ホーム » Prophet
「Prophet」カテゴリーアーカイブ
Prophet 1.1 : 季節性、休日効果とリグレッサー
Prophet 1.1 : 季節性、休日効果とリグレッサー (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 08/31/2023 (1.1.4)
* 本ページは、Prophet の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。

- 人工知能研究開発支援
- 人工知能研修サービス(経営者層向けオンサイト研修)
- テクニカルコンサルティングサービス
- 実証実験(プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
- PoC(概念実証)を失敗させないための支援
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
- 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション
- sales-info@classcat.com ; Web: www.classcat.com ; ClassCatJP
Prophet 1.1 : 季節性、休日効果とリグレッサー
休日と特殊イベントのモデル化
モデル化したい休日や他の繰り返し発生する (循環性の, recurring) イベントを持つ場合、それらに対してデータフレームを作成しなければなりません。それは 2 つのカラム (holiday と ds) と休日の各々の発生のに対して行を持ちます。それは過去 (後方に履歴データがある限り) と未来 (予測が行なわれている限り) の両者の、休日の総ての発生を含まなければなりません、それらが未来に繰り返されない場合、Prophet はそれらをモデル化して予測ではそれらを含めません。
カラムに lower_window と upper_window を含めることもできます、これらは休日を日付周りの [lower_window, upper_window] days に拡張します。例えば、クリスマスに加えてクリスマス・イブを含めることを望んだ場合、lower_window=-1,upper_window=0 を含めます。感謝祭に加えてブラックフライデーを使用したい場合には、lower_window=0,upper_window=1 を含めます。下で説明されるように、各休日のために prior scale を個別に設定するためにカラム prior_scale を含めることもできます。
ここでは Peyton Manning のプレーオフ出場の総ての日付を含むデータフレームを作成します :
playoffs = pd.DataFrame({
'holiday': 'playoff',
'ds': pd.to_datetime(['2008-01-13', '2009-01-03', '2010-01-16',
'2010-01-24', '2010-02-07', '2011-01-08',
'2013-01-12', '2014-01-12', '2014-01-19',
'2014-02-02', '2015-01-11', '2016-01-17',
'2016-01-24', '2016-02-07']),
'lower_window': 0,
'upper_window': 1,
})
superbowls = pd.DataFrame({
'holiday': 'superbowl',
'ds': pd.to_datetime(['2010-02-07', '2014-02-02', '2016-02-07']),
'lower_window': 0,
'upper_window': 1,
})
holidays = pd.concat((playoffs, superbowls))
上記ではスーパーボウル days をプレーオフゲームとスーパーボウルゲームの両方として含めました。これは、スパーボウル効果はプレーオフ効果の上に追加の加算的ボーナスであることを意味します。
ひとたびテーブルが作成されれば、休日効果はそれらを holidays 引数で渡すことにより予測に含まれます。ここでは クイックスタート からの Peyton Manning データでそれを行ないます :
m = Prophet(holidays=holidays)
forecast = m.fit(df).predict(future)
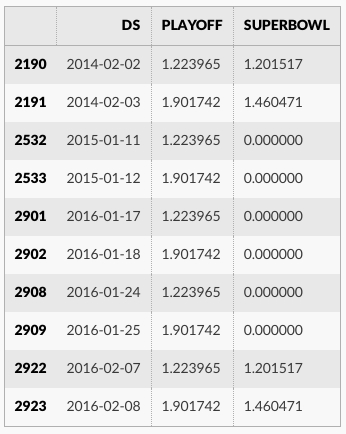
休日効果は予測データフレーム内で見ることができます :
forecast[(forecast['playoff'] + forecast['superbowl']).abs() > 0][
['ds', 'playoff', 'superbowl']][-10:]
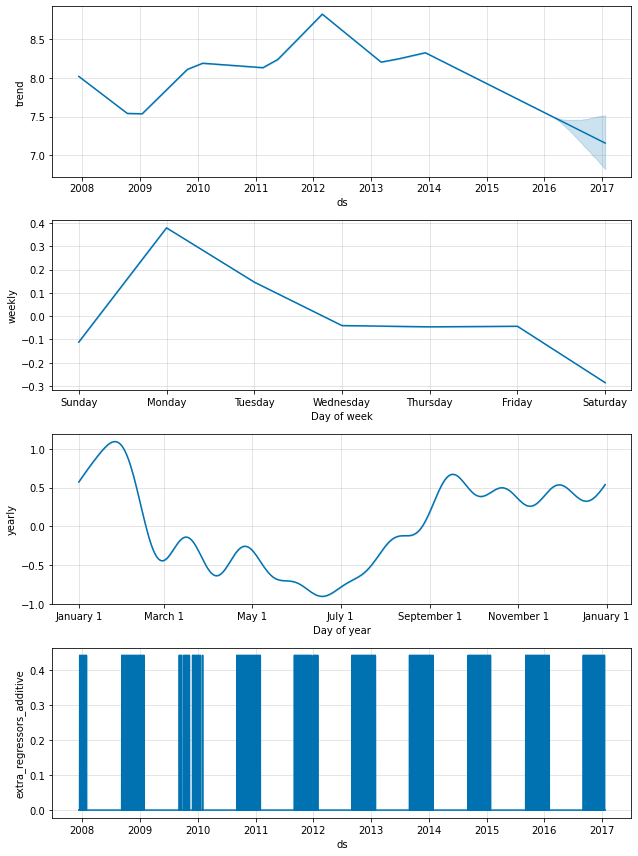
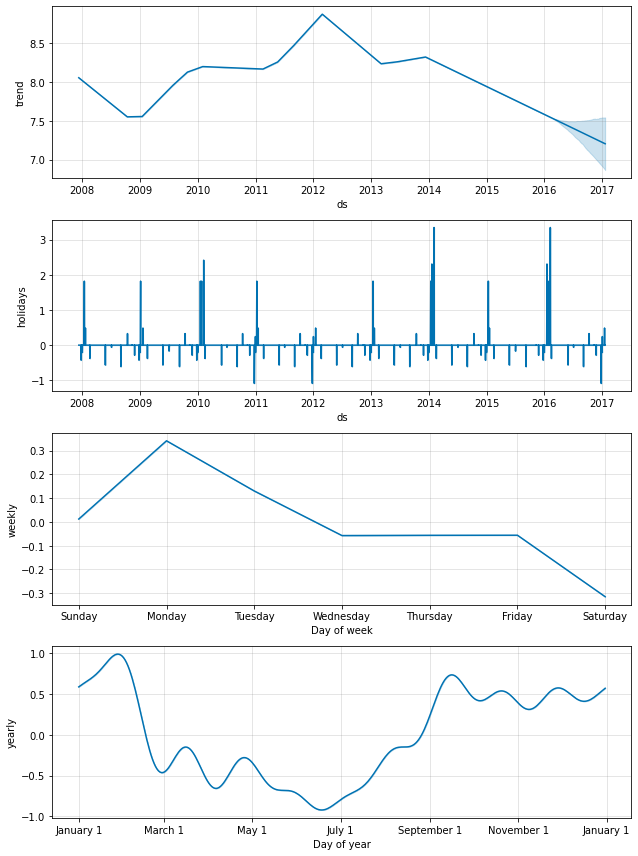
休日効果はまた成分プロット内にも現れます、そこではプレーオフ出場周りの日々でスパイクがあり、スーパーボウルに対しては特に巨大なスパイクがあります :
fig = m.plot_components(forecast)
スーパボウル休日成分だけをプロットする plot_forecast_component(m, forecast, ‘superbowl’) のように、(Python で prophet.plot からインポートされる) plot_forecast_component 関数を使用して個々の休日をプロットできます。
組込みの国の休日
add_country_holidays メソッド (Python) や関数 (R) を使用して国固有の休日の組込みコレクションを使用できます。国の名前が指定されると、上述の holidays 引数を通して指定された任意の休日に加えて、その国のための主要な休日が含まれます :
m = Prophet(holidays=holidays)
m.add_country_holidays(country_name='US')
m.fit(df)
モデルの train_holiday_names (Python) か train.holiday.names (R) 属性を見ることによりどの休日が含まれたかを見ることができます :
m.train_holiday_names
0 playoff 1 superbowl 2 New Year's Day 3 Martin Luther King Jr. Day 4 Washington's Birthday 5 Memorial Day 6 Independence Day 7 Labor Day 8 Columbus Day 9 Veterans Day 10 Thanksgiving 11 Christmas Day 12 Christmas Day (Observed) 13 Veterans Day (Observed) 14 Independence Day (Observed) 15 New Year's Day (Observed) dtype: object
各国のための休日は Python の holidays パッケージにより提供されます。利用可能な国のリストと使用する国名はページ : https://github.com/dr-prodigy/python-holidays で利用可能です。それらの国に加えて、Prophet はこれらの国のための休日を含みます : ブラジル (BR), インドネシア (ID), インド (IN), マレーシア (MY), ベトナム (VN), タイ (TH), フィリッピン (PH), パキスタン (PK), バングラディシュ (BD), エジプト (EG), 中国 (CN), そしてロシア (RU), 韓国 (KR), ベラルーシ (BY), そしてアラブ首長国連邦 (AE) です。
※ 訳注 : 日本 (JP) (08/31/2023 : 以前に使用可能であった JPN は削除されたようです。)
Python では、殆どの休日は決定論的に計算されますので任意の日付範囲で利用可能です ; 日付がその国でサポートされる範囲に入らない場合、警告が上げられます。R では、休日の日付は 1995 年から 2044 年まで計算されて data-raw/generated_holidays.csv としてパッケージにストアされています。より広い日付範囲が必要であれば、このスクリプトがそのファイルを異なる日付範囲と置き換えるために使用できます : https://github.com/facebook/prophet/blob/main/python/scripts/generate_holidays_file.py 。
上記のように、国レベルの休日は成分プロットで現れます :
forecast = m.predict(future)
fig = m.plot_components(forecast)
季節性のフーリエ次数
季節性は部分フーリエ和を使用して推定されます。完全な詳細は 論文 を、そして部分フーリエ和がどのように任意の周期信号を近似できるかの例示については Wikipedia のこの図 を見てください。部分和の項の数 (次数) はどのくらい素早く季節性が変化するかを決定するパラメータです。これを説明するために、クイックスタート からの Peyton Manning データを考えます。yearly 季節性のためのデフォルトのフーリエ次数は 10 で、これはこの適合を生成します :
from prophet.plot import plot_yearly
m = Prophet().fit(df)
a = plot_yearly(m)
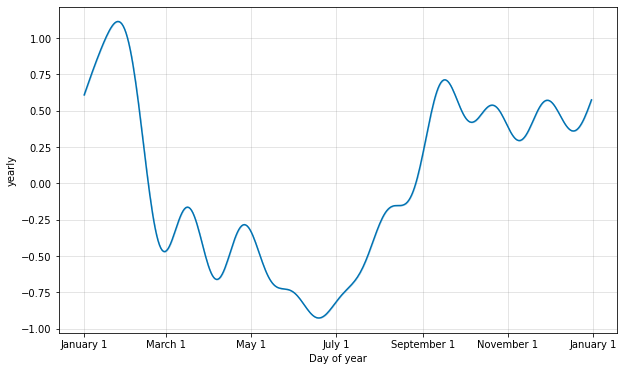
デフォルト値は適切である場合が多いですが、季節性がより高い頻度の変化に適合する必要があるとき、それらは増やすことができます、そして一般に滑らかでなくなります。フーリエ次数はモデルをインスタンス化するとき各組込みの季節性のために指定できます、ここではそれは 20 に増やされています :
from prophet.plot import plot_yearly
m = Prophet(yearly_seasonality=20).fit(df)
a = plot_yearly(m)
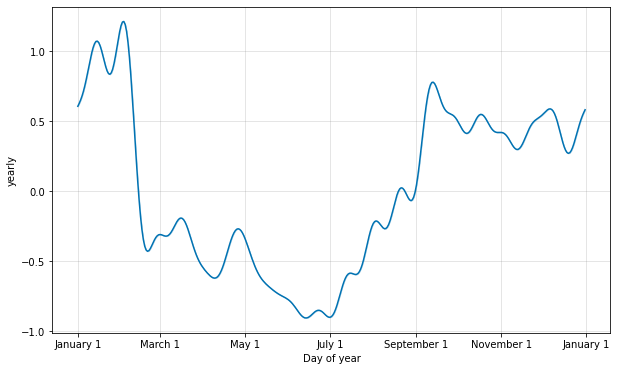
フーリエ項の数を増やすことは季節性を高速に変化するサイクルに適合させることを可能にしますが、過剰適合に繋がる可能性もあります : N 個のフーリエ項はサイクルをモデル化するために使用される 2N 変数に相当します。
カスタム季節性を指定する
Prophet は時系列が 2 つのサイクル長を越える場合、デフォルトで weekly と yearly の季節性に適合させます。それはまた部分的な daily 時系列のために daily の季節性にも適合させます。add_seasonality メソッド (Python) or 関数 (R) を使用して他の季節性 (monthly, quarterly, hourly) を追加することができます。
この関数への入力は名前、季節性の期間 (period) (in days)、そして季節性のためのフーリエ次数です。参考までに、デフォルトでは Prophet は weekly 季節性のために 3 のフーリエ次数をそして yearly 季節性のために 10 を使用します。add_seasonality へのオプションの入力はその季節性成分のための prior scale です – これは下で議論されます。
例として、ここでは クイックスタート から Peyton Manning データを適合させますが、weekly 季節性を monthly 季節性で置き換えます。そして monthly 季節性は成分プロットに現れます :
m = Prophet(weekly_seasonality=False)
m.add_seasonality(name='monthly', period=30.5, fourier_order=5)
forecast = m.fit(df).predict(future)
fig = m.plot_components(forecast)
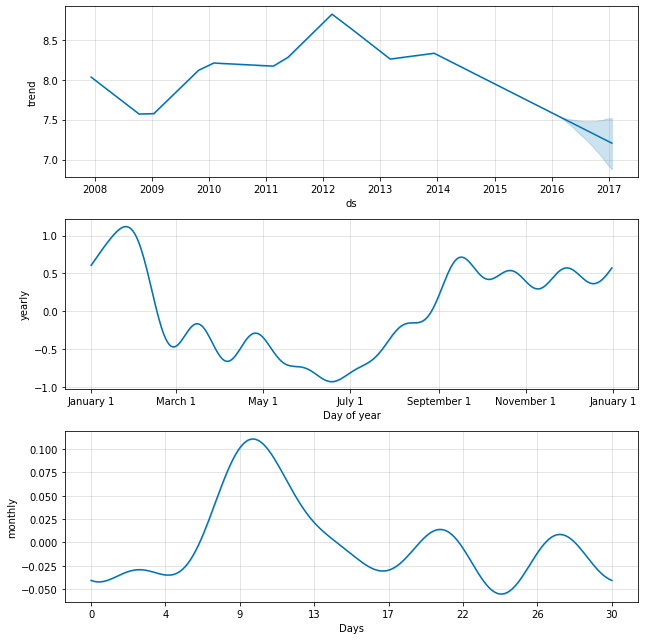
他の要因に依存する季節性
ある場合には、夏の間は年の残りの間とは異なるような weekly 季節パターンや、週末 vs 平日で異なるような daily 季節パターンのように、季節性は他の要因に依存するかもしれません。これらのタイプの季節性は条件付き季節性を使用してモデル化できます。
