ホーム » sales-info の投稿
作者アーカイブ: sales-info
Prophet 1.1 : 季節性、休日効果とリグレッサー
Prophet 1.1 : 季節性、休日効果とリグレッサー (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 08/31/2023 (1.1.4)
* 本ページは、Prophet の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。

- 人工知能研究開発支援
- 人工知能研修サービス(経営者層向けオンサイト研修)
- テクニカルコンサルティングサービス
- 実証実験(プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
- PoC(概念実証)を失敗させないための支援
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
- 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション
- sales-info@classcat.com ; Web: www.classcat.com ; ClassCatJP
Prophet 1.1 : 季節性、休日効果とリグレッサー
休日と特殊イベントのモデル化
モデル化したい休日や他の繰り返し発生する (循環性の, recurring) イベントを持つ場合、それらに対してデータフレームを作成しなければなりません。それは 2 つのカラム (holiday と ds) と休日の各々の発生のに対して行を持ちます。それは過去 (後方に履歴データがある限り) と未来 (予測が行なわれている限り) の両者の、休日の総ての発生を含まなければなりません、それらが未来に繰り返されない場合、Prophet はそれらをモデル化して予測ではそれらを含めません。
カラムに lower_window と upper_window を含めることもできます、これらは休日を日付周りの [lower_window, upper_window] days に拡張します。例えば、クリスマスに加えてクリスマス・イブを含めることを望んだ場合、lower_window=-1,upper_window=0 を含めます。感謝祭に加えてブラックフライデーを使用したい場合には、lower_window=0,upper_window=1 を含めます。下で説明されるように、各休日のために prior scale を個別に設定するためにカラム prior_scale を含めることもできます。
ここでは Peyton Manning のプレーオフ出場の総ての日付を含むデータフレームを作成します :
playoffs = pd.DataFrame({
'holiday': 'playoff',
'ds': pd.to_datetime(['2008-01-13', '2009-01-03', '2010-01-16',
'2010-01-24', '2010-02-07', '2011-01-08',
'2013-01-12', '2014-01-12', '2014-01-19',
'2014-02-02', '2015-01-11', '2016-01-17',
'2016-01-24', '2016-02-07']),
'lower_window': 0,
'upper_window': 1,
})
superbowls = pd.DataFrame({
'holiday': 'superbowl',
'ds': pd.to_datetime(['2010-02-07', '2014-02-02', '2016-02-07']),
'lower_window': 0,
'upper_window': 1,
})
holidays = pd.concat((playoffs, superbowls))
上記ではスーパーボウル days をプレーオフゲームとスーパーボウルゲームの両方として含めました。これは、スパーボウル効果はプレーオフ効果の上に追加の加算的ボーナスであることを意味します。
ひとたびテーブルが作成されれば、休日効果はそれらを holidays 引数で渡すことにより予測に含まれます。ここでは クイックスタート からの Peyton Manning データでそれを行ないます :
m = Prophet(holidays=holidays)
forecast = m.fit(df).predict(future)
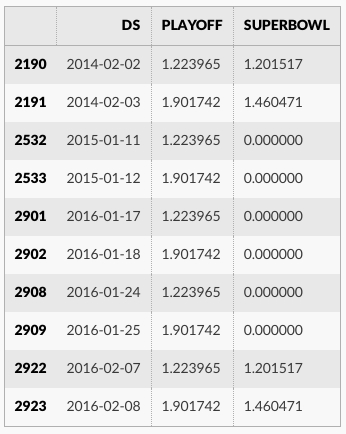
休日効果は予測データフレーム内で見ることができます :
forecast[(forecast['playoff'] + forecast['superbowl']).abs() > 0][
['ds', 'playoff', 'superbowl']][-10:]
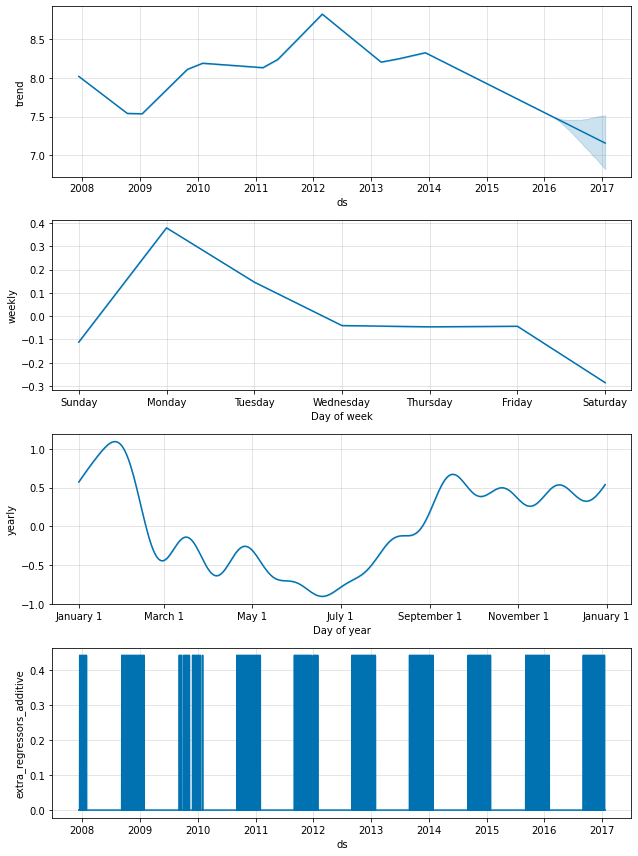
休日効果はまた成分プロット内にも現れます、そこではプレーオフ出場周りの日々でスパイクがあり、スーパーボウルに対しては特に巨大なスパイクがあります :
fig = m.plot_components(forecast)
スーパボウル休日成分だけをプロットする plot_forecast_component(m, forecast, ‘superbowl’) のように、(Python で prophet.plot からインポートされる) plot_forecast_component 関数を使用して個々の休日をプロットできます。
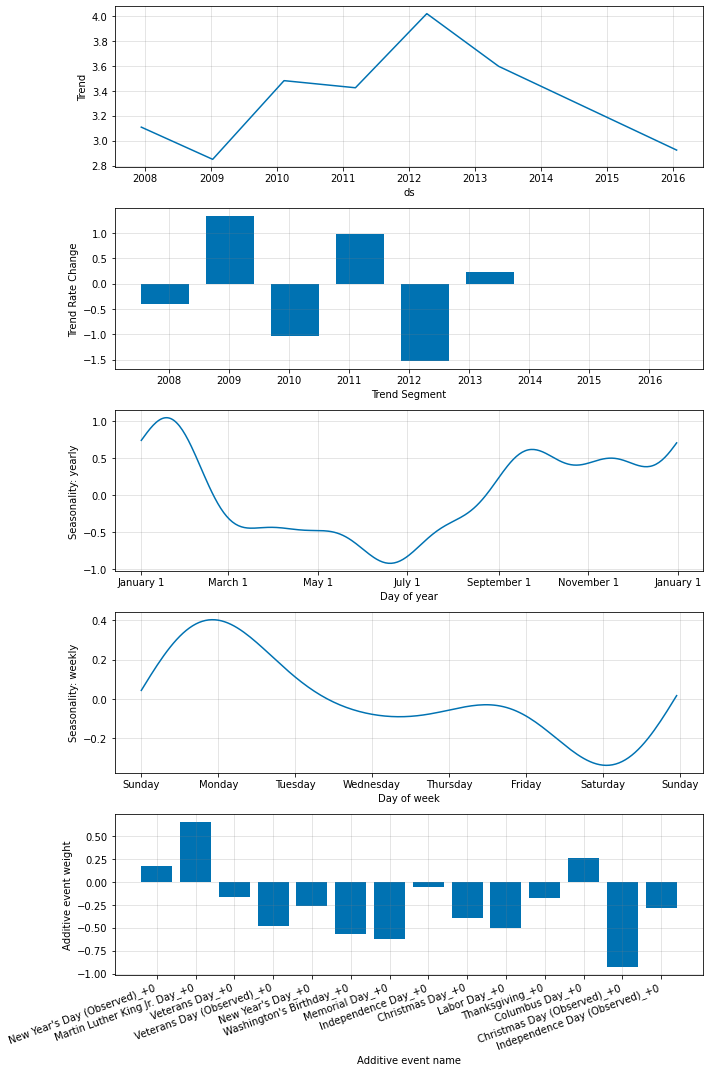
組込みの国の休日
add_country_holidays メソッド (Python) や関数 (R) を使用して国固有の休日の組込みコレクションを使用できます。国の名前が指定されると、上述の holidays 引数を通して指定された任意の休日に加えて、その国のための主要な休日が含まれます :
m = Prophet(holidays=holidays)
m.add_country_holidays(country_name='US')
m.fit(df)
モデルの train_holiday_names (Python) か train.holiday.names (R) 属性を見ることによりどの休日が含まれたかを見ることができます :
m.train_holiday_names
0 playoff 1 superbowl 2 New Year's Day 3 Martin Luther King Jr. Day 4 Washington's Birthday 5 Memorial Day 6 Independence Day 7 Labor Day 8 Columbus Day 9 Veterans Day 10 Thanksgiving 11 Christmas Day 12 Christmas Day (Observed) 13 Veterans Day (Observed) 14 Independence Day (Observed) 15 New Year's Day (Observed) dtype: object
各国のための休日は Python の holidays パッケージにより提供されます。利用可能な国のリストと使用する国名はページ : https://github.com/dr-prodigy/python-holidays で利用可能です。それらの国に加えて、Prophet はこれらの国のための休日を含みます : ブラジル (BR), インドネシア (ID), インド (IN), マレーシア (MY), ベトナム (VN), タイ (TH), フィリッピン (PH), パキスタン (PK), バングラディシュ (BD), エジプト (EG), 中国 (CN), そしてロシア (RU), 韓国 (KR), ベラルーシ (BY), そしてアラブ首長国連邦 (AE) です。
