ホーム » 「ADTK 0.6」タグがついた投稿
タグアーカイブ: ADTK 0.6
ADTK (異常検知ツールキット) 0.6 : Examples : Transformer
ADTK (異常検知ツールキット) 0.6 : Examples : Transformer (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 06/22/2021 (0.6.2)
* 本ページは、ADTK の以下のページの Transformer セクションを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。

スケジュールは弊社 公式 Web サイト でご確認頂けます。
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
| 人工知能研究開発支援 | 人工知能研修サービス | テレワーク & オンライン授業を支援 |
| PoC(概念実証)を失敗させないための支援 (本支援はセミナーに参加しアンケートに回答した方を対象としています。) | ||
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |
![]()
ADTK (異常検知ツールキット) 0.6 : Examples : Transformer
概要
- RollingAggregate – スライディング・ウィンドウを時系列に沿って roll して選択された演算を使用して aggregate します。一般的な例は移動平均 (= moving average)、rolling 標準偏差, etc. を含みます。例えば、時系列に沿って妥当な値の rolling カウントを追跡します、これは欠落する値が頻繁に発生するとき alarm を上げるのに役立ちます。
- DoubleRollingAggregate – 時系列に沿って 2 つのスライディング・ウィンドウを並べて roll して、選択された演算を使用して aggregate し、そして 2 つのウィンドウ間の aggregated metrics の差異を追跡します。これは時系列の統計的動作の変化を追跡するのに役立つかもしれません。
- ClassicSeasonalDecomposition – 系列をトレンド・パート (オプション), seasonal パートと残差パートに分解します。残差パートは seasonal パータンからの異常偏差を識別する役に立つかもしれません。
- Retrospect – retrospective 値を持つデータフレームを返します、i.e. 時間 t における行は (t-k) における値を含みます、ここで k はユーザにより指定されます。この transformer はラグ効果 (= lagging effect) が考慮されるべきケースのために有用であるかもしれません。
- RegressionResidual – 多変量系列への回帰を遂行して回帰残差を返します。これは系列の間の通常の関係の異常な violation を識別するのに役立つかもしれません。
- PcaProjection – 多変量系列を最初の k 主成分を持つ表現に変換します。
- PcaReconstruction – 多変量系列をその最初の k 主成分により結ばれた (spanned) 超平面に射影します。
- PcaReconstructionError – 多変量系列をその最初の k 主成分により結ばれた (spanned) 超平面に射影して、データポイントと最初の k 主成分の低ランク部分空間の間の距離を示すエラーを返します。
- CustomizedTransformer – カスタマイズされた detector のように、ユーザは関数を CustomizedTransformer1D or CustomizedTransformerHD を伴うカスタマイズされた transformer に変換しても良いです、その結果それは Pipe オブジェクトにより利用できます。
RollingAggregate
RollingAggregate はスライディング・ウィンドウを時系列に沿って roll して選択された演算を使用して aggregate します。一般的な例は移動平均 (= moving average)、rolling 標準偏差, etc. を含みます。
次の例では、時系列に沿って妥当な値の rolling カウントを追跡します、これは欠落する値が頻繁に発生するとき alarm を上げるのに役立ちます。
s = pd.read_csv('./data/pressure.csv', index_col="Time", parse_dates=True, squeeze=True)
s = validate_series(s)
plot(s, ts_linewidth=1, ts_markersize=4);
![]()
from adtk.transformer import RollingAggregate
s_transformed = RollingAggregate(agg='count', window=5).transform(s)
plot(s_transformed.rename("Rolling count of valid values"), ts_linewidth=1, ts_markersize=4);
![]()
DoubleRollingAggregate
DoubleRollingAggregate は時系列に沿って 2 つのスライディング・ウィンドウを並べて roll して、選択された演算を使用して aggregate し、そして 2 つのウィンドウ間の aggregated metrics の差異を追跡します。これは時系列の統計的動作の変化を追跡するのに役立つかもしれません。
次の例では、系列値の統計的分布の変化を追跡します。
s = pd.read_csv('./data/seismic.csv', index_col="Time", parse_dates=True, squeeze=True)
s = validate_series(s)
from adtk.transformer import DoubleRollingAggregate
s_transformed = DoubleRollingAggregate(
agg="quantile",
agg_params={"q": [0.1, 0.5, 0.9]},
window=50,
diff="l2").transform(s).rename("Diff rolling quantiles (mm)")
plot(pd.concat([s, s_transformed], axis=1));
![]()
次の例では、値レベルのシフトを追跡します。
s = pd.read_csv('./data/cpu.csv', index_col="Time", parse_dates=True, squeeze=True)
s = validate_series(s)
from adtk.transformer import DoubleRollingAggregate
s_transformed = DoubleRollingAggregate(
agg="median",
window=5,
diff="diff").transform(s).rename("Diff rolling median (mm)")
plot(pd.concat([s, s_transformed], axis=1));
![]()
次の例では、ウィンドウ・パラメータを調整することにより価格の異常変化を追跡します。
s = pd.read_csv('./data/price_short.csv', index_col="Time", parse_dates=True, squeeze=True)
s = validate_series(s)
from adtk.transformer import DoubleRollingAggregate
s_transformed = DoubleRollingAggregate(
agg="mean",
window=(3,1), #The tuple specifies the left window to be 3, and right window to be 1
diff="l1").transform(s).rename("Diff rolling mean with different window size")
plot(pd.concat([s, s_transformed], axis=1), ts_linewidth=1, ts_markersize=3);
![]()
ClassicSeasonalDecomposition
ClassicSeasonalDecomposition は系列をトレンド・パート (オプション), seasonal パートと残差パートに分解します。残差パートは seasonal パータンからの異常偏差を識別する役に立つかもしれません。
次の例では、系列に沿って通常の交通パターンから偏差を計算します、これは通常ではない交通量を識別する役に立つかもしれません。
s = pd.read_csv('./data/seasonal.csv', index_col="Time", parse_dates=True, squeeze=True)
s = validate_series(s)
from adtk.transformer import ClassicSeasonalDecomposition
s_transformed = ClassicSeasonalDecomposition().fit_transform(s).rename("Seasonal decomposition residual")
plot(pd.concat([s, s_transformed], axis=1), ts_markersize=1);
![]()
トレンドの抽出なしの ClassicSeasonalDecomposition は長期トレンドにノイズに加えて seasonal パターンが混在してるようなケースを処理できないでしょう。そのようなケースでは、オプションの trend が有効にされるべきです。
次の例では、ClassicSeasonalDecomposition は trend オプションが有効にされずに合成系列から残差系列と長期トレンドを分解することに失敗しています。
s = pd.read_csv('./data/seasonal+trend.csv', index_col="Time", parse_dates=True, squeeze=True)
s = validate_series(s)
s_transformed = ClassicSeasonalDecomposition(freq=7).fit_transform(s).rename("Seasonal decomposition residual and trend")
plot(pd.concat([s, s_transformed], axis=1), ts_linewidth=1, ts_markersize=4);
![]()
モデルの trend オプションを有効にして上の同じ例に再適用します、そこでは残差はトレンドから分離されます。
s_transformed = ClassicSeasonalDecomposition(freq=7, trend=True).fit_transform(s).rename("Seasonal decomposition residual")
plot(pd.concat([s, s_transformed], axis=1), ts_linewidth=1, ts_markersize=4);
![]()
Retrospect
Retrospect は retrospective 値を持つデータフレームを返します、i.e. 時間 t における行は (t-k) における値を含みます、ここで k はユーザにより指定されます。この transformer はラグ効果 (= lagging effect) が考慮されるべきケースのために有用であるかもしれません。
次の例では、合成系列のために retrospective データフレームを作成します。
s = pd.read_csv('./data/sin.csv', index_col="Time", parse_dates=True, squeeze=True)
s = validate_series(s)
from adtk.transformer import Retrospect
df = Retrospect(n_steps=4, step_size=20, till=50).transform(s)
plot(pd.concat([s, df], axis=1), curve_group="all");
![]()
RegressionResidual
RegressionResidual は多変量系列への回帰を遂行して回帰残差を返します。これは系列の間の通常の関係の異常な violation を識別するのに役立つかもしれません。
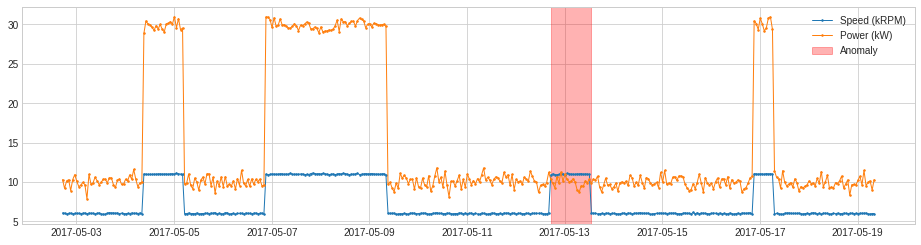
次の例では、発電機スピードとパワーの間の通常の相関性から系列の偏差を追跡します。
df = pd.read_csv('./data/generator.csv', index_col="Time", parse_dates=True)