クイックスタート からの Peyton Manning サンプルを考えます。デフォルトの weekly 季節性は、weekly 季節性のパターンが一年を通して同じであることを仮定していますが、(毎日曜日に試合がある) オンシーズン中とオフシーズンの間では weekly 季節性のパターンが異なることを私たちは予想します。個別のオンシーズンとオフシーズンの weekly 季節性を構築するために条件付き季節性を使用できます。
最初にデータフレームにブーリアン・カラムを追加します、これは各日付がオンシーズンかオフシーズンにあるかを示します :
def is_nfl_season(ds):
date = pd.to_datetime(ds)
return (date.month > 8 or date.month < 2)
df['on_season'] = df['ds'].apply(is_nfl_season)
df['off_season'] = ~df['ds'].apply(is_nfl_season)
そして組込みの weekly 季節性を無効にして、それを、条件として指定されたこれらのカラムを持つ 2 つの weekly 季節性で置き換えます。これは、季節性は condition_name カラムが True である日付にだけ適用されることを意味します。また (そのために) 予測を行なう future データフレームにカラムを追加しなければなりません。
m = Prophet(weekly_seasonality=False)
m.add_seasonality(name='weekly_on_season', period=7, fourier_order=3, condition_name='on_season')
m.add_seasonality(name='weekly_off_season', period=7, fourier_order=3, condition_name='off_season')
future['on_season'] = future['ds'].apply(is_nfl_season)
future['off_season'] = ~future['ds'].apply(is_nfl_season)
forecast = m.fit(df).predict(future)
fig = m.plot_components(forecast)
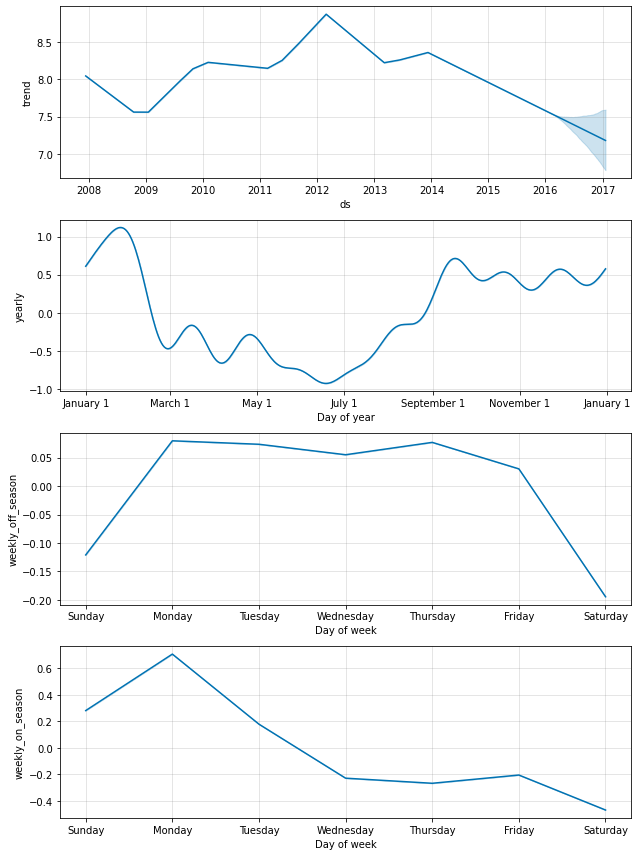
両方の季節性が今では上記の成分プロットに現れます。ゲームが毎土曜日にプレーされるオンシーズンの間、日曜日と月曜日に大規模な増加があることが見れますが、オフシーズンの間にはまったくありません。
休日と季節性のための Prior (事前) スケール
休日が過剰適合していることを見つける場合、パラメータ holidays_prior_scale を使用してそれらを滑らかにするために prior スケールを調整できます。デフォルトではこのパラメータは 10 で、それは正則化を殆ど提供しません。このパラメータを減少させると休日効果を減衰させます :
m = Prophet(holidays=holidays, holidays_prior_scale=0.05).fit(df)
forecast = m.predict(future)
forecast[(forecast['playoff'] + forecast['superbowl']).abs() > 0][
['ds', 'playoff', 'superbowl']][-10:]
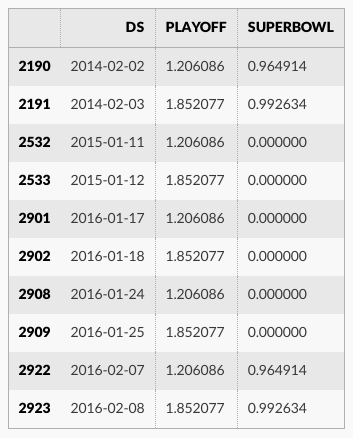
休日効果の大きさは前に比べて減少しています、特にスーパーボウルについて、これは最も少ない観測を持ちました。季節性モデルがデータに適合する範囲を同様に調整するパラメータ seasonality_prior_scale があります。
prior スケールは、holidays データフレーム内にカラム prior_scale を含めることにより個々の休日のために個別に設定できます。個々の季節性のための prior スケールは add_seasonality への引数として渡すことができます。例えば、weekly 季節性のためだけの prior スケールは次を使用して設定できます :
m = Prophet()
m.add_seasonality(
name='weekly', period=7, fourier_order=3, prior_scale=0.1)
追加のリグレッサー
add_regressor メソッドか関数を使用して追加のリグレッサーがモデルの線形部分に追加できます。regressor 値を持つカラムは fitting と prediction データフレームの両方で存在する必要があります。例えば、NFL シーズンの間の日曜日に追加の効果を追加することができます。成分プロットでは、この効果は ‘extra_regressors’ プロットに現れます :
def nfl_sunday(ds):
date = pd.to_datetime(ds)
if date.weekday() == 6 and (date.month > 8 or date.month < 2):
return 1
else:
return 0
df['nfl_sunday'] = df['ds'].apply(nfl_sunday)
m = Prophet()
m.add_regressor('nfl_sunday')
m.fit(df)
future['nfl_sunday'] = future['ds'].apply(nfl_sunday)
forecast = m.predict(future)
fig = m.plot_components(forecast)
NFL サンデーはまた過去と未来の NFL サンデーのリストを作成して、上述の “holidays” インターフェイスを使用して処理されました。add_regressor 関数は追加の (= extra) 線形リグレッサーを定義するためにより一般的なインターフェイスを提供し、そして特にリグレッサーは二値インジケーターであることを必要としません。別の時系列をリグレッサーとして使用できるでしょうが、その future 値は知られなければなりません。
このノートブック は自転車 (bicycle) の使用量の予測において追加のリグレッサーとして天気要因を使用する例を示し、そして他の時系列が追加のリグレッサーとして含まれる方法の優れた例を提供します。
add_regressor 関数は prior スケール (デフォルトでは holiday prior スケールが使用されます) とリグレッサーが標準化されているか否かを指定するためのオプション引数を持ちます - Python の help(Prophet.add_regressor) そして R の ?add_regressor で docstring を見てください。リグレッサーはモデル適合の前に追加されなければならないことに注意してください。Prophet はまたリグレッサーが履歴を通して定数である場合にはエラーを上げます、何故ならばそれから適合するものがないからです。
追加のリグレッサーは履歴と未来の日付の両方のために知られなければなりません。従ってそれは (nfl_sunday のように) 未来の値を知っているものか、あるいは他で別に予測された何かでなければなりません。上でリンクされたノートブックで使用される天気リグレッサーは未来値のために使用できる予測を持つ追加のリグレッサーの良いサンプルです。Prophet のような時系列モデルで予測された別の時系列をリグレッサーとして使用することもできます。例えば、r(t) が y(t) のためのリグレッサーとして含まれる場合、Prophet は r(t) を予測するために使用できてそしてその予測は y(t) を予測するとき未来値としてプラグインできます。このアプローチまわりの注意点は : これは r(t) が y(t) を予測するのが幾分容易でない限りは多分役立ちません。これは r(t) の予測誤差が y(t) の予測で誤差を生成するからです。これが有用であり得る一つの設定は階層型時系列内です、そこでは高い信号対雑音 (= signal-to-noise) を持ち予測が容易なトップレベルの予測があります。その予測は各下位レベルの系列のための予測に含めることができます。
追加のリグレッサーはモデルの線形成分に配置されますので、基礎的なモデルは、加法 or 乗法要因のいずれかとして時系列が追加のリグレッサーに依存します (乗法のためには次のセクション参照)。
追加のリグレッサーの係数
追加のリグレッサーの beta 係数を抽出するため、適合されたモデル上でユティリティ関数 regressor_coefficients を使用します (Python では from prophet.utilities import regressor_coefficients, R では prophet::regressor_coefficients)。各リグレッサーのための推定された beta 係数はリグレッサー値の単位増加に対する予測値の増加をおおよそ表します (返される係数は常に元のデータのスケールであることに注意してください)。mcmc_samples が指定される場合、各係数の信用区間 (= credible interval) も返されます、これは各レグレッサーが「統計的に有意である」かを識別するのに役立ちます。
以上
Prophet 1.1 : クイックスタート
Prophet 1.1 : クイックスタート (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 08/29/2023 (1.1.4)
* 本ページは、Prophet の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。
- 人工知能研究開発支援
- 人工知能研修サービス(経営者層向けオンサイト研修)
- テクニカルコンサルティングサービス
- 実証実験(プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
- PoC(概念実証)を失敗させないための支援
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
- 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション
- sales-info@classcat.com ; Web: www.classcat.com ; ClassCatJP
Prophet 1.1 : クイックスタート
Python API
Prophet は sklearn モデル API に従います。Prophet クラスのインスタンスを作成してからその fit と predict メソッドを呼び出します。
Prophet への入力は常に 2 つのカラム : ds と y を含むデータフレームです。ds (datestamp) カラムは Pandas により想定される形式である必要があり、理想的には日付のための YYYY-MM-DD またはタイムスタンプのための YYYY-MM-DD HH:MM:SS です。y カラムは数値でなければなりません、そして予測したい測定値を表します。
例として、 Peyton Manning のための Wikipedia ページのログの daily ページビューの時系列を見てみましょう。このデータを R の Wikipediatrend パッケージを使用してかき集めました (scraped)。Peyton Manning は良いサンプルを提供します、何故ならばそれは複数の季節性 (= seasonality)、成長率の変化、そして (Manning のプレーオフとスーパーボウルの出現のような) 特別な日をモデル化する機能のような Prophet の機能の幾つかを例示するからです。CSV は ここ で利用可能です。
最初にデータをインポートします :
import pandas as pd
from prophet import Prophet
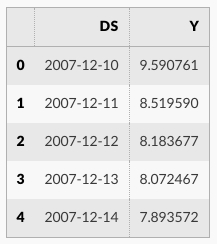
df = pd.read_csv('https://raw.githubusercontent.com/facebook/prophet/main/examples/example_wp_log_peyton_manning.csv')
df.head()
df.tail()
df.count()
ds 2905 y 2905 dtype: int64
新しい Prophet オブジェクトをインスタンス化することによりモデルを適合させます。予測手続きへの任意の設定はコンストラクタに渡されます。そしてその fit メソッドを呼び出して履歴データフレームを渡します。フィッティングには 1-5 秒かかるはずです。
m = Prophet()
m.fit(df)
