Jr. Day 4 Washington's Birthday 5 Memorial Day 6 Independence Day 7 Labor Day 8 Columbus Day 9 Veterans Day 10 Thanksgiving 11 Christmas Day 12 Christmas Day (Observed) 13 Veterans Day (Observed) 14 Independence Day (Observed) 15 New Year's Day (Observed) dtype: object
各国のための休日は Python の holidays パッケージにより提供されます。利用可能な国のリストと使用する国名はページ : https://github.com/dr-prodigy/python-holidays で利用可能です。それらの国に加えて、Prophet はこれらの国のための休日を含みます : ブラジル (BR), インドネシア (ID), インド (IN), マレーシア (MY), ベトナム (VN), タイ (TH), フィリッピン (PH), パキスタン (PK), バングラディシュ (BD), エジプト (EG), 中国 (CN), そしてロシア (RU), 韓国 (KR), ベラルーシ (BY), そしてアラブ首長国連邦 (AE) です。
※ 訳注 : 日本 (JP) (08/31/2023 : 以前に使用可能であった JPN は削除されたようです。)
Python では、殆どの休日は決定論的に計算されますので任意の日付範囲で利用可能です ; 日付がその国でサポートされる範囲に入らない場合、警告が上げられます。R では、休日の日付は 1995 年から 2044 年まで計算されて data-raw/generated_holidays.csv としてパッケージにストアされています。より広い日付範囲が必要であれば、このスクリプトがそのファイルを異なる日付範囲と置き換えるために使用できます : https://github.com/facebook/prophet/blob/main/python/scripts/generate_holidays_file.py 。
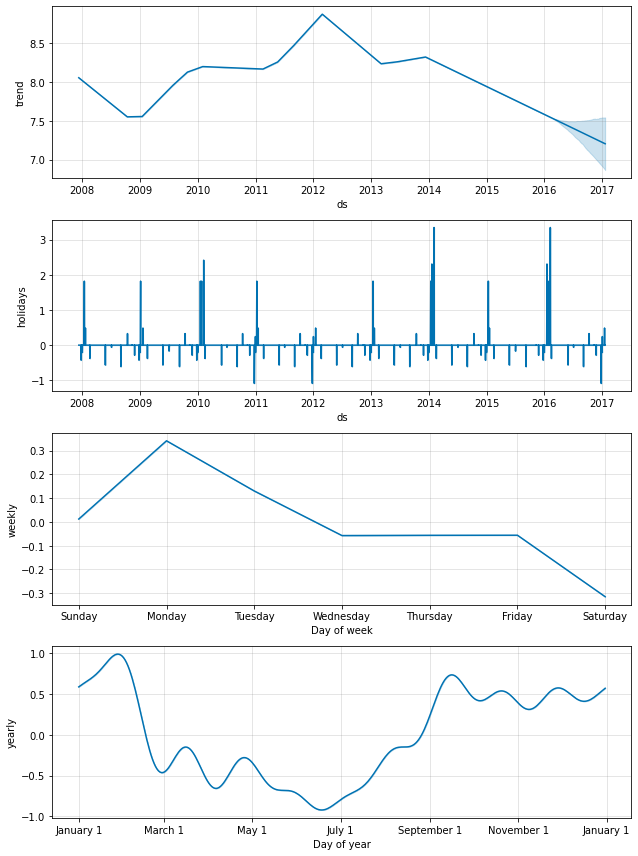
上記のように、国レベルの休日は成分プロットで現れます :
forecast = m.predict(future)
fig = m.plot_components(forecast)
季節性のフーリエ次数
季節性は部分フーリエ和を使用して推定されます。完全な詳細は 論文 を、そして部分フーリエ和がどのように任意の周期信号を近似できるかの例示については Wikipedia のこの図 を見てください。部分和の項の数 (次数) はどのくらい素早く季節性が変化するかを決定するパラメータです。これを説明するために、クイックスタート からの Peyton Manning データを考えます。yearly 季節性のためのデフォルトのフーリエ次数は 10 で、これはこの適合を生成します :
from prophet.plot import plot_yearly
m = Prophet().fit(df)