df = validate_series(df)
from adtk.transformer import RegressionResidual
s = RegressionResidual(regressor=LinearRegression(), target="Speed (kRPM)").fit_transform(df).rename("Regression residual (kRPM)")
plot(pd.concat([df, s], axis=1), ts_linewidth=1, ts_markersize=3, curve_group=[("Speed (kRPM)", "Power (kW)"), "Regression residual (kRPM)"]);
![]()
PcaProjection
PcaProjection は多変量系列を最初の k 主成分を持つ表現に変換します。
次の例では、前の例で使用された 2-次元系列をその最初の主係数を保持するだけにより 1-次元に変換します。
from adtk.transformer import PcaProjection
s = PcaProjection(k=1).fit_transform(df)
plot(pd.concat([df, s], axis=1), ts_linewidth=1, ts_markersize=3, curve_group=[("Speed (kRPM)", "Power (kW)"), "pc0"]);
![]()
PcaReconstruction
PcaReconstruction は多変量系列をその最初の k 主成分により結ばれた (spanned) 超平面に射影します。
次の例では、前の例で使用された 2-次元系列をその最初の主成分のライン上に射影します。
from adtk.transformer import PcaReconstruction
df_transformed = PcaReconstruction(k=1).fit_transform(df).rename(columns={"Speed (kRPM)": "Speed reconstruction (kRPM)", "Power (kW)": "Power reconstruction (kW)"})
plot(pd.concat([df, df_transformed], axis=1), ts_linewidth=1, ts_markersize=3, curve_group=[("Speed (kRPM)", "Power (kW)"), ("Speed reconstruction (kRPM)", "Power reconstruction (kW)")]);
![]()
PcaReconstructionError
PcaReconstructionError は多変量系列をその最初の k 主成分により結ばれた (spanned) 超平面に射影して、データポイントと最初の k 主成分の低ランク部分空間の間の距離を示すエラーを返します。
次の例では、前の例で使用された 2-次元系列をその最初の主成分のライン上に射影します。
from adtk.transformer import PcaReconstructionError
s = PcaReconstructionError(k=1).fit_transform(df).rename("PCA Reconstruction Error")
plot(pd.concat([df, s], axis=1), ts_linewidth=1, ts_markersize=3, curve_group=[("Speed (kRPM)", "Power (kW)"), "PCA Reconstruction Error"]);
![]()
CustomizedTransformer
カスタマイズされた detector のように、ユーザは関数を CustomizedTransformer1D or CustomizedTransformerHD を伴うカスタマイズされた transformer に変換しても良いです、その結果それは Pipe オブジェクトにより利用できます。
次の例では、発電速度 (in kRPM) で除算された発電電力 (in kW) の計算された系列を得ました。
df = pd.read_csv('./data/generator.csv', index_col="Time", parse_dates=True)
df = validate_series(df)
def myTransformationFunc(df):
return (df["Power (kW)"] / df["Speed (kRPM)"]).rename("Power/Speed (kW/kRPM)")
pd.concat([df, s], axis=1)
Speed (kRPM) Power (kW) PCA Reconstruction Error Time 2017-05-02 17:08:37 6.066579 10.308257 0.097240 2017-05-02 18:08:37 6.035764 9.186763 0.006847 2017-05-02 19:08:37 5.922730 10.128382 0.168298 2017-05-02 20:08:37 5.999581 10.290300 0.139034 2017-05-02 21:08:37 6.031067 8.910037 0.000547 ... ... ... ... 2017-05-19 04:08:37 6.040213 9.531571 0.024986 2017-05-19 05:08:37 5.948470 9.959600 0.119861 2017-05-19 06:08:37 5.932115 10.144819 0.163950 2017-05-19 07:08:37 5.986675 8.983310 0.006974 2017-05-19 08:08:37 5.991435 10.305261 0.147651 400 rows × 3 columns
from adtk.transformer import CustomizedTransformerHD
customized_transformer = CustomizedTransformerHD(transform_func=myTransformationFunc)
s = customized_transformer.transform(df)
plot(pd.concat([df, s], axis=1), ts_linewidth=1, curve_group=[("Speed (kRPM)", "Power (kW)"), "Power/Speed (kW/kRPM)"]);
![]()
以上
ADTK (異常検知ツールキット) 0.6 : Examples : Detector
ADTK (異常検知ツールキット) 0.6 : Examples : Detector (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 06/22/2021 (0.6.2)
* 本ページは、ADTK の以下のページの Detector セクションを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。
スケジュールは弊社 公式 Web サイト でご確認頂けます。
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
| 人工知能研究開発支援 | 人工知能研修サービス | テレワーク & オンライン授業を支援 |
| PoC(概念実証)を失敗させないための支援 (本支援はセミナーに参加しアンケートに回答した方を対象としています。) | ||
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |
ADTK (異常検知ツールキット) 0.6 : Examples : Detector
概要
- ThresholdAD – 各時系列値を与えられた閾値と比較します。
- QuantileAD – 各時系列値を履歴 quantiles (分位点、変位値) と比較します。
例えば、気温が 99% パーセンタイルより上か 1% パーセンタイルより下であるとき時間ポイントを検知します。
- InterQuartileRangeAD – 単純な履歴統計に基づくもう一つの広く利用される detector で、四分位範囲 (IQR, interquartile range) に基づきます。
- GeneralizedESDTestAD – generalized extreme Studentized deviate (ESD) に基づいて異常を検知します。
※ generalized ESD テストのキーとなる仮定は正常値は近似的に正規分布に従うことであることに注意してください。
- PersistAD – 各時系列値をその前の値と比較します。
※ デフォルトでは PersistAD は一つ前の値をチェックするだけです、これは短期間スケールで additive 異常を捕捉するには良いですが、長期間スケールではそうではありません、何故ならばそれは近視眼的に過ぎるからです。
- LevelShiftAD – 隣同士の 2 つのスライディング時間ウィンドウにおける median 値の間の差を追跡する ことにより値レベルのシフトを検知します。
- VolatilityShiftAD – volatility (変動性) レベルのシフトを隣り合う 2 つのスライディング時間ウィンドウにおける 標準偏差間の差異を追跡する ことにより検知します。
- SeasonalAD – seasonal パターンの異常 vaiolation を検知します。
- AutoregressionAD – 時系列の自己回帰の異常な変化を検知します。
- MinClusterDetector – 多変量 時系列を高次元空間の独立したポイントとして扱い、それらをクラスタに分割し、そして最も小さいクラスタの値を異常として識別します。これは高次元空間の外れ値を捕捉するのに役立つかも知れません。
- OutlierDetector – 多変量 時間独立な外れ値検知を遂行して外れ値を異常として識別します。多変量外れ値検知アルゴリズムは同じ API に従う scikit-learn or 他のパッケージのそれらであり得ます。scikit-learn local outlier factor model とともに OutlierDetector を適用できます。
- RegressionAD – regressive error を追跡することにより 多変量 系列間の通常の関係の異常な violation を検知します。線形回帰モデルとともに RegressionAD を適用できます。
- PcaAD – 主成分分析 (PCA) を 多変量 時系列 (高次元空間のベクトルとして総ての時間ポイント) に遂行してそれらのベクトルの reconstruction error を追跡します。
- CustomizedDetector – CustomizedDetector1D と CustomizedDetectorHD はユーザに関数を他の detector オブジェクトとして (Pipeline オブジェクトにより、例えば) 利用できるようなカスタマイズされた detector オブジェクトに変換するために役立ちます。
ThresholdAD
ThresholdAD は各時系列値を与えられた閾値と比較します。
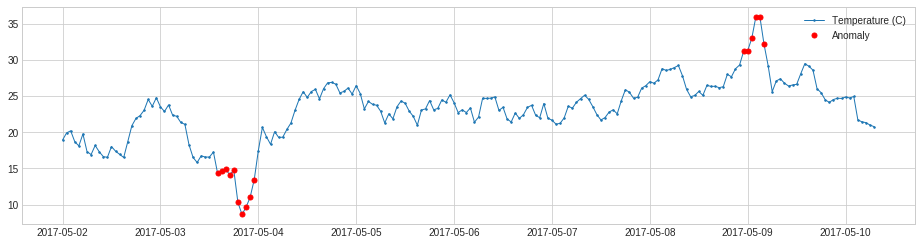
次の例では、気温が 30C より上か 15C より下であるとき時間ポイントを検知します。
import pandas as pd
s = pd.read_csv('./data/temperature.csv', index_col="Time", parse_dates=True, squeeze=True)
from adtk.data import validate_series
s = validate_series(s)
Time
2017-05-02 00:00:00 18.91
2017-05-02 01:00:00 19.91
2017-05-02 02:00:00 20.19
2017-05-02 03:00:00 18.69
2017-05-02 04:00:00 18.11
...
2017-05-10 03:00:00 21.70
2017-05-10 04:00:00 21.43
2017-05-10 05:00:00 21.32
2017-05-10 06:00:00 20.98
2017-05-10 07:00:00 20.76
Freq: H, Name: Temperature (C), Length: 200, dtype: float64
from adtk.detector import ThresholdAD
threshold_ad = ThresholdAD(high=30, low=15)
anomalies = threshold_ad.detect(s)
Time
2017-05-02 00:00:00 False
2017-05-02 01:00:00 False
2017-05-02 02:00:00 False
2017-05-02 03:00:00 False
2017-05-02 04:00:00 False
...
