ホーム » sales-info の投稿 (ページ 3)
作者アーカイブ: sales-info
Prophet 1.0 : 季節性、休日効果とリグレッサー
Prophet 1.0 : 季節性、休日効果とリグレッサー (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 07/10/2021 (1.0)
* 本ページは、Prophet の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。

スケジュールは弊社 公式 Web サイト でご確認頂けます。
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
| 人工知能研究開発支援 | 人工知能研修サービス | テレワーク & オンライン授業を支援 |
| PoC(概念実証)を失敗させないための支援 (本支援はセミナーに参加しアンケートに回答した方を対象としています。) | ||
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |
Prophet 1.0 : 季節性、休日効果とリグレッサー
休日と特定のイベントをモデリング
モデル化したい休日や他の繰り返し発生する (= recurring) イベントを持つ場合、それらからデータフレームを作成しなければなりません。それは 2 つのカラム (holiday と ds) と休日の各発生のために行を持ちます。それは過去 (後方に履歴データがある限り) と未来 (予測が行なわれている限り) の両者の、休日の総ての発生を含まなければなりません、それらが未来に繰り返されない場合、Prophet はそれらをモデル化して予測ではそれらを含めません。
カラムに lower_window と upper_window を含めることができます、これらは休日を日付周りの [lower_window, upper_window] days に拡張します。例えば、クリスマスに加えてクリスマス・イブを含めることを望んだ場合、lower_window=-1,upper_window=0 を含めます。感謝祭に加えてブラックフライデーを使用したい場合には、 lower_window=0,upper_window=1 を含めます。下で説明されるように、各休日のために prior scale を個別に設定するためにカラム prior_scale を含めることもできます。
ここでは Peyton Manning のプレーオフ出場の総ての日付を含むデータフレームを作成します :
playoffs = pd.DataFrame({
'holiday': 'playoff',
'ds': pd.to_datetime(['2008-01-13', '2009-01-03', '2010-01-16',
'2010-01-24', '2010-02-07', '2011-01-08',
'2013-01-12', '2014-01-12', '2014-01-19',
'2014-02-02', '2015-01-11', '2016-01-17',
'2016-01-24', '2016-02-07']),
'lower_window': 0,
'upper_window': 1,
})
superbowls = pd.DataFrame({
'holiday': 'superbowl',
'ds': pd.to_datetime(['2010-02-07', '2014-02-02', '2016-02-07']),
'lower_window': 0,
'upper_window': 1,
})
holidays = pd.concat((playoffs, superbowls))
上ではスーパーボウル days をプレーオフ・ゲームとスーパーボウルゲームの両者として含めました。これは、スパーボウル効果はプレーオフ効果の上に追加の加算的ボーナスであることを意味します。
ひとたびテーブルが作成されれば、休日効果はそれらを holidays 引数で渡すことにより予測に含まれます。ここでは クイックスタート からの Peyton Manning データでそれを行ないます :
m = Prophet(holidays=holidays)
forecast = m.fit(df).predict(future)
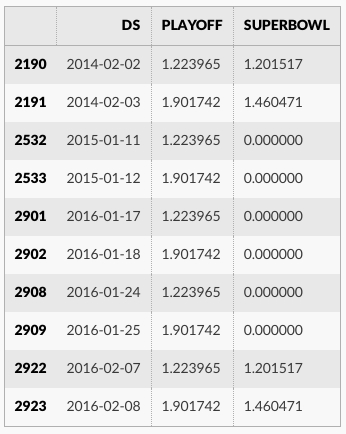
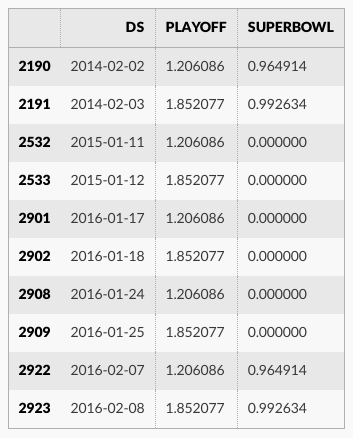
休日効果は予測データフレーム内で見ることができます :
forecast[(forecast['playoff'] + forecast['superbowl']).abs() > 0][
['ds', 'playoff', 'superbowl']][-10:]
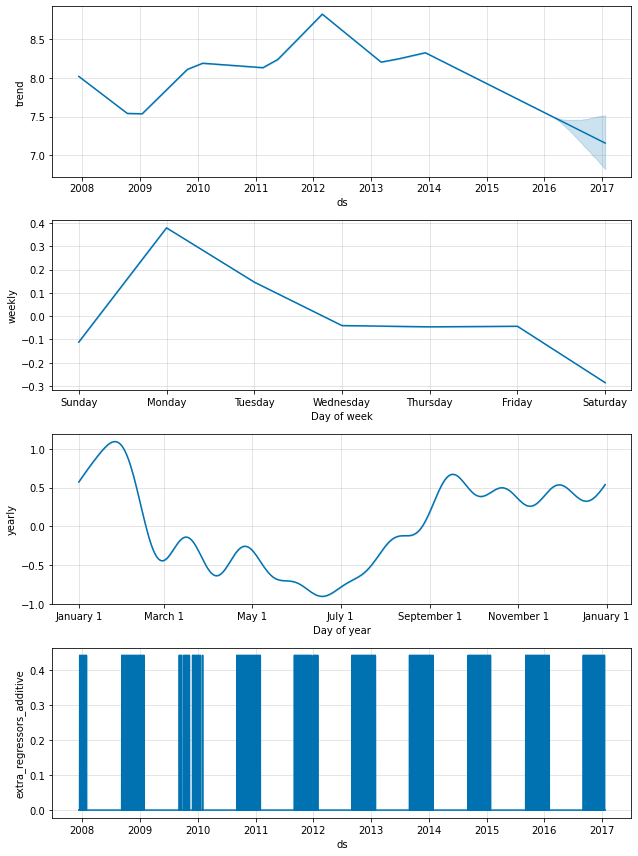
休日効果はまた成分プロット内にも現れます、そこではプレーオフ出場周りの日々でスパイクがあり、スーパーボウルのためには特に巨大なスパイクがあります :
fig = m.plot_components(forecast)
スーパボウル休日成分だけをプロットする plot_forecast_component(m, forecast, ‘superbowl’) のように、(Python で prophet.plot からインポートされる) plot_forecast_component 関数を使用して個々の休日をプロットできます。
組込みの国の休日
add_country_holidays メソッド (Python) や関数 (R) を使用して国固有の休日の組込みコレクションを使用できます。国の名前が指定されると、上で説明された holidays 引数を通して指定された任意の休日に加えて、その国のための主要な休日が含まれます。
m = Prophet(holidays=holidays)
m.add_country_holidays(country_name='US')
m.fit(df)
モデルの train_holiday_names (Python) か train.holiday.names (R) 属性を見ることによりどの休日が含まれたかを見ることができます :
m.train_holiday_names
0 playoff 1 superbowl 2 New Year's Day 3 Martin Luther King Jr. Day 4 Washington's Birthday 5 Memorial Day 6 Independence Day 7 Labor Day 8 Columbus Day 9 Veterans Day 10 Thanksgiving 11 Christmas Day 12 Christmas Day (Observed) 13 Veterans Day (Observed) 14 Independence Day (Observed) 15 New Year's Day (Observed) dtype: object
各国のための休日は Python の holidays パッケージにより提供されます。利用可能な国のリストと使用する国名はページ : https://github.com/dr-prodigy/python-holidays で利用可能です。それらの国に加えて、Prophet はこれらの国のための休日を含みます : ブラジル (BR), インドネシア (ID), インド (IN), マレーシア (MY), ベトナム (VN), タイ (TH), フィリッピン (PH), パキスタン (PK), バングラディシュ (BD), エジプト (EG), 中国 (CN), そしてロシア (RU), 韓国 (KR), ベラルーシ (BY), そしてアラブ首長国連邦 (AE) です。
※ 訳注 : 日本 (JP/JPN)
Python では、殆どの休日は決定論的に計算されますので任意の日付範囲で利用可能です ; 日付がその国でサポートされる範囲に入らない場合、警告が上げられます。R では、休日の日付は 1995 から 2044 年まで計算されて data-raw/generated_holidays.csv としてパッケージにストアされます。より広い日付範囲が必要であれば、このスクリプトはそのファイルを別の日付範囲と置き換えるために使用できます : https://github.com/facebook/prophet/blob/master/python/scripts/generate_holidays_file.py 。
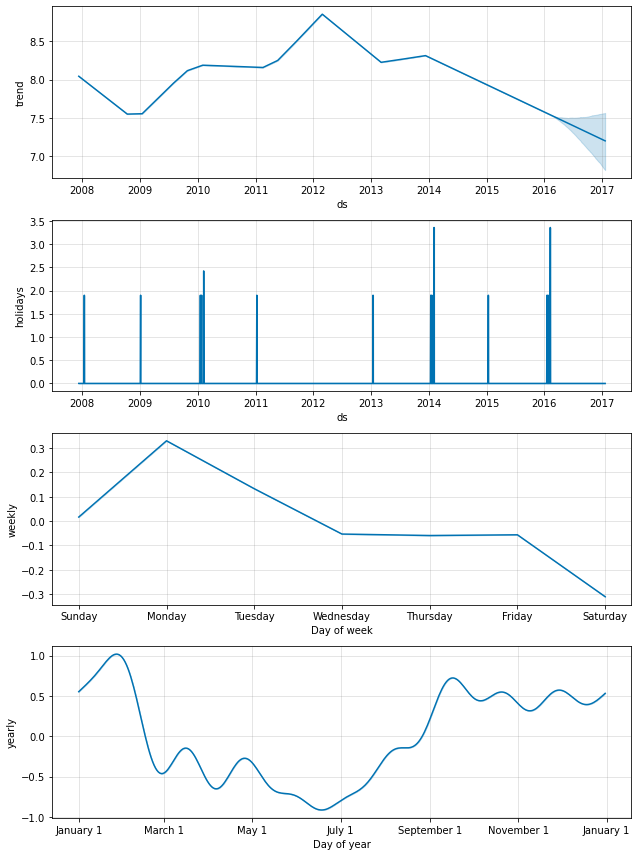
上のように、国レベルの休日は成分プロットで現れます :
forecast = m.predict(future)
fig = m.plot_components(forecast)
季節性のフーリエ次数
季節性は部分フーリエ和を使用して推定されます。完全な詳細は 論文 を、そして部分フーリエ和がどのように任意の周期信号を近似できるかの例示のためには Wikipedia のこの図 を見てください。部分和の項の数 (次数) はどのくらい素早く周期性が変化するかを決定するパラメータです。これを説明するために、クイックスタート からの Peyton Manning データを考えます。年毎の季節性のためのデフォルトのフーリエ次数は 10 で、これはこの適合を生成します :
from prophet.plot import plot_yearly
m = Prophet().fit(df)
a = plot_yearly(m)
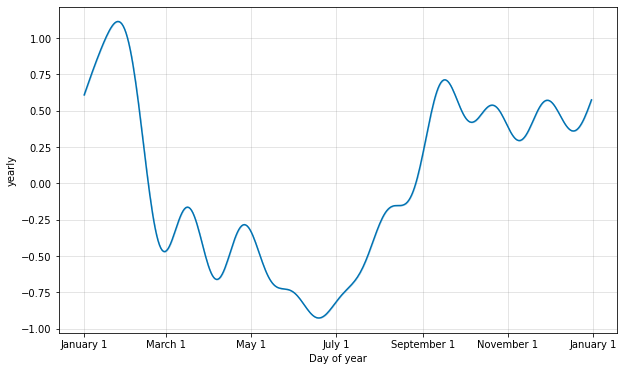
デフォルト値はしばしば適切ですが、季節性がより高い頻度の変化に適合する必要があるとき、それらは増やすことができます、そして一般に滑らかでなくなります。フーリエ次数はモデルをインスタンス化するとき各組込みの季節性のために指定できます、ここではそれは 20 に増やされています :
from prophet.plot import plot_yearly
m = Prophet(yearly_seasonality=20).fit(df)
a = plot_yearly(m)
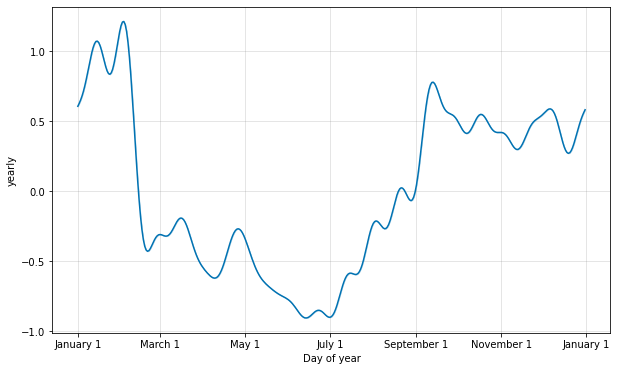
フーリエ項の数を増やすことは季節性を変化するサイクルに高速に適合させることを可能にしますが、過剰適合に繋がる可能性もあります : N 個のフーリエ項はサイクルをモデリングするために使用される 2N 変数に相当します。
カスタム季節性を指定する
Prophet は時系列が 2 つのサイクル長を越える場合、デフォルトで weekly と yearly の季節性に適合させます。それはまた部分的な daily 時系列のために daily の季節性にも適合させます。add_seasonality メソッド (Python) or 関数 (R) を使用して他の季節性 (monthly, quarterly, hourly) を追加することができます。
この関数への入力は名前、季節性の期間 (in days)、そして季節性のためのフーリエ次数です。参考までに、デフォルトでは Prophet は weekly 季節性のために 3 のフーリエ次数をそして yearly 季節性のために 10 を使用します。add_seasonality へのオプションの入力はその季節性成分のための prior scale です – これは下で議論されます。
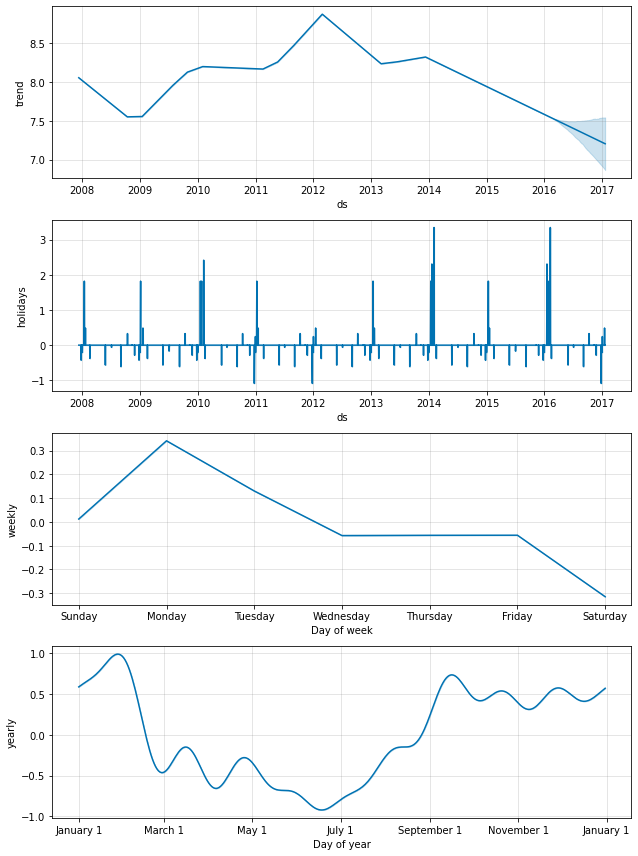
例として、ここでは クイックスタート から Peyton Manning データを適合させますが、weekly 季節性を monthly 季節性で置き換えます。そして monthly 季節性は成分プロットに現れます :
m = Prophet(weekly_seasonality=False)
m.add_seasonality(name='monthly', period=30.5, fourier_order=5)
forecast = m.fit(df).predict(future)
fig = m.plot_components(forecast)
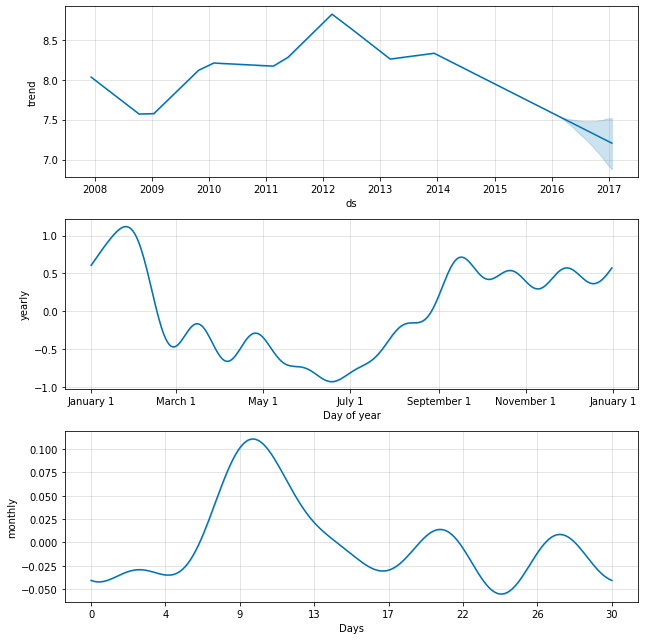
他の要因に依存する季節性
ある場合には、夏の間は年の残りの間とは異なるような weekly 季節パターンや、週末 vs 平日で異なるような daily 季節パターンのように、季節性は他の要員に依存するかもしれません。これらのタイプの季節性は条件付き季節性を使用してモデル化できます。
クイックスタート からの Peyton Manning サンプルを考えます。デフォルトの weekly 季節性は weekly 季節性のパターンが一年を通して同じであることを仮定していますが、(毎日曜日に試合がある) オンシーズン中とオフシーズンの間では weekly 季節性のパターンが異なることを予期します。個別のオンシーズンとオフシーズン weekly 季節性を構築するために条件付き季節性を使用できます。
最初にデータフレームにブーリアン・カラムを追加します、これは各日付がオンシーズンかオフシーズンにあるかを示します :
def is_nfl_season(ds):
date = pd.to_datetime(ds)
return (date.month > 8 or date.month < 2)
df['on_season'] = df['ds'].apply(is_nfl_season)
df['off_season'] = ~df['ds'].apply(is_nfl_season)
そして組込みの weekly 季節性を無効にして、それを条件として指定されたこれらのカラムを持つ 2 つの weekly 季節性で置き換えます。これは、季節性は condition_name カラムが True である日付にだけ適用されることを意味します。また (そのために) 予測を行なう future データフレームにカラムを追加しなければなりません。
m = Prophet(weekly_seasonality=False)
m.add_seasonality(name='weekly_on_season', period=7, fourier_order=3, condition_name='on_season')
m.add_seasonality(name='weekly_off_season', period=7, fourier_order=3, condition_name='off_season')
future['on_season'] = future['ds'].apply(is_nfl_season)
future['off_season'] = ~future['ds'].apply(is_nfl_season)
forecast = m.fit(df).predict(future)
fig = m.plot_components(forecast)
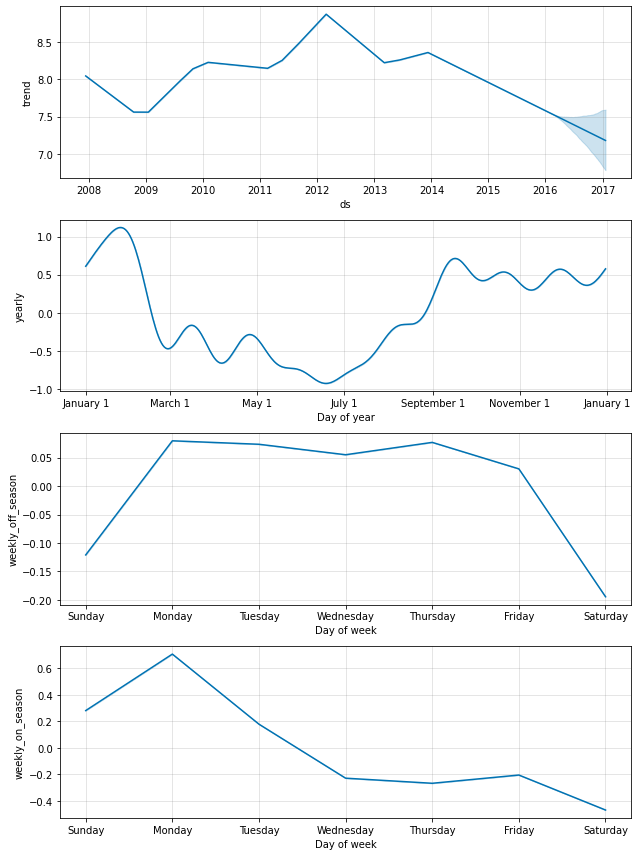
両者の季節性が今では上の成分プロットに現れます。ゲームが毎土曜日にプレーされるオンシーズンの間、日曜日と月曜日に大規模な増加があることが見れますが、オフシーズンの間にはまったくありません。
休日と季節性のための Prior スケール
休日が過剰適合していることを見つける場合、パラメータ holidays_prior_scale を使用してそれらを滑らかにするために prior スケールを調整できます。デフォルトではこのパラメータは 10 で、それは正則化を殆ど提供しません。このパラメータを減少させると休日効果を減衰させます :
m = Prophet(holidays=holidays, holidays_prior_scale=0.05).fit(df)
forecast = m.predict(future)
forecast[(forecast['playoff'] + forecast['superbowl']).abs() > 0][
['ds', 'playoff', 'superbowl']][-10:]
休日効果の大きさは前に比べて減少しています、特にスーパーボウルについて、これは最も少ない観測を持ちました。季節性モデルがデータに適合する範囲を同様に調整するパラメータ seasonality_prior_scale があります。
prior スケールは holidays データフレーム内にカラム prior_scale を含めることにより個々の休日のために個別に設定できます。個々の季節性のための prior スケールは add_seasonality への引数として渡すことができます。例えば、weekly 季節性のためだけの prior スケールは次を使用して設定できます :
m = Prophet()
m.add_seasonality(
name='weekly', period=7, fourier_order=3, prior_scale=0.1)
追加のリグレッサー
add_regressor メソッドか関数を使用して追加のリグレッサーがモデルの線形部分に追加できます。regressor 値を持つカラムは fitting と prediction データフレームの両者で存在する必要があります。例えば、NFL シーズンの間の日曜日に追加の効果を追加することができます。成分プロットでは、効果は ‘extra_regressors’ プロットに現れます :
def nfl_sunday(ds):
date = pd.to_datetime(ds)
if date.weekday() == 6 and (date.month > 8 or date.month < 2):
return 1
else:
return 0
df['nfl_sunday'] = df['ds'].apply(nfl_sunday)
m = Prophet()
m.add_regressor('nfl_sunday')
m.fit(df)
future['nfl_sunday'] = future['ds'].apply(nfl_sunday)
forecast = m.predict(future)
fig = m.plot_components(forecast)
NFL サンデーはまた過去と未来の NFL サンデーのリストを作成して、上で説明された “holidays” インターフェイスを使用して処理されました。add_regressor 関数は追加の (= extra) 線形リグレッサーを定義するためにより一般的なインターフェイスを提供し、そして特にリグレッサーは二値インジケーターであることを必要としません。別の時系列をリグレッサーとして使用できるでしょうが、その future 値は知られなければなりません。
このノートブック は自転車の使用量の予測において追加のリグレッサーとして天気要因を使用する例を示し、そして他の時系列が追加のリグレッサーとして含まれる方法の優れた例を提供します。
add_regressor 関数は prior スケール (デフォルトでは holiday prior スケールが使用されます) とリグレッサーが標準化されているか否かを指定するためのオプション引数を持ちます - Python の help(Prophet.add_regressor) そして R の ?add_regressor で docstring を見てください。リグレッサーはモデル適合の前に追加されなければならないことに注意してください。Prophet はまたリグレッサーが履歴を通して定数である場合にはエラーを上げます、何故ならばそれから適合するものがないからです。
追加のリグレッサーは履歴と未来の日付の両者のために知られなければなりません。従ってそれは (nfl_sunday のように) 未来の値を知っているものか、あるいは他で別に予測された何かでなければなりません。上でリンクされたノートブックで使用される天気リグレッサーは未来値のために使用できる予測を持つ追加のリグレッサーの良いサンプルです。Prophet のような時系列モデルで予測された別の時系列をリグレッサーとして使用することもできます。例えば、r(t) が y(t) のためのリグレッサーとして含まれる場合、Prophet は r(t) を予測するために使用できてそしてその予測は y(t) を予測するとき未来値としてプラグインできます。このアプローチまわりの注意点は : これは r(t) が y(t) を予測するのが幾分容易でない限りは多分有用でありません。これは r(t) の予測誤差が y(t) の予測で誤差を生成するからです。これが有用であり得る一つの設定は階層型時系列内です、そこでは高い信号対雑音 (= signal-to-noise) を持ち予測が容易なトップレベルの予測があります。その予測は各下位レベルの系列のための予測に含めることができます。