※ 訳注 : 日本 (JP) (08/31/2023 : 以前に使用可能であった JPN は削除されたようです。)
Python では、殆どの休日は決定論的に計算されますので任意の日付範囲で利用可能です ; 日付がその国でサポートされる範囲に入らない場合、警告が上げられます。R では、休日の日付は 1995 年から 2044 年まで計算されて data-raw/generated_holidays.csv としてパッケージにストアされています。より広い日付範囲が必要であれば、このスクリプトがそのファイルを異なる日付範囲と置き換えるために使用できます : https://github.com/facebook/prophet/blob/main/python/scripts/generate_holidays_file.py 。
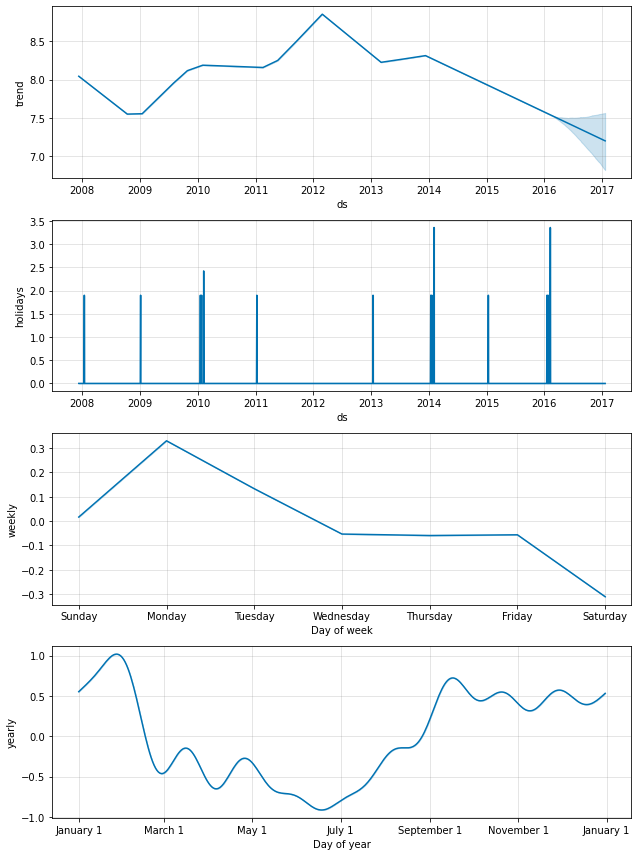
上記のように、国レベルの休日は成分プロットで現れます :
forecast = m.predict(future)
fig = m.plot_components(forecast)
季節性のフーリエ次数
季節性は部分フーリエ和を使用して推定されます。完全な詳細は 論文 を、そして部分フーリエ和がどのように任意の周期信号を近似できるかの例示については Wikipedia のこの図 を見てください。部分和の項の数 (次数) はどのくらい素早く季節性が変化するかを決定するパラメータです。これを説明するために、クイックスタート からの Peyton Manning データを考えます。yearly 季節性のためのデフォルトのフーリエ次数は 10 で、これはこの適合を生成します :
from prophet.plot import plot_yearly
m = Prophet().fit(df)
a = plot_yearly(m)
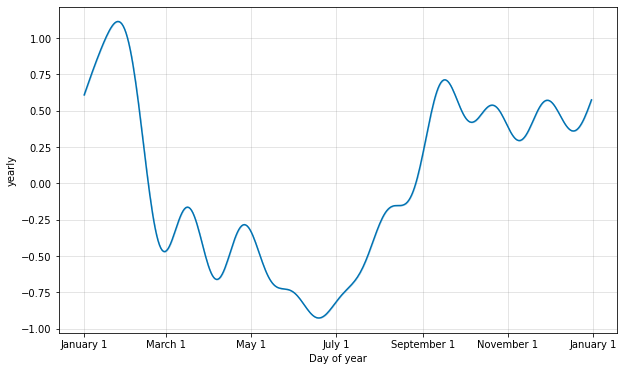
デフォルト値は適切である場合が多いですが、季節性がより高い頻度の変化に適合する必要があるとき、それらは増やすことができます、そして一般に滑らかでなくなります。フーリエ次数はモデルをインスタンス化するとき各組込みの季節性のために指定できます、ここではそれは 20 に増やされています :
from prophet.plot import plot_yearly
m = Prophet(yearly_seasonality=20).fit(df)
a = plot_yearly(m)
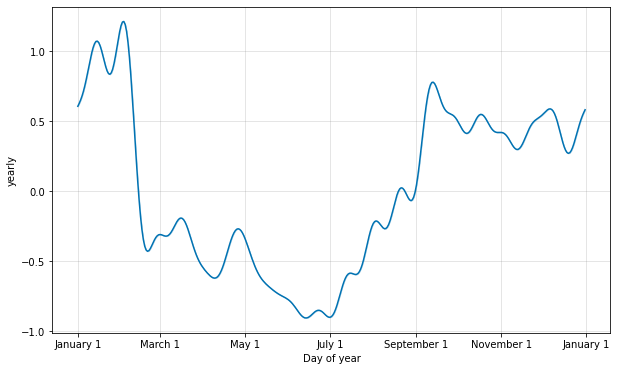
フーリエ項の数を増やすことは季節性を高速に変化するサイクルに適合させることを可能にしますが、過剰適合に繋がる可能性もあります : N 個のフーリエ項はサイクルをモデル化するために使用される 2N 変数に相当します。
カスタム季節性を指定する
Prophet は時系列が 2 つのサイクル長を越える場合、デフォルトで weekly と yearly の季節性に適合させます。それはまた部分的な daily 時系列のために daily の季節性にも適合させます。add_seasonality メソッド (Python) or 関数 (R) を使用して他の季節性 (monthly, quarterly, hourly) を追加することができます。
この関数への入力は名前、季節性の期間 (period) (in days)、そして季節性のためのフーリエ次数です。参考までに、デフォルトでは Prophet は weekly 季節性のために 3 のフーリエ次数をそして yearly 季節性のために 10 を使用します。add_seasonality へのオプションの入力はその季節性成分のための prior scale です – これは下で議論されます。
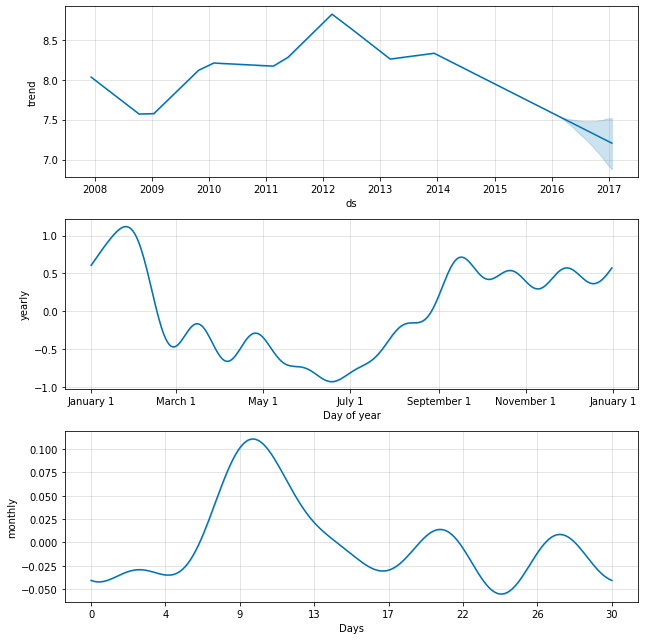
例として、ここでは クイックスタート から Peyton Manning データを適合させますが、weekly 季節性を monthly 季節性で置き換えます。そして monthly 季節性は成分プロットに現れます :
m = Prophet(weekly_seasonality=False)
m.add_seasonality(name='monthly', period=30.5, fourier_order=5)
forecast = m.fit(df).predict(future)
fig = m.plot_components(forecast)
他の要因に依存する季節性
ある場合には、夏の間は年の残りの間とは異なるような weekly 季節パターンや、週末 vs 平日で異なるような daily 季節パターンのように、季節性は他の要因に依存するかもしれません。これらのタイプの季節性は条件付き季節性を使用してモデル化できます。
クイックスタート からの Peyton Manning サンプルを考えます。デフォルトの weekly 季節性は、weekly 季節性のパターンが一年を通して同じであることを仮定していますが、(毎日曜日に試合がある) オンシーズン中とオフシーズンの間では weekly 季節性のパターンが異なることを私たちは予想します。個別のオンシーズンとオフシーズンの weekly 季節性を構築するために条件付き季節性を使用できます。
最初にデータフレームにブーリアン・カラムを追加します、これは各日付がオンシーズンかオフシーズンにあるかを示します :
def is_nfl_season(ds):
date = pd.to_datetime(ds)
return (date.month > 8 or date.month < 2)
df['on_season'] = df['ds'].apply(is_nfl_season)
df['off_season'] = ~df['ds'].apply(is_nfl_season)
そして組込みの weekly 季節性を無効にして、それを、条件として指定されたこれらのカラムを持つ 2 つの weekly 季節性で置き換えます。これは、季節性は condition_name カラムが True である日付にだけ適用されることを意味します。また (そのために) 予測を行なう future データフレームにカラムを追加しなければなりません。
m = Prophet(weekly_seasonality=False)
m.add_seasonality(name='weekly_on_season', period=7, fourier_order=3, condition_name='on_season')
m.add_seasonality(name='weekly_off_season', period=7, fourier_order=3, condition_name='off_season')
future['on_season'] = future['ds'].apply(is_nfl_season)
future['off_season'] = ~future['ds'].apply(is_nfl_season)
forecast = m.fit(df).predict(future)
fig = m.plot_components(forecast)
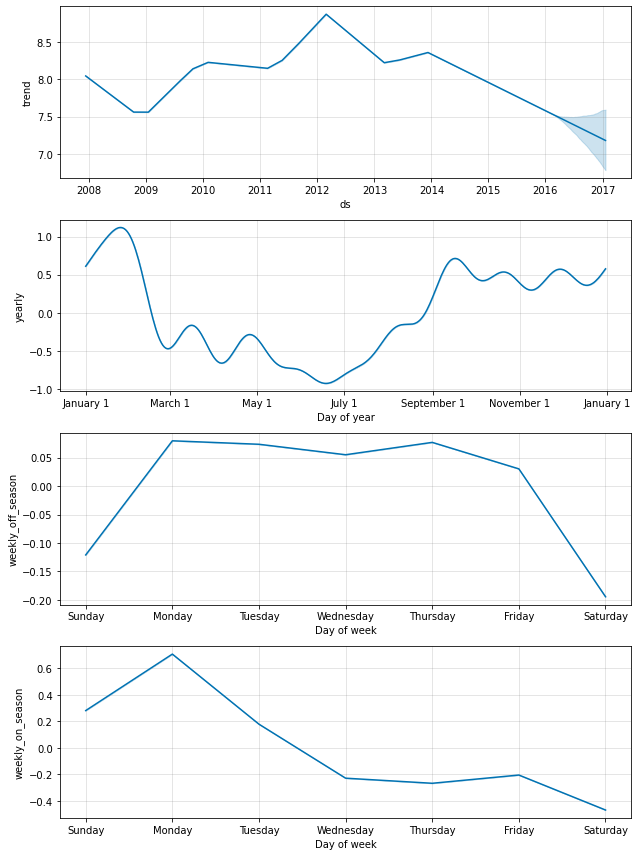