2017-05-10 03:00:00 False
2017-05-10 04:00:00 False
2017-05-10 05:00:00 False
2017-05-10 06:00:00 False
2017-05-10 07:00:00 False
Freq: H, Name: Temperature (C), Length: 200, dtype: bool
from adtk.visualization import plot
plot(s, anomaly=anomalies, ts_linewidth=1, ts_markersize=3, anomaly_markersize=5, anomaly_color='red', anomaly_tag="marker");
QuantileAD
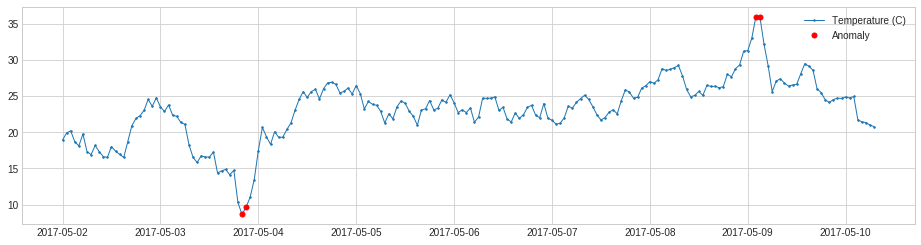
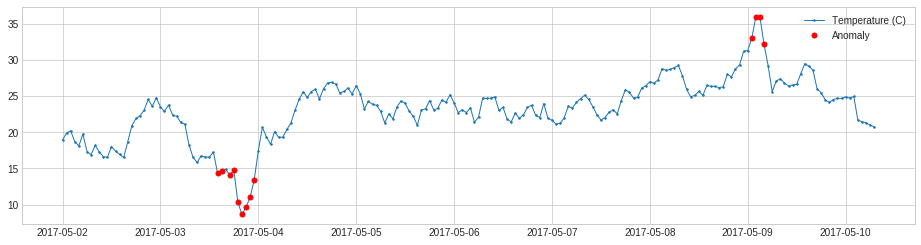
QuantileAD は各時系列値を履歴 quantiles (分位点、変位値) と比較します。
次の例では、気温が 99% パーセンタイルより上か 1% パーセンタイルより下であるとき時間ポイントを検知します。
from adtk.detector import QuantileAD
quantile_ad = QuantileAD(high=0.99, low=0.01)
anomalies = quantile_ad.fit_detect(s)
Time
2017-05-02 00:00:00 False
2017-05-02 01:00:00 False
2017-05-02 02:00:00 False
2017-05-02 03:00:00 False
2017-05-02 04:00:00 False
...
2017-05-10 03:00:00 False
2017-05-10 04:00:00 False
2017-05-10 05:00:00 False
2017-05-10 06:00:00 False
2017-05-10 07:00:00 False
Freq: H, Name: Temperature (C), Length: 200, dtype: bool
plot(s, anomaly=anomalies, ts_linewidth=1, ts_markersize=3, anomaly_markersize=5, anomaly_color='red', anomaly_tag="marker");
InterQuartileRangeAD
InterQuartileRangeAD は単純な履歴統計に基づくもう一つの広く利用される detector で四分位範囲 (IQR, interquartile range) に基づきます。When a value is out of the range defined by $[Q_1 – c \times IQR,\ Q_3 + c \times IQR]$ where $IQR = Q_3 – Q_1$ is the difference between 25% and 75% quantiles. この detector は訓練データの小さな部分が異常であるか異常が全くない場合には通常は QuantileAD よりも選択されます。
from adtk.detector import InterQuartileRangeAD
iqr_ad = InterQuartileRangeAD(c=1.5)
anomalies = iqr_ad.fit_detect(s)
plot(s, anomaly=anomalies, ts_linewidth=1, ts_markersize=3, anomaly_markersize=5, anomaly_color='red', anomaly_tag="marker");
GeneralizedESDTestAD
GeneralizedESDTestAD は generalized extreme Studentized deviate (ESD) に基づいて異常を検知します。
generalized ESD テストのキーとなる仮定は正常値は近似的に正規分布に従うことであることに注意してください。この仮定が有効であるときだけにこの detector を利用してください。
from adtk.detector import GeneralizedESDTestAD
esd_ad = GeneralizedESDTestAD(alpha=0.3)
anomalies = esd_ad.fit_detect(s)
plot(s, anomaly=anomalies, ts_linewidth=1, ts_markersize=3, anomaly_markersize=5, anomaly_color='red', anomaly_tag="marker");
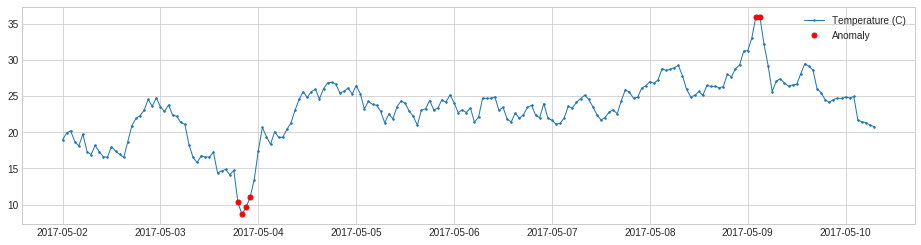
PersistAD
PersistAD は各時系列値をその前の値と比較します。内部的には、それは transformer DoubleRollingAggregate を伴う pipenet として実装されます。
以下の例では、価格の異常な positive 変化を検知します。
s = pd.read_csv('./data/price_short.csv', index_col="Time", parse_dates=True, squeeze=True)
s = validate_series(s)
Time
2017-05-02 00:00:00 21.33
2017-05-02 01:00:00 22.05
2017-05-02 02:00:00 20.50
2017-05-02 03:00:00 20.49
2017-05-02 04:00:00 21.11
...
2017-05-10 03:00:00 49.34
2017-05-10 04:00:00 50.29
2017-05-10 05:00:00 49.27
2017-05-10 06:00:00 50.43
2017-05-10 07:00:00 49.86
Freq: H, Name: Price ($), Length: 200, dtype: float64
from adtk.detector import PersistAD
persist_ad = PersistAD(c=3.0, side='positive')
anomalies = persist_ad.fit_detect(s)
plot(s, anomaly=anomalies, ts_linewidth=1, ts_markersize=3, anomaly_color='red');
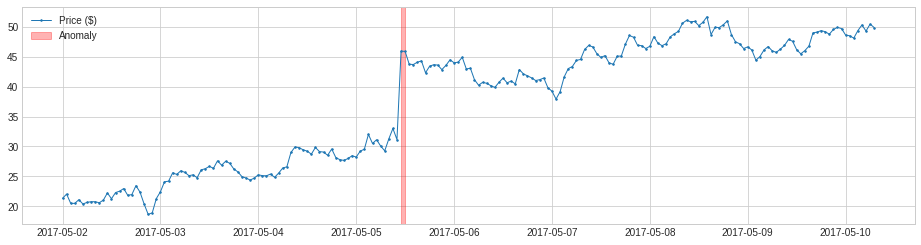
デフォルトでは、PersistAD は一つ前の値をチェックするだけです、これは短期間スケールで additive 異常を捕捉するには良いですが、長期間スケールではそうではありません、何故ならばそれは近視眼的に過ぎるからです。
次の例では、より長いタイムスケールで価格の meaningful 下落を捕捉することに失敗しています。
s = pd.read_csv('./data/price_long.csv', index_col="Time", parse_dates=True, squeeze=True)
s = validate_series(s)
Time
2017-05-02 00:00:00 21.33
2017-05-02 01:00:00 22.05
2017-05-02 02:00:00 20.50
2017-05-02 03:00:00 20.49
2017-05-02 04:00:00 21.11
...
2017-06-12 11:00:00 4.08
2017-06-12 12:00:00 3.75
2017-06-12 13:00:00 5.19
2017-06-12 14:00:00 4.80
2017-06-12 15:00:00 5.44
Freq: H, Name: Price ($), Length: 1000, dtype: float64
persist_ad = PersistAD(c=1.5, side='negative')
anomalies = persist_ad.fit_detect(s)
plot(s, anomaly=anomalies, anomaly_color='red');
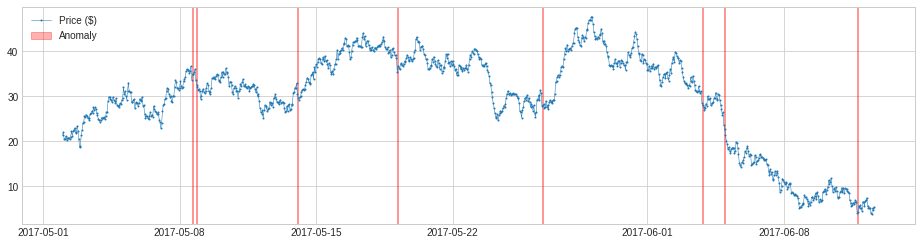
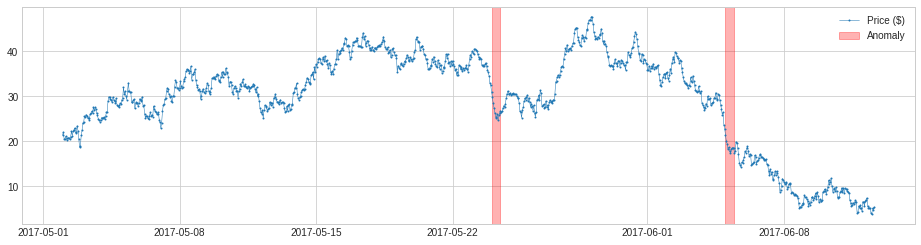
パラメータウィンドウを 1 より大きい数字に変更しても良いです、すると detector は値を前の時間ウィンドウの中央値か平均と値を比較します。それは近視眼的ではあまりないので、これは中期から長期スケールでの異常変化を捕捉します。上と同じサンプルで、それは長期スケールで価格の下落を成功的に検出しています。
persist_ad.window = 24
anomalies = persist_ad.fit_detect(s)
plot(s, anomaly=anomalies, anomaly_color='red');
LevelShiftAD
LevelShiftAD は隣同士の 2 つのスライディング時間ウィンドウにおける median 値の間の差を追跡することにより値レベルのシフトを検知します。それは瞬間的なスパイクには敏感ではなく、ノイズの多い外れ値が頻繁に発生する場合には良い選択である可能性があります。内部的には、それは transformer DoubleRollingAggregate を伴う pipenet として実装されます。
次のサンプルでは、CPU 使用率のシフトポイントを検知します。
s = pd.read_csv('./data/cpu.csv', index_col="Time", parse_dates=True, squeeze=True)
s = validate_series(s)
Time
2017-05-02 00:00:00 19.597904
2017-05-02 01:00:00 18.858335
2017-05-02 02:00:00 16.145520
2017-05-02 03:00:00 17.989939
2017-05-02 04:00:00 18.745603
...