追加のリグレッサーはモデルの線形成分に配置されますので、基礎的なモデルは、加法 or 乗法要因のいずれかとして時系列が追加のリグレッサーに依存します (乗法のためには次のセクション参照)。
追加のリグレッサーの係数
追加のリグレッサーの beta 係数を抽出するため、適合されたモデル上でユティリティ関数 regressor_coefficients を使用します (Python では from prophet.utilities import regressor_coefficients, R では prophet::regressor_coefficients)。各リグレッサーのための推定された beta 係数はリグレッサー値の単位増加に対する予測値の増加をおおよそ表します (返される係数は常に元のデータのスケールであることに注意してください)。mcmc_samples が指定される場合、各係数の信用区間 (= credible interval) も返されます、これは各レグレッサーが「統計的に有意である」かを識別するのに役立つことができます。
以上
Prophet 1.0 : トレンドの変化点
Prophet 1.0 : トレンドの変化点 (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 07/09/2021 (1.0)
* 本ページは、Prophet の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。
スケジュールは弊社 公式 Web サイト でご確認頂けます。
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
| 人工知能研究開発支援 | 人工知能研修サービス | テレワーク & オンライン授業を支援 |
| PoC(概念実証)を失敗させないための支援 (本支援はセミナーに参加しアンケートに回答した方を対象としています。) | ||
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |
Prophet 1.0 : トレンドの変化点
ドキュメントのこれまでのサンプルで、リアルタイムな時系列はその軌跡において急激な (= abrupt) 変化を頻繁に持つことに気付いたかもしれません。デフォルトでは、Prophet はこれらの変化点を自動的に検出してトレンドが適切に適応することを可能にします。けれども、このプロセスをより細かく制御したい場合は (e.g., Prophet がレート変化を見逃す、あるいは履歴でレート変化を過剰適合させている)、使用できる幾つかの入力引数があります。
Prophet の自動変化点検出
Prophet は多くの潜在的な変化点 (そこではレートは変化することが許容されています) を最初に指定することにより変化点を検出します。そしてそれはレート変化の大きさにスパースな事前分布を置きます (L1 正則化と同値) – これは Prophet がレートが変化できる可能性のある多くの場所を持ちますが、出来る限りそれらの少しを使用することを本質的に意味します。クイックスタート からの Peyton Manning 予測を考えます。デフォルトでは、Prophet は 25 の潜在的な変化点を指定します、これらは時系列の最初の 80% 内に一様に配置されます。この図の垂直線は潜在的な変化点が配置されたところを示します。
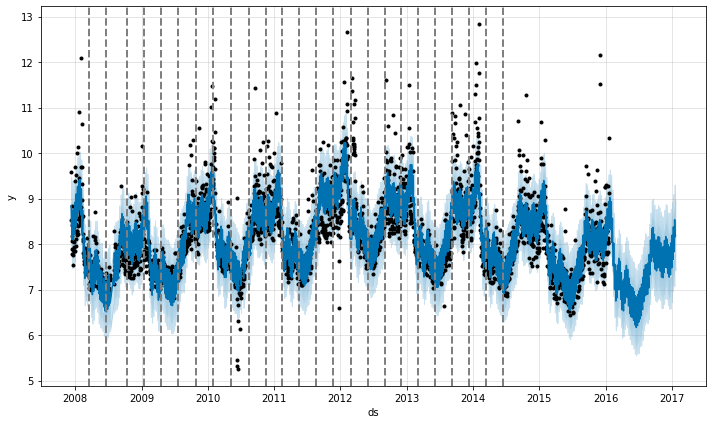
レートが変化し得る多くの場所を持ちますが、スパースな事前分布ゆえに、これらの変化点の殆どは使用されません。各変化点でのレート変更の大きさをプロットすることによりこれを見ることができます :
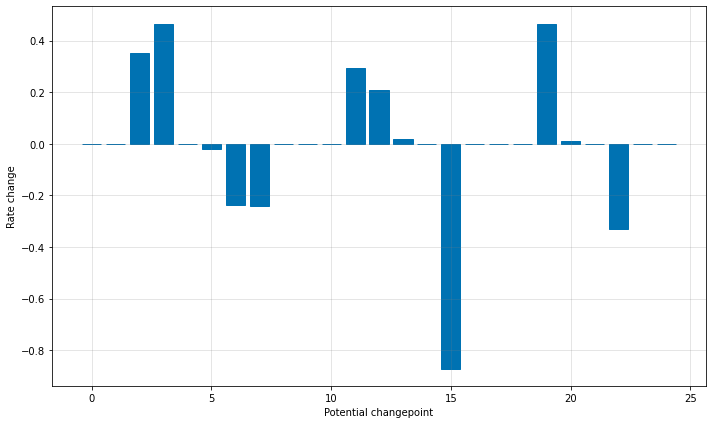
潜在的な変化点の数は引数 n_changepoints を使用して設定できますが、正則化を調整することでより良く調整されます。意義ある変化点の位置は次で可視化できます :
from prophet.plot import add_changepoints_to_plot
fig = m.plot(forecast)
a = add_changepoints_to_plot(fig.gca(), m, forecast)
デフォルトでは変化点は時系列の最初の 80% のためにだけ推論されます、これはトレンドを前方に推定するための多くの助走路を持ちそして時系列の最後で上下動の過剰適合を回避するためです。このデフォルトは多くの状況で動作しますが総てではありません、そして changepoint_range 引数を使用して変更できます。例えば、Python で m = Prophet(changepoint_range=0.9) または R で m <- prophet(changepoint.range = 0.9) は時系列の最初の 90% 内に潜在的な変化点を配置します。
トレンドの柔軟性の調整
トレンド変化が過剰適合 (overfit, 柔軟性が高すぎる) か過小適合 (underfit, 柔軟性が不十分) である場合、入力引数 changepoint_prior_scale を使用してスパースな事前分布の強さを調整できます。デフォルトでは、このパラメータは 0.05 に設定されています。それを増加することはトレンドをより柔軟にします :
m = Prophet(changepoint_prior_scale=0.5)
forecast = m.fit(df).predict(future)
fig = m.plot(forecast)
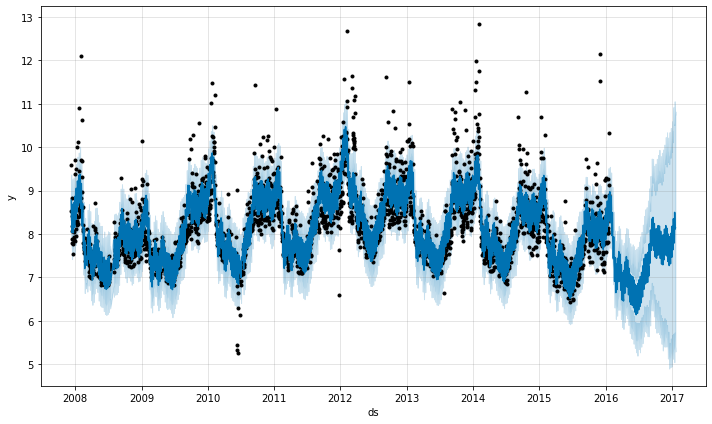
それを減少することはトレンドの柔軟性を低下させます :
m = Prophet(changepoint_prior_scale=0.001)
forecast = m.fit(df).predict(future)
fig = m.plot(forecast)
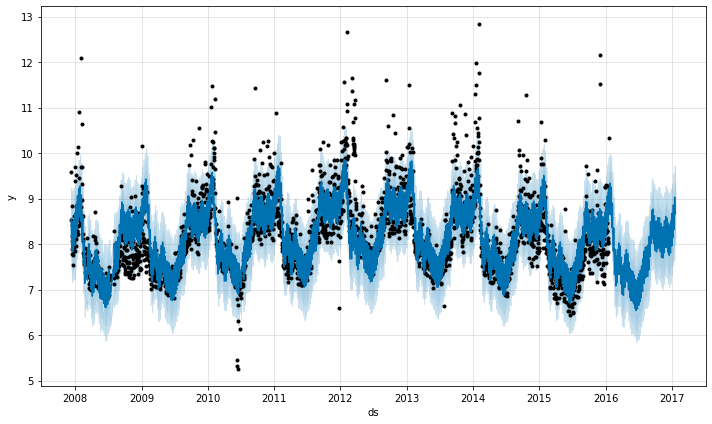
予測を可視化するとき、トレンドが過剰または過小適合に見える場合、このパラメータは必要に応じて調整できます。完全に自動化された設定では、このパラメータがどのように調整されるかの推奨については、交差検証についてのドキュメントを見てください。
変化点の位置を指定する
お望みであれば、自動変化点検出を使用するのではなく、changepoints 引数で潜在的な変化点の位置を手動で指定できます。そして傾き (= slope) の変化は前と同じスパースな正則化によって、これらのポイントでのみ許容されます。例えば、ポイントのグリッドを自動的に成されたように作成して、そのグリッドを変化を持つ傾向にあると知られている幾つかの特定の日付で増強できます。別の例として、ここで成されるように、変化点は日付の小さいセットに全体的に制限できます :
m = Prophet(changepoints=['2014-01-01'])
forecast = m.fit(df).predict(future)
fig = m.plot(forecast)
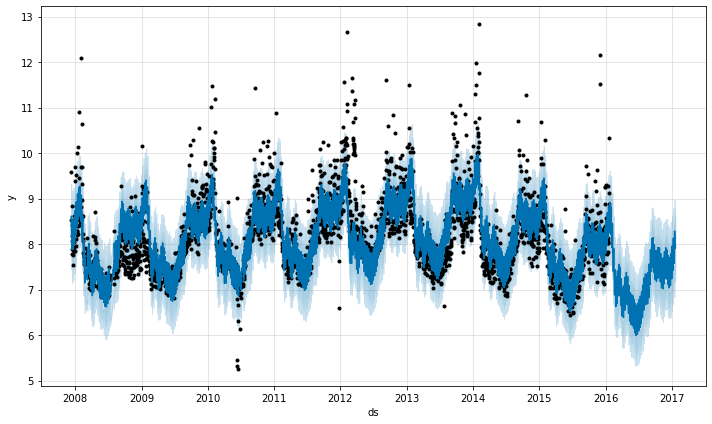
以上
Prophet 1.0 : 予測の飽和
Prophet 1.0 : 予測の飽和 (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 07/08/2021 (1.0)
* 本ページは、Prophet の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。
スケジュールは弊社 公式 Web サイト でご確認頂けます。
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
| 人工知能研究開発支援 | 人工知能研修サービス | テレワーク & オンライン授業を支援 |
| PoC(概念実証)を失敗させないための支援 (本支援はセミナーに参加しアンケートに回答した方を対象としています。) | ||
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |
Prophet 1.0 : 予測の飽和
成長の予測
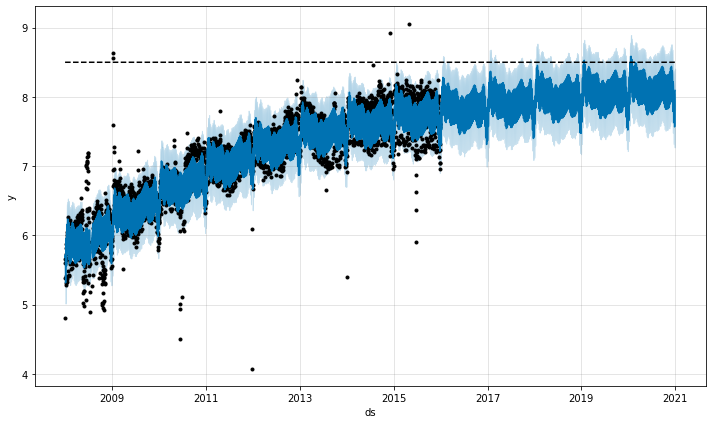
デフォルトでは、Prophet はその予測のために線形モデルを使用します。成長を予測するとき、通常はある達成可能な最大ポイントがあります : 全体的な市場規模、人口規模 etc. です。これは環境収容力 (= carrying capacity) と呼ばれ、予測はこのポイントで飽和するはずです。
Prophet は、指定された環境収容力とともに、ロジスティック成長 (= logistic growth) トレンドモデルを使用して予測を行なうことを可能にします。Wikipedia の R (プログラミング言語) のページへの訪問のログ数でこれを例示します。
df = pd.read_csv('../examples/example_wp_log_R.csv')
カラム cap で環境収容力を指定しなければなりません。ここでは特定の値を仮定しますが、これは通常は市場規模についてのデータや専門知識を使用して設定されます。
df['cap'] = 8.5
注意すべき重要なことは cap はデータフレームの総ての行のために指定されなければならず、そしてそれは定数である必要はないことです。市場規模が拡大している場合、cap は増大するシークエンスである可能性があります。
そして前のようにモデルを適合させますが、ロジスティック growth を指定するために追加の引数を渡します :
m = Prophet(growth='logistic')
m.fit(df)
前のように未来の予測のためにデータフレームを作成しますが、未来の収容力も指定しなければなりません。ここでは収容力を履歴のものと同じ値で定数として保持し、そして未来の 5 年を予測します :
future = m.make_future_dataframe(periods=1826)
future['cap'] = 8.5
fcst = m.predict(future)
fig = m.plot(fcst)
ロジスティック関数は 0 の暗黙的な最小値を持ち、収容力で飽和するのと同じように 0 で飽和します。別の飽和最小値を指定することも可能です。
飽和最小値
ロジスティック成長モデルはまた飽和最小値も処理できます、これは cap カラムが最大値を指定するのと同じ方法でカラム floor で指定されます :
df['y'] = 10 - df['y']
df['cap'] = 6
df['floor'] = 1.5
future['cap'] = 6
future['floor'] = 1.5
m = Prophet(growth='logistic')
m.fit(df)
fcst = m.predict(future)
fig = m.plot(fcst)
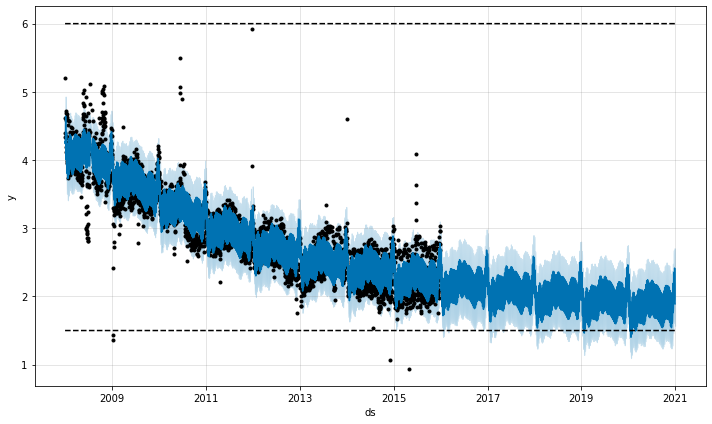
飽和最小値でロジスティック成長トレンドを使用するために、最大収容力も指定されなければなりません。
以上
Prophet 1.0 : クイックスタート
Prophet 1.0 : クイックスタート (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 07/06/2021 (1.0)
* 本ページは、Prophet の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。
スケジュールは弊社 公式 Web サイト でご確認頂けます。
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
| 人工知能研究開発支援 | 人工知能研修サービス | テレワーク & オンライン授業を支援 |
| PoC(概念実証)を失敗させないための支援 (本支援はセミナーに参加しアンケートに回答した方を対象としています。) | ||
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |
Prophet 1.0 : クイックスタート
Python API
Prophet は sklearn モデル API に従います。Prophet クラスのインスタンスを作成してからその fit と predict メソッドを呼び出します。
Prophet への入力は常に 2 つのカラム : ds と y を持つデータフレームです。ds (datestamp) カラムは Pandas により想定される形式であるべきです、理想的には日付のための YYYY-MM-DD またはタイムスタンプのための YYYY-MM-DD HH:MM:SS です。y カラムは数値でなければなりません、そして予測したい測定値を表します。
例として、 Peyton Manning のための Wikipedia ページのログの daily ページビューの時系列を見ましょう。このデータを R の Wikipediatrend パッケージを使用してかき集めました。Peyton Manning は良いサンプルを提供します、何故ならばそれは複数の季節性 (= seasonality)、成長率の変化、そして (Manning のプレーオフとスーパーボウルの出現のような) 特別な日をモデル化する機能のような Prophet の機能の幾つかを例示するからです。CSV は ここ で利用可能です。
最初にデータをインポートします :
import pandas as pd
from prophet import Prophet
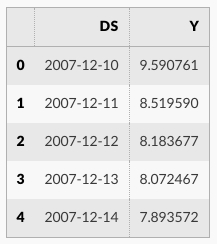
df = pd.read_csv('../examples/example_wp_log_peyton_manning.csv')
df.head()
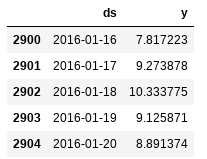
df.tail()
df.count()
ds 2905 y 2905 dtype: int64
新しい Prophet オブジェクトをインスタンス化することによりモデルを適合させます。予測手続きへの任意の設定はコンストラクタに渡されます。そしてその fit メソッドを呼び出して履歴データフレームを渡します。フィッティングには 1-5 秒かかるはずです。
m = Prophet()
m.fit(df)
それから予測は (そのために予測が成される) 日付を含むカラム ds を持つデータフレーム上で行なわれます。ヘルパーメソッド Prophet.make_future_dataframe を使用して指定された日数だけ未来に拡張する適切なデータフレームを得ることができます。デフォルトではそれは履歴からの日付も含みますので、モデルが適合していることも分かります。
future = m.make_future_dataframe(periods=365)
future.tail()
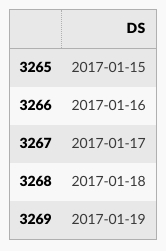
predict メソッドは future の各行に予測された値を割当てます、それは yhat と名前付けられます。履歴日付を渡す場合、それは in-sample な適合を提供します。ここで forecast オブジェクトは新しいデータフレームで、それは予測を持つカラム yhat と、成分と不確かな interval のためのカラムを含みます。
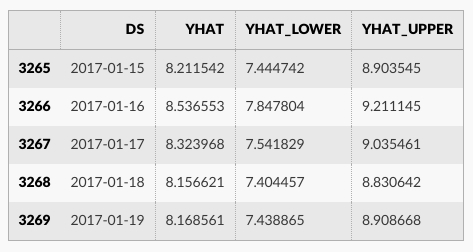
forecast = m.predict(future)
forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].tail()
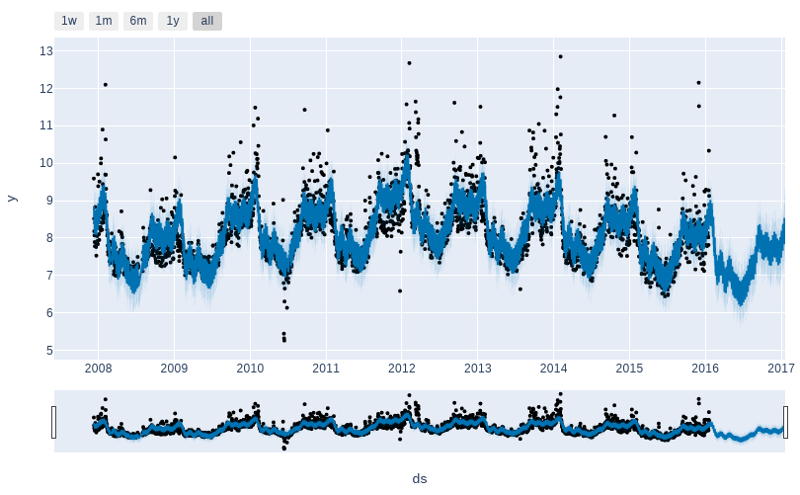
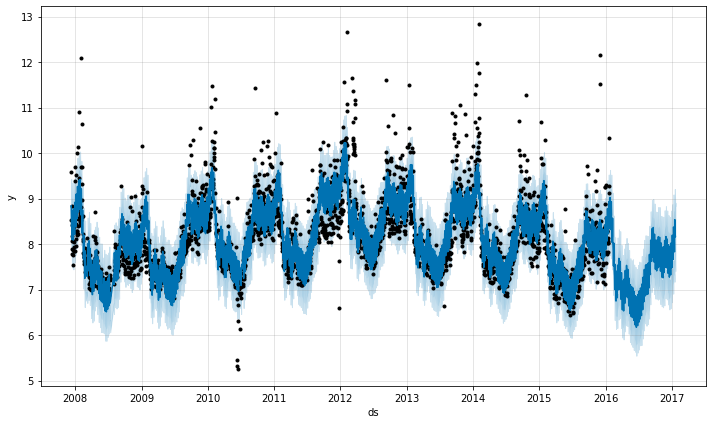
Prophet.plot メソッドを呼び出して forecast データフレームを渡すことにより予測をプロットできます。
fig1 = m.plot(forecast)
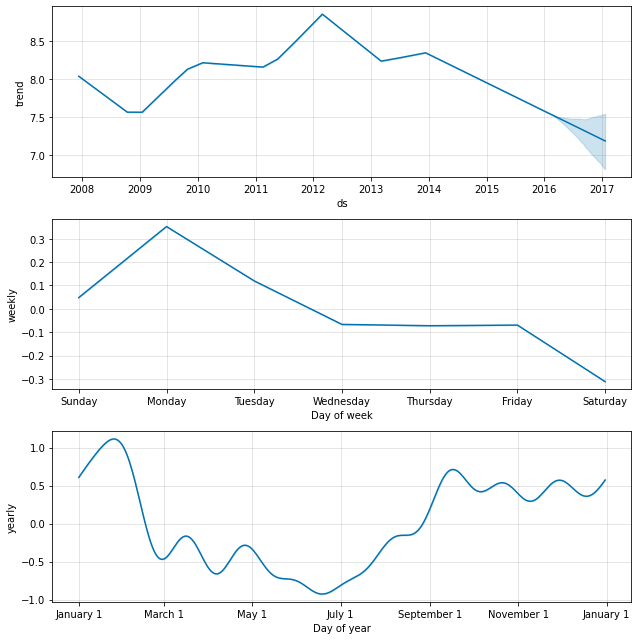
予測成分を見ることを望む場合、Prophet.plot_components メソッドを利用できます。デフォルトでは、時系列のトレンド、yearly 周期性と weekly 周期性を見ます。休日を含める場合、ここでそれらも見ます。
fig2 = m.plot_components(forecast)
予測と成分の対話的な図は plotly で作成できます。plotly 4.0 かそれ以上を個別にインストールする必要があります、それはデフォルトでは prophet と共にインストールされないからです。notebook と ipywidgets パッケージをインストールする必要もあります。
from prophet.plot import plot_plotly, plot_components_plotly
plot_plotly(m, forecast)
plot_components_plotly(m, forecast)
各メソッドのために利用可能なオプションについての詳細は docstrings で利用可能です、例えば help(Prophet) や help(Prophet.fit) を通してです。CRAN の R リファレンスマニュアルは利用可能な関数の総ての正確なリストを提供します、それらの各々は Python の同値を持ちます。
以上
Alibi Detect 0.7 : Examples : 外れ値、敵対的 & ドリフト検知 on CIFAR10
Alibi Detect 0.7 : Examples : 外れ値、敵対的 & ドリフト検知 on CIFAR10 (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 07/04/2021 (0.7.0)
* 本ページは、Alibi Detect の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。
スケジュールは弊社 公式 Web サイト でご確認頂けます。
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
| 人工知能研究開発支援 | 人工知能研修サービス | テレワーク & オンライン授業を支援 |
| PoC(概念実証)を失敗させないための支援 (本支援はセミナーに参加しアンケートに回答した方を対象としています。) | ||
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |
Alibi Detect 0.7 : Examples : 外れ値、敵対的 & ドリフト検知 on CIFAR10
0. データセット
CIFAR10 は 10 クラス : 飛行機、自動車、鳥、猫、鹿、犬、カエル、馬、船とトラック – に渡り均等に分配された 60,000 の 32 x 32 RGB 画像から成ります。
# imports and plot examples
import matplotlib.pyplot as plt
%matplotlib inline
import tensorflow as tf
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.cifar10.load_data()
X_train = X_train.astype('float32') / 255
X_test = X_test.astype('float32') / 255
y_train = y_train.astype('int64').reshape(-1,)
y_test = y_test.astype('int64').reshape(-1,)
print('Train: ', X_train.shape, y_train.shape)
print('Test: ', X_test.shape, y_test.shape)
plt.figure(figsize=(10, 10))
n = 4
for i in range(n ** 2):
plt.subplot(n, n, i + 1)
plt.imshow(X_train[i])
plt.axis('off')
plt.show();
Train: (50000, 32, 32, 3) (50000,) Test: (10000, 32, 32, 3) (10000,)