両方の季節性が今では上記の成分プロットに現れます。ゲームが毎土曜日にプレーされるオンシーズンの間、日曜日と月曜日に大規模な増加があることが見れますが、オフシーズンの間にはまったくありません。
休日と季節性のための Prior (事前) スケール
休日が過剰適合していることを見つける場合、パラメータ holidays_prior_scale を使用してそれらを滑らかにするために prior スケールを調整できます。デフォルトではこのパラメータは 10 で、それは正則化を殆ど提供しません。このパラメータを減少させると休日効果を減衰させます :
m = Prophet(holidays=holidays, holidays_prior_scale=0.05).fit(df)
forecast = m.predict(future)
forecast[(forecast['playoff'] + forecast['superbowl']).abs() > 0][
['ds', 'playoff', 'superbowl']][-10:]
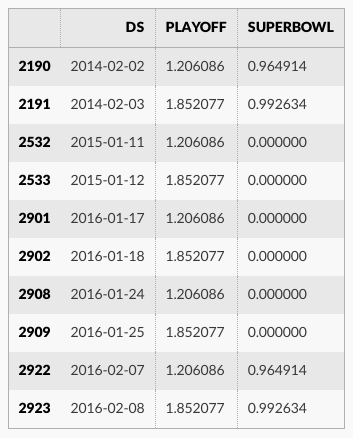
休日効果の大きさは前に比べて減少しています、特にスーパーボウルについて、これは最も少ない観測を持ちました。季節性モデルがデータに適合する範囲を同様に調整するパラメータ seasonality_prior_scale があります。
prior スケールは、holidays データフレーム内にカラム prior_scale を含めることにより個々の休日のために個別に設定できます。個々の季節性のための prior スケールは add_seasonality への引数として渡すことができます。例えば、weekly 季節性のためだけの prior スケールは次を使用して設定できます :
m = Prophet()
m.add_seasonality(
name='weekly', period=7, fourier_order=3, prior_scale=0.1)
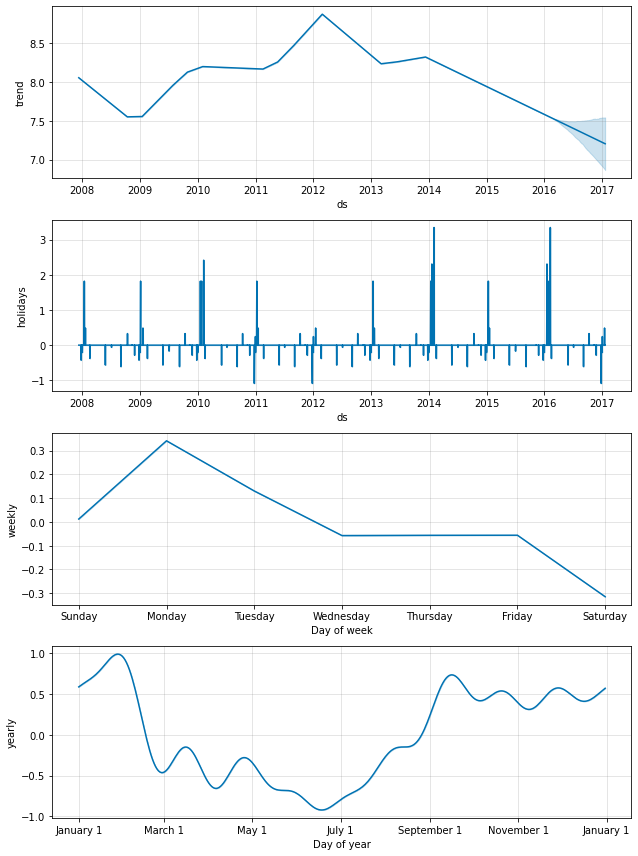
追加のリグレッサー
add_regressor メソッドか関数を使用して追加のリグレッサーがモデルの線形部分に追加できます。regressor 値を持つカラムは fitting と prediction データフレームの両方で存在する必要があります。例えば、NFL シーズンの間の日曜日に追加の効果を追加することができます。成分プロットでは、この効果は ‘extra_regressors’ プロットに現れます :
def nfl_sunday(ds):
date = pd.to_datetime(ds)
if date.weekday() == 6 and (date.month > 8 or date.month < 2):
return 1
else:
return 0
df['nfl_sunday'] = df['ds'].apply(nfl_sunday)
m = Prophet()
m.add_regressor('nfl_sunday')
m.fit(df)
future['nfl_sunday'] = future['ds'].apply(nfl_sunday)
forecast = m.predict(future)
fig = m.plot_components(forecast)
NFL サンデーはまた過去と未来の NFL サンデーのリストを作成して、上述の “holidays” インターフェイスを使用して処理されました。add_regressor 関数は追加の (= extra) 線形リグレッサーを定義するためにより一般的なインターフェイスを提供し、そして特にリグレッサーは二値インジケーターであることを必要としません。別の時系列をリグレッサーとして使用できるでしょうが、その future 値は知られなければなりません。
このノートブック は自転車 (bicycle) の使用量の予測において追加のリグレッサーとして天気要因を使用する例を示し、そして他の時系列が追加のリグレッサーとして含まれる方法の優れた例を提供します。
add_regressor 関数は prior スケール (デフォルトでは holiday prior スケールが使用されます) とリグレッサーが標準化されているか否かを指定するためのオプション引数を持ちます - Python の help(Prophet.add_regressor) そして R の ?add_regressor で docstring を見てください。リグレッサーはモデル適合の前に追加されなければならないことに注意してください。Prophet はまたリグレッサーが履歴を通して定数である場合にはエラーを上げます、何故ならばそれから適合するものがないからです。
追加のリグレッサーは履歴と未来の日付の両方のために知られなければなりません。従ってそれは (nfl_sunday のように) 未来の値を知っているものか、あるいは他で別に予測された何かでなければなりません。上でリンクされたノートブックで使用される天気リグレッサーは未来値のために使用できる予測を持つ追加のリグレッサーの良いサンプルです。Prophet のような時系列モデルで予測された別の時系列をリグレッサーとして使用することもできます。例えば、r(t) が y(t) のためのリグレッサーとして含まれる場合、Prophet は r(t) を予測するために使用できてそしてその予測は y(t) を予測するとき未来値としてプラグインできます。このアプローチまわりの注意点は : これは r(t) が y(t) を予測するのが幾分容易でない限りは多分役立ちません。これは r(t) の予測誤差が y(t) の予測で誤差を生成するからです。これが有用であり得る一つの設定は階層型時系列内です、そこでは高い信号対雑音 (= signal-to-noise) を持ち予測が容易なトップレベルの予測があります。その予測は各下位レベルの系列のための予測に含めることができます。
追加のリグレッサーはモデルの線形成分に配置されますので、基礎的なモデルは、加法 or 乗法要因のいずれかとして時系列が追加のリグレッサーに依存します (乗法のためには次のセクション参照)。
追加のリグレッサーの係数
追加のリグレッサーの beta 係数を抽出するため、適合されたモデル上でユティリティ関数 regressor_coefficients を使用します (Python では from prophet.utilities import regressor_coefficients, R では prophet::regressor_coefficients)。各リグレッサーのための推定された beta 係数はリグレッサー値の単位増加に対する予測値の増加をおおよそ表します (返される係数は常に元のデータのスケールであることに注意してください)。mcmc_samples が指定される場合、各係数の信用区間 (= credible interval) も返されます、これは各レグレッサーが「統計的に有意である」かを識別するのに役立ちます。
以上
Prophet 1.1 : クイックスタート
Prophet 1.1 : クイックスタート (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 08/29/2023 (1.1.4)
* 本ページは、Prophet の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。
- 人工知能研究開発支援
- 人工知能研修サービス(経営者層向けオンサイト研修)
- テクニカルコンサルティングサービス
- 実証実験(プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