2017-06-12 11:00:00 16.782793
2017-06-12 12:00:00 17.601807
2017-06-12 13:00:00 19.728837
2017-06-12 14:00:00 17.531739
2017-06-12 15:00:00 18.770941
Freq: H, Name: CPU (%), Length: 1000, dtype: float64
from adtk.detector import LevelShiftAD
level_shift_ad = LevelShiftAD(c=6.0, side='both', window=5)
anomalies = level_shift_ad.fit_detect(s)
plot(s, anomaly=anomalies, anomaly_color='red');
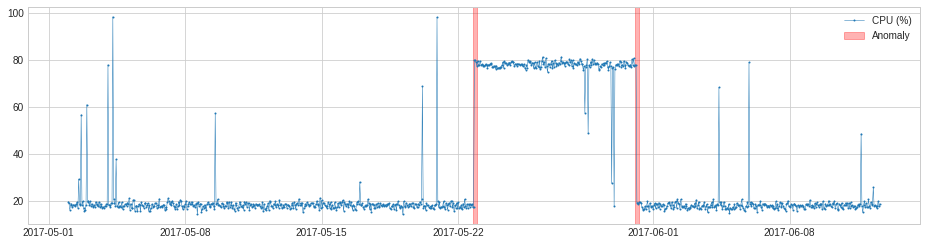
VolatilityShiftAD
VolatilityShiftAD は volatility (変動性) レベルのシフトを隣り合う 2 つのスライディング時間ウィンドウにおける標準偏差間の差異を追跡することにより検知します。内部的には、それは transformer DoubleRollingAggregate を伴う pipenet として実装されます。
次の例では、地震の始まりを示す、地震振幅 (= seismic amplitude) の変動性の positive shift を検知しています。
s = pd.read_csv('./data/seismic.csv', index_col="Time", parse_dates=True, squeeze=True)
s = validate_series(s)
Time
2017-05-02 17:08:37.000 3.994760
2017-05-02 17:08:37.500 2.145837
2017-05-02 17:08:38.000 -4.636201
2017-05-02 17:08:38.500 -0.025152
2017-05-02 17:08:39.000 1.864008
...
2017-05-02 17:16:54.500 23.206275
2017-05-02 17:16:55.000 -18.304593
2017-05-02 17:16:55.500 4.448594
2017-05-02 17:16:56.000 57.900672
2017-05-02 17:16:56.500 17.283682
Freq: 500L, Name: Seismic amplitude (mm), Length: 1000, dtype: float64
from adtk.detector import VolatilityShiftAD
volatility_shift_ad = VolatilityShiftAD(c=6.0, side='positive', window=30)
anomalies = volatility_shift_ad.fit_detect(s)
plot(s, anomaly=anomalies, anomaly_color='red');
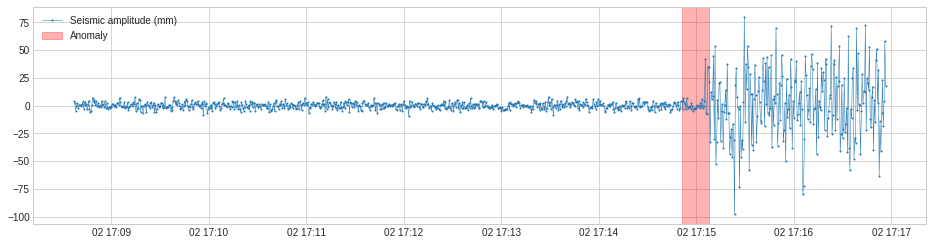
SeasonalAD
SeasonalAD は seasonal パターンの異常 vaiolation を検知します。内部的には、それは transformer ClassicSeasonalDecomposition を伴う pipenet として実装されます。
次の例では、普通ではない交通量を検知します、これは殆どは主要な祝日で発生しました。
s = pd.read_csv('./data/seasonal.csv', index_col="Time", parse_dates=True, squeeze=True)
s = validate_series(s)
Time
2014-07-01 00:00:00 10844
2014-07-01 00:30:00 8127
2014-07-01 01:00:00 6210
2014-07-01 01:30:00 4656
2014-07-01 02:00:00 3820
...
2015-01-31 21:30:00 24670
2015-01-31 22:00:00 25721
2015-01-31 22:30:00 27309
2015-01-31 23:00:00 26591
2015-01-31 23:30:00 26288
from adtk.detector import SeasonalAD
seasonal_ad = SeasonalAD(c=3.0, side="both")
anomalies = seasonal_ad.fit_detect(s)
plot(s, anomaly=anomalies, ts_markersize=1, anomaly_color='red', anomaly_tag="marker", anomaly_markersize=2);
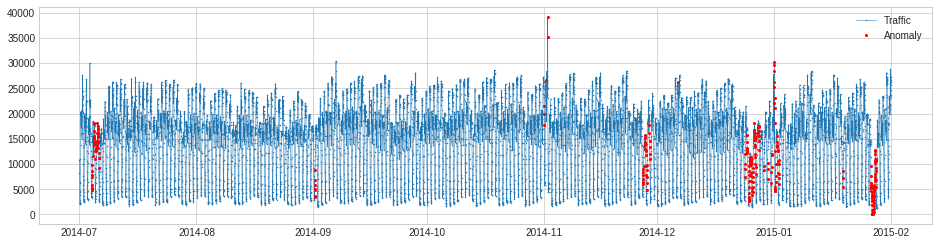
AutoregressionAD
AutoregressionAD は時系列の自己回帰の異常な変化を検知します。内部的には、それは transformers Retrospect と RegressionResidual を伴う pipenet として実装されます。
上と同じ例について、交通量履歴の普通ではない回帰動作の violatioin を検知します。
s = pd.read_csv('./data/seasonal.csv', index_col="Time", parse_dates=True, squeeze=True)
s = validate_series(s)
from adtk.detector import AutoregressionAD autoregression_ad = AutoregressionAD(n_steps=7*2, step_size=24, c=3.0) anomalies = autoregression_ad.fit_detect(s) plot(s, anomaly=anomalies, ts_markersize=1, anomaly_color='red', anomaly_tag="marker", anomaly_markersize=2);
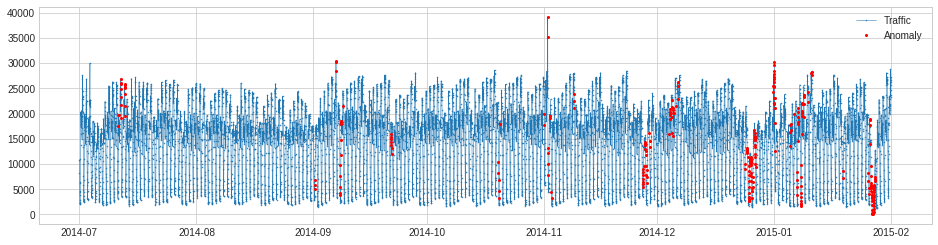
MinClusterDetector
MinClusterDetector は多変量時系列を高次元空間の独立したポイントとして扱い、それらをクラスタに分割し、そして最も小さいクラスタの値を異常として識別します。これは高次元空間の外れ値を捕捉するのに役立つかも知れません。
次の例は、発電機のスピードと生成されるパワー間の関係の異常な変化を検知します。通常の関係の violation は装置の failure を示します。
f = pd.read_csv('./data/generator.csv', index_col="Time", parse_dates=True, squeeze=True)
df = validate_series(df)
from adtk.detector import MinClusterDetector