1. 変分オートエンコーダ (VAE) による外れ値検知
メソッド
簡単に言えば :
- 正常データ上で VAE を訓練するのでそれは inlier を上手く再構築できます。
- VAE が incoming リクエストを上手く再構築できないのであれば?外れ値です!
画像ソース: https://lilianweng.github.io/lil-log/2018/08/12/from-autoencoder-to-beta-vae.html
# more imports
import logging
import numpy as np
import os
from tensorflow.keras.layers import Conv2D, Conv2DTranspose, Dense
from tensorflow.keras.layers import Flatten, Layer, Reshape, InputLayer
from tensorflow.keras.regularizers import l1
from alibi_detect.od import OutlierVAE
from alibi_detect.utils.fetching import fetch_detector
from alibi_detect.utils.perturbation import apply_mask
from alibi_detect.utils.saving import save_detector, load_detector
from alibi_detect.utils.visualize import plot_instance_score, plot_feature_outlier_image
logger = tf.get_logger()
logger.setLevel(logging.ERROR)
検知器をロードまたはスクラッチから訓練する
ノートブックで使用される事前訓練済みの外れ値と敵対的検知器は ここ で見つかります。組込みの fetch_detector 関数を利用できます、これは事前訓練モデルをローカルディレクトリ filepath にセーブして検知器をロードします。代わりに、スクラッチから検知器を訓練することができます :
load_pretrained = False
%%time
filepath = os.path.join(os.getcwd(), 'outlier')
if load_pretrained: # load pre-trained detector
detector_type = 'outlier'
dataset = 'cifar10'
detector_name = 'OutlierVAE'
od = fetch_detector(filepath, detector_type, dataset, detector_name)
filepath = os.path.join(filepath, detector_name)
else: # define model, initialize, train and save outlier detector
# define encoder and decoder networks
latent_dim = 1024
encoder_net = tf.keras.Sequential(
[
InputLayer(input_shape=(32, 32, 3)),
Conv2D(64, 4, strides=2, padding='same', activation=tf.nn.relu),
Conv2D(128, 4, strides=2, padding='same', activation=tf.nn.relu),
Conv2D(512, 4, strides=2, padding='same', activation=tf.nn.relu)
]
)
decoder_net = tf.keras.Sequential(
[
InputLayer(input_shape=(latent_dim,)),
Dense(4*4*128),
Reshape(target_shape=(4, 4, 128)),
Conv2DTranspose(256, 4, strides=2, padding='same', activation=tf.nn.relu),
Conv2DTranspose(64, 4, strides=2, padding='same', activation=tf.nn.relu),
Conv2DTranspose(3, 4, strides=2, padding='same', activation='sigmoid')
]
)
# initialize outlier detector
od = OutlierVAE(
threshold=.015, # threshold for outlier score
encoder_net=encoder_net, # can also pass VAE model instead
decoder_net=decoder_net, # of separate encoder and decoder
latent_dim=latent_dim
)
# train
od.fit(X_train, epochs=50, verbose=True)
# save the trained outlier detector
save_detector(od, filepath)
782/782 [=] - 32s 36ms/step - loss: 3328.0921 782/782 [=] - 29s 36ms/step - loss: -2477.8159 782/782 [=] - 29s 36ms/step - loss: -3505.9077 782/782 [=] - 29s 36ms/step - loss: -4018.4684 782/782 [=] - 29s 36ms/step - loss: -4339.1812 782/782 [=] - 29s 36ms/step - loss: -4564.4784 782/782 [=] - 29s 36ms/step - loss: -4752.0325 782/782 [=] - 29s 36ms/step - loss: -4909.1439 782/782 [=] - 29s 36ms/step - loss: -5027.7148 782/782 [=] - 29s 36ms/step - loss: -5108.3359 782/782 [=] - 29s 36ms/step - loss: -5183.5322 782/782 [=] - 29s 36ms/step - loss: -5221.8213 782/782 [=] - 29s 36ms/step - loss: -5286.5078 782/782 [=] - 29s 36ms/step - loss: -5336.4698 782/782 [=] - 29s 36ms/step - loss: -5390.1145 782/782 [=] - 29s 36ms/step - loss: -5435.4759 782/782 [=] - 29s 36ms/step - loss: -5469.5508 782/782 [=] - 29s 36ms/step - loss: -5513.7060 782/782 [=] - 29s 36ms/step - loss: -5546.3630 782/782 [=] - 29s 36ms/step - loss: -5586.9172 782/782 [=] - 29s 36ms/step - loss: -5604.6617 782/782 [=] - 29s 36ms/step - loss: -5638.2204 782/782 [=] - 29s 36ms/step - loss: -5657.4971 782/782 [=] - 29s 36ms/step - loss: -5684.9612 782/782 [=] - 29s 36ms/step - loss: -5706.7390 782/782 [=] - 29s 36ms/step - loss: -5719.2535 782/782 [=] - 29s 36ms/step - loss: -5742.7461 782/782 [=] - 29s 36ms/step - loss: -5760.9044 782/782 [=] - 29s 36ms/step - loss: -5777.8526 782/782 [=] - 29s 36ms/step - loss: -5793.0808 782/782 [=] - 29s 36ms/step - loss: -5803.5456 782/782 [=] - 29s 36ms/step - loss: -5822.1962 782/782 [=] - 29s 36ms/step - loss: -5821.3968 782/782 [=] - 29s 36ms/step - loss: -5847.5206 782/782 [=] - 29s 36ms/step - loss: -5855.4035 782/782 [=] - 29s 36ms/step - loss: -5866.9793 782/782 [=] - 29s 36ms/step - loss: -5879.4730 782/782 [=] - 29s 36ms/step - loss: -5885.7166 782/782 [=] - 29s 36ms/step - loss: -5895.9667 782/782 [=] - 29s 36ms/step - loss: -5905.9128 782/782 [=] - 29s 36ms/step - loss: -5913.2937 782/782 [=] - 29s 36ms/step - loss: -5922.4864 782/782 [=] - 29s 36ms/step - loss: -5930.4101 782/782 [=] - 29s 36ms/step - loss: -5935.5514 782/782 [=] - 29s 36ms/step - loss: -5942.9960 782/782 [=] - 29s 36ms/step - loss: -5953.9588 782/782 [=] - 29s 36ms/step - loss: -5959.2278 782/782 [=] - 29s 36ms/step - loss: -5962.3586 782/782 [=] - 29s 36ms/step - loss: -5967.2992 782/782 [=] - 29s 36ms/step - loss: -5975.1563 Directory /home/ubuntu/ws.alibi_detect/outlier does not exist and is now created. CPU times: user 24min 6s, sys: 22.3 s, total: 24min 28s Wall time: 24min 8s
モデルが in-distribution 訓練データを何とか再構築できるかを確認しましょう :
# plot original and reconstructed instance
idx = 8
X = X_train[idx].reshape(1, 32, 32, 3)
X_recon = od.vae(X)
plt.imshow(X.reshape(32, 32, 3)); plt.axis('off'); plt.show()
plt.imshow(X_recon.numpy().reshape(32, 32, 3)); plt.axis('off'); plt.show()


閾値を設定する
良い閾値を見つけることは技巧的であり得ます、何故ならばそれらは典型的には解釈することが容易でないからです。infer_threshold メソッドは sensible な値を見つけるのに役立ちます。インスタンスのバッチ X を渡してそれらの何パーセントを正常であると考えるかを threshold_perc を通して指定する必要があります。
print('Current threshold: {}'.format(od.threshold))
od.infer_threshold(X_train, threshold_perc=99, batch_size=128) # assume 1% of the training data are outliers
print('New threshold: {}'.format(od.threshold))
Current threshold: 0.015 New threshold: 0.00969364859163762
外れ値を作成して検知する
元のインスタンスにランダムノイズマスクを適用することにより幾つかの外れ値を作成できます :
np.random.seed(0)
i = 1
# create masked instance
x = X_test[i].reshape(1, 32, 32, 3)
x_mask, mask = apply_mask(
x,
mask_size=(8,8),
n_masks=1,
channels=[0,1,2],
mask_type='normal',
noise_distr=(0,1),
clip_rng=(0,1)
)
# predict outliers and reconstructions
sample = np.concatenate([x_mask, x])
preds = od.predict(sample)
x_recon = od.vae(sample).numpy()
# check if outlier and visualize outlier scores
labels = ['No!', 'Yes!']
print(f"Is original outlier? {labels[preds['data']['is_outlier'][1]]}")
print(f"Is perturbed outlier? {labels[preds['data']['is_outlier'][0]]}")
plot_feature_outlier_image(preds, sample, x_recon, max_instances=1)
Is original outlier? No! Is perturbed outlier? Yes!

検知器を配備する
このサンプルのオープンソース配備プラットフォーム Seldon Core と (サーバレス・コンポーネントがイベントストリームに接続されることを可能にする) イベント・ベースのプロジェクト Knative を使用します。Seldon Core payload logger はモデルリクエストを含むイベントを Knative に送ります、これはこれらを外れ値、ドリフトや敵対的検知モジュールのようなサーバレス・コンポーネントに委託することができます。更に例えばアラート or ストレージ・モジュールに前方に送るためにこれらのコンポーネントにより生成されたイベントを供給するためにイベント・コンポーネントが追加できます。これらは非同期に発生します。
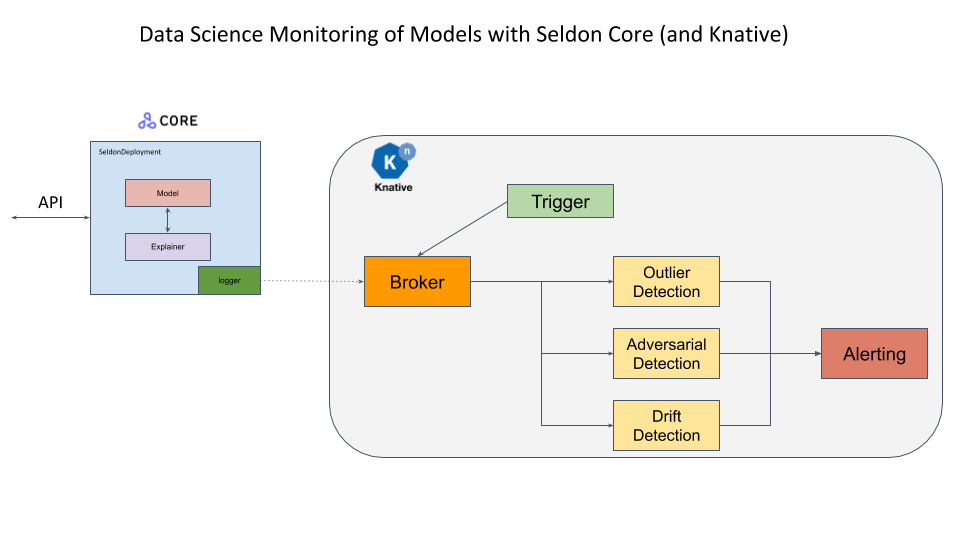
既に Seldon Core をインストールして DigitalOcean 上クラスタを構成しました。スクラッチから総てをセットアップする構成ステップは このサンプル・ノートブック で詳述されています。
最初に Istio Ingress Gatewaw の IP アドレスを取得します。これは Istio が LoadBalancer とともにインストールされていることを仮定しています。
CLUSTER_IPS=!(kubectl -n istio-system get service istio-ingressgateway -o jsonpath='{.status.loadBalancer.ingress[0].ip}')
CLUSTER_IP=CLUSTER_IPS[0]
print(CLUSTER_IP)
188.166.139.197
SERVICE_HOSTNAMES=!(kubectl get ksvc vae-outlier -o jsonpath='{.status.url}' | cut -d "/" -f 3)
SERVICE_HOSTNAME_VAEOD=SERVICE_HOSTNAMES[0]
print(SERVICE_HOSTNAME_VAEOD)
vae-outlier.default.example.com
配備されたモデルの予測のために幾つかのユティリティ関数を定義します。
import json
import requests
from typing import Union
classes = ('plane', 'car', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck')
def predict(x: np.ndarray) -> Union[str, list]:
""" Model prediction. """
formData = {
'instances': x.tolist()
}
headers = {}
res = requests.post(
'http://'+CLUSTER_IP+'/seldon/default/tfserving-cifar10/v1/models/resnet32/:predict',
json=formData,
headers=headers
)
if res.status_code == 200:
return classes[np.array(res.json()["predictions"])[0].argmax()]
else:
print("Failed with ",res.status_code)
return []
def outlier(x: np.ndarray) -> Union[dict, list]:
""" Outlier prediction. """
formData = {
'instances': x.tolist()
}
headers = {
"Alibi-Detect-Return-Feature-Score": "true",
"Alibi-Detect-Return-Instance-Score": "true"
}
headers["Host"] = SERVICE_HOSTNAME_VAEOD
res = requests.post('http://'+CLUSTER_IP+'/', json=formData, headers=headers)
if res.status_code == 200:
od = res.json()
od["data"]["feature_score"] = np.array(od["data"]["feature_score"])
od["data"]["instance_score"] = np.array(od["data"]["instance_score"])
return od
else:
print("Failed with ",res.status_code)
return []
def show(x: np.ndarray) -> None:
plt.imshow(x.reshape(32, 32, 3))
plt.axis('off')
plt.show()
元のインスタンス上で予測を行ないましょう :
show(x)
predict(x)

'ship'
外れ値検知器の出力のためにメッセージ dumper を確認しましょう :
res=!kubectl logs $(kubectl get pod -l serving.knative.dev/configuration=message-dumper -o jsonpath='{.items[0].metadata.name}') user-container
data = []
for i in range(0,len(res)):
if res[i] == 'Data,':
data.append(res[i+1])
j = json.loads(json.loads(data[0]))
print("Outlier?",labels[j["data"]["is_outlier"]==[1]])
Outlier? No!
そして摂動されたインスタンスで予測を行ないます :
show(x_mask)
predict(x_mask)

'ship'
予測は依然として正しいですが、インスタンスは明らかに外れ値です :
res=!kubectl logs $(kubectl get pod -l serving.knative.dev/configuration=message-dumper -o jsonpath='{.items[0].metadata.name}') user-container
data= []
for i in range(0,len(res)):
if res[i] == 'Data,':
data.append(res[i+1])
j = json.loads(json.loads(data[1]))
print("Outlier?",labels[j["data"]["is_outlier"]==[1]])
Outlier? Yes!
preds = outlier(x_mask)
plot_feature_outlier_image(preds, x_mask, X_recon=None)