a = plot_yearly(m)
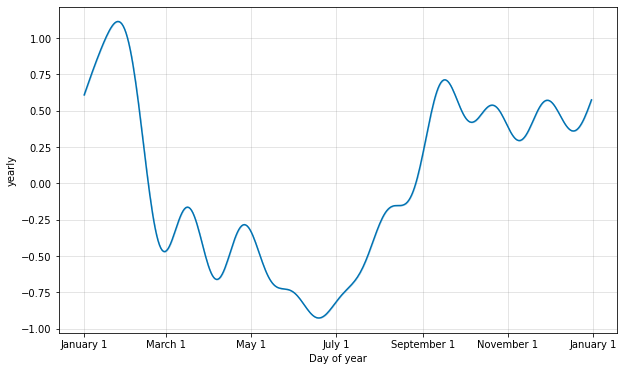
デフォルト値は適切である場合が多いですが、季節性がより高い頻度の変化に適合する必要があるとき、それらは増やすことができます、そして一般に滑らかでなくなります。フーリエ次数はモデルをインスタンス化するとき各組込みの季節性のために指定できます、ここではそれは 20 に増やされています :
from prophet.plot import plot_yearly
m = Prophet(yearly_seasonality=20).fit(df)
a = plot_yearly(m)
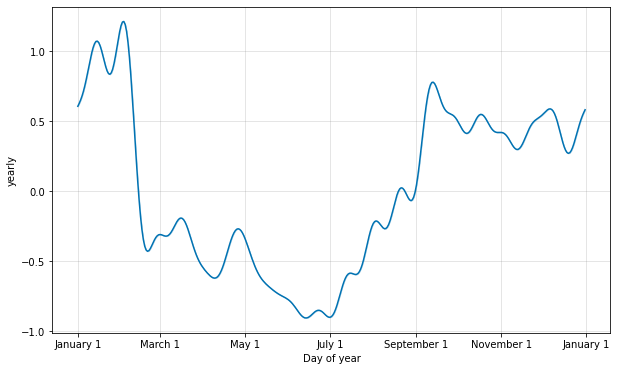
フーリエ項の数を増やすことは季節性を高速に変化するサイクルに適合させることを可能にしますが、過剰適合に繋がる可能性もあります : N 個のフーリエ項はサイクルをモデル化するために使用される 2N 変数に相当します。
カスタム季節性を指定する
Prophet は時系列が 2 つのサイクル長を越える場合、デフォルトで weekly と yearly の季節性に適合させます。それはまた部分的な daily 時系列のために daily の季節性にも適合させます。add_seasonality メソッド (Python) or 関数 (R) を使用して他の季節性 (monthly, quarterly, hourly) を追加することができます。
この関数への入力は名前、季節性の期間 (period) (in days)、そして季節性のためのフーリエ次数です。参考までに、デフォルトでは Prophet は weekly 季節性のために 3 のフーリエ次数をそして yearly 季節性のために 10 を使用します。add_seasonality へのオプションの入力はその季節性成分のための prior scale です – これは下で議論されます。
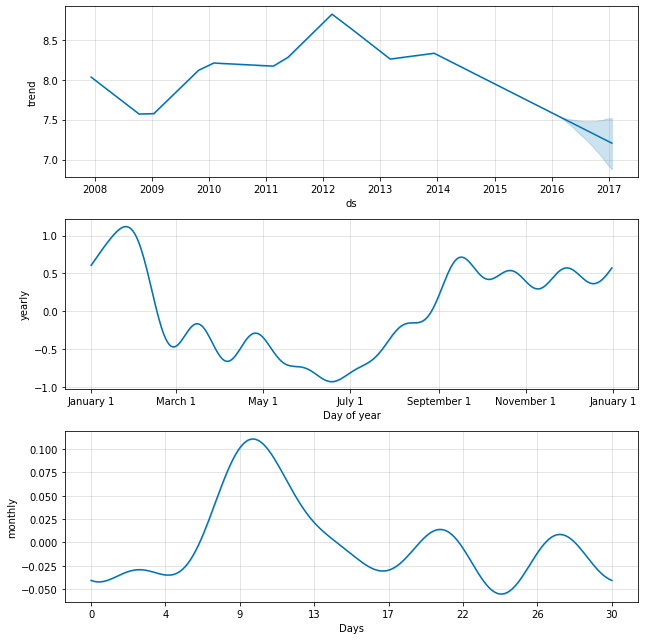
例として、ここでは クイックスタート から Peyton Manning データを適合させますが、weekly 季節性を monthly 季節性で置き換えます。そして monthly 季節性は成分プロットに現れます :
m = Prophet(weekly_seasonality=False)
m.add_seasonality(name='monthly', period=30.5, fourier_order=5)
forecast = m.fit(df).predict(future)
fig = m.plot_components(forecast)
他の要因に依存する季節性
ある場合には、夏の間は年の残りの間とは異なるような weekly 季節パターンや、週末 vs 平日で異なるような daily 季節パターンのように、季節性は他の要因に依存するかもしれません。これらのタイプの季節性は条件付き季節性を使用してモデル化できます。