from sklearn.cluster import KMeans
min_cluster_detector = MinClusterDetector(KMeans(n_clusters=3))
anomalies = min_cluster_detector.fit_detect(df)
plot(df, anomaly=anomalies, ts_linewidth=1, ts_markersize=3, anomaly_color='red', anomaly_alpha=0.3, curve_group='all');
OutlierDetector
OutlierDetector は多変量時間独立な外れ値検知を遂行して外れ値を異常として識別します。多変量外れ値検知アルゴリズムは同じ API に従う scikit-learn or 他のパッケージのそれらであり得ます。
上と同じ例について、scikit-learn local outlier factor model とともに OutlierDetector を適用します。
from adtk.detector import OutlierDetector
from sklearn.neighbors import LocalOutlierFactor
outlier_detector = OutlierDetector(LocalOutlierFactor(contamination=0.05))
anomalies = outlier_detector.fit_detect(df)
plot(df, anomaly=anomalies, ts_linewidth=1, ts_markersize=3, anomaly_color='red', anomaly_alpha=0.3, curve_group='all');
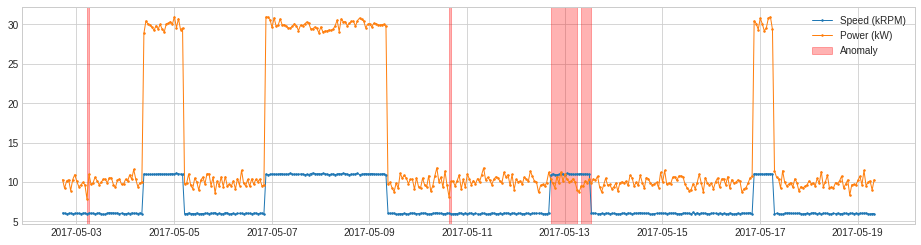
RegressionAD
RegressionAD は regressive error を追跡することにより多変量系列間の通常の関係の異常な violation を検知します。内部的には、それは transformer RegressionResidual を伴う pipenet として実装されます。
上と同じ例について、線形回帰モデルとともに RegressionAD を適用します。
from adtk.detector import RegressionAD
from sklearn.linear_model import LinearRegression
regression_ad = RegressionAD(regressor=LinearRegression(), target="Speed (kRPM)", c=3.0)
anomalies = regression_ad.fit_detect(df)
plot(df, anomaly=anomalies, ts_linewidth=1, ts_markersize=3, anomaly_color='red', anomaly_alpha=0.3, curve_group='all');
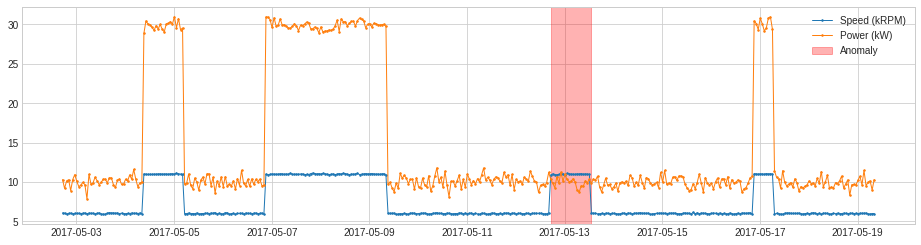
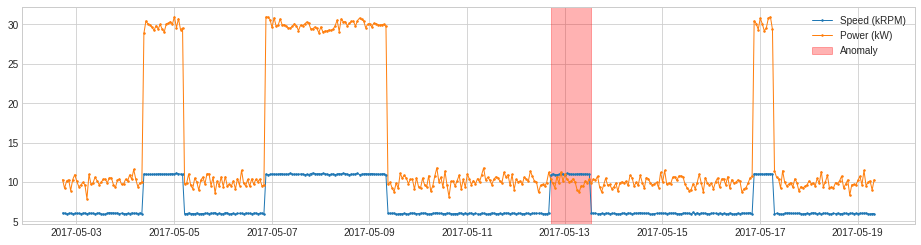
PcaAD
PcaAD は主成分分析 (PCA) を多変量時系列 (高次元空間のベクトルとして総ての時間ポイント) に遂行してそれらのベクトルの reconstruction error を追跡します。この detector は正常ポイントが低ランク manifold にある一方で異常ポイントがそうではないと想定されるときに有用です。内部的には、それは transformer PcaReconstructionError を伴う pipeline として実装されます。
上と同じ例に PcaAD を適用します。
from adtk.detector import PcaAD
pca_ad = PcaAD(k=1)
anomalies = pca_ad.fit_detect(df)
plot(df, anomaly=anomalies, ts_linewidth=1, ts_markersize=3, anomaly_color='red', anomaly_alpha=0.3, curve_group='all');
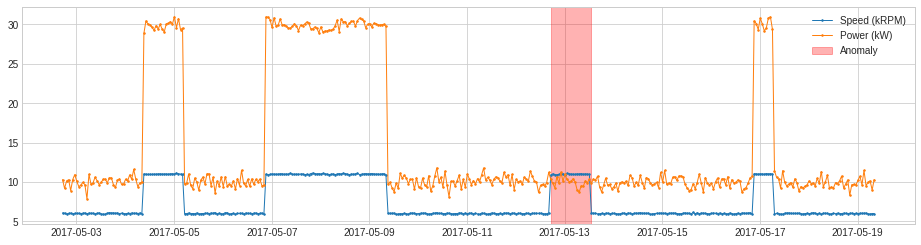
CustomizedDetector
CustomizedDetector1D と CustomizedDetectorHD はユーザに関数を他の detector オブジェクトとして (Pipeline オブジェクトにより、例えば) 利用できるようなカスタマイズされた detector オブジェクトに変換するために役立ちます。
次の例では、生成された電力 (in kW) が発電機速度 (in kRPM) の 1.2 倍未満であるときを検出します。
df = pd.read_csv('./data/generator.csv', index_col="Time", parse_dates=True)
df = validate_series(df)
df.head()
Speed (kRPM) Power (kW)
Time
2017-05-02 17:08:37 6.066579 10.308257
2017-05-02 18:08:37 6.035764 9.186763
2017-05-02 19:08:37 5.922730 10.128382
2017-05-02 20:08:37 5.999581 10.290300
2017-05-02 21:08:37 6.031067 8.910037
def myDetectionFunc(df):
return (df["Speed (kRPM)"] * 1.2 > df["Power (kW)"])
from adtk.detector import CustomizedDetectorHD
customized_detector = CustomizedDetectorHD(detect_func=myDetectionFunc)
anomalies = customized_detector.detect(df)
plot(df, anomaly=anomalies, ts_linewidth=1, ts_markersize=3, anomaly_color='red', anomaly_alpha=0.3, curve_group='all');
以上
ADTK (異常検知ツールキット) 0.6 : ユーザガイド
ADTK (異常検知ツールキット) 0.6 : ユーザガイド (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 06/21/2021 (0.6.2)
* 本ページは、ADTK の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。
スケジュールは弊社 公式 Web サイト でご確認頂けます。
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
| 人工知能研究開発支援 | 人工知能研修サービス | テレワーク & オンライン授業を支援 |
| PoC(概念実証)を失敗させないための支援 (本支援はセミナーに参加しアンケートに回答した方を対象としています。) | ||