そして予測は (そのために予測が行われる) 日付を含むカラム ds を持つデータフレーム上で行なわれます。ヘルパーメソッド Prophet.make_future_dataframe を使用して指定された日数だけ future 内に拡張した適切なデータフレームを得ることができます。デフォルトではそれは履歴からの日付も含みますので、モデルの適合も分かります。
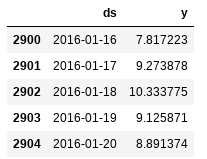
future = m.make_future_dataframe(periods=365)
future.tail()
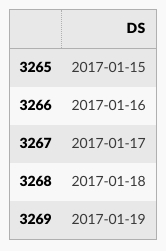
predict メソッドは future の各行に予測された値を割当てます、それは yhat と名前付けられます。履歴日付を渡す場合、それは in-sample な適合を提供します。ここで forecast オブジェクトは新しいデータフレームで、それは予測を持つカラム yhat と、成分と不確定区間のためのカラムを含みます。
forecast = m.predict(future)
forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].tail()
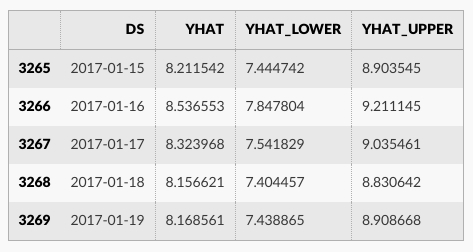
Prophet.plot メソッドを呼び出して forecast データフレームを渡すことにより予測をプロットできます。
fig1 = m.plot(forecast)
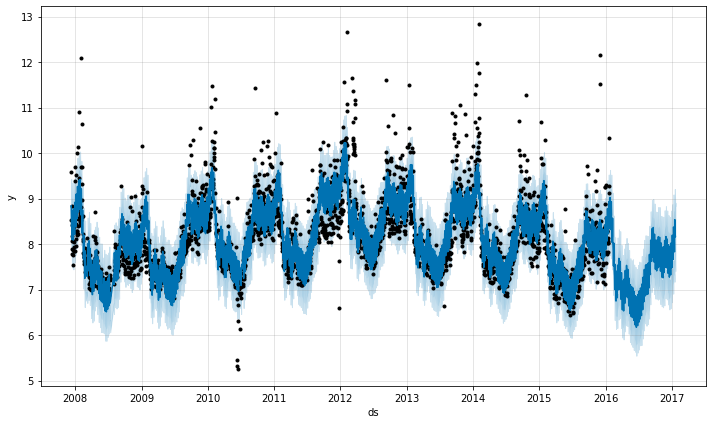
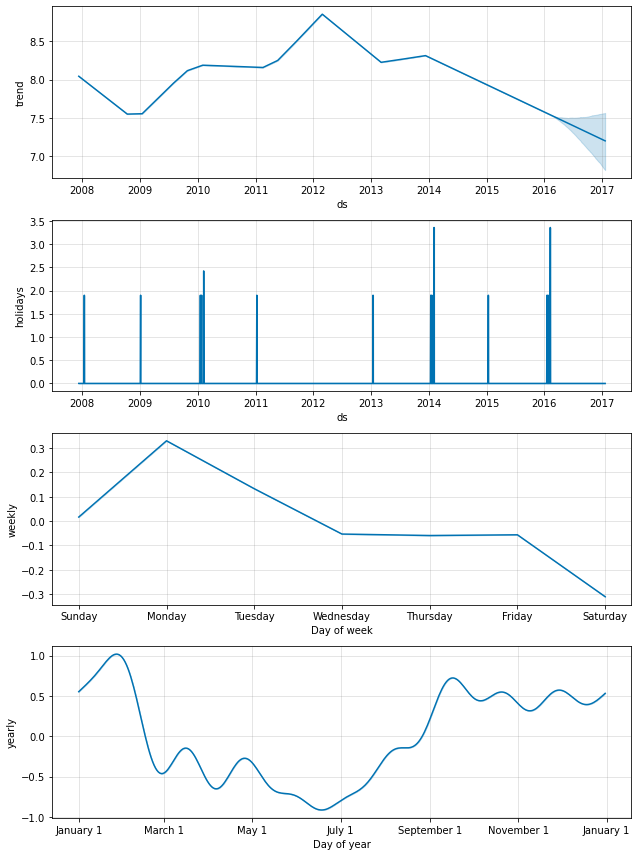
予測成分を見ることを望む場合、Prophet.plot_components メソッドを利用できます。デフォルトでは、時系列のトレンド、yearly 季節性と weekly 季節性を見ます。休日を含める場合、ここでそれらも見ます。
fig2 = m.plot_components(forecast)
予測と成分の対話的な図は plotly で作成できます。plotly 4.0 かそれ以上を個別にインストールする必要があります、それはデフォルトでは prophet と共にインストールされないからです。notebook と ipywidgets パッケージをインストールする必要もあります。
from prophet.plot import plot_plotly, plot_components_plotly
plot_plotly(m, forecast)
plot_components_plotly(m, forecast)
各メソッドのために利用可能なオプションについての詳細は docstrings で利用可能です、例えば help(Prophet) や help(Prophet.fit) を通してです。CRAN の R リファレンスマニュアル は利用可能な関数の総ての正確なリストを提供します、それらの各々は Python 同値を持ちます。
以上
Prophet 1.0 : 追加のトピック
Prophet 1.0 : 追加のトピック (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 07/16/2021 (1.0)
* 本ページは、Prophet の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。
スケジュールは弊社 公式 Web サイト でご確認頂けます。
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
| 人工知能研究開発支援 | 人工知能研修サービス | テレワーク & オンライン授業を支援 |
| PoC(概念実証)を失敗させないための支援 (本支援はセミナーに参加しアンケートに回答した方を対象としています。) | ||
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |

Prophet 1.0 : 追加のトピック
モデルをセーブする
適合された Prophet モデルを後でロードして利用できるようにセーブすることは可能です。
Python では、モデルは pickle でセーブされるべきではありません ; モデルオブジェクトに装着される Stan バックエンドは上手く pickle しません、そして Python の特定のバージョンで問題が発生します。代わりに、モデルを json にシリアライズする組込みのシリアリゼーション関数を使用するべきです :
import json
from prophet.serialize import model_to_json, model_from_json
with open('serialized_model.json', 'w') as fout:
json.dump(model_to_json(m), fout) # Save model
with open('serialized_model.json', 'r') as fin:
m = model_from_json(json.load(fin)) # Load model
json ファイルはシステム間で可搬で、デシリアリゼーションは prophet の古いバージョンと後方互換です。
フラットなトレンドとカスタムトレンド
トレンド変化よりも強い季節性パターンを示す時系列については、トレンド成長率をフラットに強制することは有用かもしれません。これはモデルを作成するとき単純に growth=flat を渡すことにより実現されます :
m = Prophet(growth='flat')
これが定数トレンドを持たない時系列で使用される場合、任意のトレンドはノイズ項で適合されて従って予測で高い予測不確実性があることに注意してください。
これらの 3 つの組込みトレンド関数 (piecewise linear, piecewise logistic growth と flat) 以外のトレンドを使用するために、github からソースコードをダウンロードして、ローカルブランチで要望どおりトレンド関数を変更し、それからそのローカルバージョンをインストールできます。この PR はカスタム・トレンドを実装するために成されなければならないものの良い例を提供します、これ は step 関数 trend をそして これ は R で新しいトレンドを実装するものです。
適合されたモデルを更新する
予測の一般的な設定はモデルを適合させます、これは追加のデータが入ってくるとき更新される必要があります。Prophet モデルは一度だけ適合させることが可能で、新しいデータが利用可能になるとき新しいモデルが再適合されなければなりません。殆どの設定では、モデル適合はスクラッチから再適合することによるどのような問題もないほど十分に高速です。けれども、先のモデルのモデルパラメータから適合をウォームアップすることにより少しスピードアップすることは可能です。このコードサンプルは Python でこれがどのように成されるかを示します :
def stan_init(m):
"""Retrieve parameters from a trained model.
Retrieve parameters from a trained model in the format
used to initialize a new Stan model.
Parameters
----------
m: A trained model of the Prophet class.
Returns
-------
A Dictionary containing retrieved parameters of m.
"""
res = {}
for pname in ['k', 'm', 'sigma_obs']:
res[pname] = m.params[pname][0][0]
for pname in ['delta', 'beta']:
res[pname] = m.params[pname][0]
return res
df = pd.read_csv('../examples/example_wp_log_peyton_manning.csv')
df1 = df.loc[df['ds'] < '2016-01-19', :] # All data except the last day
m1 = Prophet().fit(df1) # A model fit to all data except the last day
%timeit m2 = Prophet().fit(df) # Adding the last day, fitting from scratch
%timeit m2 = Prophet().fit(df, init=stan_init(m1)) # Adding the last day, warm-starting from m1
1.33 s ± 55.9 ms per loop (mean ± std. dev. of 7 runs, 1 loop each) 185 ms ± 4.46 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
ご覧のように、前のモデルからのパラメータが kwarg init で次の (モデルの) ための適合に渡されます。この場合、ウォームスタートを使用するときモデル適合はおよそ 5x 高速でした。スピードアップは新しいデータの追加で最適なモデルパラメータがどの程度変化したかに一般に依存します。
ウォームスタートを考えるとき留意するべき幾つかの注意があります。最初に、ウォームアップスタートは (上のサンプルに 1 日を追加するような) データへの小さい更新のために上手く機能しますが、データへの大きな変更がある場合 (i.e., 多くの日付が追加される場合) スクラッチから適合させるよりも悪い可能性があります。これは履歴の大きあ総量が追加されるとき、変化点の位置が 2 つのモデル間で非常に異なり、従って前のモデルからのパラメータは実際には悪いトレンド初期化を生成するかもしれないからです。2 番目に、詳細として、changepoints の数は一つのモデルから次のモデルへ一貫している必要があります、そうでなければエラーが上げられます、何故ならば changepoint prior パラメータ delta が誤ったサイズになるからです。
外部リファレンス
これらの github レポジトリは幅広い関心があるかもしれない方法で Prophet の上に構築するサンプルを提供します :
- forecastr : Prophet のための UI を提供する web app。
- NeuralProphet : pytorch で実装された Prophet スタイルのモデル、より適応可能で拡張可能です。
以上
Prophet 1.0 : 診断 (Diagnostics)
Prophet 1.0 : 診断 (Diagnostics) (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 07/15/2021 (1.0)
* 本ページは、Prophet の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。
スケジュールは弊社 公式 Web サイト でご確認頂けます。
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
| 人工知能研究開発支援 | 人工知能研修サービス | テレワーク & オンライン授業を支援 |
| PoC(概念実証)を失敗させないための支援 (本支援はセミナーに参加しアンケートに回答した方を対象としています。) | ||
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |
Prophet 1.0 : 診断 (Diagnostics)
交差検証
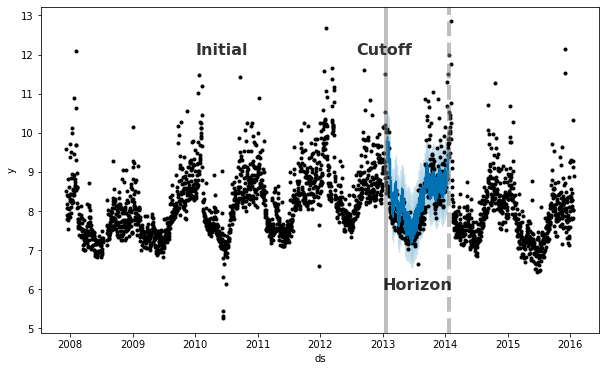
Prophet は履歴データを使用して予測誤差を測定するための時系列交差検証の機能を含みます。これは、履歴のカットオフポイントを選択し、それらの各々についてそのカットオフポイントまでのデータのみを使用してモデルを適合させることによって成されます。そして予測された値を実際の値と比較できます。この図は Peyton Manning データセット上のシミュレートされた履歴予測を示します、そこではモデルは 5 年の初期履歴に適合され、予測は 1 年の範囲で行なわれました。
Prophet 論文 はシミュレートされた履歴予測の更なる説明を与えます。
この交差検証手続きは cross_validation 関数を使用して履歴のカットオフの範囲のために自動的に成されます。予測範囲 (horizon)、それからオプションで初期訓練期間のサイズ (initial) とカットオフ日の間の間隔 (period) を指定します。デフォルトでは、initial 訓練期間は horizon の 3 倍に設定されて、カットオフは horizon の半分毎に行なわれます。