- PoC(概念実証)を失敗させないための支援
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
- 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション
- sales-info@classcat.com ; Web: www.classcat.com ; ClassCatJP
Prophet 1.1 : クイックスタート
Python API
Prophet は sklearn モデル API に従います。Prophet クラスのインスタンスを作成してからその fit と predict メソッドを呼び出します。
Prophet への入力は常に 2 つのカラム : ds と y を含むデータフレームです。ds (datestamp) カラムは Pandas により想定される形式である必要があり、理想的には日付のための YYYY-MM-DD またはタイムスタンプのための YYYY-MM-DD HH:MM:SS です。y カラムは数値でなければなりません、そして予測したい測定値を表します。
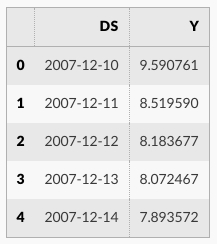
例として、 Peyton Manning のための Wikipedia ページのログの daily ページビューの時系列を見てみましょう。このデータを R の Wikipediatrend パッケージを使用してかき集めました (scraped)。Peyton Manning は良いサンプルを提供します、何故ならばそれは複数の季節性 (= seasonality)、成長率の変化、そして (Manning のプレーオフとスーパーボウルの出現のような) 特別な日をモデル化する機能のような Prophet の機能の幾つかを例示するからです。CSV は ここ で利用可能です。
最初にデータをインポートします :
import pandas as pd
from prophet import Prophet
df = pd.read_csv('https://raw.githubusercontent.com/facebook/prophet/main/examples/example_wp_log_peyton_manning.csv')
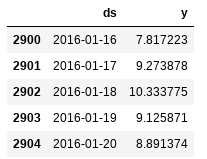
df.head()
df.tail()
df.count()
ds 2905 y 2905 dtype: int64
新しい Prophet オブジェクトをインスタンス化することによりモデルを適合させます。予測手続きへの任意の設定はコンストラクタに渡されます。そしてその fit メソッドを呼び出して履歴データフレームを渡します。フィッティングには 1-5 秒かかるはずです。
m = Prophet()
m.fit(df)
そして予測は (そのために予測が行われる) 日付を含むカラム ds を持つデータフレーム上で行なわれます。ヘルパーメソッド Prophet.make_future_dataframe を使用して指定された日数だけ future 内に拡張した適切なデータフレームを得ることができます。デフォルトではそれは履歴からの日付も含みますので、モデルの適合も分かります。
future = m.make_future_dataframe(periods=365)
future.tail()
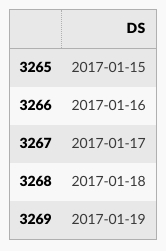
predict メソッドは future の各行に予測された値を割当てます、それは yhat と名前付けられます。履歴日付を渡す場合、それは in-sample な適合を提供します。ここで forecast オブジェクトは新しいデータフレームで、それは予測を持つカラム yhat と、成分と不確定区間のためのカラムを含みます。
forecast = m.predict(future)
forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].tail()
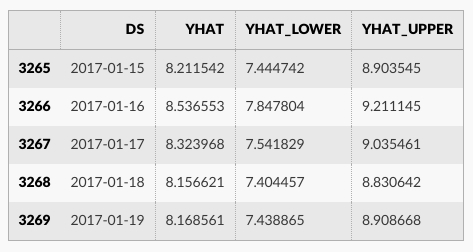
Prophet.plot メソッドを呼び出して forecast データフレームを渡すことにより予測をプロットできます。
fig1 = m.plot(forecast)
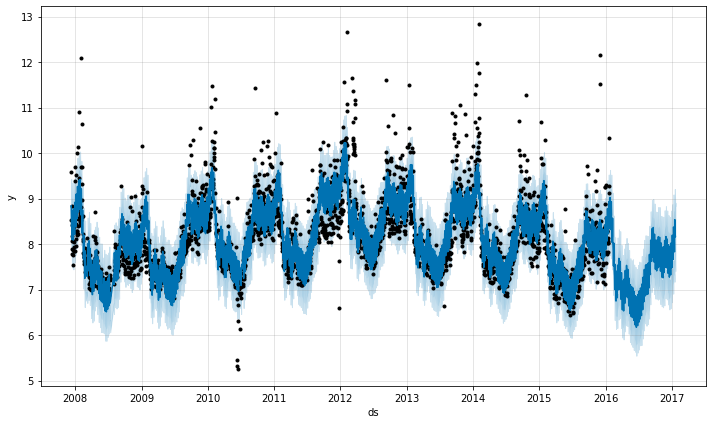
予測成分を見ることを望む場合、Prophet.plot_components メソッドを利用できます。デフォルトでは、時系列のトレンド、yearly 季節性と weekly 季節性を見ます。休日を含める場合、ここでそれらも見ます。
fig2 = m.plot_components(forecast)
予測と成分の対話的な図は plotly で作成できます。plotly 4.0 かそれ以上を個別にインストールする必要があります、それはデフォルトでは prophet と共にインストールされないからです。notebook と ipywidgets パッケージをインストールする必要もあります。
from prophet.plot import plot_plotly, plot_components_plotly
plot_plotly(m, forecast)
plot_components_plotly(m, forecast)
各メソッドのために利用可能なオプションについての詳細は docstrings で利用可能です、例えば help(Prophet) や help(Prophet.fit) を通してです。CRAN の R リファレンスマニュアル は利用可能な関数の総ての正確なリストを提供します、それらの各々は Python 同値を持ちます。
以上
sktime 0.7 : チュートリアル (1) sktime で予測する
sktime 0.7 : チュートリアル (1) sktime で予測する (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 07/30/2021 (v0.7.0)
* 本ページは、sktime の以下のノートブックを翻訳した上で適宜、補足説明したものです:
- Tutorials : Forecasting with sktime
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。
- 人工知能研究開発支援
- 人工知能研修サービス(経営者層向けオンサイト研修)
- テクニカルコンサルティングサービス
- 実証実験(プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
- PoC(概念実証)を失敗させないための支援
- テレワーク & オンライン授業を支援
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |
sktime 0.7 : チュートリアル (1) sktime で予測する
セットアップ手順 : このノートブックは sktime でサポートされる予測学習タスクのチュートリアルを与えます。binder では、これはそのまま実行できるはずです。
このノートブックを意図したとおりに実行するには、基本的な依存性 requirements とともに sktime が貴方の python 環境にインストールされていることを確実にしてください。
sktime のローカル開発版でこのノートブックを実行するには、以下をアンコメントして実行するか、sktime main ブランチのローカル・クローンを “pip install -e” します。