クイックスタート からの Peyton Manning サンプルを考えます。デフォルトの weekly 季節性は、weekly 季節性のパターンが一年を通して同じであることを仮定していますが、(毎日曜日に試合がある) オンシーズン中とオフシーズンの間では weekly 季節性のパターンが異なることを私たちは予想します。個別のオンシーズンとオフシーズンの weekly 季節性を構築するために条件付き季節性を使用できます。
最初にデータフレームにブーリアン・カラムを追加します、これは各日付がオンシーズンかオフシーズンにあるかを示します :
def is_nfl_season(ds):
date = pd.to_datetime(ds)
return (date.month > 8 or date.month < 2)
df['on_season'] = df['ds'].apply(is_nfl_season)
df['off_season'] = ~df['ds'].apply(is_nfl_season)
そして組込みの weekly 季節性を無効にして、それを、条件として指定されたこれらのカラムを持つ 2 つの weekly 季節性で置き換えます。これは、季節性は condition_name カラムが True である日付にだけ適用されることを意味します。また (そのために) 予測を行なう future データフレームにカラムを追加しなければなりません。
m = Prophet(weekly_seasonality=False)
m.add_seasonality(name='weekly_on_season', period=7, fourier_order=3, condition_name='on_season')
m.add_seasonality(name='weekly_off_season', period=7, fourier_order=3, condition_name='off_season')
future['on_season'] = future['ds'].apply(is_nfl_season)
future['off_season'] = ~future['ds'].apply(is_nfl_season)
forecast = m.fit(df).predict(future)
fig = m.plot_components(forecast)
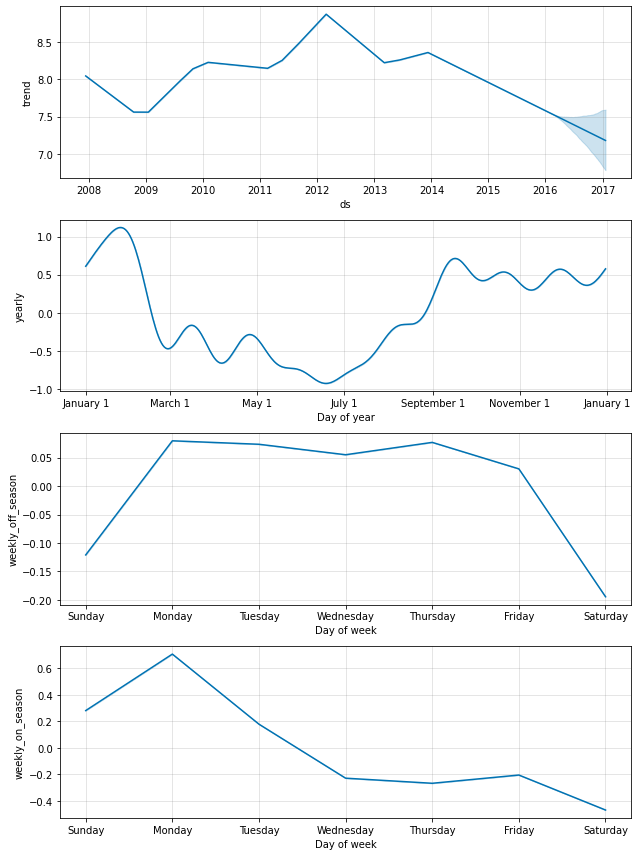
両方の季節性が今では上記の成分プロットに現れます。ゲームが毎土曜日にプレーされるオンシーズンの間、日曜日と月曜日に大規模な増加があることが見れますが、オフシーズンの間にはまったくありません。
休日と季節性のための Prior (事前) スケール
休日が過剰適合していることを見つける場合、パラメータ holidays_prior_scale を使用してそれらを滑らかにするために prior スケールを調整できます。デフォルトではこのパラメータは 10 で、それは正則化を殆ど提供しません。このパラメータを減少させると休日効果を減衰させます :
m = Prophet(holidays=holidays, holidays_prior_scale=0.05).fit(df)
forecast = m.predict(future)
forecast[(forecast['playoff'] + forecast['superbowl']).abs() > 0][