2. 予測確率のマッチングによる敵対的検知
メソッド
敵対的検知器は Adversarial Detection and Correction by Matching Prediction Distributions に基づいています。通常、オートエンコーダは平均二乗再構築誤差のような $x$ と $x’$ の間の類似性を捕捉するのに適する損失関数を用いて、入力インスタンス $x$ を出来る限り正確に再構築するような変換 $T$ を見つけるために訓練されます。敵対的オートエンコーダ (AE) 検知器の新奇性は、オートエンコーダネットワークを訓練するために、モデルの出力空間の距離尺度に基づいた分類モデル依存な損失関数の使用に依存していることです。分類モデル $M$ が与えられたとき、オートエンコーダの重みは $x$ と $x’$ のモデル予測間の KL-ダイバージェンス を最小化するように最適化されます。再構築損失項 $x’$ の存在がない場合には、$x$ と $x’$ の近接性を気に掛けることなく、単純に予測確率 $M(x’)$ と $M(x)$ が一致することを確かなものにしようとします。その結果、$x’$ はモデル $M$ に関する異なる決定境界 shape によって $x$ とは異なる入力特徴空間の異なる領域に存在することが可能になります。$x$ 周りで効果的な注意深く作成された敵対的摂動は特徴空間の $x’$ の新しい位置には転送されませんので、従って攻撃は無力化されます。オートエンコーダの訓練は教師なしです、何故ならばモデル予測確率と通常の訓練インスタンスへのアクセスだけを必要とするからです。基礎となる敵対的攻撃についての知識を必要としません、そして分類器の重みは訓練の間凍結されます。
検知器は以下のように利用できます :
- 敵対的スコア $S$ が計算されます。$S$ は $x$ と $x’$ のモデル予測間の K-L ダイバージェンスに等しいです。
- $S$ が (明示的に定義されたか訓練データから推論された) 閾値を越える場合、インスタンスは敵対的とフラグ立てされます。
- 敵対的インスタンスについては、モデル $M$ は予測を行なうために再構築されたインスタンス $x’$ を使用します。敵対的スコアが閾値の下であれば、モデルは元のインスタンス $x$ 上で予測を行ないます。
この手順は下の図で図示されます :
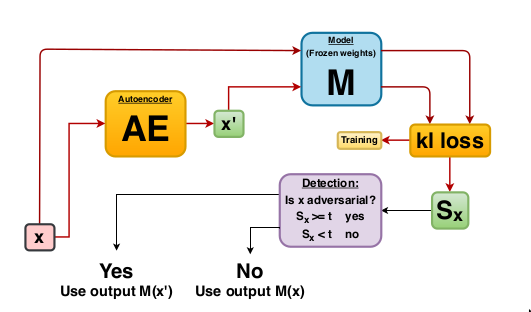
この方法は非常に柔軟で、モデル性能にネガティブな影響を与える一般的なデータ破損と摂動を検出するためにも使用できます。
# more imports
from sklearn.metrics import roc_curve, auc
from alibi_detect.ad import AdversarialAE
from alibi_detect.datasets import fetch_attack
from alibi_detect.utils.fetching import fetch_tf_model
from alibi_detect.utils.prediction import predict_batch
ユティリティ関数
# instance scaling and plotting utility functions
def scale_by_instance(X: np.ndarray) -> np.ndarray:
mean_ = X.mean(axis=(1, 2, 3)).reshape(-1, 1, 1, 1)
std_ = X.std(axis=(1, 2, 3)).reshape(-1, 1, 1, 1)
return (X - mean_) / std_, mean_, std_
def accuracy(y_true: np.ndarray, y_pred: np.ndarray) -> float:
return (y_true == y_pred).astype(int).sum() / y_true.shape[0]
def plot_adversarial(idx: list,
X: np.ndarray,
y: np.ndarray,
X_adv: np.ndarray,
y_adv: np.ndarray,
mean: np.ndarray,
std: np.ndarray,
score_x: np.ndarray = None,
score_x_adv: np.ndarray = None,
X_recon: np.ndarray = None,
y_recon: np.ndarray = None,
figsize: tuple = (10, 5)) -> None:
# category map from class numbers to names
cifar10_map = {0: 'airplane', 1: 'automobile', 2: 'bird', 3: 'cat', 4: 'deer', 5: 'dog',
6: 'frog', 7: 'horse', 8: 'ship', 9: 'truck'}
nrows = len(idx)
ncols = 3 if isinstance(X_recon, np.ndarray) else 2
fig, ax = plt.subplots(nrows=nrows, ncols=ncols, figsize=figsize)
n_subplot = 1
for i in idx:
# rescale images in [0, 1]
X_adj = (X[i] * std[i] + mean[i]) / 255
X_adv_adj = (X_adv[i] * std[i] + mean[i]) / 255
if isinstance(X_recon, np.ndarray):
X_recon_adj = (X_recon[i] * std[i] + mean[i]) / 255
# original image
plt.subplot(nrows, ncols, n_subplot)
plt.axis('off')
if i == idx[0]:
if isinstance(score_x, np.ndarray):
plt.title('CIFAR-10 Image \n{}: {:.3f}'.format(cifar10_map[y[i]], score_x[i]))
else:
plt.title('CIFAR-10 Image \n{}'.format(cifar10_map[y[i]]))
else:
if isinstance(score_x, np.ndarray):
plt.title('{}: {:.3f}'.format(cifar10_map[y[i]], score_x[i]))
else:
plt.title('{}'.format(cifar10_map[y[i]]))
plt.imshow(X_adj)
n_subplot += 1
# adversarial image
plt.subplot(nrows, ncols, n_subplot)
plt.axis('off')
if i == idx[0]:
if isinstance(score_x_adv, np.ndarray):
plt.title('Adversarial \n{}: {:.3f}'.format(cifar10_map[y_adv[i]], score_x_adv[i]))
else:
plt.title('Adversarial \n{}'.format(cifar10_map[y_adv[i]]))
else:
if isinstance(score_x_adv, np.ndarray):
plt.title('{}: {:.3f}'.format(cifar10_map[y_adv[i]], score_x_adv[i]))
else:
plt.title('{}'.format(cifar10_map[y_adv[i]]))
plt.imshow(X_adv_adj)
n_subplot += 1
# reconstructed image
if isinstance(X_recon, np.ndarray):
plt.subplot(nrows, ncols, n_subplot)
plt.axis('off')
if i == idx[0]:
plt.title('AE Reconstruction \n{}'.format(cifar10_map[y_recon[i]]))
else:
plt.title('{}'.format(cifar10_map[y_recon[i]]))
plt.imshow(X_recon_adj)
n_subplot += 1
plt.show()
def plot_roc(roc_data: dict, figsize: tuple = (10,5)):
plot_labels = []
scores_attacks = []
labels_attacks = []
for k, v in roc_data.items():
if 'original' in k:
continue
score_x = roc_data[v['normal']]['scores']
y_pred = roc_data[v['normal']]['predictions']
score_v = v['scores']
y_pred_v = v['predictions']
labels_v = np.ones(score_x.shape[0])
idx_remove = np.where(y_pred == y_pred_v)[0]
labels_v = np.delete(labels_v, idx_remove)
score_v = np.delete(score_v, idx_remove)
scores = np.concatenate([score_x, score_v])
labels = np.concatenate([np.zeros(y_pred.shape[0]), labels_v]).astype(int)
scores_attacks.append(scores)
labels_attacks.append(labels)
plot_labels.append(k)
for sc_att, la_att, plt_la in zip(scores_attacks, labels_attacks, plot_labels):
fpr, tpr, thresholds = roc_curve(la_att, sc_att)
roc_auc = auc(fpr, tpr)
label = str('{}: AUC = {:.2f}'.format(plt_la, roc_auc))
plt.plot(fpr, tpr, lw=1, label='{}: AUC={:.4f}'.format(plt_la, roc_auc))
plt.plot([0, 1], [0, 1], color='black', lw=1, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('{}'.format('ROC curve'))
plt.legend(loc="lower right", ncol=1)
plt.grid()
plt.show()
データをリスケールする
ResNet 分類モデルはインスタンスにより標準化されたデータ上で訓練されます :
# rescale data
X_train, mean_train, std_train = scale_by_instance(X_train * 255.)
X_test, mean_test, std_test = scale_by_instance(X_test * 255.)
scale = (mean_train, std_train), (mean_test, std_test)
事前訓練済みの分類器をロードする
dataset = 'cifar10'
model = 'resnet56'
clf = fetch_tf_model(dataset, model)
テスト上の予測を確認します :
y_pred = predict_batch(clf, X_test, batch_size=32, return_class=True)
acc_y_pred = accuracy(y_test, y_pred)
print('Accuracy: {:.4f}'.format(acc_y_pred))
Accuracy: 0.9315
敵対的攻撃
Carlini-Wagner (C&W) と SLIDE 攻撃の両者を調査します。以前に見つかった敵対的なインスタンスを事前訓練済みの ResNet-56 モデル上に単純にロードできます。攻撃は Foolbox を使用して生成されます :
# C&W attack
data_cw = fetch_attack(dataset, model, 'cw')
X_train_cw, X_test_cw = data_cw['data_train'], data_cw['data_test']
meta_cw = data_cw['meta'] # metadata with hyperparameters of the attack
# SLIDE attack
data_slide = fetch_attack(dataset, model, 'slide')
X_train_slide, X_test_slide = data_slide['data_train'], data_slide['data_test']
meta_slide = data_slide['meta']
分類器の精度が殆ど 0% に低下することを検証できます :
y_pred_cw = predict_batch(clf, X_test_cw, batch_size=32, return_class=True)
y_pred_slide = predict_batch(clf, X_test_slide, batch_size=32, return_class=True)
acc_y_pred_cw = accuracy(y_test, y_pred_cw)
acc_y_pred_slide = accuracy(y_test, y_pred_slide)
print('Accuracy: cw {:.4f} -- SLIDE {:.4f}'.format(acc_y_pred_cw, acc_y_pred_slide))
Accuracy: cw 0.0000 -- SLIDE 0.0001
幾つかの敵対的インスタンスを可視化しましょう :
# plot attacked instances
idx = [3, 4]
print('C&W attack...')
plot_adversarial(idx, X_test, y_pred, X_test_cw, y_pred_cw,
mean_test, std_test, figsize=(10, 10))
print('SLIDE attack...')
plot_adversarial(idx, X_test, y_pred, X_test_slide, y_pred_slide,
mean_test, std_test, figsize=(10, 10))
C&W 攻撃 …

SLIDE 攻撃 …

敵対的検知器をロードまたは訓練して評価する
Google Cloud Bucket から事前訓練済みの検知器を再度取得するかスクラッチから訓練できます :
load_pretrained = False
filepath = os.path.join(os.getcwd(), 'adversarial')
if load_pretrained:
detector_type = 'adversarial'
detector_name = 'base'
ad = fetch_detector(filepath, detector_type, dataset, detector_name, model=model)
filepath = os.path.join(filepath, detector_name)
else: # train detector from scratch
# define encoder and decoder networks
encoder_net = tf.keras.Sequential(
[
InputLayer(input_shape=(32, 32, 3)),
Conv2D(32, 4, strides=2, padding='same',
activation=tf.nn.relu, kernel_regularizer=l1(1e-5)),
Conv2D(64, 4, strides=2, padding='same',
activation=tf.nn.relu, kernel_regularizer=l1(1e-5)),
Conv2D(256, 4, strides=2, padding='same',
activation=tf.nn.relu, kernel_regularizer=l1(1e-5)),
Flatten(),
Dense(40)
]
)
decoder_net = tf.keras.Sequential(
[
InputLayer(input_shape=(40,)),
Dense(4 * 4 * 128, activation=tf.nn.relu),
Reshape(target_shape=(4, 4, 128)),
Conv2DTranspose(256, 4, strides=2, padding='same',
activation=tf.nn.relu, kernel_regularizer=l1(1e-5)),
Conv2DTranspose(64, 4, strides=2, padding='same',
activation=tf.nn.relu, kernel_regularizer=l1(1e-5)),
Conv2DTranspose(3, 4, strides=2, padding='same',
activation=None, kernel_regularizer=l1(1e-5))
]
)
# initialise and train detector
ad = AdversarialAE(
encoder_net=encoder_net,
decoder_net=decoder_net,
model=clf
)
ad.fit(X_train, epochs=40, batch_size=64, verbose=True)
# save the trained adversarial detector
save_detector(ad, filepath)
検知器は最初に敵対的であり得る入力インスタンスを再構築します。そして再構築された入力は敵対的スコアを計算するために分類器に供給されます。スコアが閾値より上の場合、インスタンスは敵対的と分類されて検知器は攻撃を正そうとします。攻撃されたインスタンスを再構築してその上で予測を行なうとき何が起きるかを調べましょう :
X_recon_cw = predict_batch(ad.ae, X_test_cw, batch_size=32)
X_recon_slide = predict_batch(ad.ae, X_test_slide, batch_size=32)
y_recon_cw = predict_batch(clf, X_recon_cw, batch_size=32, return_class=True)
y_recon_slide = predict_batch(clf, X_recon_slide, batch_size=32, return_class=True)
攻撃された (インスタンス) vs. 再構築されたインスタンスの精度 :
acc_y_recon_cw = accuracy(y_test, y_recon_cw)
acc_y_recon_slide = accuracy(y_test, y_recon_slide)
print('Accuracy after C&W attack {:.4f} -- reconstruction {:.4f}'.format(acc_y_pred_cw, acc_y_recon_cw))
print('Accuracy after SLIDE attack {:.4f} -- reconstruction {:.4f}'.format(acc_y_pred_slide, acc_y_recon_slide))
Accuracy after C&W attack 0.0000 -- reconstruction 0.8048 Accuracy after SLIDE attack 0.0001 -- reconstruction 0.8159
検知器は攻撃後の精度を殆ど 0 % から 80% を上手く越えるまでに復旧します!攻撃的スコアを計算して再構築されたインスタンスの幾つかを調査できます :
score_x = ad.score(X_test, batch_size=32)
score_cw = ad.score(X_test_cw, batch_size=32)
score_slide = ad.score(X_test_slide, batch_size=32)
# visualize original, attacked and reconstructed instances with adversarial scores
print('C&W attack...')
idx = [10, 13, 14, 16, 17]
plot_adversarial(idx, X_test, y_pred, X_test_cw, y_pred_cw, mean_test, std_test,
score_x=score_x, score_x_adv=score_cw, X_recon=X_recon_cw,
y_recon=y_recon_cw, figsize=(10, 15))
print('SLIDE attack...')
idx = [23, 25, 27, 29, 34]
plot_adversarial(idx, X_test, y_pred, X_test_slide, y_pred_slide, mean_test, std_test,
score_x=score_x, score_x_adv=score_slide, X_recon=X_recon_slide,
y_recon=y_recon_slide, figsize=(10, 15))
C&W 攻撃 …

SLIDE 攻撃 …

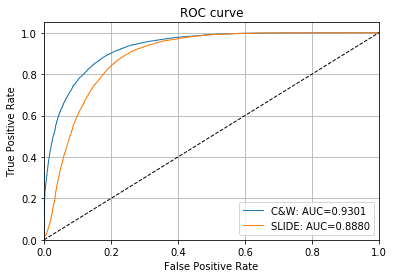
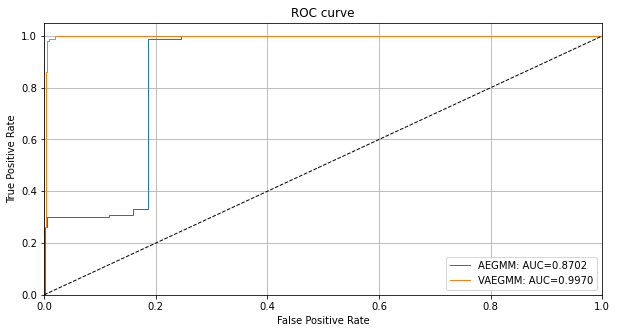
ROC カーブと AUC 値は敵対的インスタンスを検知するための敵対的スコアの有効性を示します :
# plot roc curve
roc_data = {
'original': {'scores': score_x, 'predictions': y_pred},
'C&W': {'scores': score_cw, 'predictions': y_pred_cw, 'normal': 'original'},
'SLIDE': {'scores': score_slide, 'predictions': y_pred_slide, 'normal': 'original'}
}
plot_roc(roc_data)
敵対的スコアのための閾値は infer_threshold を通して設定できます。インスタンスのバッチ X を渡してそれらの何パーセントを正常であると考えるかを threshold_perc を通して指定する必要があります。Assume we have only normal instances some of which the model has misclassified leading to a higher score if the reconstruction picked up features from the correct class or some might look adversarial in the first place. その結果、閾値を 95% に設定します :
ad.infer_threshold(X_test, threshold_perc=95, margin=0., batch_size=32)
print('Adversarial threshold: {:.4f}'.format(ad.threshold))
Adversarial threshold: 2.6722
検知器の正しい方法は Figure 1 の図を実行します。最初に敵対的スコアが計算されます。スコアが閾値を越えるインスタンスについては、再構築されたインスタンスの分類器予測が返されます。そうでなければ元の予測が保持されます。このメソッドは検知器のメタデータ、(バッチのインスタンスが敵対的であろうとなかろうと、) 訂正メカニズムを使用した分類器予測、そして元の予測と再構築された予測の両者を含む辞書を返します。幾つかの敵対的 (インスタンス) そして元のテストセットのインスタンスを含むバッチでこれを示しましょう :
n_test = X_test.shape[0]
np.random.seed(0)
idx_normal = np.random.choice(n_test, size=1600, replace=False)
idx_cw = np.random.choice(n_test, size=400, replace=False)
X_mix = np.concatenate([X_test[idx_normal], X_test_cw[idx_cw]])
y_mix = np.concatenate([y_test[idx_normal], y_test[idx_cw]])
print(X_mix.shape, y_mix.shape)
(2000, 32, 32, 3) (2000,)
モデル性能を確認しましょう :
y_pred_mix = predict_batch(clf, X_mix, batch_size=32, return_class=True)
acc_y_pred_mix = accuracy(y_mix, y_pred_mix)
print('Accuracy {:.4f}'.format(acc_y_pred_mix))
Accuracy 0.7380
これは訂正メカニズムで改良できます :
preds = ad.correct(X_mix, batch_size=32)
acc_y_corr_mix = accuracy(y_mix, preds['data']['corrected'])
print('Accuracy {:.4f}'.format(acc_y_corr_mix))
Accuracy 0.8205
論文 でハイライトされていて (temperature スケーリング と 隠れ層 K-L ダイバージェンス) Alibi Detect で実装されている幾つかの他のトリックがあります、これは敵対的検知器の性能を更にブーストできます。より詳細については この example ノートブック を確認してください。
以上
Alibi Detect 0.7 : Examples : AE 外れ値検知 on CIFAR10
Alibi Detect 0.7 : Examples : AE 外れ値検知 on CIFAR10 (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 07/04/2021 (0.7.0)
* 本ページは、Alibi Detect の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。
スケジュールは弊社 公式 Web サイト でご確認頂けます。
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
| 人工知能研究開発支援 | 人工知能研修サービス | テレワーク & オンライン授業を支援 |
| PoC(概念実証)を失敗させないための支援 (本支援はセミナーに参加しアンケートに回答した方を対象としています。) | ||
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |
Alibi Detect 0.7 : Examples : AE 外れ値検知 on CIFAR10
オートエンコーダ – 概要
オートエンコーダ (AE, Auto-Encoder) 外れ値検知器はラベル付けされていない、しかし通常 (inlier) データのバッチで最初に訓練されます。教師なし訓練が望ましいです、何故ならばラベル付けされたデータはしばしば十分でないからです。AE 検知器はそれが受け取る入力を再構築しようとします。入力データが上手く再構築されない場合、再構築エラーは高くそしてデータは外れ値としてフラグ立てできます。再構築エラーは入力と再構築されたインスタンスの間の平均二乗誤差 (MSE, mean squared error) として測定されます。
データセット
CIFAR10 は 10 クラスに渡り均等に分配された 60,000 の 32 x 32 RGB 画像から成ります。
import logging
import matplotlib.pyplot as plt
import numpy as np
import os
import tensorflow as tf
tf.keras.backend.clear_session()
from tensorflow.keras.layers import Conv2D, Conv2DTranspose, \
Dense, Layer, Reshape, InputLayer, Flatten
from tqdm import tqdm
from alibi_detect.od import OutlierAE
from alibi_detect.utils.fetching import fetch_detector
from alibi_detect.utils.perturbation import apply_mask
from alibi_detect.utils.saving import save_detector, load_detector
from alibi_detect.utils.visualize import plot_instance_score, plot_feature_outlier_image
logger = tf.get_logger()
logger.setLevel(logging.ERROR)
CIFAR10 データをロードする
train, test = tf.keras.datasets.cifar10.load_data()
X_train, y_train = train
X_test, y_test = test
X_train = X_train.astype('float32') / 255
X_test = X_test.astype('float32') / 255
print(X_train.shape, y_train.shape, X_test.shape, y_test.shape)
(50000, 32, 32, 3) (50000, 1) (10000, 32, 32, 3) (10000, 1)
外れ値検知器をロードまたは定義する
examples ノートブックで使用される事前訓練済みの外れ値と敵対的検知器は ここ で見つかります。組込みの fetch_detector 関数を利用できます、これは事前訓練モデルをローカルディレクトリ filepath にセーブして検知器をロードします。代わりに、スクラッチから検知器を訓練することができます :
load_outlier_detector = False
filepath = 'model_ae_cifar10' # change to (absolute) directory where model is downloaded
if load_outlier_detector: # load pretrained outlier detector
detector_type = 'outlier'
dataset = 'cifar10'
detector_name = 'OutlierAE'
od = fetch_detector(filepath, detector_type, dataset, detector_name)
filepath = os.path.join(filepath, detector_name)
else: # define model, initialize, train and save outlier detector
encoding_dim = 1024
encoder_net = tf.keras.Sequential(
[
InputLayer(input_shape=(32, 32, 3)),
Conv2D(64, 4, strides=2, padding='same', activation=tf.nn.relu),
Conv2D(128, 4, strides=2, padding='same', activation=tf.nn.relu),
Conv2D(512, 4, strides=2, padding='same', activation=tf.nn.relu),
Flatten(),
Dense(encoding_dim,)
])
decoder_net = tf.keras.Sequential(
[
InputLayer(input_shape=(encoding_dim,)),
Dense(4*4*128),
Reshape(target_shape=(4, 4, 128)),
Conv2DTranspose(256, 4, strides=2, padding='same', activation=tf.nn.relu),
Conv2DTranspose(64, 4, strides=2, padding='same', activation=tf.nn.relu),
Conv2DTranspose(3, 4, strides=2, padding='same', activation='sigmoid')
])
# initialize outlier detector
od = OutlierAE(threshold=.015, # threshold for outlier score
encoder_net=encoder_net, # can also pass AE model instead
decoder_net=decoder_net, # of separate encoder and decoder
)
# train
od.fit(X_train,
epochs=50,
verbose=True)
# save the trained outlier detector
save_detector(od, filepath)
AE モデルの品質を確認する
idx = 8
X = X_train[idx].reshape(1, 32, 32, 3)
X_recon = od.ae(X)
plt.imshow(X.reshape(32, 32, 3))
plt.axis('off')
plt.show()

plt.imshow(X_recon.numpy().reshape(32, 32, 3))
plt.axis('off')
plt.show()

元の CIFAR10 画像の外れ値を確認する
X = X_train[:500]
print(X.shape)
(500, 32, 32, 3)
od_preds = od.predict(X,
outlier_type='instance', # use 'feature' or 'instance' level
return_feature_score=True, # scores used to determine outliers
return_instance_score=True)
print(list(od_preds['data'].keys()))
['instance_score', 'feature_score', 'is_outlier']
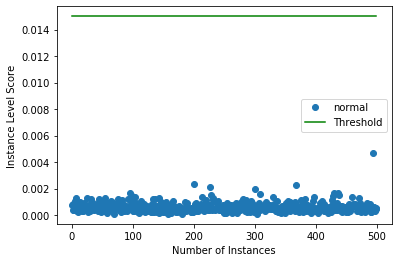
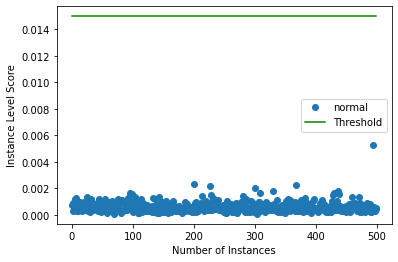
インスタンスレベルの外れ値スコアをプロットする
target = np.zeros(X.shape[0],).astype(int) # all normal CIFAR10 training instances
labels = ['normal', 'outlier']
plot_instance_score(od_preds, target, labels, od.threshold)
予測を可視化する
X_recon = od.ae(X).numpy()
plot_feature_outlier_image(od_preds,
X,
X_recon=X_recon,
instance_ids=[8, 60, 100, 330], # pass a list with indices of instances to display
max_instances=5, # max nb of instances to display
outliers_only=False) # only show outlier predictions