# from os import sys
# sys.path.append("..")
◆ 予測では、時系列の時間的前方予測を行なうために過去のデータが使用されます。これは scikit-learn と類似のライブラリによりサポートされる表形式予測タスクと顕著に異なります。
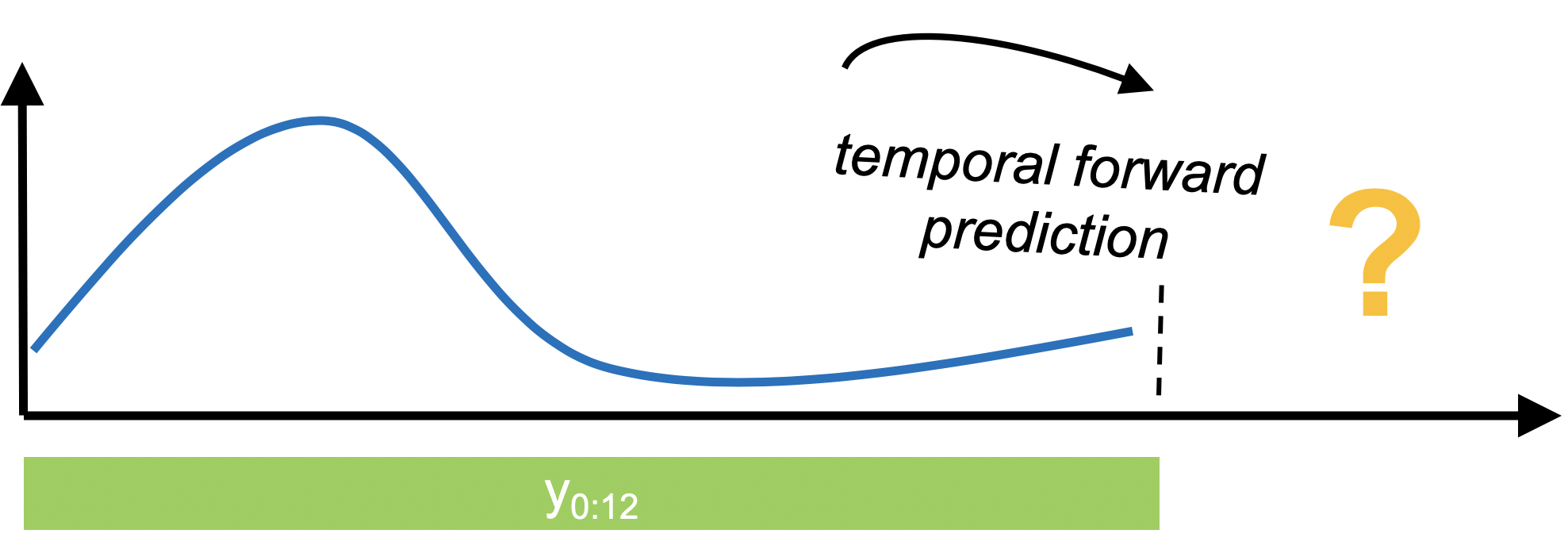
sktime は様々な古典的そして ML-スタイルの予測アルゴリズムに一般的な、scikit-learn ライクなインターフェイスを時間調整スキームを含む、パイプラインと合成的な機械学習モデルを構築するためのツール、あるいは scikit-learn リグレッサーの walk-forward アプリケーションのようなリダクションとともに提供します。
- セクション 1 は sktime によりサポートされる一般的な予測ワークフローの概要を提供します。
- セクション 2 は sktime で利用可能な予測器のファミリーを説明します。
- セクション 3 はパイプライン構築、リダクション、調整、アンサンブルと autoML を含む、高度な合成パターンを説明します。
- セクション 4 は sktime インターフェイスに準拠するカスタム推定器をどのように書くかのイントロダクションを与えます。
その他のリファレンス :
- 予測が教師あり予測とどのように異なるかの更なる詳細、そして予測を教師あり予測として誤診する落とし穴については、このノートブック を見てください。
- 科学的なリファレンスについては、sktime による予測の論文 を見てください、ここでは sktime の予測モジュールを詳しく説明して M4 study を複製して拡張するためにそれを利用します。
基本的な予測ワークフロー
パッケージのインポート
import numpy as np
import pandas as pd
このセクションは基本的な予測ワークフロー、そしてそのための主要なインターフェイス・ポイントを説明します、
以下の 3 つのワークフローをカバーします (訳注: 原文ママ) :
- 基本的な配備ワークフロー : 適合と予測のバッチ処理
- 基本的な評価ワークフロー : 正解観測に対する予測のバッチの評価
- 上位配備ワークフロー : 適合と更新/予測のローリング
- 上位評価ワークフロー : ローリング予測分割を使用して、一般的なバックテスト・スキームを含む分割毎と集計誤差を計算します。
1.1 データ・コンテナ形式
総てのワークフローは入力データ形式に共通の仮定を持ちます。
sktime は時系列を表すために pands を利用します :
- 単変量時系列とシークエンスのための pd.Series
- 多変量時系列とシークエンスのための pd.Series
Series.index and DataFrame.index は時系列やシークエンスのインデックスを表すために使用されます。sktime は pandas の integer, period と timestamp インデックスをサポートします。
NOTE : 現時点 (v0.6x) では、多変量時系列の予測は安定的な機能ではありません、これは優先的なロードマップ項目です。多変量外因的な時系列は安定的な機能の一部です。
Example : このチュートリアルの実行例として、テキストブックのデータセット、Box-Jenkins 航空会社データセットを使用します、これは 1949 – 1960 の国際航空会社の旅客の月間合計数から成ります。値は千単位です。”Makridakis, Wheelwright and Hyndman (1998) Forecasting: 手法とアプリケーション”, 課題セクション 2 と 3 を見てください。
from sktime.datasets import load_airline
from sktime.utils.plotting import plot_series
y = load_airline()
# plotting for visualization
plot_series(y)
y.index
一般に、ユーザは予測のためのデータセットをロードするために read_csv のような pandas と pandas 互換パッケージの組込みロード機能や、データが他のインメモリ形式 e.g., numpy.array で利用可能な場合には Series or DataFrame コンストラクタを使用することが想定されています。
sktime 予測器は pandas 隣接 (= pandas-adjacent) 形式の入力を受け取るかもしれませんが、pandas 形式で出力を生成し、そして (pandas 形式で) 入力を強制しようとします。
Note : 貴方の好みの形式に正しく変換あるいは強制されない場合、その機能を sktime に親切に寄与することを考えてください。
1.2 基本的な配備ワークフロー – 適合と予測のバッチ処理
最も単純なユースケース・ワークフローは適合と予測のバッチ処理です、つまり、予測モデルを過去のデータの 1 つのバッチに適合させてから、未来の時間ポイントで予測を要求します。
このワークフローのステップは以下のようなものです :
- データの準備
- 予測がリクエストされる時間ポイントの仕様。これは numpy.array or ForecastingHorizon オブジェクトを使用します。
- 予測器の仕様とインスタンス化。これは scikit-learn ライクなシンタクスに従います ; 予測器オブジェクトはお馴染みの scikit-learn BaseEstimator インターフェイスに従います。