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |
ADTK (異常検知ツールキット) 0.6 : ユーザガイド
これは ADTK で時系列のための異常検知モデルをどのように構築するかの簡潔なガイドです。ADTK を利用し始める前にこのガイドを読み通すことを総てのユーザに勧めます。
教師なし vs. 教師あり
モデルを構築する前にユーザが決める必要がある最初のことは問題を教師あり学習問題か教師なし問題として定式化することです。教師あり学習メソッドは訓練セットの時系列と normal/anomalous ラベルに基づいてモデルを訓練します、その一方で教師なしメソッドは時系列とドメイン知識のみに基づきモデルを構築し、ラベル付されたデータは必要としません。
現実世界の異常検知問題は通常はラベル付けされた履歴異常の欠落に悩まされます、これはユーザが堅牢な教師ありモデルを構築することを妨げます。この場合、教師なし/ルールベースのメソッドがより良い選択です。ADTK は時系列異常検知の教師なし/ルールベースのモデルのためのパッケージです。ユーザがタスクを教師あり学習問題として定式化する場合には、代わりのツールが必要とされます。
Anomaly Types
異常 (= anomaly) は広い概念で、時系列の多くの異なるタイプのイベントを参照するかもしれません。値のスパイク (急な山型)、変動性 (= volatility) のシフト、周期パターンの違反, etc. は総て特定のコンテキストに依拠して、異常か正常になり得ます。ADTK は異なるシナリオのための様々のタイプの異常検知モデルに組合せられる一般的なコンポーネントのセットを提供します。けれども、ADTK はユーザのためのモデルを自動的には選択したり構築しません。ユーザはどのようなタイプの異常を検知するのか知るべきで、それに従ってモデルを構築することができます。
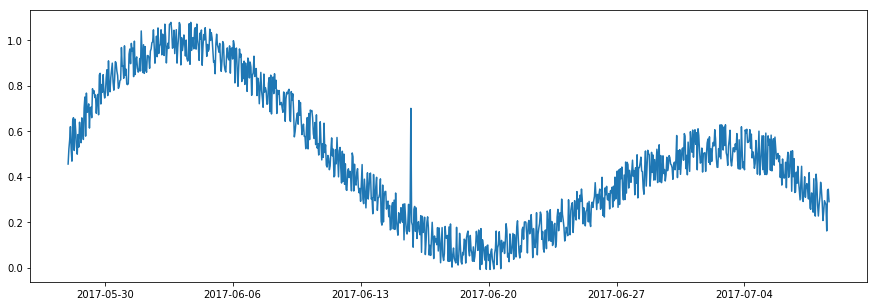
1. 外れ値 (= Outlier)
外れ値はその値が他とは本質的に異なるようなデータポイントです。時系列の外れ値ポイントはこの系列の正常範囲を越えます、データポイント間の一時的な関係を考慮することなしに。換言すれば、総てのデータポイントを時間独立と見做してさえも、外れ値ポイントは依然として際立ちます (= outstand)。
外れ値を検知するには、時系列値の正常範囲が detector が学習する必要があるものです。それは user-given absolute thresholds (adtk.detector.ThresholdAD) で定義できます。代わりに、ユーザは履歴データか正常範囲を学習するために detector を作成するかもしれません (adtk.detector.QuantileAD, adtk.detector.InterQuartileRangeAD と adtk.detector.GeneralizedESDTestAD)。
外れ値は異常の最も基本的なタイプす。他のタイプを対象とする異常検知メソッドはしばしば時系列を新しい一つに変換して外れ値検知がそれに対して適用されます。ADTK の殆どの進んだ detector はこのストラテジーに従っています。
2. スパイクとレベルシフト
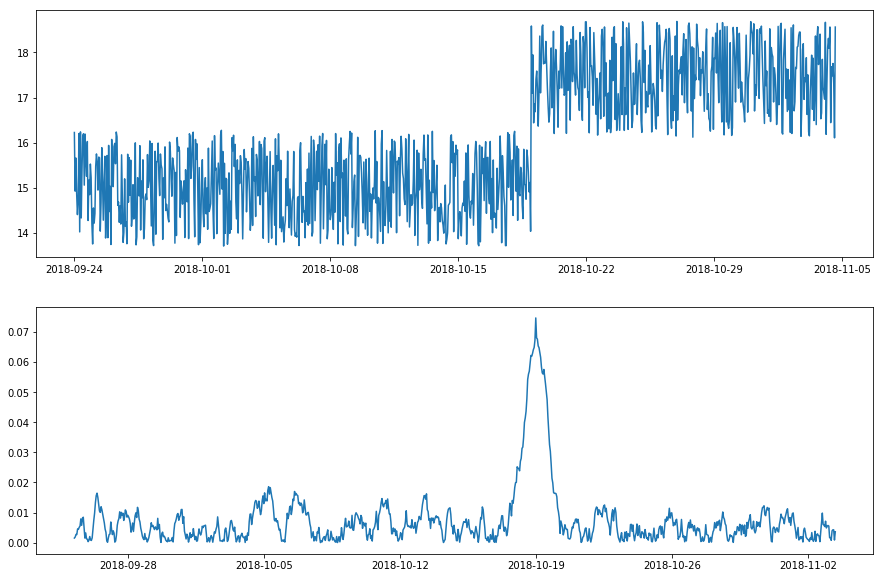
幾つかの状況では、時間ポイントが正常であるか否かはその値がその近接過去 (= near past) でアラインされるかどうかに依拠します。値の唐突な増加や減少は変化が一時的であればスパイク、あるいは変化が永続的であればレベルシフトと呼ばれます。スパイクは外れ値に類似しているように見えますが、外れ値が時間独立である一方で、それ (スパイク) は時間依存であることに注意してください。スパイクの値は時間的順序を考慮することなく総てのデータポイントで検査する場合正常である可能性があります (see figure below)。
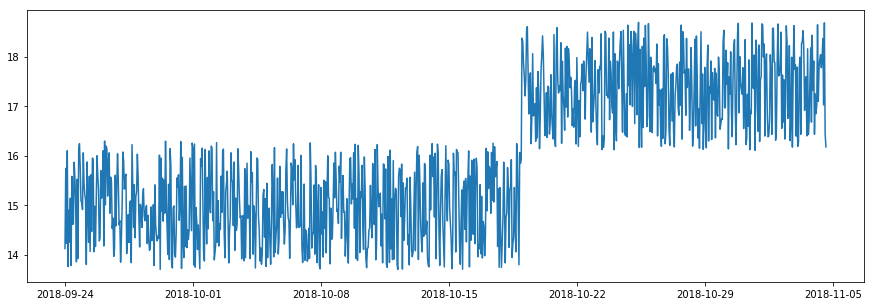
2 つの時間ウィンドウを並べてスライドしてそれらの mean や median 値の間の差異を追跡し続けても良いです。時間に渡るこの差異、これは新しい時系列です、は外れ値 detector で検査されます。左と右のウィンドウの統計が本質的に異なるときはいつでも、それはこの時間ポイントまわりの突然の変化を示します。時間ウィンドウの長さが検知する変化の時間スケールを制御します : スパイクについては、近接過去の表現激な情報を捉える左のウィンドウは右のものより長いです ; その一方で、レベルシフトについては、両者のウィンドウは stable ステータスを捉えるために十分に長くあるべきです。
adtk.detector.PersistAD と adtk.detector.LevelShiftAD はそれぞれスパイクとレベルシフトの detector です。両者は transformer adtk.transformer.DoubleRollingAggregate で実装されます、これは時系列を上で述べた 2 つの時間ウィンドウを持つ新しい系列に transform します。
Transform a time series with level shift using DoubleRollingAggregate with mean as time window statistic.
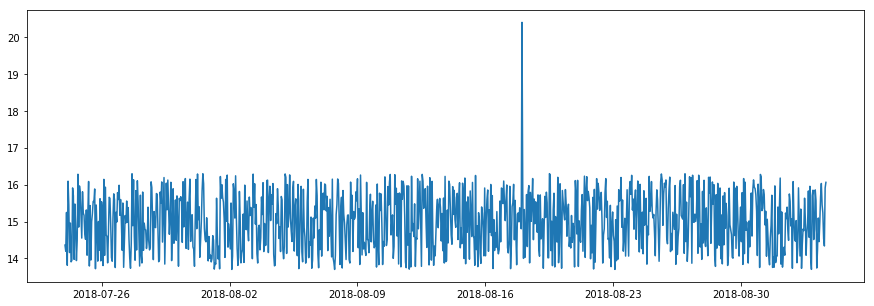
3. パターン変化
上で述べたストラテジーは値以外のパターンのシフトを検知するために一般化できるかもしれません。例えば、変動性 (= volatility) のシフトに関心がある場合、時間ウィンドウで追跡する統計値は mean/median の代わりに標準偏差であり得るかもしれません。adtk.transformer.DoubleRollingAggregate は関心あるパターンを定量化するために利用できるかもしれません。
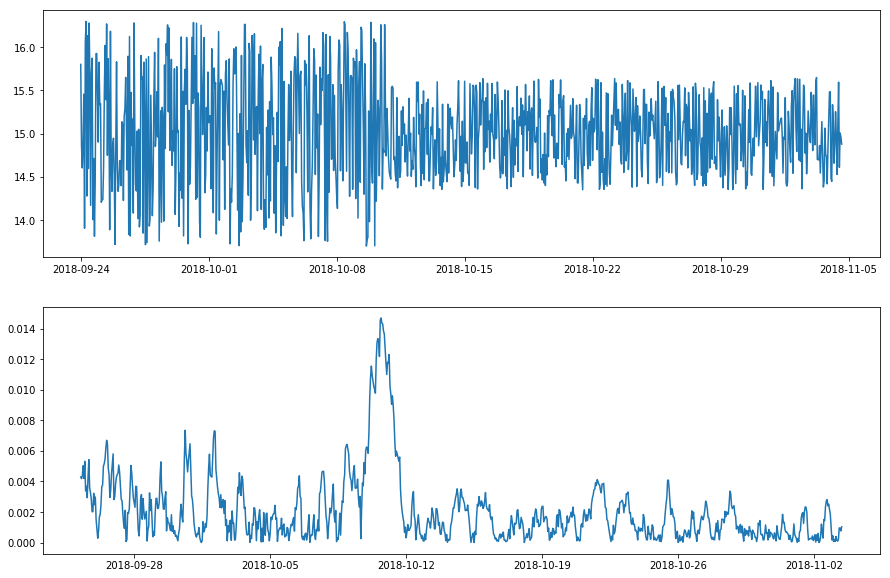
Transform a time series with volatility level shift using DoubleRollingAggregate with standard deviation as metric.
パターンの時間的変更を検知するためには、adtk.transformer.RollingAggregate も良い選択であるかもしれません。それは時間ウィンドウをスライドして時間的パターンを定量化するウィンドウ内で測定された統計値を返します。For example, if a user wants to detect temporary anomalously high number of visit to a system, tracking the number of visits in sliding window is an effective approach.
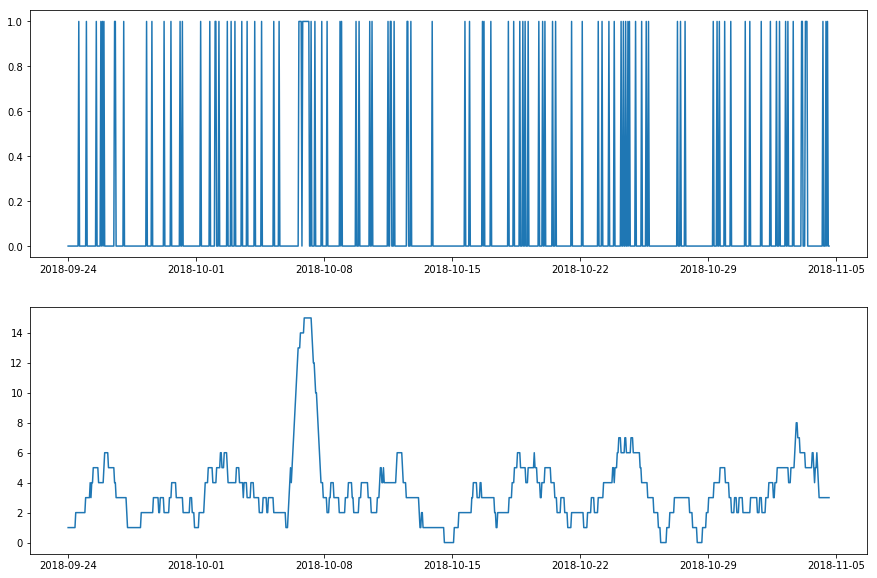
Transform a time series with temporary high frequency of requests using RollingAggregate with number of non-zeros values as metric.