摂動された CIFAR 画像で外れ値を予測する
CIFAR 画像を画像のパッチ (マスク) にランダムノイズを追加することにより摂動させます。n_mask_sizes の各マスクサイズについて、n_masks をサンプリングしてそれらを n_imgs 画像の各々に適用します。そしてマスクされたインスタンスで外れ値を予測します :
# nb of predictions per image: n_masks * n_mask_sizes
n_mask_sizes = 10
n_masks = 20
n_imgs = 50
マスクを定義して画像を取得します :
mask_sizes = [(2*n,2*n) for n in range(1,n_mask_sizes+1)]
print(mask_sizes)
img_ids = np.arange(n_imgs)
X_orig = X[img_ids].reshape(img_ids.shape[0], 32, 32, 3)
print(X_orig.shape)
[(2, 2), (4, 4), (6, 6), (8, 8), (10, 10), (12, 12), (14, 14), (16, 16), (18, 18), (20, 20)] (50, 32, 32, 3)
インスタンスレベルの外れ値スコアを計算します :
all_img_scores = []
for i in tqdm(range(X_orig.shape[0])):
img_scores = np.zeros((len(mask_sizes),))
for j, mask_size in enumerate(mask_sizes):
# create masked instances
X_mask, mask = apply_mask(X_orig[i].reshape(1, 32, 32, 3),
mask_size=mask_size,
n_masks=n_masks,
channels=[0,1,2],
mask_type='normal',
noise_distr=(0,1),
clip_rng=(0,1))
# predict outliers
od_preds_mask = od.predict(X_mask)
score = od_preds_mask['data']['instance_score']
# store average score over `n_masks` for a given mask size
img_scores[j] = np.mean(score)
all_img_scores.append(img_scores)
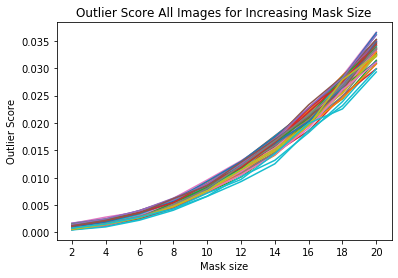
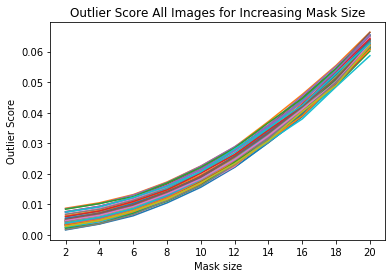
外れ値スコア vs. マスクサイズを可視化する
x_plt = [mask[0] for mask in mask_sizes]
for ais in all_img_scores:
plt.plot(x_plt, ais)
plt.xticks(x_plt)
plt.title('Outlier Score All Images for Increasing Mask Size')
plt.xlabel('Mask size')
plt.ylabel('Outlier Score')
plt.show()
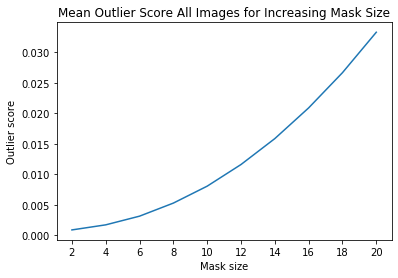
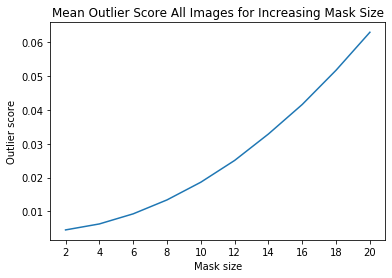
ais_np = np.zeros((len(all_img_scores), all_img_scores[0].shape[0]))
for i, ais in enumerate(all_img_scores):
ais_np[i, :] = ais
ais_mean = np.mean(ais_np, axis=0)
plt.title('Mean Outlier Score All Images for Increasing Mask Size')
plt.xlabel('Mask size')
plt.ylabel('Outlier score')
plt.plot(x_plt, ais_mean)
plt.xticks(x_plt)
plt.show()
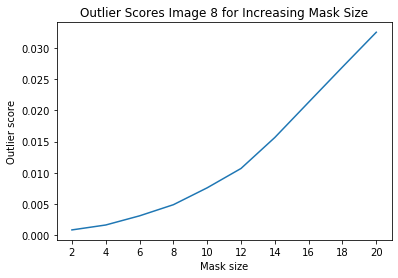
インスタンスレベルの外れ値を調査する
i = 8 # index of instance to look at
plt.plot(x_plt, all_img_scores[i])
plt.xticks(x_plt)
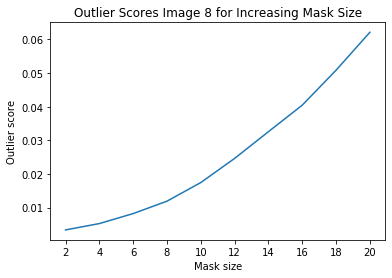
plt.title('Outlier Scores Image {} for Increasing Mask Size'.format(i))
plt.xlabel('Mask size')
plt.ylabel('Outlier score')
plt.show()
マスクされた画像の再構築とチャネル毎の外れ値スコア :
all_X_mask = []
X_i = X_orig[i].reshape(1, 32, 32, 3)
all_X_mask.append(X_i)
# apply masks
for j, mask_size in enumerate(mask_sizes):
# create masked instances
X_mask, mask = apply_mask(X_i,
mask_size=mask_size,
n_masks=1, # just 1 for visualization purposes
channels=[0,1,2],
mask_type='normal',
noise_distr=(0,1),
clip_rng=(0,1))
all_X_mask.append(X_mask)
all_X_mask = np.concatenate(all_X_mask, axis=0)
all_X_recon = od.ae(all_X_mask).numpy()
od_preds = od.predict(all_X_mask)
可視化します :
plot_feature_outlier_image(od_preds,
all_X_mask,
X_recon=all_X_recon,
max_instances=all_X_mask.shape[0],
n_channels=3)

特徴のサブセットで外れ値を予測する
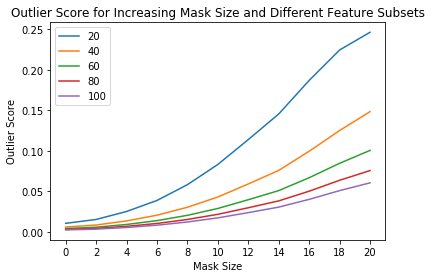
外れ値検知器の sensitivity (感度) は閾値を通してだけでなくインスタンスレベルの外れ値スコア計算のために使用される特徴のパーセンテージを選択することによっても制御できます。例えば、特徴の 40% が閾値を越える平均外れ値スコアを持つ場合外れ値であるとフラグ立てすることを望むかもしれません。これは predict 関数の outlier_perc 引数を通して可能です。それは降順の外れ値スコア順序でソートされた、外れ値検知のために使用される特徴のパーセンテージを指定します。
perc_list = [20, 40, 60, 80, 100]
all_perc_scores = []
for perc in perc_list:
od_preds_perc = od.predict(all_X_mask, outlier_perc=perc)
iscore = od_preds_perc['data']['instance_score']
all_perc_scores.append(iscore)
外れ値スコア vs. マスクサイズと使用された特徴サイズのパーセンテージを可視化します :
x_plt = [0] + x_plt
for aps in all_perc_scores:
plt.plot(x_plt, aps)
plt.xticks(x_plt)
plt.legend(perc_list)
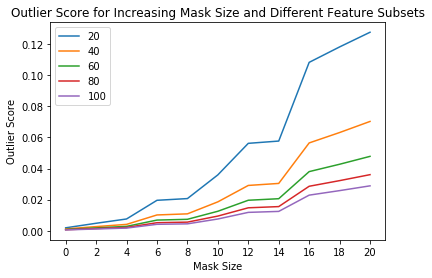
plt.title('Outlier Score for Increasing Mask Size and Different Feature Subsets')
plt.xlabel('Mask Size')
plt.ylabel('Outlier Score')
plt.show()
外れ値の閾値を推論する
良い閾値を見つけることは技巧的であり得ます、何故ならばそれらは典型的には解釈することが容易でないからです。infer_threshold メソッドは sensible な値を見つけるのに役立ちます。インスタンスのバッチ X を渡してそれらの何パーセントを正常であると考えるかを threshold_perc を通して指定する必要があります。
print('Current threshold: {}'.format(od.threshold))
od.infer_threshold(X, threshold_perc=99) # assume 1% of the training data are outliers
print('New threshold: {}'.format(od.threshold))
Current threshold: 0.015 New threshold: 0.0017021061840932791
以上
Alibi Detect 0.7 : Examples : VAE 外れ値検知 on CIFAR10
Alibi Detect 0.7 : Examples : VAE 外れ値検知 on CIFAR10 (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 07/04/2021 (0.7.0)
* 本ページは、Alibi Detect の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。
スケジュールは弊社 公式 Web サイト でご確認頂けます。
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
| 人工知能研究開発支援 | 人工知能研修サービス | テレワーク & オンライン授業を支援 |
| PoC(概念実証)を失敗させないための支援 (本支援はセミナーに参加しアンケートに回答した方を対象としています。) | ||
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |

Alibi Detect 0.7 : Examples : VAE 外れ値検知 on CIFAR10
VAE – 概要
変分オートエンコーダ (VAE, Variational Auto-Encoder) 外れ値検知器は最初にラベル付けされていない、しかし通常 (inlier) データのバッチで訓練されます。教師なしか半教師あり訓練が望ましいです、何故ならばラベル付けされたデータはしばしば十分でないからです。VAE 検知器はそれが受け取る入力を再構築しようとします。入力データが上手く再構築されない場合、再構築エラーは高くそしてデータは外れ値としてフラグ立てできます。再構築エラーは、入力と再構築されたインスタンスの間の平均二乗誤差 (MSE, mean squared error) か、入力と再構築されたインスタンスの両者が同じプロセスで生成される確率として測定されます。アルゴリズムは表形式か画像データのために適合します。
データセット
CIFAR10 は 10 クラスに渡り均等に分配された 60,000 の 32 x 32 RGB 画像から成ります。
import logging
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
tf.keras.backend.clear_session()
from tensorflow.keras.layers import Conv2D, Conv2DTranspose, Dense, Layer, Reshape, InputLayer
from tqdm import tqdm
from alibi_detect.models.tensorflow.losses import elbo
from alibi_detect.od import OutlierVAE
from alibi_detect.utils.fetching import fetch_detector
from alibi_detect.utils.perturbation import apply_mask
from alibi_detect.utils.saving import save_detector, load_detector
from alibi_detect.utils.visualize import plot_instance_score, plot_feature_outlier_image
logger = tf.get_logger()
logger.setLevel(logging.ERROR)
CIFAR10 データをロードする
train, test = tf.keras.datasets.cifar10.load_data()
X_train, y_train = train
X_test, y_test = test
X_train = X_train.astype('float32') / 255
X_test = X_test.astype('float32') / 255
print(X_train.shape, y_train.shape, X_test.shape, y_test.shape)
(50000, 32, 32, 3) (50000, 1) (10000, 32, 32, 3) (10000, 1)
外れ値検知器をロードまたは定義する
examples ノートブックで使用される事前訓練済みの外れ値と敵対的検知器は ここ で見つかります。組込みの fetch_detector 関数を利用できます、これは事前訓練モデルをローカルディレクトリ filepath にセーブして検知器をロードします。代わりに、スクラッチから検知器を訓練することができます :
load_outlier_detector = False
filepath = 'model_vae_cifar10' # change to directory where model is downloaded
if load_outlier_detector: # load pretrained outlier detector
detector_type = 'outlier'
dataset = 'cifar10'
detector_name = 'OutlierVAE'
od = fetch_detector(filepath, detector_type, dataset, detector_name)
filepath = os.path.join(filepath, detector_name)
else: # define model, initialize, train and save outlier detector
latent_dim = 1024
encoder_net = tf.keras.Sequential(
[
InputLayer(input_shape=(32, 32, 3)),
Conv2D(64, 4, strides=2, padding='same', activation=tf.nn.relu),
Conv2D(128, 4, strides=2, padding='same', activation=tf.nn.relu),
Conv2D(512, 4, strides=2, padding='same', activation=tf.nn.relu)
])
decoder_net = tf.keras.Sequential(
[
InputLayer(input_shape=(latent_dim,)),
Dense(4*4*128),
Reshape(target_shape=(4, 4, 128)),
Conv2DTranspose(256, 4, strides=2, padding='same', activation=tf.nn.relu),
Conv2DTranspose(64, 4, strides=2, padding='same', activation=tf.nn.relu),
Conv2DTranspose(3, 4, strides=2, padding='same', activation='sigmoid')
])
# initialize outlier detector
od = OutlierVAE(threshold=.015, # threshold for outlier score
score_type='mse', # use MSE of reconstruction error for outlier detection
encoder_net=encoder_net, # can also pass VAE model instead
decoder_net=decoder_net, # of separate encoder and decoder
latent_dim=latent_dim,
samples=2)
# train
od.fit(X_train,
loss_fn=elbo,
cov_elbo=dict(sim=.05),
epochs=50,
verbose=True)
# save the trained outlier detector
save_detector(od, filepath)
(訳注 : TF 2.5.0, 8 vCPUs)
782/782 [=] - 200s 254ms/step - loss: 3261.4951 782/782 [=] - 199s 254ms/step - loss: -2490.5888 782/782 [=] - 199s 254ms/step - loss: -3502.6840 782/782 [=] - 203s 259ms/step - loss: -3973.3844 782/782 [=] - 203s 259ms/step - loss: -4287.5373 782/782 [=] - 202s 258ms/step - loss: -4530.9941 782/782 [=] - 202s 257ms/step - loss: -4697.7253 782/782 [=] - 202s 257ms/step - loss: -4847.7671 782/782 [=] - 203s 260ms/step - loss: -4976.0743 782/782 [=] - 198s 253ms/step - loss: -5082.4453 782/782 [=] - 200s 254ms/step - loss: -5159.3614 782/782 [=] - 203s 259ms/step - loss: -5219.0779 782/782 [=] - 200s 255ms/step - loss: -5276.2153 782/782 [=] - 201s 256ms/step - loss: -5351.2658 782/782 [=] - 201s 257ms/step - loss: -5400.3945 782/782 [=] - 203s 258ms/step - loss: -5440.3792 (打ち切り)
(訳注 : TF 2.4.1, NVIDIA T4 GPU)
782/782 [=] - 39s 36ms/step - loss: 2861.8008 782/782 [=] - 29s 36ms/step - loss: -2660.4216 782/782 [=] - 29s 36ms/step - loss: -3656.3224 782/782 [=] - 29s 36ms/step - loss: -4132.3934 782/782 [=] - 29s 36ms/step - loss: -4442.0791 782/782 [=] - 29s 36ms/step - loss: -4647.3034 782/782 [=] - 29s 36ms/step - loss: -4835.5262 782/782 [=] - 29s 36ms/step - loss: -4972.2206 782/782 [=] - 29s 36ms/step - loss: -5072.7729 782/782 [=] - 29s 37ms/step - loss: -5150.4993 782/782 [=] - 29s 36ms/step - loss: -5216.9460 782/782 [=] - 29s 37ms/step - loss: -5288.1443 782/782 [=] - 29s 36ms/step - loss: -5347.1787 782/782 [=] - 29s 36ms/step - loss: -5415.1764 782/782 [=] - 29s 36ms/step - loss: -5458.5443 782/782 [=] - 29s 36ms/step - loss: -5507.7469 782/782 [=] - 29s 36ms/step - loss: -5530.3080 782/782 [=] - 29s 36ms/step - loss: -5575.4234 782/782 [=] - 29s 36ms/step - loss: -5614.9955 782/782 [=] - 29s 36ms/step - loss: -5635.2912 782/782 [=] - 29s 36ms/step - loss: -5672.6891 782/782 [=] - 29s 36ms/step - loss: -5689.9361 782/782 [=] - 29s 36ms/step - loss: -5719.1222 782/782 [=] - 29s 37ms/step - loss: -5734.5167 782/782 [=] - 29s 37ms/step - loss: -5761.0373 782/782 [=] - 29s 36ms/step - loss: -5770.7223 782/782 [=] - 29s 36ms/step - loss: -5797.3944 782/782 [=] - 29s 36ms/step - loss: -5813.8093 782/782 [=] - 29s 36ms/step - loss: -5825.7507 782/782 [=] - 29s 36ms/step - loss: -5842.4082 782/782 [=] - 29s 36ms/step - loss: -5852.7256 782/782 [=] - 29s 36ms/step - loss: -5870.8946 782/782 [=] - 29s 36ms/step - loss: -5877.0400 782/782 [=] - 29s 36ms/step - loss: -5887.7013 782/782 [=] - 29s 36ms/step - loss: -5898.9985 782/782 [=] - 29s 36ms/step - loss: -5910.3501 782/782 [=] - 29s 36ms/step - loss: -5918.1856 782/782 [=] - 29s 36ms/step - loss: -5930.0882 782/782 [=] - 29s 36ms/step - loss: -5940.8020 782/782 [=] - 29s 36ms/step - loss: -5944.5714 782/782 [=] - 29s 36ms/step - loss: -5952.0312 782/782 [=] - 29s 36ms/step - loss: -5963.3228 782/782 [=] - 29s 36ms/step - loss: -5966.7727 782/782 [=] - 29s 36ms/step - loss: -5970.3328 782/782 [=] - 29s 36ms/step - loss: -5976.2218 782/782 [=] - 29s 36ms/step - loss: -5977.2582 782/782 [=] - 29s 36ms/step - loss: -5990.5260 782/782 [=] - 29s 36ms/step - loss: -5997.9227 782/782 [=] - 29s 36ms/step - loss: -6001.5070 782/782 [=] - 29s 36ms/step - loss: -6005.6862
VAE モデルの品質を確認する
idx = 8
X = X_train[idx].reshape(1, 32, 32, 3)
X_recon = od.vae(X)
plt.imshow(X.reshape(32, 32, 3))
plt.axis('off')
plt.show()

plt.imshow(X_recon.numpy().reshape(32, 32, 3))
plt.axis('off')
plt.show()

元の CIFAR 画像で外れ値を確認する
X = X_train[:500]
print(X.shape)
(500, 32, 32, 3)
od_preds = od.predict(X,
outlier_type='instance', # use 'feature' or 'instance' level
return_feature_score=True, # scores used to determine outliers
return_instance_score=True)
print(list(od_preds['data'].keys()))
['instance_score', 'feature_score', 'is_outlier']
インスタンスレベルの外れ値スコアをプロットする
target = np.zeros(X.shape[0],).astype(int) # all normal CIFAR10 training instances
labels = ['normal', 'outlier']
plot_instance_score(od_preds, target, labels, od.threshold)
予測を可視化する
X_recon = od.vae(X).numpy()
plot_feature_outlier_image(od_preds,
X,
X_recon=X_recon,
instance_ids=[8, 60, 100, 330], # pass a list with indices of instances to display
max_instances=5, # max nb of instances to display
outliers_only=False) # only show outlier predictions

(訳注 : 下は実験結果)
摂動された CIFAR 画像で外れ値を予測する
CIFAR 画像を画像のパッチ (マスク) にランダムノイズを追加することにより摂動させます。n_mask_sizes の各マスクサイズについて、n_masks をサンプリングしてそれらを n_imgs 画像の各々に適用します。そしてマスクされたインスタンスで外れ値を予測します :
# nb of predictions per image: n_masks * n_mask_sizes
n_mask_sizes = 10
n_masks = 20
n_imgs = 50
マスクを定義して画像を得る :
mask_sizes = [(2*n,2*n) for n in range(1,n_mask_sizes+1)]
print(mask_sizes)
img_ids = np.arange(n_imgs)
X_orig = X[img_ids].reshape(img_ids.shape[0], 32, 32, 3)
print(X_orig.shape)
[(2, 2), (4, 4), (6, 6), (8, 8), (10, 10), (12, 12), (14, 14), (16, 16), (18, 18), (20, 20)] (50, 32, 32, 3)
インスタンスレベルの外れ値スコアを計算します :
all_img_scores = []
for i in tqdm(range(X_orig.shape[0])):
img_scores = np.zeros((len(mask_sizes),))
for j, mask_size in enumerate(mask_sizes):
# create masked instances
X_mask, mask = apply_mask(X_orig[i].reshape(1, 32, 32, 3),
mask_size=mask_size,
n_masks=n_masks,
channels=[0,1,2],
mask_type='normal',
noise_distr=(0,1),
clip_rng=(0,1))
# predict outliers
od_preds_mask = od.predict(X_mask)
score = od_preds_mask['data']['instance_score']
# store average score over `n_masks` for a given mask size
img_scores[j] = np.mean(score)
all_img_scores.append(img_scores)
外れ値スコア vs. マスクサイズ
x_plt = [mask[0] for mask in mask_sizes]
for ais in all_img_scores:
plt.plot(x_plt, ais)
plt.xticks(x_plt)
plt.title('Outlier Score All Images for Increasing Mask Size')
plt.xlabel('Mask size')
plt.ylabel('Outlier Score')
plt.show()
ais_np = np.zeros((len(all_img_scores), all_img_scores[0].shape[0]))
for i, ais in enumerate(all_img_scores):
ais_np[i, :] = ais
ais_mean = np.mean(ais_np, axis=0)
plt.title('Mean Outlier Score All Images for Increasing Mask Size')
plt.xlabel('Mask size')
plt.ylabel('Outlier score')
plt.plot(x_plt, ais_mean)
plt.xticks(x_plt)
plt.show()
インスタンスレベルの外れ値を調査する
i = 8 # index of instance to look at
plt.plot(x_plt, all_img_scores[i])
plt.xticks(x_plt)
plt.title('Outlier Scores Image {} for Increasing Mask Size'.format(i))
plt.xlabel('Mask size')
plt.ylabel('Outlier score')
plt.show()
マスクされた画像の再構築とチャネル毎の外れ値スコア :
all_X_mask = []
X_i = X_orig[i].reshape(1, 32, 32, 3)
all_X_mask.append(X_i)
# apply masks
for j, mask_size in enumerate(mask_sizes):
# create masked instances
X_mask, mask = apply_mask(X_i,
mask_size=mask_size,
n_masks=1, # just 1 for visualization purposes
channels=[0,1,2],
mask_type='normal',
noise_distr=(0,1),
clip_rng=(0,1))
all_X_mask.append(X_mask)
all_X_mask = np.concatenate(all_X_mask, axis=0)
all_X_recon = od.vae(all_X_mask).numpy()
od_preds = od.predict(all_X_mask)
可視化します :
plot_feature_outlier_image(od_preds,
all_X_mask,
X_recon=all_X_recon,
max_instances=all_X_mask.shape[0],
n_channels=3)