- 予測器の fit メソッドを使用して、予測器をデータに適合させます。
- 予測器の predict メソッドを使用して、予測を行ないます。
下では最初に基本的な配備ワークフローの vanilla 変種を段階的に概説します。
最後に、パターンからの一般的な deviations を伴う、1 セル・ワークフローが提供されます (セクション 1.2.1 とそれ以降)。
ステップ 1 – データの準備
セクション 1.1 で説明されたように、データは pd.Series or pd.DataFrame 形式にあることが仮定されています。
from sktime.datasets import load_airline
from sktime.utils.plotting import plot_series
# in the example, we use the airline data set.
y = load_airline()
plot_series(y)
ステップ 2 – 予測期間を指定する
次に予測期間を指定してそれを予測アルゴリズムに渡す必要があります。
2 つの主要な方法があります :
- 整数の numpy.array を使用する。これは時系列の整数インデックスか periodic インデックスのいずれかを想定しています ; 整数は (そのために) 前もって予測したい時間ポイントか期間の数を示します。E.g., 1 は次の期間を予測すること、2 は 2 番目の次の期間を予測することを意味します、等々。
- ForecastingHorizon を使用する。これは引数としてサポートされるインデックス型を使用して、予測範囲を定義するために使用できます。periodic インデックスは想定されていません。
予測範囲は絶対的、つまり未来の特定の時間ポイントを参照するか、相対的、つまり現在までの時間差を参照することができます。デフォルトとして、現在は予測器に渡される任意の y で見られる最新の時間ポイントです。
numpy.array ベースの予測範囲は常に相対的です ; ForecastingHorizon オブジェクトは相対的と絶対的にの両者であることが可能です。特に絶対的予測範囲は ForecastingHorizon を使用してのみ指定できます。
numpy 予測範囲を使用する
fh = np.arange(1, 37)
fh
これは次の 3 年間の monthly 予測を求めます、何故ならば元の系列期間は 1 ヶ月だからです。別の例では、先の 2 番目と 5 番目の月だけを予測するために、次のように書けます :
import numpy as np
fh = np.array([2, 5]) # 2nd and 5th step ahead
ForecastingHorizon ベースの予測範囲を使用する
ForecastingHorizon オブジェクトは入力として絶対的インデックスを取りますが、is_relative フラグに応じて入力を絶対的または相対的と見なします。
pandas から時間差タイプが渡される場合、ForecastingHorizon は自動的に相対的範囲を想定します ; pandas から値タイプが渡される場合、それは絶対的範囲を想定します。
この例で絶対的な ForecastingHorizon を定義するためには :
from sktime.forecasting.base import ForecastingHorizon
fh = ForecastingHorizon(
pd.PeriodIndex(pd.date_range("1961-01", periods=36, freq="M")), is_relative=False
)
fh
ForecastingHorizon は to_relative と to_absolute メソッドを通して相対的から絶対的に (そしてその反対に) 変換できます。
これらの変換の両者は互換なカットオフが渡されることを要求します :
cutoff = pd.Period("1960-12", freq="M")
fh.to_relative(cutoff)
fh.to_absolute(cutoff)
ステップ 3 – 予測アルゴリズムを指定する
予測を行なうためには、予測アルゴリズムが指定される必要があります。これは scikit-learn のようなインターフェイスを使用して成されます。最も重要なことは、総ての sktime 予測器が同じインターフェイスに従いますので、どの予測器が選択されても、これまでのそして残りのステップが同じであることです。
この例については、最後の観測値を予測する naive 予測メソッドを選択します。パイプラインとリダクション構築シンタクスを使用して、より複雑な仕様が可能です。これはセクション 2 で後でカバーされます。
from sktime.forecasting.naive import NaiveForecaster
forecaster = NaiveForecaster(strategy="last")
ステップ 4 – 予測器を観測データに適合させる
今は予測器は観測値に適合される必要があります :
forecaster.fit(y)
ステップ 5 – 予測を要求する
最後に、指定された予測範囲のための予測を要求します。予測器に適合させた後これは成される必要があります :
y_pred = forecaster.predict(fh)
# plotting predictions and past data
plot_series(y, y_pred, labels=["y", "y_pred"])
基本的な配備ワークフロー (in a nutshell)
便利のために、基本的な配備ワークフローを一つのセルで表します。これは同じデータを使用しますが、異なる予測器です : 同じ月に観測された最新の値を予測します。
from sktime.datasets import load_airline
from sktime.forecasting.base import ForecastingHorizon
from sktime.forecasting.naive import NaiveForecaster
# step 1: data specification
y = load_airline()
# step 2: specifying forecasting horizon
fh = np.arange(1, 37)
# step 3: specifying the forecasting algorithm
forecaster = NaiveForecaster(strategy="last", sp=12)
# step 4: fitting the forecaster
forecaster.fit(y)
# step 5: querying predictions
y_pred = forecaster.predict(fh)
# optional: plotting predictions and past data
plot_series(y, y_pred, labels=["y", "y_pred"])
… 翻訳中 …
以上
NeuralProphet 0.2 : ノートブック : 変化するトレンドへの適合 / トレンドの調整
NeuralProphet 0.2 : ノートブック : 変化するトレンドへの適合 / トレンドの調整 (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 07/25/2021 (Beta 0.2.7)
* 本ページは、NeuralProphet の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。
- 人工知能研究開発支援
- 人工知能研修サービス(経営者層向けオンサイト研修)
- テクニカルコンサルティングサービス
- 実証実験(プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
- PoC(概念実証)を失敗させないための支援
- テレワーク & オンライン授業を支援
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |
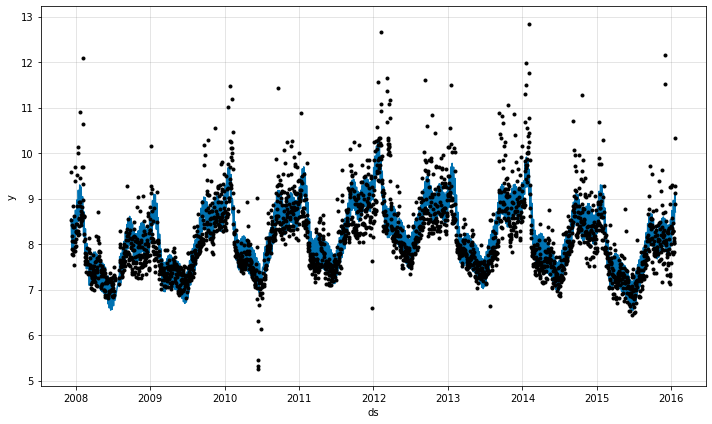
NeuralProphet 0.2 : ノートブック : 変化するトレンドに適合させる
変化するトレンドにどのように適合させるかを示すための例として Peyton Manning の Wikipedia ページのログ daily ページビューの時系列を使用します。
最初に、データをロードします :
if 'google.colab' in str(get_ipython()):
!pip install git+https://github.com/ourownstory/neural_prophet.git # may take a while
#!pip install neuralprophet # much faster, but may not have the latest upgrades/bugfixes
data_location = "https://raw.githubusercontent.com/ourownstory/neural_prophet/master/"
else:
data_location = "../"
import pandas as pd
from neuralprophet import NeuralProphet
df = pd.read_csv(data_location + "example_data/wp_log_peyton_manning.csv")
df.head(3)
今はどのようなカスタマイズもなく初期モデルを適合させることができます。
データ頻度を daily に指定します。モデルは後で未来を予測するときにこれを記憶します。
m = NeuralProphet()
metrics = m.fit(df, freq="D")
metrics.head(3)
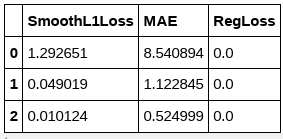
返されるメトリック・データフレームは各訓練エポックのための記録されたメトリックを含みます。
次に、その上で予測するためのデータフレームを作成します。ここでは、未来へ 1 年間を予測することを望みそして履歴全体を含めることを望むことを指定します。
future = m.make_future_dataframe(df, periods=365, n_historic_predictions=len(df))
future.tail(3)
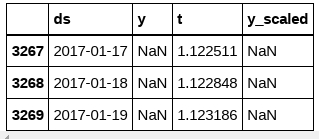
Note: 未来に拡張された期間の ‘y’ と ‘y_scaled’ は与えられません、それらの真の値を知らないからです。
forecast = m.predict(future)
print(list(forecast.columns))
['ds', 'y', 'yhat1', 'residual1', 'trend', 'season_yearly', 'season_weekly']
返された予測データフレームは元の日付スタンプ 、’y’ 値、予測された ‘yhat’ 値、残差と総ての個々のモデル・コンポーネントを含みます。
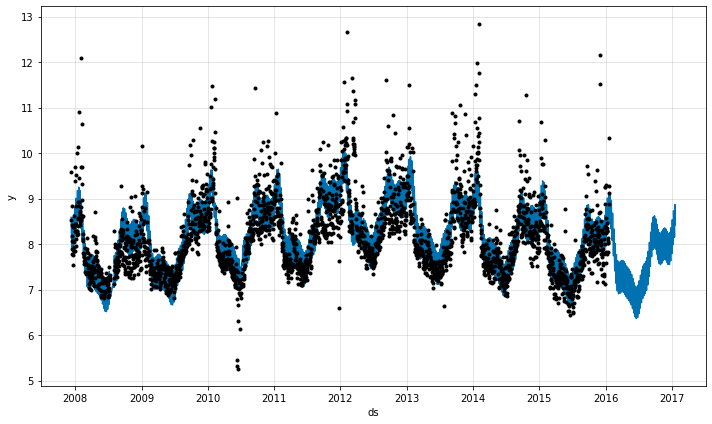
# plots the model predictions
fig1 = m.plot(forecast)