['ds', 'playoff', 'superbowl']][-10:]
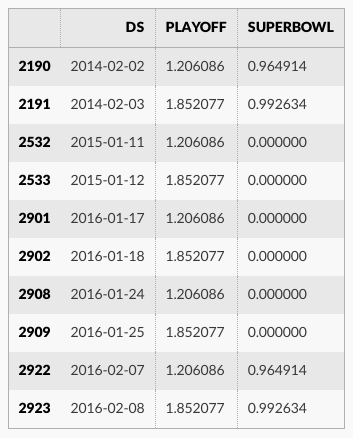
休日効果の大きさは前に比べて減少しています、特にスーパーボウルについて、これは最も少ない観測を持ちました。季節性モデルがデータに適合する範囲を同様に調整するパラメータ seasonality_prior_scale があります。
prior スケールは、holidays データフレーム内にカラム prior_scale を含めることにより個々の休日のために個別に設定できます。個々の季節性のための prior スケールは add_seasonality への引数として渡すことができます。例えば、weekly 季節性のためだけの prior スケールは次を使用して設定できます :
m = Prophet()
m.add_seasonality(
name='weekly', period=7, fourier_order=3, prior_scale=0.1)
追加のリグレッサー
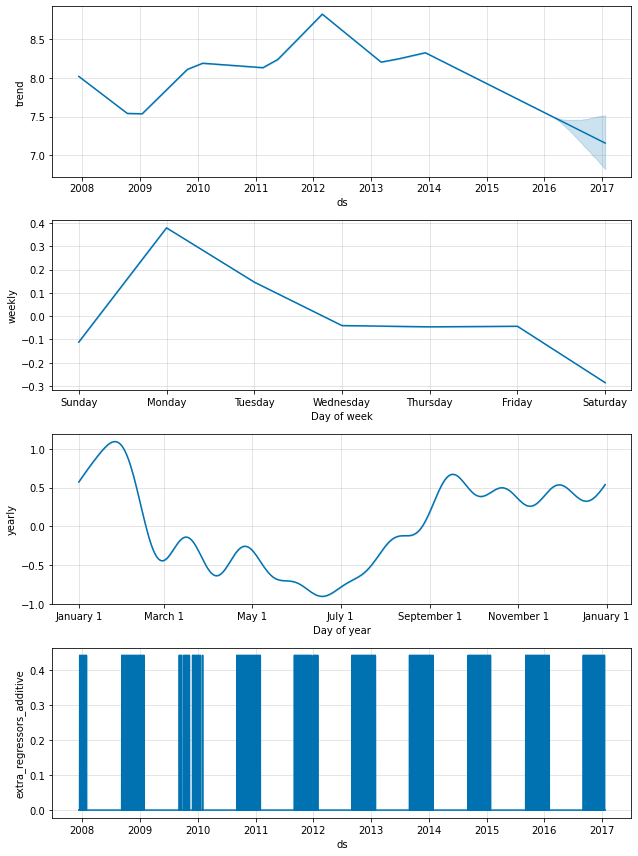
add_regressor メソッドか関数を使用して追加のリグレッサーがモデルの線形部分に追加できます。regressor 値を持つカラムは fitting と prediction データフレームの両方で存在する必要があります。例えば、NFL シーズンの間の日曜日に追加の効果を追加することができます。成分プロットでは、この効果は ‘extra_regressors’ プロットに現れます :
def nfl_sunday(ds):
date = pd.to_datetime(ds)
if date.weekday() == 6 and (date.month > 8 or date.month < 2):
return 1
else:
return 0
df['nfl_sunday'] = df['ds'].apply(nfl_sunday)
m = Prophet()
m.add_regressor('nfl_sunday')
m.fit(df)
future['nfl_sunday'] = future['ds'].apply(nfl_sunday)
forecast = m.predict(future)
fig = m.plot_components(forecast)
NFL サンデーはまた過去と未来の NFL サンデーのリストを作成して、上述の “holidays” インターフェイスを使用して処理されました。add_regressor 関数は追加の (= extra) 線形リグレッサーを定義するためにより一般的なインターフェイスを提供し、そして特にリグレッサーは二値インジケーターであることを必要としません。別の時系列をリグレッサーとして使用できるでしょうが、その future 値は知られなければなりません。
このノートブック は自転車 (bicycle) の使用量の予測において追加のリグレッサーとして天気要因を使用する例を示し、そして他の時系列が追加のリグレッサーとして含まれる方法の優れた例を提供します。