(訳注 : 下は実験結果)

特徴のサブセットで外れ値を予測する
外れ値検知器の sensitivity (感度) は閾値を通してだけでなくインスタンスレベルの外れ値スコア計算のために使用される特徴のパーセンテージを選択することによっても制御できます。例えば、特徴の 40% が閾値を越える平均外れ値スコアを持つ場合外れ値であるとフラグ立てすることを望むかもしれません。これは predict 関数の outlier_perc 引数を通して可能です。それは降順の外れ値スコア順序でソートされた、外れ値検知のために使用される特徴のパーセンテージを指定します。
perc_list = [20, 40, 60, 80, 100]
all_perc_scores = []
for perc in perc_list:
od_preds_perc = od.predict(all_X_mask, outlier_perc=perc)
iscore = od_preds_perc['data']['instance_score']
all_perc_scores.append(iscore)
外れ値スコア vs. マスクサイズと使用された特徴サイズのパーセンテージを可視化します :
x_plt = [0] + x_plt
for aps in all_perc_scores:
plt.plot(x_plt, aps)
plt.xticks(x_plt)
plt.legend(perc_list)
plt.title('Outlier Score for Increasing Mask Size and Different Feature Subsets')
plt.xlabel('Mask Size')
plt.ylabel('Outlier Score')
plt.show()
外れ値の閾値を推論する
良い閾値を見つけることは技巧的であり得ます、何故ならばそれらは典型的には解釈することが容易でないからです。infer_threshold メソッドは sensible な値を見つけるのに役立ちます。インスタンスのバッチ X を渡してそれらの何パーセントを正常であると考えるかを threshold_perc を通して指定する必要があります。
print('Current threshold: {}'.format(od.threshold))
od.infer_threshold(X, threshold_perc=99) # assume 1% of the training data are outliers
print('New threshold: {}'.format(od.threshold))
Current threshold: 0.015 New threshold: 0.010383214280009267
(訳注 : 実験結果)
Current threshold: 0.015 New threshold: 0.0018019021837972088
以上
Alibi Detect 0.7 : Examples : AEGMM と VAEGMM 外れ値検知 on TCP dump
Alibi Detect 0.7 : Examples : AEGMM と VAEGMM 外れ値検知 on KDD Cup ‘99 データセット (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 07/03/2021 (0.7.0)
* 本ページは、Alibi Detect の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
- AEGMM and VAEGMM outlier detection on KDD Cup ‘99 dataset
- Auto-Encoding Gaussian Mixture Model
- Variational Auto-Encoding Gaussian Mixture Model
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。
スケジュールは弊社 公式 Web サイト でご確認頂けます。
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
| 人工知能研究開発支援 | 人工知能研修サービス | テレワーク & オンライン授業を支援 |
| PoC(概念実証)を失敗させないための支援 (本支援はセミナーに参加しアンケートに回答した方を対象としています。) | ||
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |
Alibi Detect 0.7 : Examples :AEGMM と VAEGMM 外れ値検知 on KDD Cup ‘99 データセット
AEGMM (オートエンコーディング・ガウス混合モデル) – 概要
オートエンコーディング・ガウス混合モデル (AEGMM) 外れ値検知器は 教師なし異常検知のための深層オートエンコーディング・ガウス混合モデル (Deep Autoencoding Gaussian Mixture Model for Unsupervised Anomaly Detection) 論文に従っています。エンコーダがデータを圧縮する一方で、デコーダにより生成された再構築されたインスタンスは入力と再構築の間の再構築誤差に基づいた追加の特徴を作成するために使用されます。これらの特徴はエンコーディングと結合されてガウス混合モデル (GMM) に供給されます。AEGMM 外れ値検知器はラベル付けされていない、しかし通常 (inlier) データのバッチ上で最初に訓練されます。教師なしか半教師あり訓練が望ましいです、何故ならばラベル付けされたデータはしばしば十分ではないからです。そして GMM のサンプルのエネルギーはインスタンスが外れ値 (高サンプル・エネルギー) か否か (低サンプル・エネルギー) を決定するために使用できます。このアルゴリズムは表形式か画像データのために適合します。
VAEGMM (変分オートエンコーディング・ガウス混合モデル) – 概要
変分オートエンコーディング・ガウス混合モデル (VAEGMM) 外れ値検知器は 教師なし異常検知のための深層オートエンコーディング・ガウス混合モデル (Deep Autoencoding Gaussian Mixture Model for Unsupervised Anomaly Detection) 論文に従っていますが、通常のオートエンコーダの代わりに VAE を使用します。エンコーダがデータを圧縮する一方で、デコーダにより生成された再構築されたインスタンスは入力と再構築の間の再構築誤差に基づいた追加の特徴を作成するために使用されます。これらの特徴はエンコーディングと結合されてガウス混合モデル (GMM) に供給されます。VAEGMM 外れ値検知器はラベル付けされていない、しかし通常 (inlier) データのバッチ上で最初に訓練されます。教師なしか半教師あり訓練が望ましいです、何故ならばラベル付けされたデータはしばしば十分ではないからです。そして GMM のサンプルのエネルギーはインスタンスが外れ値 (高サンプル・エネルギー) か否か (低サンプル・エネルギー) を決定するために使用できます。このアルゴリズムは表形式か画像データのために適合します。
データセット
典型的な U.S. 空軍 LAN をシミュレートした LAN の TCP dump データを使用して、外れ値検知器はコンピュータ・ネットワーク侵入を検知する必要があります。コネクションは明確に定義された時間で開始して終了する TCP パケットのシークエンスで、その間にデータは明確に定義されたプロトコルのもとにソース IP とターゲット IP アドレス間で流れます。各コネクションは正常、また攻撃としてラベル付けされます。
データセットには 4 タイプの攻撃があります :
- DOS: denial-of-service, e.g. syn flood;
- R2L: 遠隔マシンからの権限のないアクセス、e.g. パスワードの推測 ;
- U2R: ローカルのスーパーユーザ (root) 特権への権限のないアクセス ;
- probing : 偵察と他の厳密な調査、e.g., ポートスキャン。
データセットは約 500 万のコネクション・レコードを含みます。
3 つのタイプの特徴があります :
- 個々のコネクションの基本的な特徴, e.g. 接続時間 (duration of connection)
- コネクション内のコンテンツ特徴, e.g. 失敗したログイン試行の数
- 2 秒 window 内の traffic 特徴, e.g. 現在の接続と同じホストへのコネクションの数
import logging
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import pandas as pd
import seaborn as sns
from sklearn.metrics import confusion_matrix, f1_score
import tensorflow as tf
tf.keras.backend.clear_session()
from tensorflow.keras.layers import Dense, InputLayer
from alibi_detect.datasets import fetch_kdd
from alibi_detect.models.tensorflow.autoencoder import eucl_cosim_features
from alibi_detect.od import OutlierAEGMM, OutlierVAEGMM
from alibi_detect.utils.data import create_outlier_batch
from alibi_detect.utils.fetching import fetch_detector
from alibi_detect.utils.saving import save_detector, load_detector
from alibi_detect.utils.visualize import plot_instance_score, plot_feature_outlier_tabular, plot_roc
logger = tf.get_logger()
logger.setLevel(logging.ERROR)
データセットをロードする
幾つかの continuous (連続) な特徴 (41 の内から 18) だけを保持します。
kddcup = fetch_kdd(percent10=True) # only load 10% of the dataset
print(kddcup.data.shape, kddcup.target.shape)
Downloading https://ndownloader.figshare.com/files/5976042 (494021, 18) (494021,)
kddcup.data[0]
array([8, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 9, 9, 1.0, 0.0, 0.11, 0.0,
0.0, 0.0, 0.0, 0.0], dtype=object)
モデルはデータセットの (外れ値ではなく) 正常インスタンス上で訓練されて標準化 (= standardization) が適用されていると仮定します :
np.random.seed(0)
normal_batch = create_outlier_batch(kddcup.data, kddcup.target, n_samples=400000, perc_outlier=0)
X_train, y_train = normal_batch.data.astype('float32'), normal_batch.target
print(X_train.shape, y_train.shape)
print('{}% outliers'.format(100 * y_train.mean()))
(400000, 18) (400000,) 0.0% outliers
mean, stdev = X_train.mean(axis=0), X_train.std(axis=0)
print(mean)
print(stdev)
[1.09550075e+01 1.55620000e-03 1.74745000e-03 5.54626500e-02 5.57733250e-02 9.85440925e-01 1.82663500e-02 1.33057100e-01 1.48641492e+02 2.02133175e+02 8.44858050e-01 5.64032750e-02 1.33479675e-01 2.40508250e-02 2.11637500e-03 1.05915000e-03 5.73124750e-02 5.52324500e-02] [2.17181039e+01 2.78305002e-02 2.61481724e-02 2.28073133e-01 2.26952689e-01 9.25608777e-02 1.16637691e-01 2.77172101e-01 1.03333220e+02 8.68577798e+01 3.05254458e-01 1.79868747e-01 2.80221411e-01 4.92476707e-02 2.95181081e-02 1.59275611e-02 2.24229381e-01 2.17798555e-01]
標準化を適用します :
X_train = (X_train - mean) / stdev
AEGMM 外れ値検知器をロードまたは定義する
examples ノートブックで使用される事前訓練済みの外れ値と敵対的検知器は ここ で見つかります。組込みの fetch_detector 関数を利用できます、これは事前訓練モデルをローカルディレクトリ filepath にセーブして検知器をロードします。代わりに、スクラッチから検知器を訓練することができます :
load_outlier_detector = False
filepath = 'model_aegmm' # 'my_path' # change to directory (absolute path) where model is downloaded
if load_outlier_detector: # load pretrained outlier detector
detector_type = 'outlier'
dataset = 'kddcup'
detector_name = 'OutlierAEGMM'
od = fetch_detector(filepath, detector_type, dataset, detector_name)
filepath = os.path.join(filepath, detector_name)
else: # define model, initialize, train and save outlier detector
# the model defined here is similar to the one defined in the original paper
n_features = X_train.shape[1]
latent_dim = 1
n_gmm = 2 # nb of components in GMM
encoder_net = tf.keras.Sequential(
[
InputLayer(input_shape=(n_features,)),
Dense(60, activation=tf.nn.tanh),
Dense(30, activation=tf.nn.tanh),
Dense(10, activation=tf.nn.tanh),
Dense(latent_dim, activation=None)
])
decoder_net = tf.keras.Sequential(
[
InputLayer(input_shape=(latent_dim,)),
Dense(10, activation=tf.nn.tanh),
Dense(30, activation=tf.nn.tanh),
Dense(60, activation=tf.nn.tanh),
Dense(n_features, activation=None)
])
gmm_density_net = tf.keras.Sequential(
[
InputLayer(input_shape=(latent_dim + 2,)),
Dense(10, activation=tf.nn.tanh),
Dense(n_gmm, activation=tf.nn.softmax)
])
# initialize outlier detector
od = OutlierAEGMM(threshold=None, # threshold for outlier score
encoder_net=encoder_net, # can also pass AEGMM model instead
decoder_net=decoder_net, # of separate encoder, decoder
gmm_density_net=gmm_density_net, # and gmm density net
n_gmm=n_gmm,
recon_features=eucl_cosim_features) # fn used to derive features
# from the reconstructed
# instances based on cosine
# similarity and Eucl distance
# train
od.fit(X_train,
epochs=50,
batch_size=1024,
#save_path=filepath,
verbose=True)
# save the trained outlier detector
save_detector(od, filepath)
391/391 [=] - 10s 25ms/step - loss: 1.7450 391/391 [=] - 10s 26ms/step - loss: 1.6758 391/391 [=] - 10s 26ms/step - loss: 1.5309 391/391 [=] - 10s 25ms/step - loss: 1.4671 391/391 [=] - 10s 25ms/step - loss: 1.4172 391/391 [=] - 10s 25ms/step - loss: 1.3793 391/391 [=] - 10s 25ms/step - loss: 1.3396 391/391 [=] - 10s 26ms/step - loss: 1.2962 391/391 [=] - 10s 26ms/step - loss: 1.2483 391/391 [=] - 10s 25ms/step - loss: 1.2015 391/391 [=] - 10s 25ms/step - loss: 1.1678 391/391 [=] - 10s 25ms/step - loss: 1.1356 391/391 [=] - 10s 25ms/step - loss: 1.0989 391/391 [=] - 10s 26ms/step - loss: 1.0617 391/391 [=] - 10s 26ms/step - loss: 1.0288 391/391 [=] - 10s 25ms/step - loss: 0.9975 391/391 [=] - 10s 25ms/step - loss: 0.9630 391/391 [=] - 10s 25ms/step - loss: 0.9298 391/391 [=] - 10s 25ms/step - loss: 0.9013 391/391 [=] - 10s 26ms/step - loss: 0.8748 391/391 [=] - 11s 27ms/step - loss: 0.8481 391/391 [=] - 10s 25ms/step - loss: 0.8259 391/391 [=] - 10s 25ms/step - loss: 0.8081 391/391 [=] - 10s 25ms/step - loss: 0.7944 391/391 [=] - 10s 25ms/step - loss: 0.7825 391/391 [=] - 10s 26ms/step - loss: 0.7726 391/391 [=] - 10s 26ms/step - loss: 0.7628 391/391 [=] - 10s 25ms/step - loss: 0.7543 391/391 [=] - 10s 25ms/step - loss: 0.7460 391/391 [=] - 10s 25ms/step - loss: 0.7385 391/391 [=] - 10s 26ms/step - loss: 0.7314 391/391 [=] - 10s 26ms/step - loss: 0.7242 391/391 [=] - 10s 25ms/step - loss: 0.7185 391/391 [=] - 10s 25ms/step - loss: 0.7120 391/391 [=] - 10s 25ms/step - loss: 0.7064 391/391 [=] - 10s 25ms/step - loss: 0.7005 391/391 [=] - 10s 25ms/step - loss: 0.6947 391/391 [=] - 10s 26ms/step - loss: 0.6891 391/391 [=] - 11s 27ms/step - loss: 0.6844 391/391 [=] - 10s 25ms/step - loss: 0.6787 391/391 [=] - 10s 25ms/step - loss: 0.6738 391/391 [=] - 10s 25ms/step - loss: 0.6693 391/391 [=] - 10s 25ms/step - loss: 0.6648 391/391 [=] - 10s 26ms/step - loss: 0.6604 391/391 [=] - 10s 26ms/step - loss: 0.6561 391/391 [=] - 10s 25ms/step - loss: 0.6521 391/391 [=] - 10s 25ms/step - loss: 0.6476 391/391 [=] - 10s 25ms/step - loss: 0.6446 391/391 [=] - 10s 25ms/step - loss: 0.6409 391/391 [=] - 10s 26ms/step - loss: 0.6378
!ls model_aegmm -l
!ls model_aegmm/model -l
total 12 -rw-rw-r-- 1 ubuntu ubuntu 760 7月 3 07:33 OutlierAEGMM.pickle -rw-rw-r-- 1 ubuntu ubuntu 89 7月 3 07:33 meta.pickle drwxrwxr-x 2 ubuntu ubuntu 4096 7月 3 07:33 model total 120 -rw-rw-r-- 1 ubuntu ubuntu 29329 7月 3 07:33 aegmm.ckpt.data-00000-of-00001 -rw-rw-r-- 1 ubuntu ubuntu 1398 7月 3 07:33 aegmm.ckpt.index -rw-rw-r-- 1 ubuntu ubuntu 77 7月 3 07:33 checkpoint -rw-rw-r-- 1 ubuntu ubuntu 31576 7月 3 07:33 decoder_net.h5 -rw-rw-r-- 1 ubuntu ubuntu 31608 7月 3 07:33 encoder_net.h5 -rw-rw-r-- 1 ubuntu ubuntu 14488 7月 3 07:33 gmm_density_net.h5
警告は outlier threshold (外れ値閾値) を依然として設定する必要があることを教えます。これは infer_threshold メソッドで成されます。インスタンスのバッチを渡してそれらの何パーセントを正常であると考えるかを threshold_perc を通して指定する必要があります。およそ 5% の外れ値を含むことを知るあるデータを持つと仮定しましょう。外れ値のパーセンテージは create_outlier_batch 関数で perc_outlier で設定できます。
np.random.seed(0)
perc_outlier = 5
threshold_batch = create_outlier_batch(kddcup.data, kddcup.target, n_samples=1000, perc_outlier=perc_outlier)
X_threshold, y_threshold = threshold_batch.data.astype('float32'), threshold_batch.target
X_threshold = (X_threshold - mean) / stdev
print('{}% outliers'.format(100 * y_threshold.mean()))
5.0% outliers
od.infer_threshold(X_threshold, threshold_perc=100-perc_outlier)
print('New threshold: {}'.format(od.threshold))
New threshold: 5.188828468322754
更新された閾値で外れ値検知器をセーブしましょう :
save_detector(od, filepath)
外れ値を検出する
今は 10% の外れ値を持つデータのバッチを生成しそしてバッチ内の外れ値を検出します。
np.random.seed(1)
outlier_batch = create_outlier_batch(kddcup.data, kddcup.target, n_samples=1000, perc_outlier=10)
X_outlier, y_outlier = outlier_batch.data.astype('float32'), outlier_batch.target
X_outlier = (X_outlier - mean) / stdev
print(X_outlier.shape, y_outlier.shape)
print('{}% outliers'.format(100 * y_outlier.mean()))
(1000, 18) (1000,) 10.0% outliers
外れ値を予測します :
od_preds = od.predict(X_outlier, return_instance_score=True)
結果を表示する
F1 スコアと混同行列 :
labels = outlier_batch.target_names
y_pred = od_preds['data']['is_outlier']
f1 = f1_score(y_outlier, y_pred)
print('F1 score: {:.4f}'.format(f1))
cm = confusion_matrix(y_outlier, y_pred)
df_cm = pd.DataFrame(cm, index=labels, columns=labels)
sns.heatmap(df_cm, annot=True, cbar=True, linewidths=.5)
plt.show()
F1 score: 0.3352
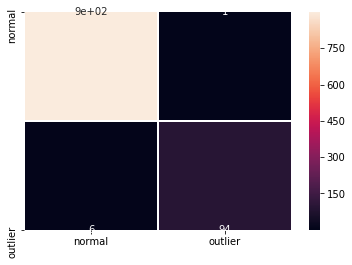
インスタンスレベルの外れ値スコア vs 外れ値閾値をプロットします :
plot_instance_score(od_preds, y_outlier, labels, od.threshold, ylim=(None, None))
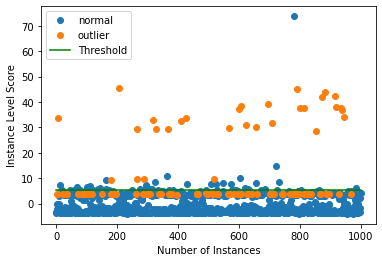
検出器の外れ値スコアのための ROC カーブをプロットすることもできます :
roc_data = {'AEGMM': {'scores': od_preds['data']['instance_score'], 'labels': y_outlier}}
plot_roc(roc_data)
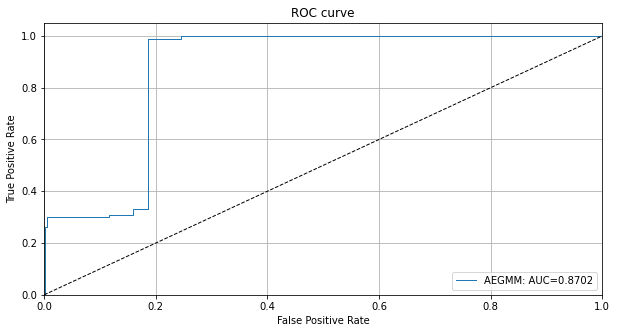
インスタンスレベル外れ値を調査する
潜在空間のインスタンスのエンコーディングとデコーダにより再構築されたインスタンスに由来する特徴を可視化できます。そしてエンコーディングと特徴は GMM 密度ネットワークに供給されます。
enc = od.aegmm.encoder(X_outlier) # encoding
X_recon = od.aegmm.decoder(enc) # reconstructed instances
recon_features = od.aegmm.recon_features(X_outlier, X_recon) # reconstructed features
df = pd.DataFrame(dict(enc=enc[:, 0].numpy(),
cos=recon_features[:, 0].numpy(),
eucl=recon_features[:, 1].numpy(),
label=y_outlier))
groups = df.groupby('label')
fig, ax = plt.subplots()
for name, group in groups:
ax.plot(group.enc, group.cos, marker='o',
linestyle='', ms=6, label=labels[name])
plt.title('Encoding vs. Cosine Similarity')
plt.xlabel('Encoding')
plt.ylabel('Cosine Similarity')
ax.legend()
plt.show()