# plots the individual forecast components for the given time period.
# fig = m.plot_components(forecast, residuals=True)
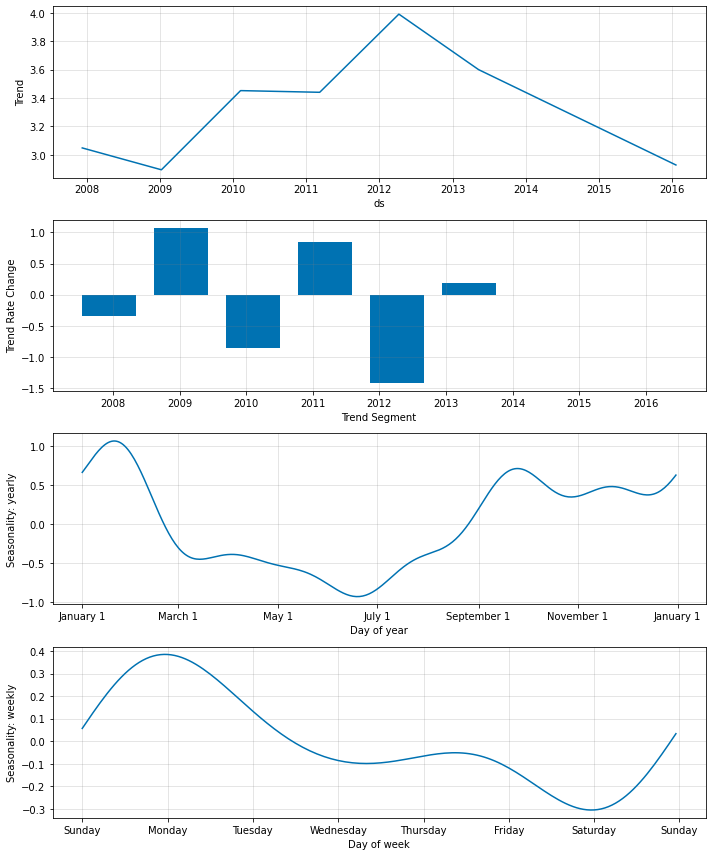
# visualizes the model parameters.
fig2 = m.plot_parameters()
NeuralProphet 0.2 : ノートブック : トレンドの調整
デフォルト値はこの例ではかなり上手く機能します。けれども、5 変更点のデフォルトはトレンドの実際の変化がポイント間の領域にたまたま収まる場合には十分ではないかもしれません。
トレンドの柔軟性の増加
過剰適合の危険性において、変化点の数を増やし、トレンドにより柔軟性を与えることでこれに対処できます。
変化点の数を 30 に増やす場合何が起きるか試しましょう。更に、最後の 10 % (デフォルトは 20 %) だけを除外するために (その上で) トレンド変化点を適合させるデータの範囲を増やすことができます。
m = NeuralProphet(
n_changepoints=30,
changepoints_range=0.90,
)
metrics = m.fit(df, freq="D")
future = m.make_future_dataframe(df, n_historic_predictions=len(df))
forecast = m.predict(future)
fig1 = m.plot(forecast)
fig2 = m.plot_parameters()
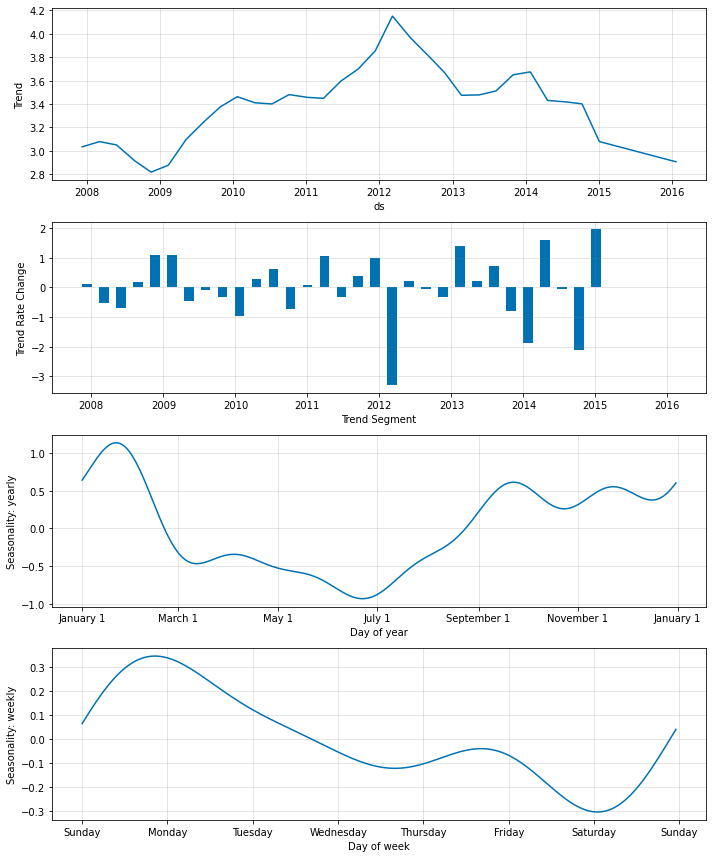
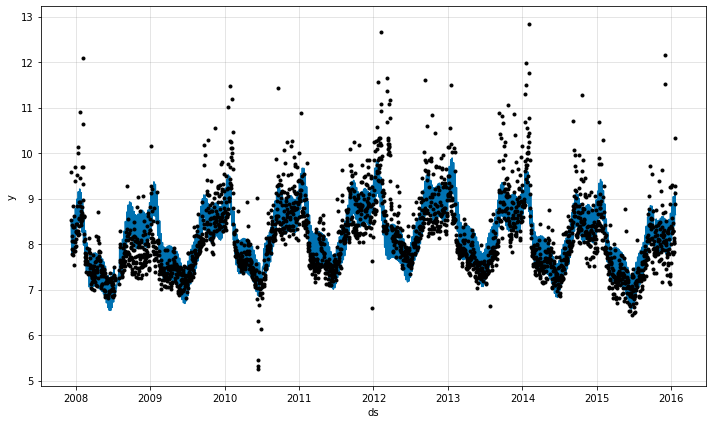
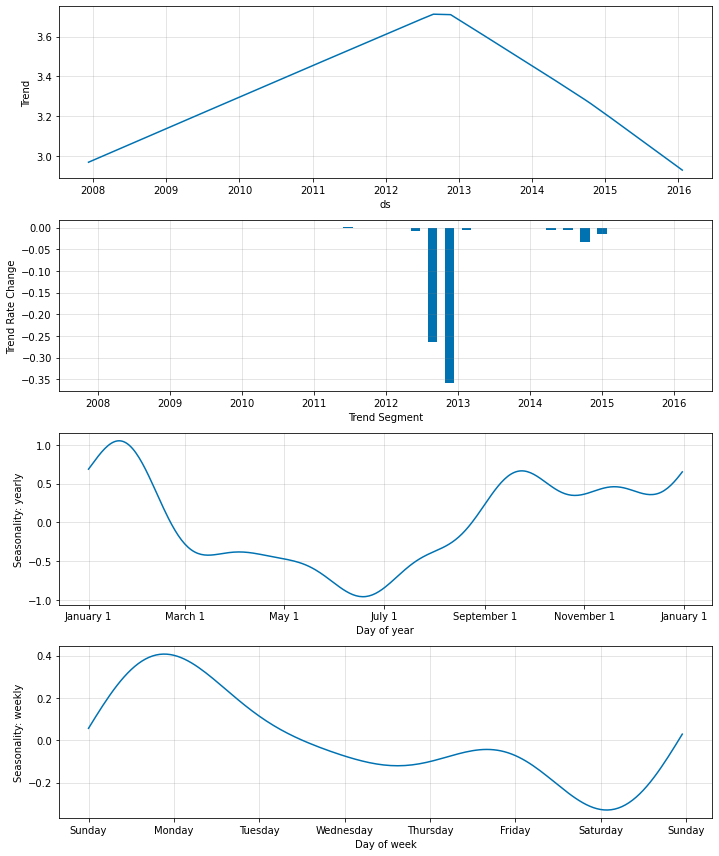
トレンドレートの変化を見ると、トレンドが短期的な変動に過剰適合していることが明白になります。
自動トレンドポイント選択
正則化を追加することで、最も関連性のある変化点の自動選択を実現できて、ゼロに近い他のポイントのレート変化を引き出すことができます。
m = NeuralProphet(
n_changepoints=30,
trend_reg=1.00,
changepoints_range=0.90,
)
metrics = m.fit(df, freq="D")
future = m.make_future_dataframe(df, n_historic_predictions=len(df))
forecast = m.predict(future)
fig1 = m.plot(forecast)
fig2 = m.plot_parameters()
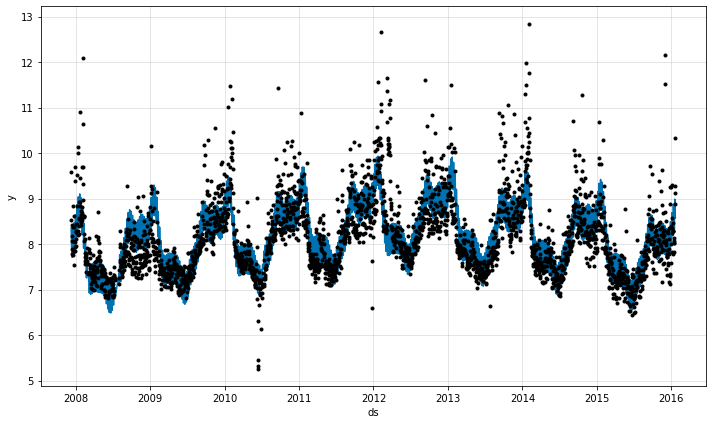
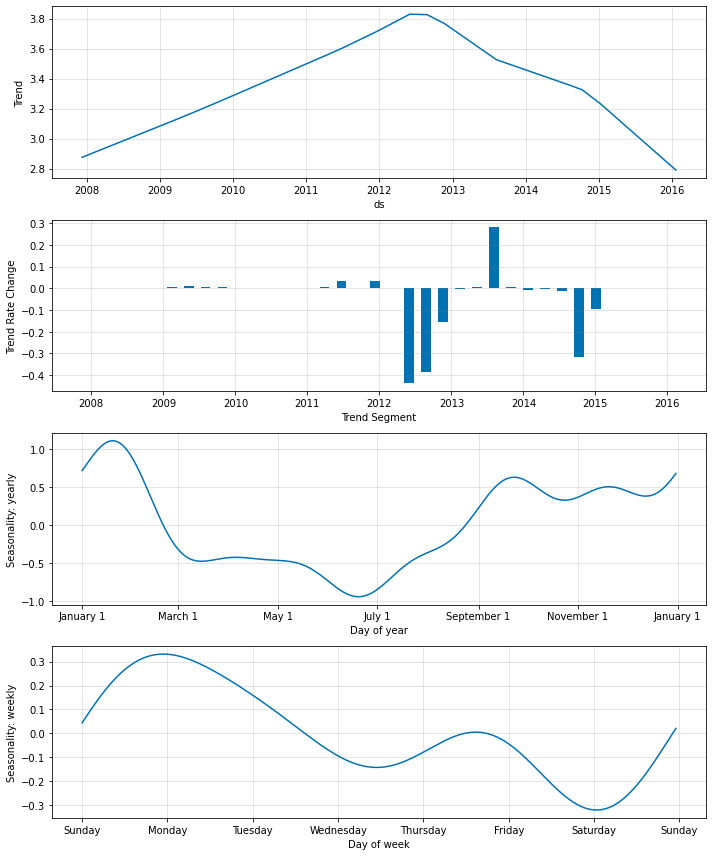
今は、モデルは幾つかの関連するトレンド変化点だけを選択して、残りをゼロに近づけます。
手動トレンド変化点
トレンド変化点を手動で指定することもできます。
Note: 変化点は常に最初に追加されます。それを無視することができます。
m = NeuralProphet(
changepoints=['2012-01-01', '2014-01-01'],
)
metrics = m.fit(df, freq="D")
future = m.make_future_dataframe(df, n_historic_predictions=len(df))
forecast = m.predict(future)
fig1 = m.plot(forecast)
fig2 = m.plot_parameters()
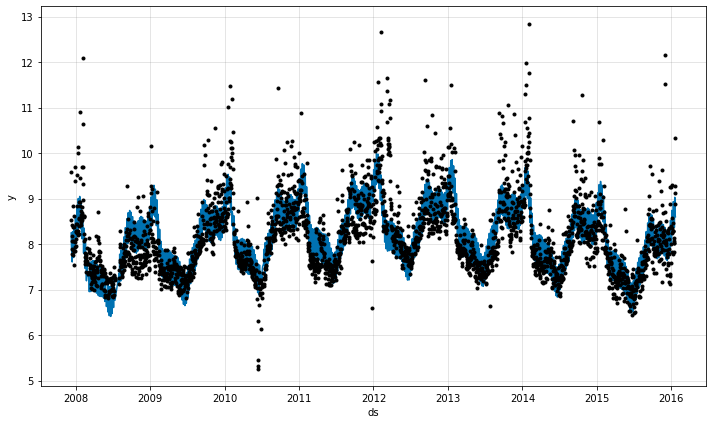