add_regressor 関数は prior スケール (デフォルトでは holiday prior スケールが使用されます) とリグレッサーが標準化されているか否かを指定するためのオプション引数を持ちます - Python の help(Prophet.add_regressor) そして R の ?add_regressor で docstring を見てください。リグレッサーはモデル適合の前に追加されなければならないことに注意してください。Prophet はまたリグレッサーが履歴を通して定数である場合にはエラーを上げます、何故ならばそれから適合するものがないからです。
追加のリグレッサーは履歴と未来の日付の両方のために知られなければなりません。従ってそれは (nfl_sunday のように) 未来の値を知っているものか、あるいは他で別に予測された何かでなければなりません。上でリンクされたノートブックで使用される天気リグレッサーは未来値のために使用できる予測を持つ追加のリグレッサーの良いサンプルです。Prophet のような時系列モデルで予測された別の時系列をリグレッサーとして使用することもできます。例えば、r(t) が y(t) のためのリグレッサーとして含まれる場合、Prophet は r(t) を予測するために使用できてそしてその予測は y(t) を予測するとき未来値としてプラグインできます。このアプローチまわりの注意点は : これは r(t) が y(t) を予測するのが幾分容易でない限りは多分役立ちません。これは r(t) の予測誤差が y(t) の予測で誤差を生成するからです。これが有用であり得る一つの設定は階層型時系列内です、そこでは高い信号対雑音 (= signal-to-noise) を持ち予測が容易なトップレベルの予測があります。その予測は各下位レベルの系列のための予測に含めることができます。
追加のリグレッサーはモデルの線形成分に配置されますので、基礎的なモデルは、加法 or 乗法要因のいずれかとして時系列が追加のリグレッサーに依存します (乗法のためには次のセクション参照)。
追加のリグレッサーの係数
追加のリグレッサーの beta 係数を抽出するため、適合されたモデル上でユティリティ関数 regressor_coefficients を使用します (Python では from prophet.utilities import regressor_coefficients, R では prophet::regressor_coefficients)。各リグレッサーのための推定された beta 係数はリグレッサー値の単位増加に対する予測値の増加をおおよそ表します (返される係数は常に元のデータのスケールであることに注意してください)。mcmc_samples が指定される場合、各係数の信用区間 (= credible interval) も返されます、これは各レグレッサーが「統計的に有意である」かを識別するのに役立ちます。
以上
Prophet 1.1 : クイックスタート
Prophet 1.1 : クイックスタート (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 08/29/2023 (1.1.4)