cross_validation の出力は各シミュレートされた予測日と各カットオフ日における真の値 y とサンプル外の予測値 yhat を持つデータフレームです。特に、予測はカットオフとカットオフ + horizon の間の総ての観測点のために行なわれます。そしてこのデータフレームは yhat vs. y の誤差測定値を計算するために使用されます。
ここでは 365 日の horizon の予測性能を評価するために交差検証を行ないます、最初のカットオフの 730 日の訓練データから始めて 180 日毎に予測を行ないます。この 8 年間の時系列では、これは合計 11 の予測に相当します。
from prophet.diagnostics import cross_validation
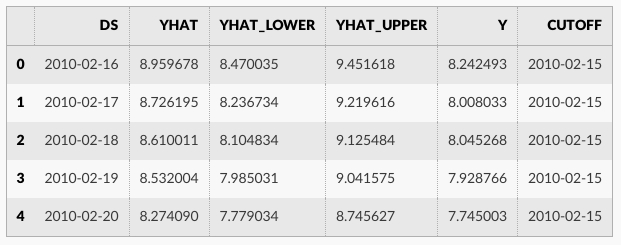
df_cv = cross_validation(m, initial='730 days', period='180 days', horizon = '365 days')
df_cv.head()
R では、引数 units は as.difftime により受け入れられるタイプでなければなりません、これは weeks か shorter です。Python では、initial, period と horizon のための文字列は Pandas Timedelta で使用される形式であるべきです、これは days or shorter の単位を受け取ります。
カスタム・カットオフは Python と R の cross_validation 関数の cutoffs キーワードへの日付のリストとして供給されることもできます。例えば、6 ヶ月間隔の 3 つのカットオフは次のような日付形式で cutoffs 引数に渡される必要があります :
cutoffs = pd.to_datetime(['2013-02-15', '2013-08-15', '2014-02-15'])
df_cv2 = cross_validation(m, cutoffs=cutoffs, horizon='365 days')
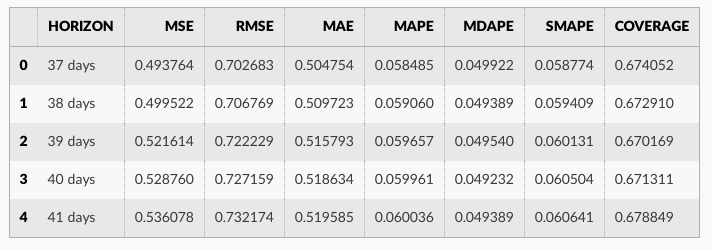
performance_metrics ユティリティはカットオフからの距離の関数として、予測性能の幾つかの有用な統計値を計算するために使用できます (yhat, yhat_lower と y に比較した yhat_upper )。計算される統計値は平均二乗誤差 (MSE)、二乗平均平方根誤差 (RMSE)、平均絶対誤差 (MAE)、平均絶対パーセント誤差 (MAPE)、中央値絶対パーセント誤差 (MDAPE)、そして yhat_lower と yhat_upper 範囲の推定値です。これらは horizon (ds minus カットオフ) によりソートされた後 df_cv の予測のローリング・ウィンドウ上で計算されます。デフォルトでは予測の 10% は各ウィンドウに含まれますが、これは rolling_window 引数で変更できます。
from prophet.diagnostics import performance_metrics
df_p = performance_metrics(df_cv)
df_p.head()
交差検証性能メトリクスは plot_cross_validation_metric で可視化できます、ここでは MAPE のために表示されます。ドットは df_cv の各予測のための絶対パーセント誤差を表します。青い線は MAPE を示し、そこでは平均はドットのローリング・ウィンドウに渡り取られます。この予測については、1ヶ月先への予測については 5% 前後の誤差が典型的で、1 年後の予測については誤差は 11% 前後にまで増加することがわかります。
from prophet.plot import plot_cross_validation_metric
fig = plot_cross_validation_metric(df_cv, metric='mape')
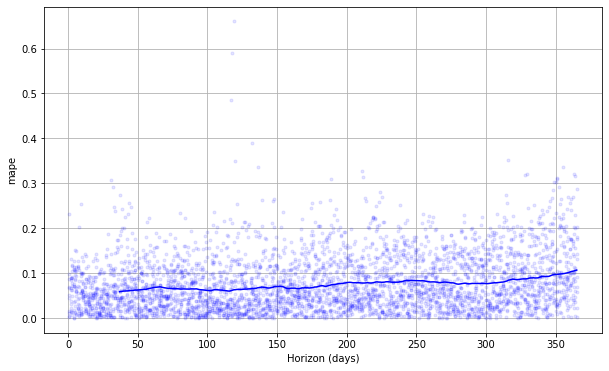
図のローリング・ウィンドウのサイズはオプション引数 rolling_window で変更できます、これは各ローリング・ウィンドウで使用する予測の比率を指定します。デフォルトは 0.1 で、各ウィンドウに含まれる df_cv からの行の 10% に相当し、これを増やすことは図での滑らかな平均カーブに繋がります。initial 期間は特に季節性と追加のリグレッサーでモデルの総ての成分を捕捉できるように十分に長くあるべきです : yearly 季節性のためには少なくとも 1 年、weekly 季節性のためには少なくとも 1 週間、等。
交差検証の並列化
交差検証は parallel キーワードの指定を設定することにより Python の並列モードで実行することもできます。4 つのモードがサポートされます :
- parallel=None (デフォルト, 並列化なし)
- parallel=”processes”
- parallel=”threads”
- parallel=”dask”
大きすぎない問題については、parallel=”processes” を使用することを勧めます。並列交差検証が単一マシン上で成されるときそれは最高の性能を達成します。大きな問題については、多くのマシン上で交差検証を行なうために Dask クラスタが使用されます。個別に Dask をインストール する必要があります、それは prophet と一緒にはインストールされないからです。
from dask.distributed import Client
client = Client() # connect to the cluster
df_cv = cross_validation(m, initial='730 days', period='180 days', horizon='365 days',
parallel="dask")
ハイパーパラメータ調整
changepoint_prior_scale と seasonality_prior_scale のような、モデルのハイパーパラメータを調整するために交差検証は利用できます。カットオフに渡る並列化、それら 2 つのパラメータの 4×4 グリッドによる、Python サンプルは下で与えられます。ここではパラメータは 30 日 horizon に渡り平均された RMSE で評価されますが、異なる性能メトリクスが異なる問題のために適切かもしれません。
# Python
import itertools
import numpy as np
import pandas as pd
param_grid = {
'changepoint_prior_scale': [0.001, 0.01, 0.1, 0.5],
'seasonality_prior_scale': [0.01, 0.1, 1.0, 10.0],
}
# Generate all combinations of parameters
all_params = [dict(zip(param_grid.keys(), v)) for v in itertools.product(*param_grid.values())]
rmses = [] # Store the RMSEs for each params here
# Use cross validation to evaluate all parameters
for params in all_params:
m = Prophet(**params).fit(df) # Fit model with given params
df_cv = cross_validation(m, cutoffs=cutoffs, horizon='30 days', parallel="processes")
df_p = performance_metrics(df_cv, rolling_window=1)
rmses.append(df_p['rmse'].values[0])
# Find the best parameters
tuning_results = pd.DataFrame(all_params)
tuning_results['rmse'] = rmses
print(tuning_results)
changepoint_prior_scale seasonality_prior_scale rmse
0 0.001 0.01 0.757694
1 0.001 0.10 0.743399
2 0.001 1.00 0.753387
3 0.001 10.00 0.762890
4 0.010 0.01 0.542315
5 0.010 0.10 0.535546
6 0.010 1.00 0.527008
7 0.010 10.00 0.541544
8 0.100 0.01 0.524835
9 0.100 0.10 0.516061
10 0.100 1.00 0.521406
11 0.100 10.00 0.518580
12 0.500 0.01 0.532140
13 0.500 0.10 0.524668
14 0.500 1.00 0.521130
15 0.500 10.00 0.522980
best_params = all_params[np.argmin(rmses)]
print(best_params)
{'changepoint_prior_scale': 0.1, 'seasonality_prior_scale': 0.1}
代わりに、上のループを並列化することによりパラメータの組合せについて並列化を行なうことができるでしょう。
Prophet モデルは調整を考えるかもしれない多くの入力パラメータを持ちます。ここに良い出発点であるかもしれないハイパーパラメータ調整のための幾つかの一般的な推奨があります。
調整可能なパラメータ
- changepoint_prior_scale : これは多分最も影響力のあるパラメータです。トレンドの柔軟性、特にトレンド変化点でどのくらいのトレンド変化があるかを決定します。このドキュメントで説明されているように、それが小さすぎれば、トレンドは過小適合になりそしてトレンド変化でモデル化されるべき分散は代わりにノイズ項で処理されることになります。それが大きすぎれば、トレンドは過剰適合となり最も極端な場合には yearly 季節性を捕捉するトレンドで終わる可能性があります。0.05 のデフォルトは多くの時系列のために動作しますが、これは調整できます ; [0.001, 0.5] の範囲がおそらく概ね適切です。このようなパラメータ (正則化ペナルティ ; これは実質的には lasso ペナルティです) はしばしば対数スケールで調整されます。
- seasonality_prior_scale : このパラメータは季節性の柔軟性を制御します。同様に、大きな値は季節性を大きな変動に適合させることを可能にし、小さい値は季節性の大きさを縮小します。デフォルトは 10. で、これは基本的には正則化を適用しません。これはここでは滅多に過剰適合を見ないからです (それは truncated フーリエ級数でモデル化されているという事実により固有の正則化はありますので、それは本質的には low-pass フィルタ処理されています)。それを調整するための合理的な範囲は多分 [0.01, 10] です ; 0.01 に設定するとき季節性の大きさが非常に小さくなるように強制されることを見出すはずです。これはまた対数スケール上でも意味がある傾向にあります、何故ならばそれはリッジ回帰のように実質的には L2 ペナルティであるからです。
- holidays_prior_scale : これは休日効果に適合させるための柔軟性を制御します。seasonality_prior_scale と同様に、それは 10.0 がデフォルトです、これは基本的には正則化を適用しません、何故ならば通常は休日の複数の観測を持ち上手く効果の推定を行えるからです。これは seasonality_prior_scale と同様に [0.01, 10] の範囲でも調整できます。
- seasonality_mode : オプションは [‘additive’, ‘multiplicative’] です。デフォルトは ‘additive’ ですが、多くのビジネス時系列は乗法的季節性を持ちます。これは時系列を単に見て、季節的変動の大きさが時系列の大きさとともに増大するかを見ることにより最善に識別されます (乗法的季節性についてはここのドキュメントを見てください) が、それが可能ではないとき、それは調整できるでしょう。
多分調整 (可能)?
