ホーム » One Class SVM
「One Class SVM」カテゴリーアーカイブ
PyOD 0.8 : Examples : One Class SVM
PyOD 0.8 : Examples : One Class SVM (解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 06/27/2021 (0.8.9)
* 本ページは、PyOD の以下のドキュメントとサンプルを参考にして作成しています:
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。

スケジュールは弊社 公式 Web サイト でご確認頂けます。
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
| 人工知能研究開発支援 | 人工知能研修サービス | テレワーク & オンライン授業を支援 |
| PoC(概念実証)を失敗させないための支援 (本支援はセミナーに参加しアンケートに回答した方を対象としています。) | ||
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |

PyOD 0.8 : Examples : One Class SVM
完全なサンプル : examples/ocsvm_example.py
合成データの生成と可視化
pyod.utils.data.generate_data() でサンプルデータを生成します :
from pyod.utils.data import generate_data
contamination = 0.1 # percentage of outliers
n_train = 200 # number of training points
n_test = 100 # number of testing points
X_train, y_train, X_test, y_test = generate_data(
n_train=n_train, n_test=n_test,
n_features=2,
contamination=contamination,
random_state=42
)
X_train, y_train の shape と値を確認します :
print(X_train.shape)
print(y_train.shape)
(200, 2) (200,)
X_train[:10]
array([[6.43365854, 5.5091683 ],
[5.04469788, 7.70806466],
[5.92453568, 5.25921966],
[5.29399075, 5.67126197],
[5.61509076, 6.1309285 ],
[6.18590347, 6.09410578],
[7.16630941, 7.22719133],
[4.05470826, 6.48127032],
[5.79978164, 5.86930893],
[4.82256361, 7.18593123]])
y_train[:200]
array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.])
X_train の分布を可視化します :
import matplotlib.pyplot as plt
plt.scatter(X_train[:, 0], X_train[:, 1])
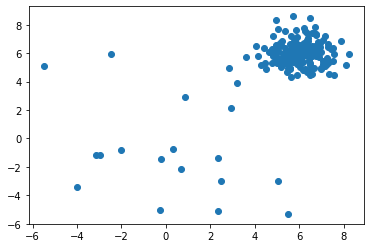
訓練データを可視化します :
import seaborn as sns
sns.set_style("dark")
from mpl_toolkits.mplot3d import Axes3D
X0 = X_train[:, 0]
X1 = X_train[:, 1]
Y = y_train
fig = plt.figure()
ax = Axes3D(fig)
ax.set_title("synthesized data")
ax.set_xlabel("X0")
ax.set_ylabel("X1")
ax.set_zlabel("Y")
ax.plot(X0, X1, Y, marker="o",linestyle='None')
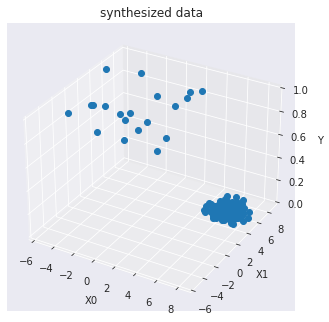
モデル訓練
pyod.models.ocsvm.OCSVM 検出器をインポートして初期化し、そしてモデルを適合させます。
より多くの機能を持つ scikit-learn one-class SVM クラスのラッパーです。教師なし外れ値検知です。
高次元分布のサポートを推定します。実装は libsvm に基づいています。
参照 :
- http://scikit-learn.org/stable/modules/svm.html#svm-outlier-detection
- Bernhard Schölkopf, John C Platt, John Shawe-Taylor, Alex J Smola, and Robert C Williamson. Estimating the support of a high-dimensional distribution. Neural computation, 13(7):1443–1471, 2001.
パラメータ
- kernel (string, optional (default=’rbf’)) :
アルゴリズムで使用されるカーネル・タイプを指定します。それは ‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’ の一つか callable でなければなりません。何も指定されない場合には、’rbf’ が使用されます。callable が与えられた場合にはカーネル行列を事前計算するために使用されます。
from pyod.models.ocsvm import OCSVM
clf_name = 'OneClassSVM'
clf = OCSVM()
clf.fit(X_train)
OCSVM(cache_size=200, coef0=0.0, contamination=0.1, degree=3, gamma='auto', kernel='rbf', max_iter=-1, nu=0.5, shrinking=True, tol=0.001, verbose=False)
訓練データの予測ラベルと外れ値スコアを得ます :
y_train_pred = clf.labels_ # binary labels (0: inliers, 1: outliers)
y_train_scores = clf.decision_scores_ # raw outlier scores
y_train_pred
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1,
1, 1])
y_train_scores[-40:]
array([-0.78857197, 1.82421735, 0.52516778, 1.36053899, 15.95268822,
2.4715799 , -1.98421762, 4.78992561, -1.49198395, -1.6983532 ,
1.03366291, 3.6321792 , -2.00333481, 0.1132708 , 1.1528244 ,
1.47166268, -0.72974317, -1.55079259, -1.2506018 , 1.15327899,
23.92572607, 24.79414184, 24.02938483, 23.69938998, 25.22054002,
22.76152076, 24.99977021, 23.81604268, 25.31886731, 24.14355787,
13.71471089, 24.11178588, 25.36021672, 25.26198196, 25.20689073,
25.25618027, 25.36017907, 24.76715117, 21.52711931, 25.30266924])
予測と評価
先に正解ラベルを確認しておきます :
y_test
array([0., array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.])
テストデータ上で予測を行ないます :
y_test_pred = clf.predict(X_test) # outlier labels (0 or 1)
y_test_scores = clf.decision_function(X_test) # outlier scores
y_test_pred
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1])
y_test_scores[-40:]
array([ 5.9045124 , -2.01938422, -0.04809363, 1.579808 , 7.29815783,
2.75891915, 10.63424239, 1.69629951, 8.35181013, 3.87787154,
-1.22952342, 2.30787057, -1.92598485, 8.78137251, -1.42671526,
2.98254633, -1.05400309, 16.91238411, -1.38842923, -1.34779231,
3.67815253, -1.95072358, -1.54857191, 3.38326885, 8.77706568,
12.33489833, -0.87534863, 8.73047852, -1.9340466 , -1.4348534 ,
26.06172492, 25.58479044, 25.93969245, 25.377791 , 22.11729834,
23.73896701, 25.48826792, 26.29453172, 25.55043239, 25.38483225])
ROC と Precision @ Rank n pyod.utils.data.evaluate_print() を使用して予測を評価します。
from pyod.utils.data import evaluate_print
# evaluate and print the results
print("\nOn Training Data:")
evaluate_print(clf_name, y_train, y_train_scores)
print("\nOn Test Data:")
evaluate_print(clf_name, y_test, y_test_scores)
On Training Data: OneClassSVM ROC:0.9992, precision @ rank n:0.95 On Test Data: OneClassSVM ROC:1.0, precision @ rank n:1.0
総ての examples に含まれる visualize 関数により可視化を生成します :
from pyod.utils.example import visualize
visualize(clf_name, X_train, y_train, X_test, y_test, y_train_pred,
y_test_pred, show_figure=True, save_figure=False)
以上
ClassCat® Chatbot
人工知能開発支援
- テクニカルコンサルティングサービス
- 実証実験 (プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
クラスキャット
セールス・インフォメーション
E-Mail:sales-info@classcat.com