* 本ページは、Prophet の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。
- 人工知能研究開発支援
- 人工知能研修サービス(経営者層向けオンサイト研修)
- テクニカルコンサルティングサービス
- 実証実験(プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
- PoC(概念実証)を失敗させないための支援
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
- 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション
- sales-info@classcat.com ; Web: www.classcat.com ; ClassCatJP
Prophet 1.1 : クイックスタート
Python API
Prophet は sklearn モデル API に従います。Prophet クラスのインスタンスを作成してからその fit と predict メソッドを呼び出します。
Prophet への入力は常に 2 つのカラム : ds と y を含むデータフレームです。ds (datestamp) カラムは Pandas により想定される形式である必要があり、理想的には日付のための YYYY-MM-DD またはタイムスタンプのための YYYY-MM-DD HH:MM:SS です。y カラムは数値でなければなりません、そして予測したい測定値を表します。
例として、 Peyton Manning のための Wikipedia ページのログの daily ページビューの時系列を見てみましょう。このデータを R の Wikipediatrend パッケージを使用してかき集めました (scraped)。Peyton Manning は良いサンプルを提供します、何故ならばそれは複数の季節性 (= seasonality)、成長率の変化、そして (Manning のプレーオフとスーパーボウルの出現のような) 特別な日をモデル化する機能のような Prophet の機能の幾つかを例示するからです。CSV は ここ で利用可能です。
最初にデータをインポートします :
import pandas as pd
from prophet import Prophet
df = pd.read_csv('https://raw.githubusercontent.com/facebook/prophet/main/examples/example_wp_log_peyton_manning.csv')
df.head()
df.tail()
df.count()
ds 2905 y 2905 dtype: int64
新しい Prophet オブジェクトをインスタンス化することによりモデルを適合させます。予測手続きへの任意の設定はコンストラクタに渡されます。そしてその fit メソッドを呼び出して履歴データフレームを渡します。フィッティングには 1-5 秒かかるはずです。
m = Prophet()
m.fit(df)