- changepoint_range : これはトレンドが変化することが許容されている履歴の割合です。これは履歴の 0.8, 80% がデフォルトで、時系列の最後の 20% ではどのようなトレンド変化にもモデルが適合されないことを意味します。これはかなり保守的で、(上手く適合するために十分な走路が残されていない) 時系列の本当に最後でトレンド変化への過剰適合を回避するためです。ループで人間によれば、これは非常に容易に視覚的に識別できます : 最後の 20% で予測が上手くいかないかを非常に明瞭に見ることができます。完全自動設定では、保守性を低くすることは有益かもしれません。上で説明されたようにカットオフによる交差検証でこのパラメータを効果的に調整することは可能ではないかもしれません。時系列の最後の 10% のトレンド変化から一般化するモデルの能力は、最後の 10% でトレンド変化を持たないかもしれない先のカットオフを見ることから学習することは困難です。従って、このパラメータは多分調整されないことが良いです、大規模な数の時系列に渡る場合を多分除いて。その設定では、[0.8, 0.95] が妥当な範囲であるかもしれません。
調整されない傾向にあるパラメータ
- growth : オプションは ‘linear’ と ‘logistic’ です。これはおそらく調整されません ; 既知の飽和点とそのポイントに向けての成長がある場合、それは含まれて logistic トレンドが使用され、そうでなければそれは linear です。
- changepoints : これは変化点の位置を手動で指定するためのものです。デフォルトは None で、これはそれらを自動的に配置します。
- n_changepoints : これは自動的に配置された変化点の数です。25 のデフォルトは典型的な時系列でトレンド変化を捕捉するために十分であるはずです (少なくとも Prophet が上手く動作するタイプ)。変化点の数を増やしたり減らしたりするよりも、それらのトレンド変化で柔軟性を増やしたり減らしたりすることに焦点を当てることがより効果的かもしれません、これは changepoint_prior_scale で成されます。
- yearly_seasonality : デフォルト (‘auto’) では、これは年間データがあれば yearly 季節性をオンに、そうでなければオフにします。オプションは [‘auto’, True, False] です。1 年間以上のデータがあれば、HPO の間にこれをオフにしようとするよりも、それをオンのままにして、seasonality_prior_scale を調整して季節的効果を無効にすることがより効果的であるかもしれません。
- weekly_seasonality : yearly_seasonality と同じです。
- daily_seasonality : yearly_seasonality と同じです。
- holidays : これは指定された休日のデータフレームを渡すためです。休日効果は holidays_prior_scale で調整されます。
- mcmc_samples : MCMC が使用されるか否かは時系列の長さとパラメータ不確実性の重要度のような要因で決定される可能性があります (これらの考慮点はドキュメントで説明されます)。
- interval_width : Prophet は予測 yhat に対する yhat_lower と yhat_upper のように、各成分に対して不確定区間を返します。これらは事後予測分布の分位点として計算され、interval_width はどの分位点を使用するかを指定します。0.8 のデフォルトは 80% 予測区間を提供します。95% 区間を望む場合はそれを 0.95 に変更できます。これは不確定区間だけに影響し、そして予測 yhat は全く変更しませんので、調整される必要はありません。
- uncertainty_samples : 不確定区間は事後予測区間の分位点として計算され、事後予測区間は Monte Carlo サンプリングで推定されます。このパラメータは使用するサンプリングの数です (デフォルトは 1000)。予測のための実行時間はこの数で線形です。それを小さくすると不確定区間の分散 (Monte Carlo 誤差) を増加させ、大きくすればその分散を減じます。従って、不確実性推定がギザギザ (jagged) に見えるなら、それらを更に滑らかにするためにこれを増加できますが、変更される必要はないかもしれません。interval_width と同様に、このパラメータは不確定区間に影響を与えるだけで、それの変更は予測 yhat にはどのようにも影響しません ; それは調整される必要はありません。
- stan_backend : pystan と cmdstanpy の両者がセットアップされる場合、バックエンドが指定できます。予測は同じで、これは調整されません。
以上
Prophet 1.0 : 非日次データ
Prophet 1.0 : 非日次データ (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 07/14/2021 (1.0)
* 本ページは、Prophet の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。
スケジュールは弊社 公式 Web サイト でご確認頂けます。
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
| 人工知能研究開発支援 | 人工知能研修サービス | テレワーク & オンライン授業を支援 |
| PoC(概念実証)を失敗させないための支援 (本支援はセミナーに参加しアンケートに回答した方を対象としています。) | ||
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |
Prophet 1.0 : 非日次データ
Sub-daily データ
Prophet は ds カラムでタイムスタンプを持つデータフレームを渡すことにより sub-daily 観測をもつ時系列のために予測を行なうことができます。タイムスタンプの形式は YYYY-MM-DD HH:MM:SS であるべきです – ここ のサンプル csv を見てください。sub-daily データが使用されるとき、daily 季節性は自動的に適合されます。ここでは Prophet を 5 分解像度のデータに適合させます (Yosemite の daily 気温) :
df = pd.read_csv('../examples/example_yosemite_temps.csv')
m = Prophet(changepoint_prior_scale=0.01).fit(df)
future = m.make_future_dataframe(periods=300, freq='H')
fcst = m.predict(future)
fig = m.plot(fcst)
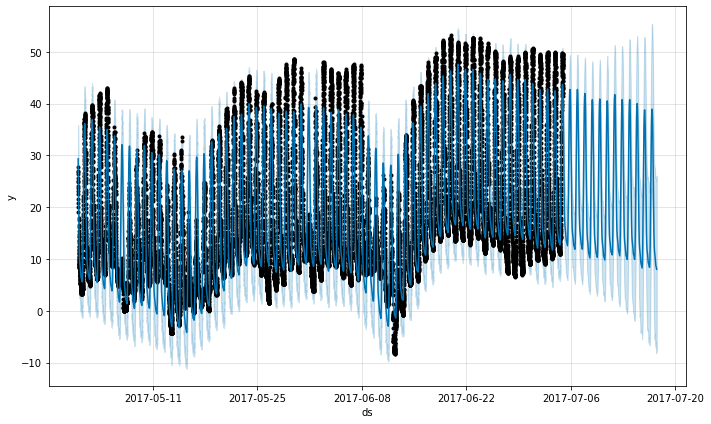
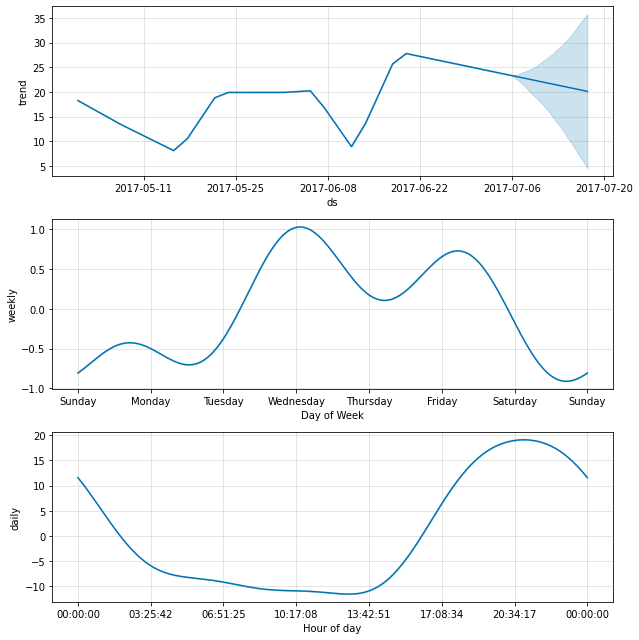
daily 季節性は成分プロットに現れます :
fig = m.plot_components(fcst)
規則的なギャップ (= regular gap) を持つデータ
上のデータセットは 12a から 6a までの観測だけを持ったと仮定します :
df2 = df.copy()
df2['ds'] = pd.to_datetime(df2['ds'])
df2 = df2[df2['ds'].dt.hour < 6]
m = Prophet().fit(df2)
future = m.make_future_dataframe(periods=300, freq='H')
fcst = m.predict(future)
fig = m.plot(fcst)
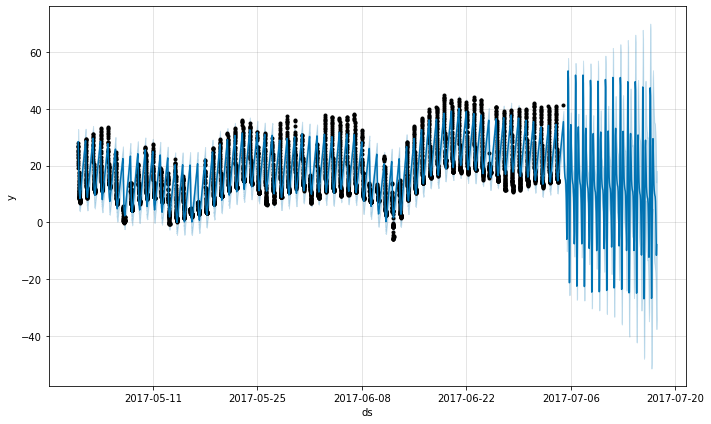
予測は非常に貧弱のようで、履歴で見られたものよりも未来は遥かに大きな上下動を持ちます。ここでの問題は 1 日の一部 (12a to 6a) のためのデータだけを持つ daily サイクルを時系列に適合させたことです。そのため daily 季節性は 1 日の残りのために制約されずに上手く推定されません。解法は履歴データがある時間帯のためだけに予測を行なうことです。ここでは、それは未来のデータフレームを 12a から 6a の時間に制限することを意味します。
future2 = future.copy()
future2 = future2[future2['ds'].dt.hour < 6]
fcst = m.predict(future2)
fig = m.plot(fcst)
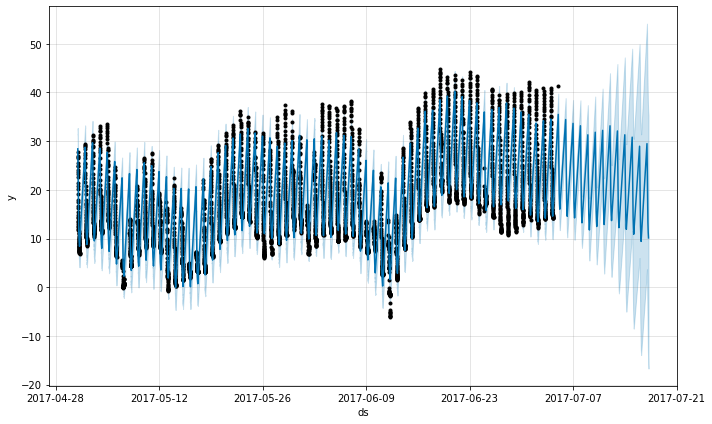
同じ原理はデータに規則的なギャップを持つ他のデータセットに適用されます。例えば、履歴が平日だけを含む場合、予測は平日のためだけに行なわれるべきです、何故ならば weekly 季節性は週末のためには上手く推定されないからです。
月次 (= Monthly) データ
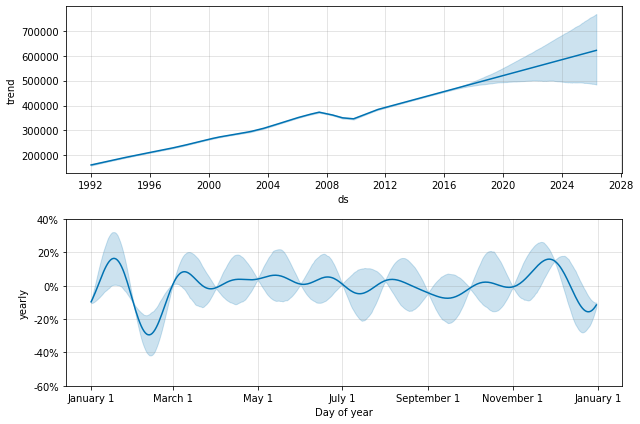
Prophet を月次データに適合させるために利用できます。けれども、基礎的なモデルは連続時間です、これはモデルを月次データに適合させて日次予測を求める場合、奇妙な結果を得る可能性があることを意味します。ここでは次の 10 年間の US 小売販売量を予測します :
df = pd.read_csv('../examples/example_retail_sales.csv')
m = Prophet(seasonality_mode='multiplicative').fit(df)
future = m.make_future_dataframe(periods=3652)
fcst = m.predict(future)
fig = m.plot(fcst)
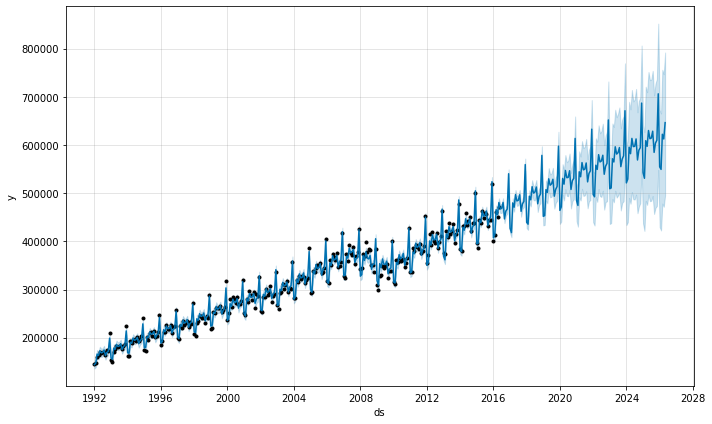
これはデータセットが定期的なギャップを持つ、上記と同じ問題です。yearly 季節性に適合させるとき、それは各月の最初のためのデータだけを持ち残りの日のための季節性成分は識別できずに過剰適合になります。これは季節性の不確実性を見るために MCMC を行なうことにより明瞭に見ることができます :
m = Prophet(seasonality_mode='multiplicative', mcmc_samples=300).fit(df)
fcst = m.predict(future)
fig = m.plot_components(fcst)
WARNING:pystan:481 of 600 iterations saturated the maximum tree depth of 10 (80.2 %) WARNING:pystan:Run again with max_treedepth larger than 10 to avoid saturation
季節性はデータポイントがある各月の最初では低い不確実性を持ちますが、その間は非常に高い事後分散を持ちます。Prophet を月次データに適合させるとき、月次予測だけを行ないます、これは頻度を make_future_dataframe に渡すことにより成されます :
future = m.make_future_dataframe(periods=120, freq='MS')
fcst = m.predict(future)
fig = m.plot(fcst)
Python では、頻度はここの頻度文字列の pandas リストからのどれでもかまいません : https://pandas.pydata.org/pandas-docs/stable/user_guide/timeseries.html#timeseries-offset-aliases 。ここで使用される MS は month-start であることに注意してください、データポイントが各月の最初に配置されることを意味します。
月次データでは、yearly 季節性は二値 extra リグレッサーでもモデル化できます。特に、モデルは is_jan, is_feb 等のような 12 個の extra リグレッサーを使用できます、ここで is_jan は日付が 1 月であれば 1 をそうでなければ 0 です。このアプローチは上で見られた月内の (= within-month) 識別不能性 (= unidentifiability) を回避するでしょう。月次 extra リグレッサーが追加される場合 yearly_seasonality=False を確実に使用してください。
集計データによる休日
休日効果は休日が指定された特定の日付に適用されます。weekly or monthly 頻度で集計されるデータでは、データで使用される特定の日付にはまらない休日は無視されます : 例えば、各データポイントが日曜日にある weekly 時系列の月曜日の休日です。モデルに休日効果を含めるには、休日は効果が望まれる履歴データフレームの日付に移動される必要があります。weekly or monthly 集計データでは、多くの休日効果は yearly 季節性で上手く捕捉されますので、追加された休日は時系列を通して異なる週に発生する休日のためだけに必要かもしれないことに注意してください。