fig, ax = plt.subplots()
for name, group in groups:
ax.plot(group.enc, group.eucl, marker='o',
linestyle='', ms=6, label=labels[name])
plt.title('Encoding vs. Relative Euclidean Distance')
plt.xlabel('Encoding')
plt.ylabel('Relative Euclidean Distance')
ax.legend()
plt.show()
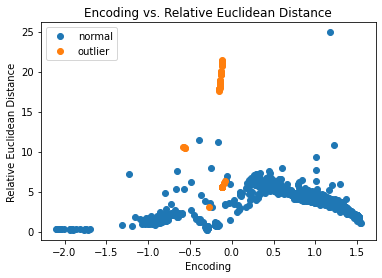
多くの外れ値が潜在空間で既に上手く分離されています。
VAEGMM 外れ値検知器を使用する
Google Cloud Bucket から 事前訓練済みの VAEGMM 検出器を再度インスタンス化できます。組込みの fetch_detector 関数を利用できます、これは事前訓練モデルをローカルディレクトリ filepath にセーブして検知器をロードします。代わりに、スクラッチから検知器を訓練することができます :
load_outlier_detector = False
filepath = 'model_vaegmm' # change to directory (absolute path) where model is downloaded
if load_outlier_detector: # load pretrained outlier detector
detector_type = 'outlier'
dataset = 'kddcup'
detector_name = 'OutlierVAEGMM'
od = fetch_detector(filepath, detector_type, dataset, detector_name)
filepath = os.path.join(filepath, detector_name)
else: # define model, initialize, train and save outlier detector
# the model defined here is similar to the one defined in
# the OutlierVAE notebook
n_features = X_train.shape[1]
latent_dim = 2
n_gmm = 2
encoder_net = tf.keras.Sequential(
[
InputLayer(input_shape=(n_features,)),
Dense(20, activation=tf.nn.relu),
Dense(15, activation=tf.nn.relu),
Dense(7, activation=tf.nn.relu)
])
decoder_net = tf.keras.Sequential(
[
InputLayer(input_shape=(latent_dim,)),
Dense(7, activation=tf.nn.relu),
Dense(15, activation=tf.nn.relu),
Dense(20, activation=tf.nn.relu),
Dense(n_features, activation=None)
])
gmm_density_net = tf.keras.Sequential(
[
InputLayer(input_shape=(latent_dim + 2,)),
Dense(10, activation=tf.nn.relu),
Dense(n_gmm, activation=tf.nn.softmax)
])
# initialize outlier detector
od = OutlierVAEGMM(threshold=None,
encoder_net=encoder_net,
decoder_net=decoder_net,
gmm_density_net=gmm_density_net,
n_gmm=n_gmm,
latent_dim=latent_dim,
samples=10,
recon_features=eucl_cosim_features)
# train
od.fit(X_train,
epochs=50,
batch_size=1024,
cov_elbo=dict(sim=.0025), # standard deviation assumption
verbose=True) # for elbo training
# save the trained outlier detector
save_detector(od, filepath)
391/391 [=] - 16s 40ms/step - loss: 0.7435 391/391 [=] - 15s 39ms/step - loss: 0.6727 391/391 [=] - 15s 38ms/step - loss: 0.6538 391/391 [=] - 15s 38ms/step - loss: 0.6449 391/391 [=] - 16s 40ms/step - loss: 0.6384 391/391 [=] - 15s 38ms/step - loss: 0.6383 391/391 [=] - 15s 38ms/step - loss: 0.6410 391/391 [=] - 16s 40ms/step - loss: 0.6557 391/391 [=] - 15s 39ms/step - loss: 0.7462 391/391 [=] - 15s 38ms/step - loss: 0.9006 391/391 [=] - 15s 38ms/step - loss: 0.8419 391/391 [=] - 15s 39ms/step - loss: 0.8301 391/391 [=] - 16s 41ms/step - loss: 0.8225 391/391 [=] - 15s 38ms/step - loss: 0.8158 391/391 [=] - 15s 39ms/step - loss: 0.8086 391/391 [=] - 15s 39ms/step - loss: 0.8014 391/391 [=] - 16s 40ms/step - loss: 0.7956 391/391 [=] - 15s 39ms/step - loss: 0.7901 391/391 [=] - 15s 39ms/step - loss: 0.7835 391/391 [=] - 15s 39ms/step - loss: 0.7772 391/391 [=] - 15s 39ms/step - loss: 0.7687 391/391 [=] - 15s 39ms/step - loss: 0.7593 391/391 [=] - 15s 39ms/step - loss: 0.7490 391/391 [=] - 15s 39ms/step - loss: 0.7400 391/391 [=] - 16s 41ms/step - loss: 0.7326 391/391 [=] - 15s 39ms/step - loss: 0.7261 391/391 [=] - 15s 39ms/step - loss: 0.7212 391/391 [=] - 16s 40ms/step - loss: 0.7167 391/391 [=] - 16s 40ms/step - loss: 0.7125 391/391 [=] - 15s 39ms/step - loss: 0.7068 391/391 [=] - 15s 39ms/step - loss: 0.7023 391/391 [=] - 16s 40ms/step - loss: 0.6979 391/391 [=] - 15s 39ms/step - loss: 0.6941 391/391 [=] - 15s 39ms/step - loss: 0.6903 391/391 [=] - 15s 39ms/step - loss: 0.6883 391/391 [=] - 16s 40ms/step - loss: 0.6861 391/391 [=] - 16s 40ms/step - loss: 0.6843 391/391 [=] - 15s 39ms/step - loss: 0.6829 391/391 [=] - 15s 39ms/step - loss: 0.6814 391/391 [=] - 16s 41ms/step - loss: 0.6802 391/391 [=] - 15s 39ms/step - loss: 0.6791 391/391 [=] - 15s 39ms/step - loss: 0.6786 391/391 [=] - 15s 39ms/step - loss: 0.6774 391/391 [=] - 16s 40ms/step - loss: 0.6767 391/391 [=] - 15s 39ms/step - loss: 0.6759 391/391 [=] - 15s 39ms/step - loss: 0.6756 391/391 [=] - 15s 40ms/step - loss: 0.6753 391/391 [=] - 16s 41ms/step - loss: 0.6741 391/391 [=] - 15s 39ms/step - loss: 0.6729 391/391 [=] - 15s 39ms/step - loss: 0.6733
!ls model_vaegmm -l
!ls model_vaegmm/model -l
total 12 -rw-rw-r-- 1 ubuntu ubuntu 935 7月 3 07:56 OutlierVAEGMM.pickle -rw-rw-r-- 1 ubuntu ubuntu 90 7月 3 07:56 meta.pickle drwxrwxr-x 2 ubuntu ubuntu 4096 7月 3 07:56 model total 80 -rw-rw-r-- 1 ubuntu ubuntu 79 7月 3 07:56 checkpoint -rw-rw-r-- 1 ubuntu ubuntu 22104 7月 3 07:56 decoder_net.h5 -rw-rw-r-- 1 ubuntu ubuntu 19304 7月 3 07:56 encoder_net.h5 -rw-rw-r-- 1 ubuntu ubuntu 14488 7月 3 07:56 gmm_density_net.h5 -rw-rw-r-- 1 ubuntu ubuntu 10033 7月 3 07:56 vaegmm.ckpt.data-00000-of-00001 -rw-rw-r-- 1 ubuntu ubuntu 1503 7月 3 07:56 vaegmm.ckpt.index
再度閾値を推論する必要があります :
od.infer_threshold(X_threshold, threshold_perc=100-perc_outlier)
print('New threshold: {}'.format(od.threshold))
New threshold: 9.472237873077368
更新された閾値で外れ値検知器をセーブします :
save_detector(od, filepath)
外れ値を検出して結果を表示する
予測します :
od_preds = od.predict(X_outlier, return_instance_score=True)
F1 スコアと混同行列 :
labels = outlier_batch.target_names
y_pred = od_preds['data']['is_outlier']
f1 = f1_score(y_outlier, y_pred)
print('F1 score: {:.4f}'.format(f1))
cm = confusion_matrix(y_outlier, y_pred)
df_cm = pd.DataFrame(cm, index=labels, columns=labels)
sns.heatmap(df_cm, annot=True, cbar=True, linewidths=.5)
plt.show()
F1 score: 0.9515

インスタンスレベルの外れ値スコア vs 外れ値閾値をプロットします :
plot_instance_score(od_preds, y_outlier, labels, od.threshold, ylim=(None, None))
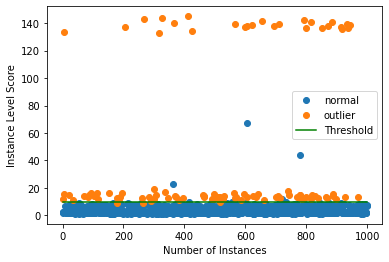
ylim の min と max 値を調整することによりズームインできます。VAEGMM ROC カーブを AEGMM と比較することもできます :
roc_data['VAEGMM'] = {'scores': od_preds['data']['instance_score'], 'labels': y_outlier}
plot_roc(roc_data)
以上
Alibi Detect 0.7 : Examples : VAE 外れ値検知 on TCP dump
Alibi Detect 0.7 : Examples : VAE 外れ値検知 on KDD Cup ‘99 データセット (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 07/02/2021 (0.7.0)
* 本ページは、Alibi Detect の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。
スケジュールは弊社 公式 Web サイト でご確認頂けます。
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
| 人工知能研究開発支援 | 人工知能研修サービス | テレワーク & オンライン授業を支援 |
| PoC(概念実証)を失敗させないための支援 (本支援はセミナーに参加しアンケートに回答した方を対象としています。) | ||
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |
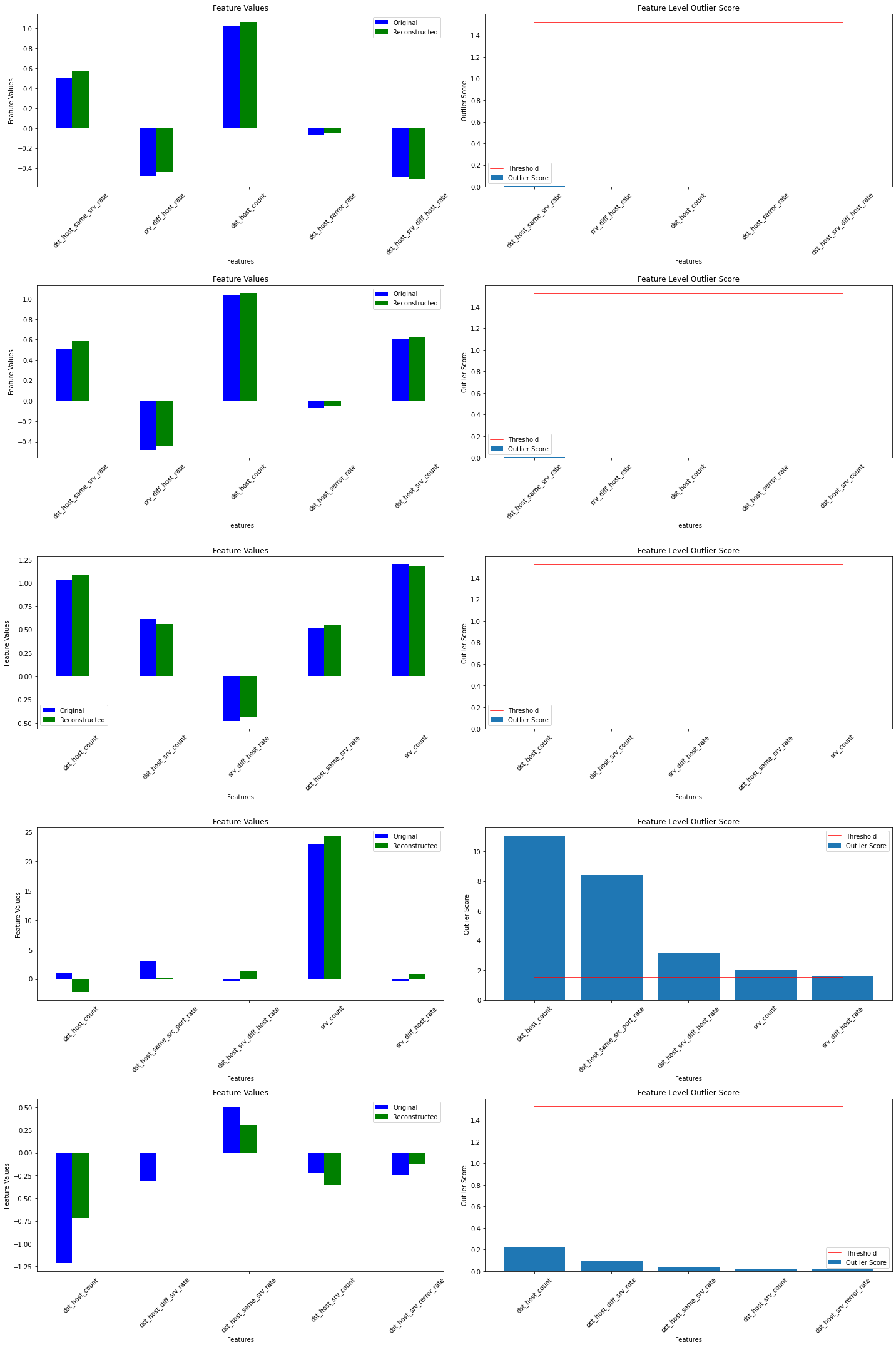
Alibi Detect 0.7 : Examples : VAE 外れ値検知 on KDD Cup ‘99 データセット
VAE – 概要
変分オートエンコーダ (VAE, Variational Auto-Encoder) 外れ値検知器は最初にラベル付けされていない、しかし通常 (inlier) データのバッチで訓練されます。教師なしか半教師あり訓練が望ましいです、何故ならばラベル付けされたデータはしばしば十分でないからです。VAE 検知器はそれが受け取る入力を再構築しようとします。入力データが上手く再構築されない場合、再構築エラーは高くそしてデータは外れ値としてフラグ立てできます。再構築エラーは、入力と再構築されたインスタンスの間の平均二乗誤差 (MSE, mean squared error) か、入力と再構築されたインスタンスの両者が同じプロセスで生成される確率として測定されます。アルゴリズムは表形式か画像データのために適合します。
データセット
典型的な U.S. 空軍 LAN をシミュレートした LAN の TCP dump データを使用して、外れ値検知器はコンピュータ・ネットワーク侵入を検知する必要があります。コネクションは明確に定義された時間で開始して終了する TCP パケットのシークエンスで、その間にデータは明確に定義されたプロトコルのもとにソース IP とターゲット IP アドレス間で流れます。各コネクションは正常、また攻撃としてラベル付けされます。
データセットには 4 タイプの攻撃があります :
- DOS: denial-of-service, e.g. syn flood;
- R2L: 遠隔マシンからの権限のないアクセス、e.g. パスワードの推測 ;
- U2R: ローカルのスーパーユーザ (root) 特権への権限のないアクセス ;
- probing : 偵察と他の厳密な調査、e.g., ポートスキャン。
データセットは約 500 万のコネクション・レコードを含みます。
3 つのタイプの特徴があります :
- 個々のコネクションの基本的な特徴, e.g. 接続時間 (duration of connection)
- コネクション内のコンテンツ特徴, e.g. 失敗したログイン試行の数
- 2 秒 window 内の traffic 特徴, e.g. 現在の接続と同じホストへのコネクションの数
import logging
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import pandas as pd
import seaborn as sns
from sklearn.metrics import confusion_matrix, f1_score
import tensorflow as tf
tf.keras.backend.clear_session()
from tensorflow.keras.layers import Dense, InputLayer
from alibi_detect.datasets import fetch_kdd
from alibi_detect.models.tensorflow.losses import elbo
from alibi_detect.od import OutlierVAE
from alibi_detect.utils.data import create_outlier_batch
from alibi_detect.utils.fetching import fetch_detector
from alibi_detect.utils.saving import save_detector, load_detector
from alibi_detect.utils.visualize import plot_instance_score, plot_feature_outlier_tabular, plot_roc
logger = tf.get_logger()
logger.setLevel(logging.ERROR)
データセットをロードする
幾つかの continuous (連続) な特徴 (41 の内から 18) だけを保持します。
kddcup = fetch_kdd(percent10=True) # only load 10% of the dataset
print(kddcup.data.shape, kddcup.target.shape)
Downloading https://ndownloader.figshare.com/files/5976042 (494021, 18) (494021,)
kddcup.data[0]
array([8, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 9, 9, 1.0, 0.0, 0.11, 0.0,
0.0, 0.0, 0.0, 0.0], dtype=object)
機械学習モデルはデータセットの (外れ値ではなく) 正常インスタンス上で訓練されて標準化 (= standardization) が適用されていると仮定します :
np.random.seed(0)
normal_batch = create_outlier_batch(kddcup.data, kddcup.target, n_samples=400000, perc_outlier=0)
X_train, y_train = normal_batch.data.astype('float'), normal_batch.target
print(X_train.shape, y_train.shape)
print('{}% outliers'.format(100 * y_train.mean()))
(400000, 18) (400000,) 0.0% outliers
mean, stdev = X_train.mean(axis=0), X_train.std(axis=0)
print(mean)
print(stdev)
[1.09550075e+01 1.55620000e-03 1.74745000e-03 5.54626500e-02 5.57733250e-02 9.85440925e-01 1.82663500e-02 1.33057100e-01 1.48641492e+02 2.02133175e+02 8.44858050e-01 5.64032750e-02 1.33479675e-01 2.40508250e-02 2.11637500e-03 1.05915000e-03 5.73124750e-02 5.52324500e-02] [2.17181039e+01 2.78305002e-02 2.61481724e-02 2.28073133e-01 2.26952689e-01 9.25608777e-02 1.16637691e-01 2.77172101e-01 1.03333220e+02 8.68577798e+01 3.05254458e-01 1.79868747e-01 2.80221411e-01 4.92476707e-02 2.95181081e-02 1.59275611e-02 2.24229381e-01 2.17798555e-01]
標準化を適用します :
X_train = (X_train - mean) / stdev
外れ値検知器をロードまたは定義する
examples ノートブックで使用される事前訓練済みの外れ値と敵対的検知器は ここ で見つかります。組込みの fetch_detector 関数を利用できます、これは事前訓練モデルをローカルディレクトリ filepath にセーブして検知器をロードします。代わりに、スクラッチから検知器を訓練することができます。
load_outlier_detector = False
filepath = 'my_dir' # change to directory (absolute path) where model is downloaded
if load_outlier_detector: # load pretrained outlier detector
detector_type = 'outlier'
dataset = 'kddcup'
detector_name = 'OutlierVAE'
od = fetch_detector(filepath, detector_type, dataset, detector_name)
filepath = os.path.join(filepath, detector_name)
else: # define model, initialize, train and save outlier detector
n_features = X_train.shape[1]
latent_dim = 2
encoder_net = tf.keras.Sequential(
[
InputLayer(input_shape=(n_features,)),
Dense(20, activation=tf.nn.relu),
Dense(15, activation=tf.nn.relu),
Dense(7, activation=tf.nn.relu)
])
decoder_net = tf.keras.Sequential(
[
InputLayer(input_shape=(latent_dim,)),
Dense(7, activation=tf.nn.relu),
Dense(15, activation=tf.nn.relu),
Dense(20, activation=tf.nn.relu),
Dense(n_features, activation=None)
])
# initialize outlier detector
od = OutlierVAE(threshold=None, # threshold for outlier score
score_type='mse', # use MSE of reconstruction error for outlier detection
encoder_net=encoder_net, # can also pass VAE model instead
decoder_net=decoder_net, # of separate encoder and decoder
latent_dim=latent_dim,
samples=5)
# train
od.fit(X_train,
loss_fn=elbo,
cov_elbo=dict(sim=.01),
epochs=30,
verbose=True)
# save the trained outlier detector
save_detector(od, filepath)
6250/6250 [=] - 148s 24ms/step - loss: 28695.7242 6250/6250 [=] - 148s 24ms/step - loss: 12437.6854 6250/6250 [=] - 146s 23ms/step - loss: 10256.9219 6250/6250 [=] - 155s 25ms/step - loss: 9557.9839 6250/6250 [=] - 147s 23ms/step - loss: 8414.8731 6250/6250 [=] - 148s 24ms/step - loss: 7847.7130 6250/6250 [=] - 151s 24ms/step - loss: 7549.5546 6250/6250 [=] - 150s 24ms/step - loss: 7412.6179 6250/6250 [=] - 147s 23ms/step - loss: 7358.9181 6250/6250 [=] - 148s 24ms/step - loss: 7064.3351 6250/6250 [=] - 145s 23ms/step - loss: 7047.5733 6250/6250 [=] - 150s 24ms/step - loss: 6862.8724 6250/6250 [=] - 146s 23ms/step - loss: 6859.6950 6250/6250 [=] - 149s 24ms/step - loss: 6733.0950 6250/6250 [=] - 146s 23ms/step - loss: 6395.8519 6250/6250 [=] - 152s 24ms/step - loss: 6239.8235 6250/6250 [=] - 147s 23ms/step - loss: 6141.0218 6250/6250 [=] - 149s 24ms/step - loss: 6080.4994 6250/6250 [=] - 150s 24ms/step - loss: 6030.9626 6250/6250 [=] - 152s 24ms/step - loss: 5986.5710 6250/6250 [=] - 152s 24ms/step - loss: 5968.1871 6250/6250 [=] - 150s 24ms/step - loss: 6026.3471 6250/6250 [=] - 152s 24ms/step - loss: 5828.1424 6250/6250 [=] - 149s 24ms/step - loss: 5841.5844 6250/6250 [=] - 147s 24ms/step - loss: 5794.9508 6250/6250 [=] - 154s 25ms/step - loss: 5792.5575 6250/6250 [=] - 147s 24ms/step - loss: 5767.5592 6250/6250 [=] - 150s 24ms/step - loss: 5643.3078 6250/6250 [=] - 147s 23ms/step - loss: 5571.4557 6250/6250 [=] - 148s 24ms/step - loss: 5541.4037
!ls model_vae -l
!ls model_vae/model -l
total 12 -rw-rw-r-- 1 ubuntu ubuntu 107 7月 2 13:26 OutlierVAE.pickle -rw-rw-r-- 1 ubuntu ubuntu 87 7月 2 13:26 meta.pickle drwxrwxr-x 2 ubuntu ubuntu 4096 7月 2 13:26 model total 64 -rw-rw-r-- 1 ubuntu ubuntu 73 7月 2 13:26 checkpoint -rw-rw-r-- 1 ubuntu ubuntu 22104 7月 2 13:26 decoder_net.h5 -rw-rw-r-- 1 ubuntu ubuntu 19304 7月 2 13:26 encoder_net.h5 -rw-rw-r-- 1 ubuntu ubuntu 9269 7月 2 13:26 vae.ckpt.data-00000-of-00001 -rw-rw-r-- 1 ubuntu ubuntu 1259 7月 2 13:26 vae.ckpt.index
警告は outlier threshold (外れ値閾値) を依然として設定する必要があることを教えます。これは infer_threshold メソッドで成されます。インスタンスのバッチを渡してそれらの何パーセントを正常であると考えるかを threshold_perc を通して指定する必要があります。およそ 5% の外れ値を含むことを知るあるデータを持つと仮定しましょう。外れ値のパーセンテージは create_outlier_batch 関数で perc_outlier で設定できます。
np.random.seed(0)
perc_outlier = 5
threshold_batch = create_outlier_batch(kddcup.data, kddcup.target, n_samples=1000, perc_outlier=perc_outlier)
X_threshold, y_threshold = threshold_batch.data.astype('float'), threshold_batch.target
X_threshold = (X_threshold - mean) / stdev
print('{}% outliers'.format(100 * y_threshold.mean()))
5.0% outliers
od.infer_threshold(X_threshold, threshold_perc=100-perc_outlier)
print('New threshold: {}'.format(od.threshold))
New threshold: 1.5222603200798008
threshold_perc を例えば 99 に設定して推論された閾値に少しのマージンを加えることにより通常の訓練データから閾値をすいろんすることもできました。更新された閾値で外れ値検知器をセーブしましょう :
save_detector(od, filepath)
!ls model_vae -l
!ls model_vae/model -l
total 12 -rw-rw-r-- 1 ubuntu ubuntu 218 7月 2 13:35 OutlierVAE.pickle -rw-rw-r-- 1 ubuntu ubuntu 87 7月 2 13:35 meta.pickle drwxrwxr-x 2 ubuntu ubuntu 4096 7月 2 13:35 model total 64 -rw-rw-r-- 1 ubuntu ubuntu 73 7月 2 13:35 checkpoint -rw-rw-r-- 1 ubuntu ubuntu 22104 7月 2 13:35 decoder_net.h5 -rw-rw-r-- 1 ubuntu ubuntu 19304 7月 2 13:35 encoder_net.h5 -rw-rw-r-- 1 ubuntu ubuntu 9269 7月 2 13:35 vae.ckpt.data-00000-of-00001 -rw-rw-r-- 1 ubuntu ubuntu 1259 7月 2 13:35 vae.ckpt.index
外れ値を検出する
今は 10% の外れ値を持つデータのバッチを生成しそしてバッチ内の外れ値を検出します。
np.random.seed(1)
outlier_batch = create_outlier_batch(kddcup.data, kddcup.target, n_samples=1000, perc_outlier=10)
X_outlier, y_outlier = outlier_batch.data.astype('float'), outlier_batch.target
X_outlier = (X_outlier - mean) / stdev
print(X_outlier.shape, y_outlier.shape)
print('{}% outliers'.format(100 * y_outlier.mean()))
(1000, 18) (1000,) 10.0% outliers
外れ値を予測します :
od_preds = od.predict(X_outlier,
outlier_type='instance', # use 'feature' or 'instance' level
return_feature_score=True, # scores used to determine outliers
return_instance_score=True)
print(list(od_preds['data'].keys()))
['instance_score', 'feature_score', 'is_outlier']
od_preds['data']['is_outlier'][:10]
array([0, 0, 0, 1, 0, 1, 1, 0, 0, 0])
od_preds['data']['instance_score'][:10]
array([5.74442137e-04, 6.24835379e-04, 6.83877481e-04, 1.52228703e+00,
2.47923307e-02, 4.29582862e+01, 1.52229905e+00, 4.45219175e-03,
8.09561496e-02, 2.37765956e-02])
od_preds['data']['feature_score']
array([[4.77347707e-05, 6.23364775e-05, 4.80892692e-05, ...,
3.21192958e-04, 6.79559419e-05, 5.60611257e-05],
[1.67435697e-04, 7.68863402e-05, 1.12371712e-04, ...,
3.19287128e-04, 9.01695907e-05, 8.10840695e-05],
[9.42410698e-04, 1.08231414e-06, 3.40019366e-05, ...,
5.65485925e-04, 1.88107799e-05, 1.04572967e-05],
...,
[2.08158688e-03, 4.93670543e-06, 3.57241685e-05, ...,
6.89739720e-04, 9.91289453e-05, 3.80882650e-06],
[2.27466705e-03, 4.25181944e-03, 6.06307292e-05, ...,
3.40673684e-05, 9.27018184e-06, 6.57232246e-03],
[1.50122506e-03, 4.51257037e-03, 1.09080541e-05, ...,
4.76422446e-04, 4.67411636e-03, 4.86378648e-02]])
結果を表示する
F1 スコアと混同行列 :
labels = outlier_batch.target_names
y_pred = od_preds['data']['is_outlier']
f1 = f1_score(y_outlier, y_pred)
print('F1 score: {:.4f}'.format(f1))
cm = confusion_matrix(y_outlier, y_pred)
df_cm = pd.DataFrame(cm, index=labels, columns=labels)
sns.heatmap(df_cm, annot=True, cbar=True, linewidths=.5)
plt.show()
F1 score: 0.9754