そして予測は (そのために予測が行われる) 日付を含むカラム ds を持つデータフレーム上で行なわれます。ヘルパーメソッド Prophet.make_future_dataframe を使用して指定された日数だけ future 内に拡張した適切なデータフレームを得ることができます。デフォルトではそれは履歴からの日付も含みますので、モデルの適合も分かります。
future = m.make_future_dataframe(periods=365)
future.tail()
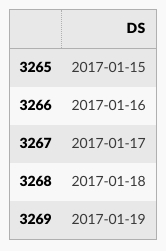
predict メソッドは future の各行に予測された値を割当てます、それは yhat と名前付けられます。履歴日付を渡す場合、それは in-sample な適合を提供します。ここで forecast オブジェクトは新しいデータフレームで、それは予測を持つカラム yhat と、成分と不確定区間のためのカラムを含みます。
forecast = m.predict(future)
forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].tail()
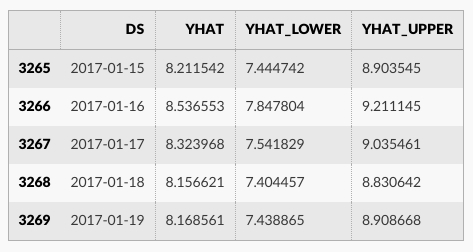
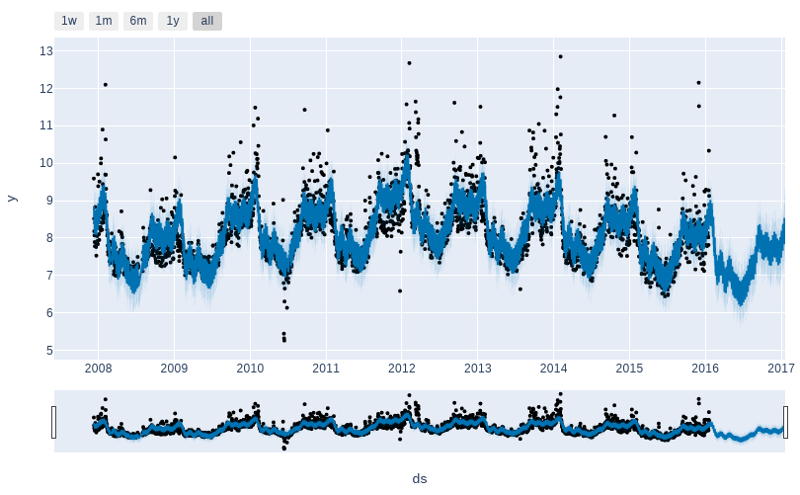
Prophet.plot メソッドを呼び出して forecast データフレームを渡すことにより予測をプロットできます。
fig1 = m.plot(forecast)
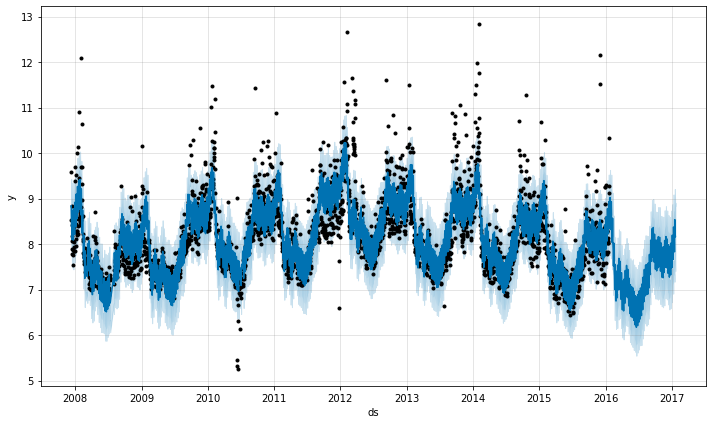
予測成分を見ることを望む場合、Prophet.plot_components メソッドを利用できます。デフォルトでは、時系列のトレンド、yearly 季節性と weekly 季節性を見ます。休日を含める場合、ここでそれらも見ます。
fig2 = m.plot_components(forecast)
予測と成分の対話的な図は plotly で作成できます。plotly 4.0 かそれ以上を個別にインストールする必要があります、それはデフォルトでは prophet と共にインストールされないからです。notebook と ipywidgets パッケージをインストールする必要もあります。
from prophet.plot import plot_plotly, plot_components_plotly
plot_plotly(m, forecast)
plot_components_plotly(m, forecast)
各メソッドのために利用可能なオプションについての詳細は docstrings で利用可能です、例えば help(Prophet) や help(Prophet.fit) を通してです。CRAN の R リファレンスマニュアル は利用可能な関数の総ての正確なリストを提供します、それらの各々は Python 同値を持ちます。
以上
ClassCat® Chatbot
人工知能開発支援
- テクニカルコンサルティングサービス
- 実証実験 (プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
クラスキャット
セールス・インフォメーション
E-Mail:sales-info@classcat.com