以上
Prophet 1.0 : 外れ値
Prophet 1.0 : 外れ値 (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 07/13/2021 (1.0)
* 本ページは、Prophet の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。
スケジュールは弊社 公式 Web サイト でご確認頂けます。
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
| 人工知能研究開発支援 | 人工知能研修サービス | テレワーク & オンライン授業を支援 |
| PoC(概念実証)を失敗させないための支援 (本支援はセミナーに参加しアンケートに回答した方を対象としています。) | ||
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |
Prophet 1.0 : 外れ値
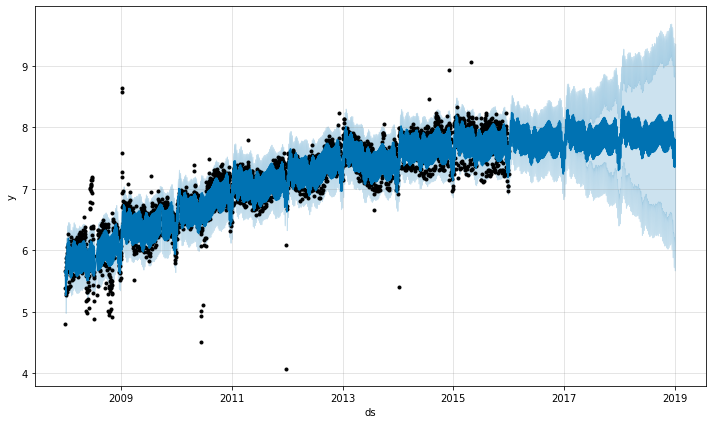
外れ値が Prophet の予測に影響を与えられる 2 つの主要な方法があります。ここでは前からの R ページへのログ記録された Wikipedia アクセスの予測を行ないますが、不良データのブロックを伴います。
df = pd.read_csv('../examples/example_wp_log_R_outliers1.csv')
m = Prophet()
m.fit(df)
future = m.make_future_dataframe(periods=1096)
forecast = m.predict(future)
fig = m.plot(forecast)
トレンド予測は合理的に見えますが、不確定区間は広すぎるようです。Prophet は履歴の外れ値を処理できますが、トレンド変化でそれらを適合させることによってのみです。そして不確実性モデルは同様の大きさの未来のトレンド変化を想定します。
外れ値を扱う最善の方法はそれらを除去することです – Prophet はデータが欠落しても問題ありません。履歴でそれらの値を NA に設定してしかし未来の日付はそのままにする場合、Prophet はそれらの値の予測を与えます。
df.loc[(df['ds'] > '2010-01-01') & (df['ds'] < '2011-01-01'), 'y'] = None
model = Prophet().fit(df)
fig = model.plot(model.predict(future))

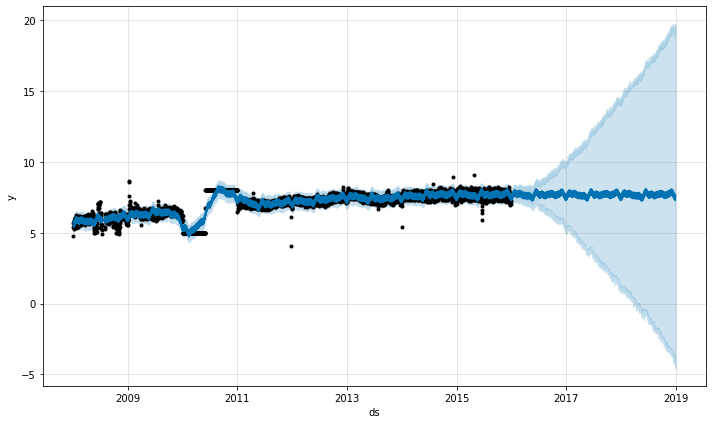
上の例では外れ値は不確実性推定を台無しにしましたが主要な予測 yhat には影響を与えませんでした。追加された外れ値をもつこの例でのように、これは常には当てはまりません :
df = pd.read_csv('../examples/example_wp_log_R_outliers2.csv')
m = Prophet()
m.fit(df)
future = m.make_future_dataframe(periods=1096)
forecast = m.predict(future)
fig = m.plot(forecast)
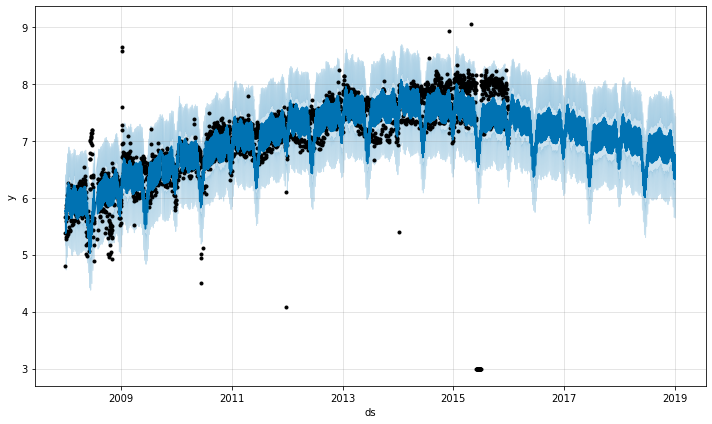
ここでは 2015年6月の極端な外れ値は季節性推定を台無しにしていますので、それらの効果は未来に永遠に響きます。再度、正しいアプローチはそれらを除去することです :
df.loc[(df['ds'] > '2015-06-01') & (df['ds'] < '2015-06-30'), 'y'] = None
m = Prophet().fit(df)
fig = m.plot(m.predict(future))
以上
Prophet 1.0 : 不確定区間
Prophet 1.0 : 不確定区間 (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 07/13/2021 (1.0)
* 本ページは、Prophet の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。
スケジュールは弊社 公式 Web サイト でご確認頂けます。
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
| 人工知能研究開発支援 | 人工知能研修サービス | テレワーク & オンライン授業を支援 |
| PoC(概念実証)を失敗させないための支援 (本支援はセミナーに参加しアンケートに回答した方を対象としています。) | ||
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |
Prophet 1.0 : 不確定区間
デフォルトでは Prophet は予測 yhat のための不確定区間を返します。これらの不確定区間の背後には幾つかの重要な仮定があります。
予測の不確実さには 3 つの源 (= source) があります : トレンドの不確実性、季節性推定の不確実性、そして追加の観測ノイズです。
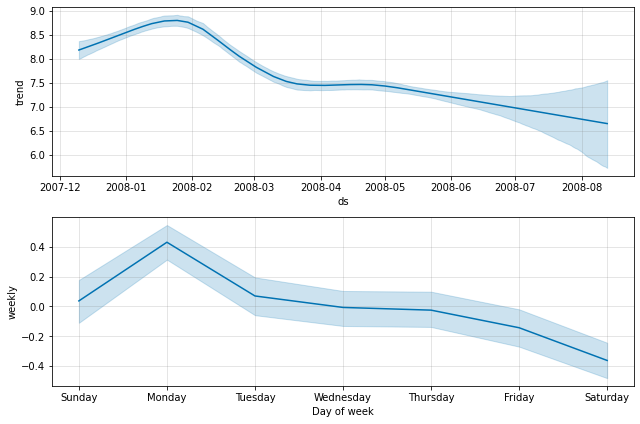
トレンドの不確実さ
予測の不確実性の最大の源は未来のトレンド変化の可能性です。このドキュメントの既に見た時系列は履歴で明確なトレンド変化を示します。Prophet はこれらを検出して適合させることができますが、その先にどのようなトレンド変化を想定するべきでしょうか?確実に知ることは不可能ですから、可能な最も合理的なものを行ない、そして未来は履歴と同様のトレンド変化を見ることを仮定します。特に、未来のトレンド変化の平均頻度と大きさは履歴で観測したものと同じであることを仮定しています。これらのトレンド変化を前方に予測し、そしてそれらの分布を計算することにより不確定区間を取得します。
不確実性の測定の方法の一つの特性は changepoint_prior_scale を増加することにより、レートの高い柔軟性を許容することで予測の不確実性を増加することです。これは、履歴のより多くのレート変化をモデル化すれば、未来でより多く (のレート変化) を想定して、不確定区間を過剰適合の有用な指標にするからです。
不確定区間の幅 (デフォルトで 80%) はパラメータ interval_width を使用して設定できます :
forecast = Prophet(interval_width=0.95).fit(df).predict(future)
再度、これらの区間は未来は過去と同じ頻度と大きさのレート変化を見ることを仮定しています。この仮定は多分真実ではありませんので、これらの不確定区間の正確なカバーを得ることは期待するべきではありません。
季節性の不確実性
デフォルトでは Prophet はトレンドと観測ノイズの不確実性だけを返します。季節性の不確実性を得るには、完全なベイジアン・サンプリングを行なわなければなりません。これはパラメータ mcmc.samples (このデフォルトは 0 です) を使用して成されます。ここではクイックスタートからの Peyton Manning データの最初の 6 ヶ月のためにこれを行ないます。
m = Prophet(mcmc_samples=300)
forecast = m.fit(df).predict(future)
これは典型的な MAP 推定を MCMC サンプリングで置き換えます、そしてどれだけの観測があるかに依存して遥かに長い時間がかかる可能性があります – 数秒の代わりに数分を予想します。完全なサンプリングを行なう場合、それらをプロットするとき季節的な成分で不確実性を見ます :
fig = m.plot_components(forecast)
Python でメソッド m.predictive_samples(future) か、R で関数 predictive_samples(m, future) を使用して raw 事後予測サンプルにアクセスできます。
Windows の PyStan では upstream issue があります、これは MCMC サンプリングを極めて遅くします。Windows での MCMC サンプリングのための最善の選択は R を使用するか、あるいは Linux VM で Python を使用することです。
以上
Prophet 1.0 : 乗法的季節性
Prophet 1.0 : 乗法的季節性 (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 07/10/2021 (1.0)
* 本ページは、Prophet の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。
スケジュールは弊社 公式 Web サイト でご確認頂けます。
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
| 人工知能研究開発支援 | 人工知能研修サービス | テレワーク & オンライン授業を支援 |
| PoC(概念実証)を失敗させないための支援 (本支援はセミナーに参加しアンケートに回答した方を対象としています。) | ||
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |
Prophet 1.0 : 乗法的季節性
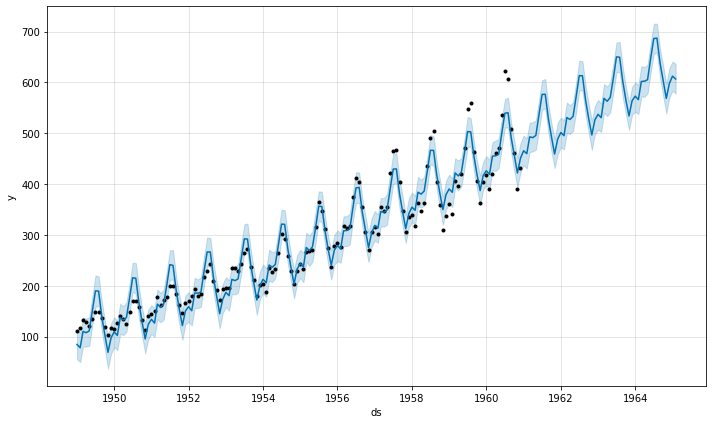
デフォルトでは Prophet は加法的季節性を適合させます、これは予測を得るために季節性の効果はトレンドに追加されることを意味します。航空旅客数のこの時系列は加法的季節性が機能しない時の例です :
df = pd.read_csv('../examples/example_air_passengers.csv')
m = Prophet()
m.fit(df)
future = m.make_future_dataframe(50, freq='MS')
forecast = m.predict(future)
fig = m.plot(forecast)
この時系列は明瞭な yearly サイクルを持ちますが、予測の季節性は時系列の最初は大きすぎて最後は小さすぎます。この時系列では、季節性は Prophet により想定される定数の加法的要因ではなく、むしろトレンドとともに成長します。これは乗法的季節性です。
Prophet は入力引数で seasonality_mode=’multiplicative’ を設定することにより乗法的季節性をモデル化することができます :
m = Prophet(seasonality_mode='multiplicative')
m.fit(df)
forecast = m.predict(future)
fig = m.plot(forecast)
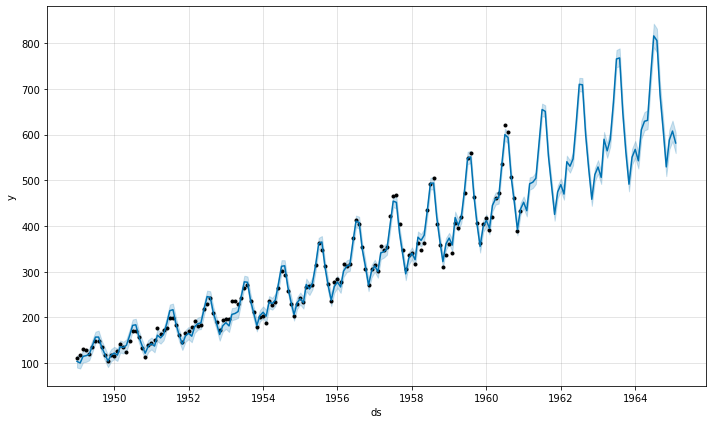
今では成分の図は季節性をトレンドのパーセントとして表示します :
fig = m.plot_components(forecast)
seasonality_mode=’multiplicative’ によって、休日効果もまた乗法的にモデル化されます。任意の追加された季節性や追加のリグレッサーはデフォルトで seasonality_mode が設定されているものを使用しますが、季節性やリグレッサーを追加するとき引数として mode=’additive’ or mode=’multiplicative’ を指定することにより override できます。
例えば、このブロックは組込みの季節性を乗法的に設定しますが、加法的四半期の季節性と加法的リグレッサーを含みます :
m = Prophet(seasonality_mode='multiplicative')
m.add_seasonality('quarterly', period=91.25, fourier_order=8, mode='additive')
m.add_regressor('regressor', mode='additive')
加法的そして乗法的追加のリグレッサーは成分プロットの個別のパネルに表示されます。けれども、加法的と乗法的季節性のミックスを持つことは殆どあり得ないので、これは通常はそれが当てはまることを想定する理由がある場合にだけ使用されます。
以上
Prophet 1.0 : 季節性、休日効果とリグレッサー
Prophet 1.0 : 季節性、休日効果とリグレッサー (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 07/10/2021 (1.0)
* 本ページは、Prophet の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。
スケジュールは弊社 公式 Web サイト でご確認頂けます。
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
| 人工知能研究開発支援 | 人工知能研修サービス | テレワーク & オンライン授業を支援 |
| PoC(概念実証)を失敗させないための支援 (本支援はセミナーに参加しアンケートに回答した方を対象としています。) | ||