4. 季節性 (= Seasonality、周期性)
時系列が季節的因子 (日の時間、週の日、年の月) により影響されるとき季節的パターンが存在します。detector adtk.detector.SeasonalAD は元の時系列から季節的パターンを除去するために transformer adtk.transformer.ClassicSeasonalDecomposition を使用し、そして時系列が (残差系列を検査することにより) 季節的パターンに正常に従わないとき時間周期 (= time period) をハイライトします。
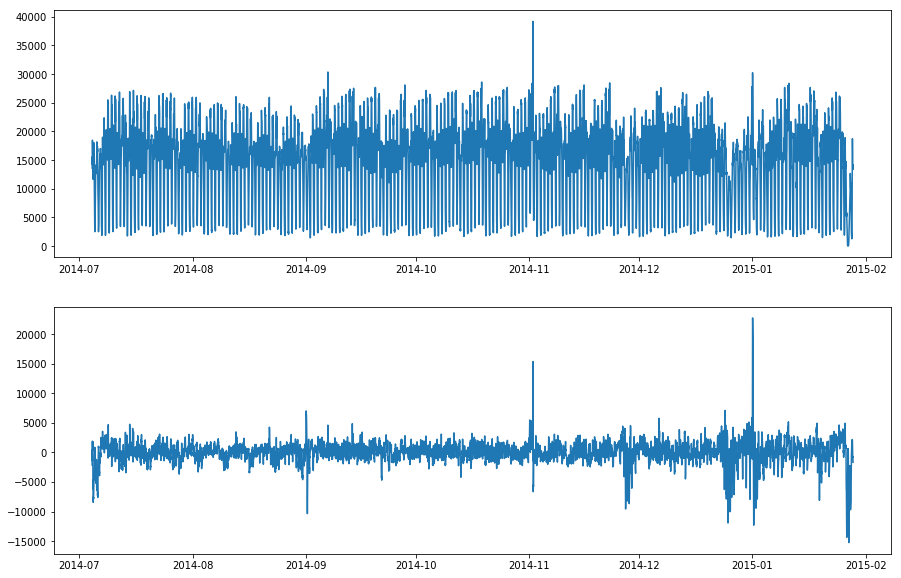
Remove the seasonal pattern from time series of NYC traffic using ClassicSeasonalDecomposition with the period as a week (data from Numenta Anomaly Benchmark)
ユーザは seasonal 系列と cyclic 系列を識別することについて注意深くある必要があります。seasonal 系列は常に固定された、通常は解釈可能で既知の、期間 (= period) を持ちます、その seasonal 性質故にです。cyclic 時系列は固定された periodic パターンには従いません、その物理的性質故に、それが同様の部分系列を繰り返しているように見えてさえもです。For example, the trajectory (軌道) of a moving part in rotating equipment is a 3-D cyclic time series, whose cycle length depends on rotation speed and is not necessarily fixed. Applying seasonality decomposition to it would be problematic, because every cycle may last a slightly different length, and decomposition residuals will be misleading for anomaly detection purpose.
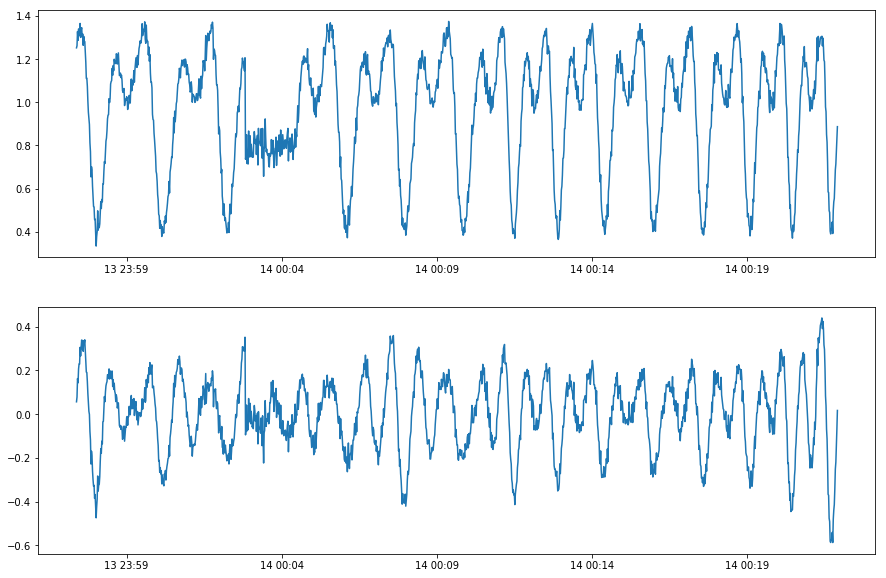
Applying ClassicSeasonalDecomposition to a cyclic series fails to detect anomalous behavior.
現在、ADTK は cyclic (but not seasonal) 時系列から cyclic パターンを除去する transformer を提供していません。However, adtk.detector.AutoregressionAD can capture changes of autoregressive relationship (the relationship between a data point and points in its near past) and could be used for cyclic (but not seasonal) series in some situations.
単変量 vs 多変量 (Univariate vs. Multivariate)
そこから異常を検知する時系列が単変量である場合、異常検知モデルは adtk.transformer の単変量 transformers と adtk.detector の単変量 detector を利用するべきです。
時系列が多変量である場合には、ユーザは系列に渡り異常検知タスクが分離可能であるか否かを理解するべきです。多くの場合、各系列に沿って並列に異常を検知することは要求を満たします。例えば、ユーザが 2 次元時系列、気温と湿度、を持ち、そして異常な気温か湿度を検知しようとする場合、気温と湿度の両者にそれぞれ単変量 detector を適用してから結果を集計することは要求を満たします。ユーザの便利のために、単変量 detector か 単変量 transformer が多変量系列 (i.e. pandas DataFrame) に適用されるとき、それは総ての系列に自動的に適用されます。
時に、ユーザは本質的な (= intrinsic) 多変量アルゴリズムを利用する必要があります、検知する異常のタイプが別々の単一の次元で表されない場合です。前の例については、ユーザが異常な heat index (気温と湿度のハイブリッド metric) を検知しようとする場合、多変量 transformers と detectors が考慮されるべきです、何故ならば異常は気温と湿度に同時に基づいて検知されなければならないからです。
Detector, Transformer, Aggregator, そして Pipe
ADTK はモデルに結合されるべき 3 つのタイプのコンポーネントを提供します。detector は時系列をスキャンして異常な時間ポイントを返すコンポーネントです。それらは総てモジュール adtk.detector に含まれます。transformer は有用な情報が抽出されるように時系列を変換します。それはまた特徴エンジニアリング・コンポーネントとしても解釈できます。それらは総てモジュール adtk.transformer に含まれます。Aggregator は様々な検知結果 (異常リスト) を結合するコンポーネントです。それはアンサンブル・コンポーネントです。それらは総てモジュール adtk.aggregator に含まれます。
モデルは単一の detector か複数のコンポーネントの組合せです。組合せが sequential である場合、i.e. シーケンシャルに detector に接続された一つか幾つかの transformers、それは adtk.pipe.Pipeline オブジェクトにより接続できます。組合せがより複雑でシーケンシャルでない場合、それは adtk.pipe.Pipenet オブジェクトにより接続できます。adtk.detector の多くの detector は内部的には Pipeline or Pipenet オブジェクトとして実装されていますが、ユーザの便利のためにモジュール adtk.detector でリストされます。
まだ実装されていない任意のコンポーネントについて、ユーザはそれを関数として実装して関数を ADTK コンポーネントに変換するためにコンポーネント adtk.detector.CustomizedDetector1D, adtk.detector.CustomizedDetectorHD, adtk.transformer.CustomizedTransformer1D, adtk.transformer.CustomizedTransformerHD, or adtk.aggregator.CustomizedAggregator を利用しても良いです。それからそれは統一 API を持ちそして通常の ADTK コンポーネントとして利用できます (for example, to be connected with other components using Pipeline or Pipenet)。Users are always welcomed to contribute their algorithm into the package permanently. More information for contributors can be found in Contributing.
ユーザは ADTK コンポーネントのサンプルのために Examples を確認しても良いです。
以上
ADTK (異常検知ツールキット) 0.6 : クイックスタート
ADTK (異常検知ツールキット) 0.6 : クイックスタート (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 06/21/2021 (0.6.2)
* 本ページは、ADTK の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。
スケジュールは弊社 公式 Web サイト でご確認頂けます。
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
| 人工知能研究開発支援 | 人工知能研修サービス | テレワーク & オンライン授業を支援 |
| PoC(概念実証)を失敗させないための支援 (本支援はセミナーに参加しアンケートに回答した方を対象としています。) | ||
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |
ADTK (異常検知ツールキット) 0.6 : クイックスタート
このサンプルでは、周期的な (= seasonal) (weekly and daily) 交通量パターンの違反 (= violation) を検知するモデルを構築します。ここで使用されるデータは Numenta Anomaly ベンチマーク からの NYC タクシー交通データセットです。
1. 訓練のために時系列をロードして検証します。
training.csv
Datetime,Traffic 2014-07-01 00:00:00,10844 2014-07-01 00:30:00,8127 2014-07-01 01:00:00,6210 2014-07-01 01:30:00,4656 2014-07-01 02:00:00,3820 ... 2015-01-04 09:30:00,9284 2015-01-04 10:00:00,10955 2015-01-04 10:30:00,13348 2015-01-04 11:00:00,13517 2015-01-04 11:30:00,14443
>>> import pandas as pd
>>> s_train = pd.read_csv("./training.csv", index_col="Datetime", parse_dates=True, squeeze=True)
>>> from adtk.data import validate_series
>>> s_train = validate_series(s_train)
>>> print(s_train)
Time
2014-07-01 00:00:00 10844
2014-07-01 00:30:00 8127
2014-07-01 01:00:00 6210
2014-07-01 01:30:00 4656
2014-07-01 02:00:00 3820
...