インスタンスレベルの外れ値スコア vs 外れ値閾値をプロットします :
plot_instance_score(od_preds, y_outlier, labels, od.threshold)
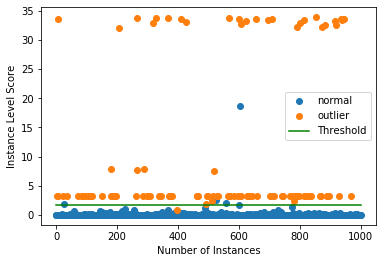
幾つかの外れ値が検出するのに非常に簡単である一方で、他は通常データに近い外れ値スコアを持つことが明瞭に分かります。検出器の外れ値スコアのための ROC カーブをプロットすることもできます :
roc_data = {'VAE': {'scores': od_preds['data']['instance_score'], 'labels': y_outlier}}
plot_roc(roc_data)
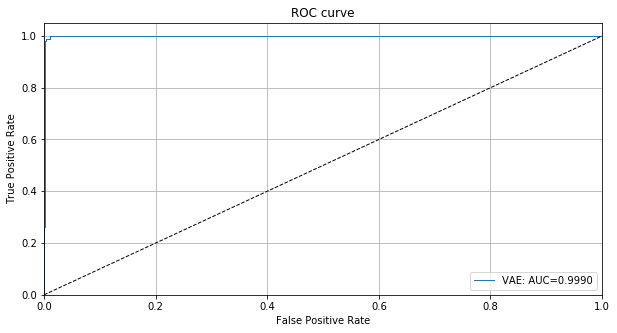
インスタンスレベル外れ値を調査する
今は X_outlier 上の個々の予測の幾つかを詳しく見ることができます。
X_recon = od.vae(X_outlier).numpy() # reconstructed instances by the VAE
plot_feature_outlier_tabular(od_preds,
X_outlier,
X_recon=X_recon,
threshold=od.threshold,
instance_ids=None, # pass a list with indices of instances to display
max_instances=5, # max nb of instances to display
top_n=5, # only show top_n features ordered by outlier score
outliers_only=False, # only show outlier predictions
feature_names=kddcup.feature_names, # add feature names
figsize=(20, 30))
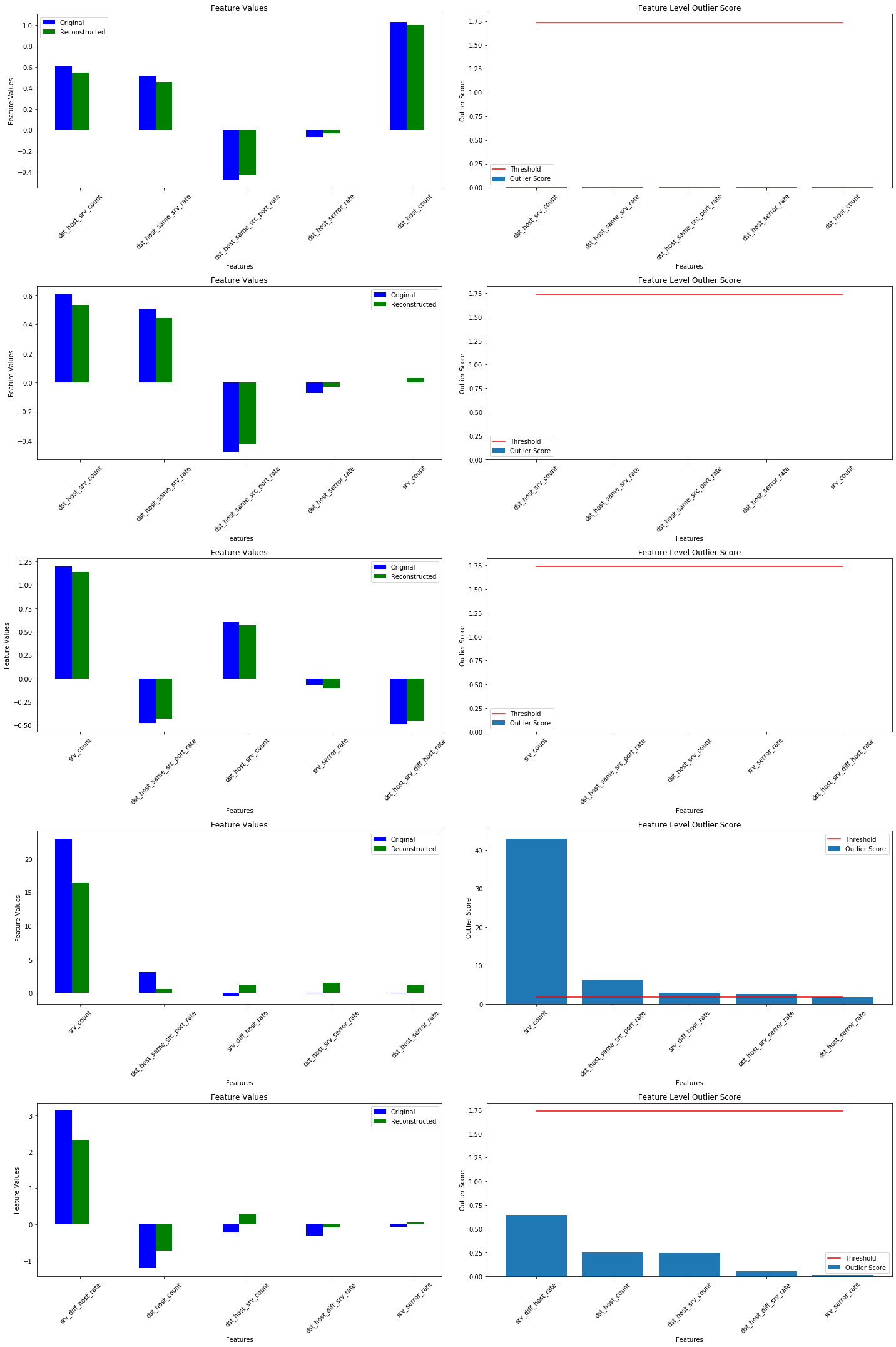
(訳注 : 下は実験結果)
srv_count 特徴は多くの表示される外れ値の責任を負います。
以上
Alibi Detect 0.7 : Examples : Isolation Forest 外れ値検知 on TCP dump
Alibi Detect 0.7 : Examples : Isolation Forest 外れ値検知 on KDD Cup ‘99 データセット (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 07/02/2021 (0.7.0)
* 本ページは、Alibi Detect の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。
スケジュールは弊社 公式 Web サイト でご確認頂けます。
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
| 人工知能研究開発支援 | 人工知能研修サービス | テレワーク & オンライン授業を支援 |
| PoC(概念実証)を失敗させないための支援 (本支援はセミナーに参加しアンケートに回答した方を対象としています。) | ||
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |
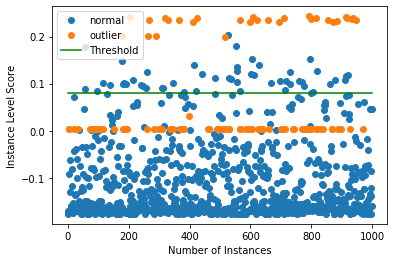
Alibi Detect 0.7 : Examples : Isolation Forest 外れ値検知 on KDD Cup ‘99 データセット
Isolation Forest – 概要
Isolation forests (IF) は特に外れ値検知のために使用される tree ベースのモデルです。IF は特徴をランダムに選択してから選択された特徴の最大値と最小値の間の分割値をランダムに選択することにより観測を isolate (分離、区分け) します。サンプルを区分けするために必要な分割の数はルートノードから終端 (= terminating) ノードへのパスの長さに等しいです。ランダム tree の森に渡り平均された、パスの長さは正常の尺度で異常スコアを定義するために使用されます。外れ値は典型的にはより迅速に分離され、より短いパスに繋がります。アルゴリズムは低次元から medium 次元の表形式データのために適します。
データセット
典型的な U.S. 空軍 LAN をシミュレートした LAN の TCP dump データを使用して、外れ値検知器はコンピュータ・ネットワーク侵入を検知する必要があります。コネクションは明確に定義された時間で開始して終了する TCP パケットのシークエンスで、その間にデータは明確に定義されたプロトコルのもとにソース IP とターゲット IP アドレス間で流れます。各コネクションは正常、また攻撃としてラベル付けされます。
データセットには 4 タイプの攻撃があります :
- DOS: denial-of-service, e.g. syn flood;
- R2L: 遠隔マシンからの権限のないアクセス、e.g. パスワードの推測 ;
- U2R: ローカルのスーパーユーザ (root) 特権への権限のないアクセス ;
- probing : 偵察と他の厳密な調査、e.g., ポートスキャン。
データセットは約 500 万のコネクション・レコードを含みます。
3 つのタイプの特徴があります :
- 個々のコネクションの基本的な特徴, e.g. 接続時間 (duration of connection)
- コネクション内のコンテンツ特徴, e.g. 失敗したログイン試行の数
- 2 秒 window 内の traffic 特徴, e.g. 現在の接続と同じホストへのコネクションの数
import matplotlib
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import os
import pandas as pd
import seaborn as sns
from sklearn.metrics import confusion_matrix, f1_score
from alibi_detect.od import IForest
from alibi_detect.datasets import fetch_kdd
from alibi_detect.utils.data import create_outlier_batch
from alibi_detect.utils.fetching import fetch_detector
from alibi_detect.utils.saving import save_detector, load_detector
from alibi_detect.utils.visualize import plot_instance_score, plot_roc
データセットをロードする
幾つかの continuous (連続) な特徴 (41 の内から 18) だけを保持します。
kddcup = fetch_kdd(percent10=True) # only load 10% of the dataset
print(kddcup.data.shape, kddcup.target.shape)
Downloading https://ndownloader.figshare.com/files/5976042 (494021, 18) (494021,)
kddcup.data[0]
array([8, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 9, 9, 1.0, 0.0, 0.11, 0.0,
0.0, 0.0, 0.0, 0.0], dtype=object)
機械学習モデルはデータセットの (外れ値ではなく) 正常インスタンス上で訓練されて標準化 (= standardization) が適用されていると仮定します :
np.random.seed(0)
normal_batch = create_outlier_batch(kddcup.data, kddcup.target, n_samples=400000, perc_outlier=0)
X_train, y_train = normal_batch.data.astype('float'), normal_batch.target
print(X_train.shape, y_train.shape)
print('{}% outliers'.format(100 * y_train.mean()))
(400000, 18) (400000,) 0.0% outliers
mean, stdev = X_train.mean(axis=0), X_train.std(axis=0)
print(mean)
print(stdev)
[1.09550075e+01 1.55620000e-03 1.74745000e-03 5.54626500e-02 5.57733250e-02 9.85440925e-01 1.82663500e-02 1.33057100e-01 1.48641492e+02 2.02133175e+02 8.44858050e-01 5.64032750e-02 1.33479675e-01 2.40508250e-02 2.11637500e-03 1.05915000e-03 5.73124750e-02 5.52324500e-02] [2.17181039e+01 2.78305002e-02 2.61481724e-02 2.28073133e-01 2.26952689e-01 9.25608777e-02 1.16637691e-01 2.77172101e-01 1.03333220e+02 8.68577798e+01 3.05254458e-01 1.79868747e-01 2.80221411e-01 4.92476707e-02 2.95181081e-02 1.59275611e-02 2.24229381e-01 2.17798555e-01]
標準化を適用します :
X_train = (X_train - mean) / stdev
外れ値検知器をロードまたは定義する
examples ノートブックで使用される事前訓練済みの外れ値と敵対的検知器は ここ で見つかります。組込みの fetch_detector 関数を利用できます、これは事前訓練モデルをローカルディレクトリ filepath にセーブして検知器をロードします。代わりに、スクラッチから検知器を訓練することができます。
load_outlier_detector = False
filepath = 'my_path' # change to directory where model is downloaded
if load_outlier_detector: # load pretrained outlier detector
detector_type = 'outlier'
dataset = 'kddcup'
detector_name = 'IForest'
od = fetch_detector(filepath, detector_type, dataset, detector_name)
filepath = os.path.join(filepath, detector_name)
else: # define model, initialize, train and save outlier detector
# initialize outlier detector
od = IForest(threshold=None, # threshold for outlier score
n_estimators=100)
# train
od.fit(X_train)
# save the trained outlier detector
save_detector(od, filepath)
load_outlier_detector が False に等しい場合、警告が outlier threshold (外れ値閾値) を依然として設定する必要があることを教えます。これは infer_threshold メソッドで成されます。インスタンスのバッチを渡してそれらの何パーセントを正常であると考えるかを threshold_perc を通して指定する必要があります。およそ 5% の外れ値を含むことを知るあるデータを持つと仮定しましょう。外れ値のパーセンテージは create_outlier_batch 関数で perc_outlier で設定できます。
np.random.seed(0)
perc_outlier = 5
threshold_batch = create_outlier_batch(kddcup.data, kddcup.target, n_samples=1000, perc_outlier=perc_outlier)
X_threshold, y_threshold = threshold_batch.data.astype('float'), threshold_batch.target
X_threshold = (X_threshold - mean) / stdev
print('{}% outliers'.format(100 * y_threshold.mean()))
5.0% outliers
od.infer_threshold(X_threshold, threshold_perc=100-perc_outlier)
print('New threshold: {}'.format(od.threshold))
New threshold: 0.0797010793476482
更新された閾値で外れ値検知器をセーブしましょう :
save_detector(od, filepath)
外れ値を検出する
今は 10% の外れ値を持つデータのバッチを生成しそしてバッチ内の外れ値を検出します。
np.random.seed(1)
outlier_batch = create_outlier_batch(kddcup.data, kddcup.target, n_samples=1000, perc_outlier=10)
X_outlier, y_outlier = outlier_batch.data.astype('float'), outlier_batch.target
X_outlier = (X_outlier - mean) / stdev
print(X_outlier.shape, y_outlier.shape)
print('{}% outliers'.format(100 * y_outlier.mean()))
(1000, 18) (1000,) 10.0% outliers
外れ値を予測します :
od_preds = od.predict(X_outlier, return_instance_score=True)
結果を表示する
F1 スコアと混同行列 :
labels = outlier_batch.target_names
y_pred = od_preds['data']['is_outlier']
f1 = f1_score(y_outlier, y_pred)
print('F1 score: {:.4f}'.format(f1))
cm = confusion_matrix(y_outlier, y_pred)
df_cm = pd.DataFrame(cm, index=labels, columns=labels)
sns.heatmap(df_cm, annot=True, cbar=True, linewidths=.5)
plt.show()
F1 score: 0.3279
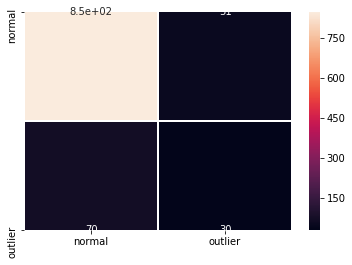
インスタンスレベルの外れ値スコア vs 外れ値閾値をプロットします :
plot_instance_score(od_preds, y_outlier, labels, od.threshold)
isolation forest が外れ値スコアが 0 あたりの外れ値の 1 タイプを検出するのに良い仕事をしていないことが分かります。これは外れ値についての明示的な知識なしに良い閾値を推論することを困難にしています。閾値を 0 のすぐ下に設定することはデータセットの外れ値のために実質的により良い検出性能に繋がるでしょう。これはまた ROC カーブによっても反映されます :
roc_data = {'IF': {'scores': od_preds['data']['instance_score'], 'labels': y_outlier}}
plot_roc(roc_data)
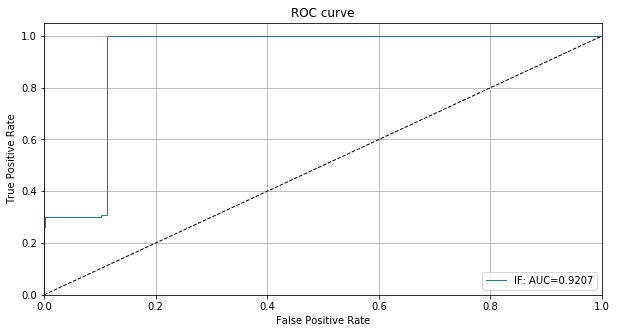
以上
ClassCat® Chatbot
人工知能開発支援
- テクニカルコンサルティングサービス
- 実証実験 (プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
クラスキャット
セールス・インフォメーション
E-Mail:sales-info@classcat.com