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |
Prophet 1.0 : 季節性、休日効果とリグレッサー
休日と特定のイベントをモデリング
モデル化したい休日や他の繰り返し発生する (= recurring) イベントを持つ場合、それらからデータフレームを作成しなければなりません。それは 2 つのカラム (holiday と ds) と休日の各発生のために行を持ちます。それは過去 (後方に履歴データがある限り) と未来 (予測が行なわれている限り) の両者の、休日の総ての発生を含まなければなりません、それらが未来に繰り返されない場合、Prophet はそれらをモデル化して予測ではそれらを含めません。
カラムに lower_window と upper_window を含めることができます、これらは休日を日付周りの [lower_window, upper_window] days に拡張します。例えば、クリスマスに加えてクリスマス・イブを含めることを望んだ場合、lower_window=-1,upper_window=0 を含めます。感謝祭に加えてブラックフライデーを使用したい場合には、 lower_window=0,upper_window=1 を含めます。下で説明されるように、各休日のために prior scale を個別に設定するためにカラム prior_scale を含めることもできます。
ここでは Peyton Manning のプレーオフ出場の総ての日付を含むデータフレームを作成します :
playoffs = pd.DataFrame({
'holiday': 'playoff',
'ds': pd.to_datetime(['2008-01-13', '2009-01-03', '2010-01-16',
'2010-01-24', '2010-02-07', '2011-01-08',
'2013-01-12', '2014-01-12', '2014-01-19',
'2014-02-02', '2015-01-11', '2016-01-17',
'2016-01-24', '2016-02-07']),
'lower_window': 0,
'upper_window': 1,
})
superbowls = pd.DataFrame({
'holiday': 'superbowl',
'ds': pd.to_datetime(['2010-02-07', '2014-02-02', '2016-02-07']),
'lower_window': 0,
'upper_window': 1,
})
holidays = pd.concat((playoffs, superbowls))
上ではスーパーボウル days をプレーオフ・ゲームとスーパーボウルゲームの両者として含めました。これは、スパーボウル効果はプレーオフ効果の上に追加の加算的ボーナスであることを意味します。
ひとたびテーブルが作成されれば、休日効果はそれらを holidays 引数で渡すことにより予測に含まれます。ここでは クイックスタート からの Peyton Manning データでそれを行ないます :
m = Prophet(holidays=holidays)
forecast = m.fit(df).predict(future)
休日効果は予測データフレーム内で見ることができます :
forecast[(forecast['playoff'] + forecast['superbowl']).abs() > 0][
['ds', 'playoff', 'superbowl']][-10:]
休日効果はまた成分プロット内にも現れます、そこではプレーオフ出場周りの日々でスパイクがあり、スーパーボウルのためには特に巨大なスパイクがあります :
fig = m.plot_components(forecast)
スーパボウル休日成分だけをプロットする plot_forecast_component(m, forecast, ‘superbowl’) のように、(Python で prophet.plot からインポートされる) plot_forecast_component 関数を使用して個々の休日をプロットできます。
組込みの国の休日
add_country_holidays メソッド (Python) や関数 (R) を使用して国固有の休日の組込みコレクションを使用できます。国の名前が指定されると、上で説明された holidays 引数を通して指定された任意の休日に加えて、その国のための主要な休日が含まれます。
m = Prophet(holidays=holidays)
m.add_country_holidays(country_name='US')
m.fit(df)
モデルの train_holiday_names (Python) か train.holiday.names (R) 属性を見ることによりどの休日が含まれたかを見ることができます :
m.train_holiday_names
0 playoff 1 superbowl 2 New Year's Day 3 Martin Luther King Jr. Day 4 Washington's Birthday 5 Memorial Day 6 Independence Day 7 Labor Day 8 Columbus Day 9 Veterans Day 10 Thanksgiving 11 Christmas Day 12 Christmas Day (Observed) 13 Veterans Day (Observed) 14 Independence Day (Observed) 15 New Year's Day (Observed) dtype: object
各国のための休日は Python の holidays パッケージにより提供されます。利用可能な国のリストと使用する国名はページ : https://github.com/dr-prodigy/python-holidays で利用可能です。それらの国に加えて、Prophet はこれらの国のための休日を含みます : ブラジル (BR), インドネシア (ID), インド (IN), マレーシア (MY), ベトナム (VN), タイ (TH), フィリッピン (PH), パキスタン (PK), バングラディシュ (BD), エジプト (EG), 中国 (CN), そしてロシア (RU), 韓国 (KR), ベラルーシ (BY), そしてアラブ首長国連邦 (AE) です。
※ 訳注 : 日本 (JP/JPN)
Python では、殆どの休日は決定論的に計算されますので任意の日付範囲で利用可能です ; 日付がその国でサポートされる範囲に入らない場合、警告が上げられます。R では、休日の日付は 1995 から 2044 年まで計算されて data-raw/generated_holidays.csv としてパッケージにストアされます。より広い日付範囲が必要であれば、このスクリプトはそのファイルを別の日付範囲と置き換えるために使用できます : https://github.com/facebook/prophet/blob/master/python/scripts/generate_holidays_file.py 。
上のように、国レベルの休日は成分プロットで現れます :
forecast = m.predict(future)
fig = m.plot_components(forecast)
季節性のフーリエ次数
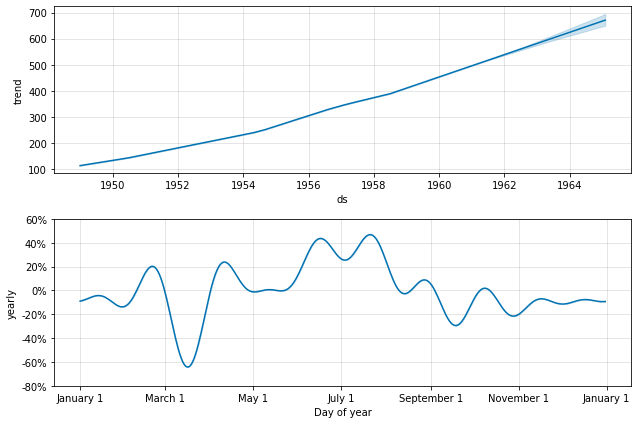
季節性は部分フーリエ和を使用して推定されます。完全な詳細は 論文 を、そして部分フーリエ和がどのように任意の周期信号を近似できるかの例示のためには Wikipedia のこの図 を見てください。部分和の項の数 (次数) はどのくらい素早く周期性が変化するかを決定するパラメータです。これを説明するために、クイックスタート からの Peyton Manning データを考えます。年毎の季節性のためのデフォルトのフーリエ次数は 10 で、これはこの適合を生成します :
from prophet.plot import plot_yearly
m = Prophet().fit(df)
a = plot_yearly(m)
デフォルト値はしばしば適切ですが、季節性がより高い頻度の変化に適合する必要があるとき、それらは増やすことができます、そして一般に滑らかでなくなります。フーリエ次数はモデルをインスタンス化するとき各組込みの季節性のために指定できます、ここではそれは 20 に増やされています :
from prophet.plot import plot_yearly
m = Prophet(yearly_seasonality=20).fit(df)
a = plot_yearly(m)
フーリエ項の数を増やすことは季節性を変化するサイクルに高速に適合させることを可能にしますが、過剰適合に繋がる可能性もあります : N 個のフーリエ項はサイクルをモデリングするために使用される 2N 変数に相当します。
カスタム季節性を指定する
Prophet は時系列が 2 つのサイクル長を越える場合、デフォルトで weekly と yearly の季節性に適合させます。それはまた部分的な daily 時系列のために daily の季節性にも適合させます。add_seasonality メソッド (Python) or 関数 (R) を使用して他の季節性 (monthly, quarterly, hourly) を追加することができます。
この関数への入力は名前、季節性の期間 (in days)、そして季節性のためのフーリエ次数です。参考までに、デフォルトでは Prophet は weekly 季節性のために 3 のフーリエ次数をそして yearly 季節性のために 10 を使用します。add_seasonality へのオプションの入力はその季節性成分のための prior scale です – これは下で議論されます。
例として、ここでは クイックスタート から Peyton Manning データを適合させますが、weekly 季節性を monthly 季節性で置き換えます。そして monthly 季節性は成分プロットに現れます :
m = Prophet(weekly_seasonality=False)
m.add_seasonality(name='monthly', period=30.5, fourier_order=5)
forecast = m.fit(df).predict(future)
fig = m.plot_components(forecast)
他の要因に依存する季節性
ある場合には、夏の間は年の残りの間とは異なるような weekly 季節パターンや、週末 vs 平日で異なるような daily 季節パターンのように、季節性は他の要員に依存するかもしれません。これらのタイプの季節性は条件付き季節性を使用してモデル化できます。
クイックスタート からの Peyton Manning サンプルを考えます。デフォルトの weekly 季節性は weekly 季節性のパターンが一年を通して同じであることを仮定していますが、(毎日曜日に試合がある) オンシーズン中とオフシーズンの間では weekly 季節性のパターンが異なることを予期します。個別のオンシーズンとオフシーズン weekly 季節性を構築するために条件付き季節性を使用できます。
最初にデータフレームにブーリアン・カラムを追加します、これは各日付がオンシーズンかオフシーズンにあるかを示します :
def is_nfl_season(ds):
date = pd.to_datetime(ds)
return (date.month > 8 or date.month < 2)
df['on_season'] = df['ds'].apply(is_nfl_season)
df['off_season'] = ~df['ds'].apply(is_nfl_season)
そして組込みの weekly 季節性を無効にして、それを条件として指定されたこれらのカラムを持つ 2 つの weekly 季節性で置き換えます。これは、季節性は condition_name カラムが True である日付にだけ適用されることを意味します。また (そのために) 予測を行なう future データフレームにカラムを追加しなければなりません。
m = Prophet(weekly_seasonality=False)
m.add_seasonality(name='weekly_on_season', period=7, fourier_order=3, condition_name='on_season')
m.add_seasonality(name='weekly_off_season', period=7, fourier_order=3, condition_name='off_season')
future['on_season'] = future['ds'].apply(is_nfl_season)
future['off_season'] = ~future['ds'].apply(is_nfl_season)
forecast = m.fit(df).predict(future)
fig = m.plot_components(forecast)