2015-01-04 09:30:00 9284
2015-01-04 10:00:00 10955
2015-01-04 10:30:00 13348
2015-01-04 11:00:00 13517
2015-01-04 11:30:00 14443
Freq: 30T, Name: Traffic, Length: 9000, dtype: int64
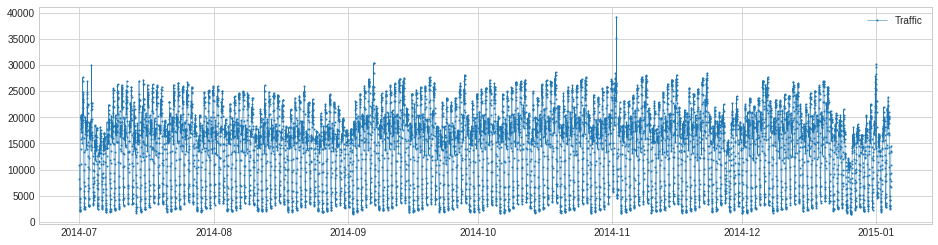
2. 訓練時系列を可視化する。
>>> from adtk.visualization import plot
>>> plot(s_train)
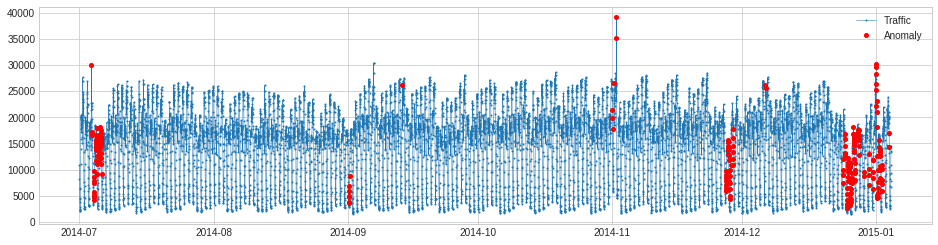
3. 周期パターンの violation を検知する。
>>> from adtk.detector import SeasonalAD
>>> seasonal_ad = SeasonalAD()
>>> anomalies = seasonal_ad.fit_detect(s_train)
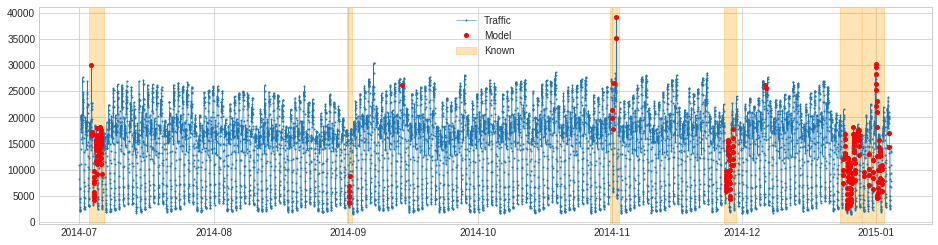
>>> plot(s_train, anomaly=anomalies, anomaly_color="red", anomaly_tag="marker")
4. 既知の異常が利用可能であれば、検知結果と交差チェックします。
known_anomalies.csv
Datetime,Anomaly 2014-07-01 00:00:00,0 2014-07-01 00:30:00,0 2014-07-01 01:00:00,0 2014-07-01 01:30:00,0 2014-07-01 02:00:00,0 ... 2015-01-04 09:30:00,0 2015-01-04 10:00:00,0 2015-01-04 10:30:00,0 2015-01-04 11:00:00,0 2015-01-04 11:30:00,0
>>> known_anomalies = pd.read_csv("./known_anomalies.csv", index_col="Datetime", parse_dates=True, squeeze=True)
>>> from adtk.data import to_events
>>> known_anomalies = to_events(known_anomalies)
>>> print(known_anomalies)
[(Timestamp('2014-07-03 07:00:00', freq='30T'),
Timestamp('2014-07-06 14:59:59.999999999', freq='30T')),
(Timestamp('2014-08-31 18:30:00', freq='30T'),
Timestamp('2014-09-01 21:59:59.999999999', freq='30T')),
(Timestamp('2014-10-31 14:30:00', freq='30T'),
Timestamp('2014-11-02 13:59:59.999999999', freq='30T')),
(Timestamp('2014-11-26 19:00:00', freq='30T'),
Timestamp('2014-11-29 14:29:59.999999999', freq='30T')),
(Timestamp('2014-12-23 19:00:00', freq='30T'),
Timestamp('2014-12-28 13:59:59.999999999', freq='30T')),
(Timestamp('2014-12-28 19:30:00', freq='30T'),
Timestamp('2015-01-02 21:29:59.999999999', freq='30T'))]
>>> plot(s_train,
anomaly={"Known": known_anomalies, "Model": anomalies},
anomaly_tag={"Known": "span", "Model": "marker"},
anomaly_color={"Known": "orange", "Model": "red"})
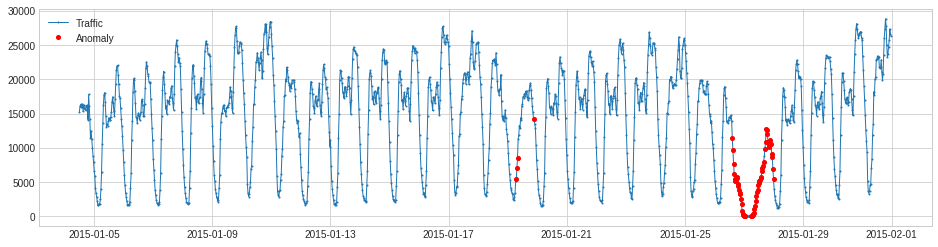
5. 新しいデータに訓練モデルを適用します。
>>> s_test = pd.read_csv("./testing.csv", index_col="Datetime", parse_dates=True, squeeze=True)
>>> s_test = validate_series(s_test)
>>> print(s_test)
Datetime
2015-01-04 12:00:00 15285
2015-01-04 12:30:00 16028
2015-01-04 13:00:00 16329
2015-01-04 13:30:00 15891
2015-01-04 14:00:00 15960
...
2015-01-31 21:30:00 24670
2015-01-31 22:00:00 25721
2015-01-31 22:30:00 27309
2015-01-31 23:00:00 26591
2015-01-31 23:30:00 26288
Freq: 30T, Name: Traffic, Length: 1320, dtype: int64
>>> anomalies_pred = seasonal_ad.detect(s_test)
>>> plot(s_test, anomaly=anomalies_pred,
ts_linewidth=1, anomaly_color='red', anomaly_tag="marker")
For more examples, please check Examples. But before that, we recommend you to read User Guide first.
以上
ADTK (異常検知ツールキット) 0.6 : 概要 (README)
ADTK (異常検知ツールキット) 0.6 : 概要 (README) (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 06/21/2021 (0.6.2)
* 本ページは、ADTK の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。
スケジュールは弊社 公式 Web サイト でご確認頂けます。
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
| 人工知能研究開発支援 | 人工知能研修サービス | テレワーク & オンライン授業を支援 |
| PoC(概念実証)を失敗させないための支援 (本支援はセミナーに参加しアンケートに回答した方を対象としています。) | ||
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |
ADTK (異常検知ツールキット) 0.6 : 概要 (README)
異常検知ツールキット (ADTK, Anomaly Detection Toolkit) は教師なし / ルールベースの時系列異常検知のための Python パッケージです。
異常の性質が異なるケースに渡り多様であるため、モデルは総ての異常検知問題のために普遍的に動作はしないかもしれません。検知アルゴリズム (detectors)、特徴エンジニアリング・メソッド (transformers) そしてアンサンブル・メソッド (aggregators) を選択して組み合わせることは効果的な異常検知モデルを構築するためのキーとなります。
このパッケージは統一された API で一般的な検知器、変換器と aggregators のセット、そしてそれらを一緒にモデルに接続する pipe クラスを提供します。それはまた時系列と異常イベントを処理して可視化するための幾つかの関数も提供します。
See https://adtk.readthedocs.io for complete documentation.
インストール
Prerequisites: Python 3.5 or later.
It is recommended to install the most recent stable release of ADTK from PyPI.
pip install adtk
Alternatively, you could install from source code. This will give you the latest, but unstable, version of ADTK.
git clone https://github.com/arundo/adtk.git
cd adtk/
git checkout develop
pip install ./
Examples
単純なサンプルのためには クイックスタート を見てください。
ADTK の各モジュールのより多くの詳細なサンプルについては、ドキュメントの Examples セクションか 対話的デモ・ノートブック を参照してください。
以上
ClassCat® Chatbot
人工知能開発支援
- テクニカルコンサルティングサービス
- 実証実験 (プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
クラスキャット
セールス・インフォメーション
E-Mail:sales-info@classcat.com