両者の季節性が今では上の成分プロットに現れます。ゲームが毎土曜日にプレーされるオンシーズンの間、日曜日と月曜日に大規模な増加があることが見れますが、オフシーズンの間にはまったくありません。
休日と季節性のための Prior スケール
休日が過剰適合していることを見つける場合、パラメータ holidays_prior_scale を使用してそれらを滑らかにするために prior スケールを調整できます。デフォルトではこのパラメータは 10 で、それは正則化を殆ど提供しません。このパラメータを減少させると休日効果を減衰させます :
m = Prophet(holidays=holidays, holidays_prior_scale=0.05).fit(df)
forecast = m.predict(future)
forecast[(forecast['playoff'] + forecast['superbowl']).abs() > 0][
['ds', 'playoff', 'superbowl']][-10:]
休日効果の大きさは前に比べて減少しています、特にスーパーボウルについて、これは最も少ない観測を持ちました。季節性モデルがデータに適合する範囲を同様に調整するパラメータ seasonality_prior_scale があります。
prior スケールは holidays データフレーム内にカラム prior_scale を含めることにより個々の休日のために個別に設定できます。個々の季節性のための prior スケールは add_seasonality への引数として渡すことができます。例えば、weekly 季節性のためだけの prior スケールは次を使用して設定できます :
m = Prophet()
m.add_seasonality(
name='weekly', period=7, fourier_order=3, prior_scale=0.1)
追加のリグレッサー
add_regressor メソッドか関数を使用して追加のリグレッサーがモデルの線形部分に追加できます。regressor 値を持つカラムは fitting と prediction データフレームの両者で存在する必要があります。例えば、NFL シーズンの間の日曜日に追加の効果を追加することができます。成分プロットでは、効果は ‘extra_regressors’ プロットに現れます :
def nfl_sunday(ds):
date = pd.to_datetime(ds)
if date.weekday() == 6 and (date.month > 8 or date.month < 2):
return 1
else:
return 0
df['nfl_sunday'] = df['ds'].apply(nfl_sunday)
m = Prophet()
m.add_regressor('nfl_sunday')
m.fit(df)
future['nfl_sunday'] = future['ds'].apply(nfl_sunday)
forecast = m.predict(future)
fig = m.plot_components(forecast)
NFL サンデーはまた過去と未来の NFL サンデーのリストを作成して、上で説明された “holidays” インターフェイスを使用して処理されました。add_regressor 関数は追加の (= extra) 線形リグレッサーを定義するためにより一般的なインターフェイスを提供し、そして特にリグレッサーは二値インジケーターであることを必要としません。別の時系列をリグレッサーとして使用できるでしょうが、その future 値は知られなければなりません。
このノートブック は自転車の使用量の予測において追加のリグレッサーとして天気要因を使用する例を示し、そして他の時系列が追加のリグレッサーとして含まれる方法の優れた例を提供します。
add_regressor 関数は prior スケール (デフォルトでは holiday prior スケールが使用されます) とリグレッサーが標準化されているか否かを指定するためのオプション引数を持ちます - Python の help(Prophet.add_regressor) そして R の ?add_regressor で docstring を見てください。リグレッサーはモデル適合の前に追加されなければならないことに注意してください。Prophet はまたリグレッサーが履歴を通して定数である場合にはエラーを上げます、何故ならばそれから適合するものがないからです。
追加のリグレッサーは履歴と未来の日付の両者のために知られなければなりません。従ってそれは (nfl_sunday のように) 未来の値を知っているものか、あるいは他で別に予測された何かでなければなりません。上でリンクされたノートブックで使用される天気リグレッサーは未来値のために使用できる予測を持つ追加のリグレッサーの良いサンプルです。Prophet のような時系列モデルで予測された別の時系列をリグレッサーとして使用することもできます。例えば、r(t) が y(t) のためのリグレッサーとして含まれる場合、Prophet は r(t) を予測するために使用できてそしてその予測は y(t) を予測するとき未来値としてプラグインできます。このアプローチまわりの注意点は : これは r(t) が y(t) を予測するのが幾分容易でない限りは多分有用でありません。これは r(t) の予測誤差が y(t) の予測で誤差を生成するからです。これが有用であり得る一つの設定は階層型時系列内です、そこでは高い信号対雑音 (= signal-to-noise) を持ち予測が容易なトップレベルの予測があります。その予測は各下位レベルの系列のための予測に含めることができます。
追加のリグレッサーはモデルの線形成分に配置されますので、基礎的なモデルは、加法 or 乗法要因のいずれかとして時系列が追加のリグレッサーに依存します (乗法のためには次のセクション参照)。
追加のリグレッサーの係数
追加のリグレッサーの beta 係数を抽出するため、適合されたモデル上でユティリティ関数 regressor_coefficients を使用します (Python では from prophet.utilities import regressor_coefficients, R では prophet::regressor_coefficients)。各リグレッサーのための推定された beta 係数はリグレッサー値の単位増加に対する予測値の増加をおおよそ表します (返される係数は常に元のデータのスケールであることに注意してください)。mcmc_samples が指定される場合、各係数の信用区間 (= credible interval) も返されます、これは各レグレッサーが「統計的に有意である」かを識別するのに役立つことができます。
以上
Prophet 1.0 : トレンドの変化点
Prophet 1.0 : トレンドの変化点 (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 07/09/2021 (1.0)
* 本ページは、Prophet の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。
スケジュールは弊社 公式 Web サイト でご確認頂けます。
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
| 人工知能研究開発支援 | 人工知能研修サービス | テレワーク & オンライン授業を支援 |
| PoC(概念実証)を失敗させないための支援 (本支援はセミナーに参加しアンケートに回答した方を対象としています。) | ||
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |
Prophet 1.0 : トレンドの変化点
ドキュメントのこれまでのサンプルで、リアルタイムな時系列はその軌跡において急激な (= abrupt) 変化を頻繁に持つことに気付いたかもしれません。デフォルトでは、Prophet はこれらの変化点を自動的に検出してトレンドが適切に適応することを可能にします。けれども、このプロセスをより細かく制御したい場合は (e.g., Prophet がレート変化を見逃す、あるいは履歴でレート変化を過剰適合させている)、使用できる幾つかの入力引数があります。
Prophet の自動変化点検出
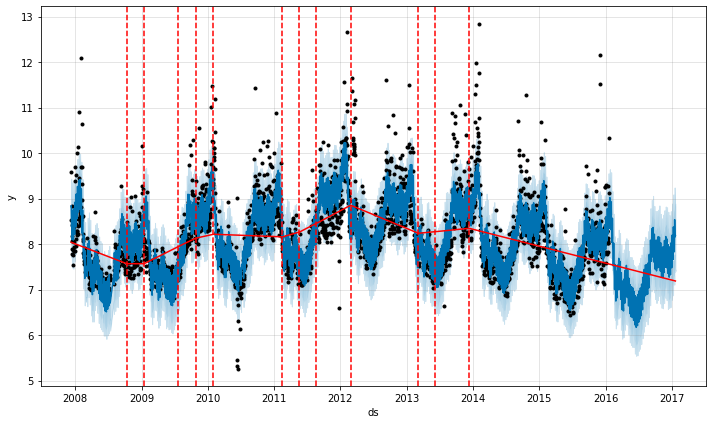
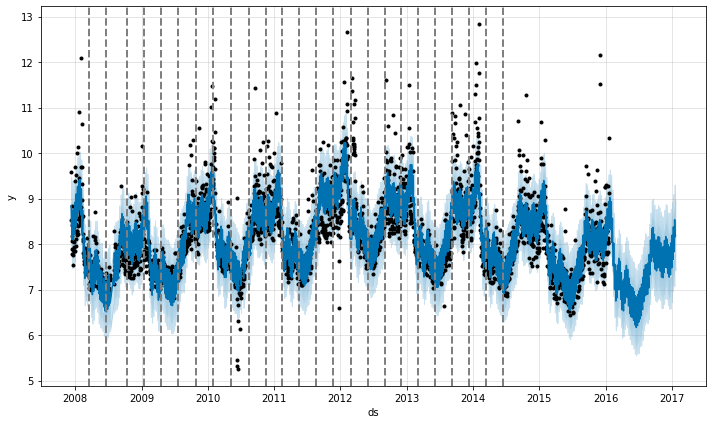
Prophet は多くの潜在的な変化点 (そこではレートは変化することが許容されています) を最初に指定することにより変化点を検出します。そしてそれはレート変化の大きさにスパースな事前分布を置きます (L1 正則化と同値) – これは Prophet がレートが変化できる可能性のある多くの場所を持ちますが、出来る限りそれらの少しを使用することを本質的に意味します。クイックスタート からの Peyton Manning 予測を考えます。デフォルトでは、Prophet は 25 の潜在的な変化点を指定します、これらは時系列の最初の 80% 内に一様に配置されます。この図の垂直線は潜在的な変化点が配置されたところを示します。
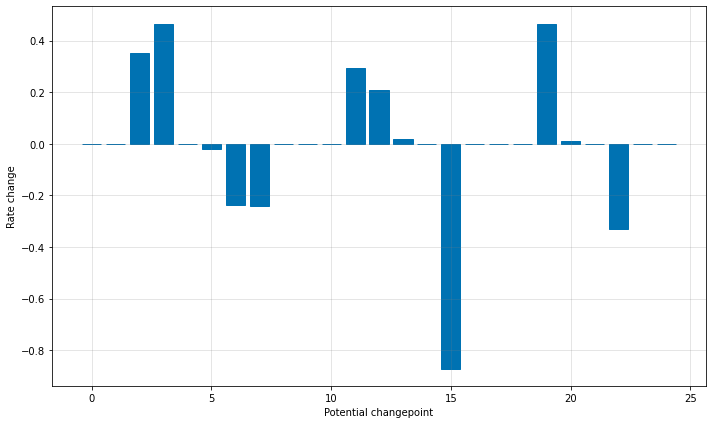
レートが変化し得る多くの場所を持ちますが、スパースな事前分布ゆえに、これらの変化点の殆どは使用されません。各変化点でのレート変更の大きさをプロットすることによりこれを見ることができます :
潜在的な変化点の数は引数 n_changepoints を使用して設定できますが、正則化を調整することでより良く調整されます。意義ある変化点の位置は次で可視化できます :
from prophet.plot import add_changepoints_to_plot
fig = m.plot(forecast)
a = add_changepoints_to_plot(fig.gca(), m, forecast)
デフォルトでは変化点は時系列の最初の 80% のためにだけ推論されます、これはトレンドを前方に推定するための多くの助走路を持ちそして時系列の最後で上下動の過剰適合を回避するためです。このデフォルトは多くの状況で動作しますが総てではありません、そして changepoint_range 引数を使用して変更できます。例えば、Python で m = Prophet(changepoint_range=0.9) または R で m <- prophet(changepoint.range = 0.9) は時系列の最初の 90% 内に潜在的な変化点を配置します。
トレンドの柔軟性の調整
トレンド変化が過剰適合 (overfit, 柔軟性が高すぎる) か過小適合 (underfit, 柔軟性が不十分) である場合、入力引数 changepoint_prior_scale を使用してスパースな事前分布の強さを調整できます。デフォルトでは、このパラメータは 0.05 に設定されています。それを増加することはトレンドをより柔軟にします :
m = Prophet(changepoint_prior_scale=0.5)
forecast = m.fit(df).predict(future)
fig = m.plot(forecast)
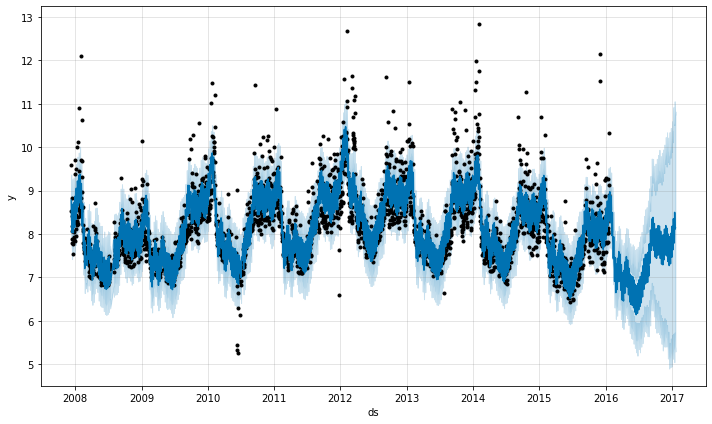
それを減少することはトレンドの柔軟性を低下させます :
m = Prophet(changepoint_prior_scale=0.001)
forecast = m.fit(df).predict(future)
fig = m.plot(forecast)
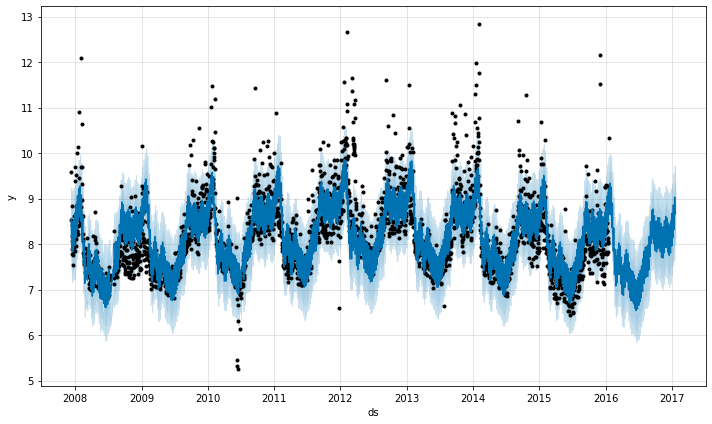
予測を可視化するとき、トレンドが過剰または過小適合に見える場合、このパラメータは必要に応じて調整できます。完全に自動化された設定では、このパラメータがどのように調整されるかの推奨については、交差検証についてのドキュメントを見てください。
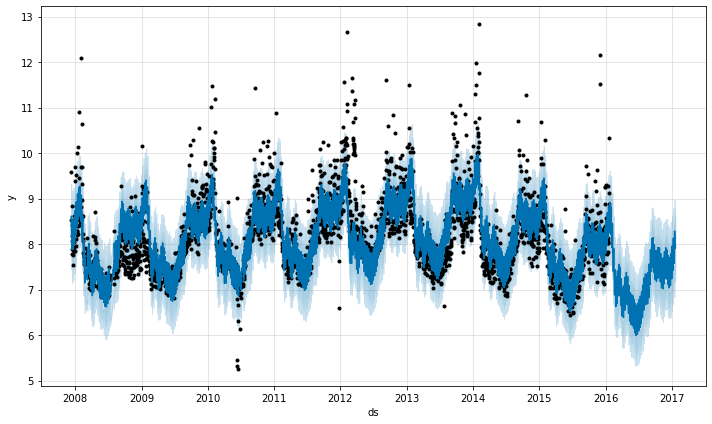
変化点の位置を指定する
お望みであれば、自動変化点検出を使用するのではなく、changepoints 引数で潜在的な変化点の位置を手動で指定できます。そして傾き (= slope) の変化は前と同じスパースな正則化によって、これらのポイントでのみ許容されます。例えば、ポイントのグリッドを自動的に成されたように作成して、そのグリッドを変化を持つ傾向にあると知られている幾つかの特定の日付で増強できます。別の例として、ここで成されるように、変化点は日付の小さいセットに全体的に制限できます :
m = Prophet(changepoints=['2014-01-01'])
forecast = m.fit(df).predict(future)
fig = m.plot(forecast)
以上
ClassCat® Chatbot
人工知能開発支援
- テクニカルコンサルティングサービス
- 実証実験 (プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
クラスキャット
セールス・インフォメーション
E-Mail:sales-info@classcat.com