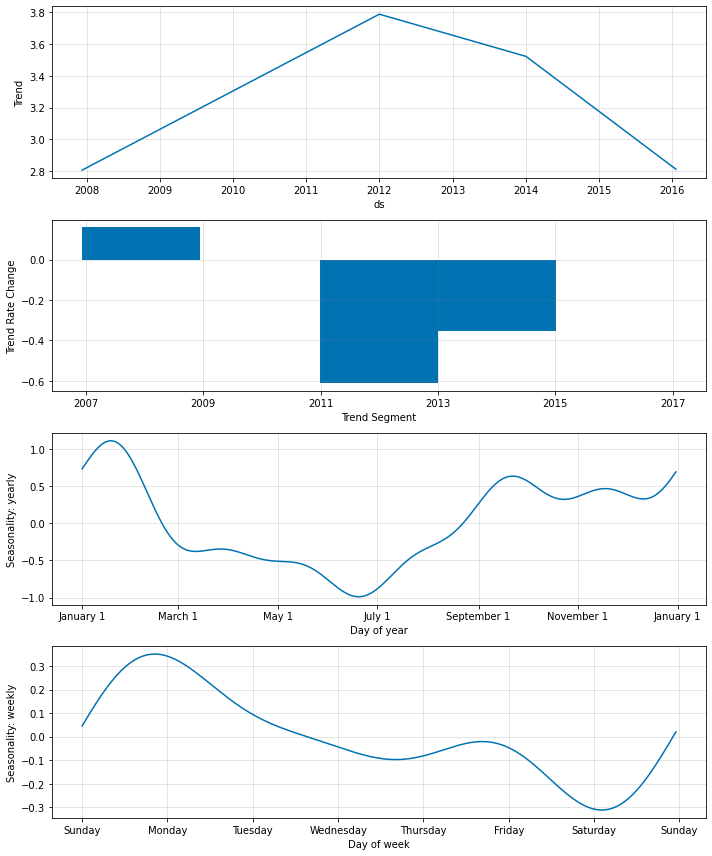
トレンドの柔軟性を微調整する
非ゼロ・レート変化を持つポイントを多かれ少なかれ得るために正則化の強さを調整できます。
Note : 高すぎる正則化強度については、モデルの適合プロセスが不安定になります。
m = NeuralProphet(
n_changepoints=30,
trend_reg=3.00,
changepoints_range=0.90,
)
metrics = m.fit(df, freq="D")
future = m.make_future_dataframe(df, n_historic_predictions=len(df))
forecast = m.predict(future)
fig1 = m.plot(forecast)
fig2 = m.plot_parameters()
以上
NeuralProphet 0.2 : ノートブック : Sub-daily データ
NeuralProphet 0.2 : ノートブック : Sub-daily データ (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 07/24/2021 (Beta 0.2.7)
* 本ページは、NeuralProphet の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。
- 人工知能研究開発支援
- 人工知能研修サービス(経営者層向けオンサイト研修)
- テクニカルコンサルティングサービス
- 実証実験(プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
- PoC(概念実証)を失敗させないための支援
- テレワーク & オンライン授業を支援
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |
NeuralProphet 0.2 : ノートブック : Sub-daily データ
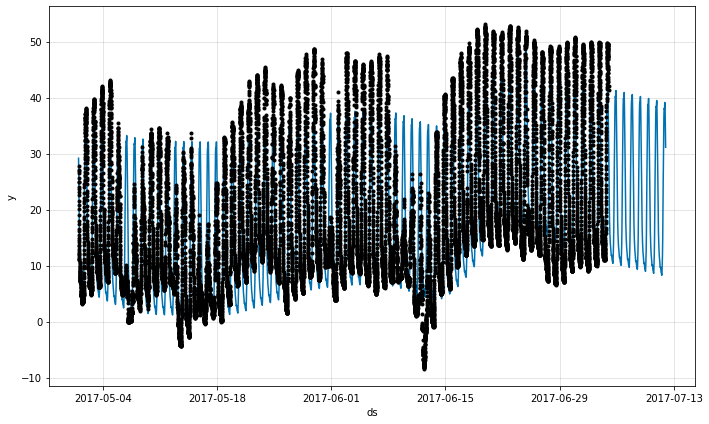
NeuralProphet は ds カラムでタイムスタンプを持つデータフレームを渡すことにより sub-daily 観測を持つ時系列のための予測を行なうことができます。タイムスタンプの形式は YYYY-MM-DD HH:MM:SS であるべきです – ここ のサンプル csv を参照してください。sub-daily データが使用されるとき、daily 季節性は自動的に適合しています。
ここでは NeuralProphet を 5 分解像度のデータに適合させます (Yosemite の毎日の気温)。
if 'google.colab' in str(get_ipython()):
!pip install git+https://github.com/ourownstory/neural_prophet.git # may take a while
#!pip install neuralprophet # much faster, but may not have the latest upgrades/bugfixes
data_location = "https://raw.githubusercontent.com/ourownstory/neural_prophet/master/"
else:
data_location = "../"
import pandas as pd
from neuralprophet import NeuralProphet, set_log_level
# set_log_level("ERROR")
df = pd.read_csv(data_location + "example_data/yosemite_temps.csv")
今は次の 7 日間を予測することを試みます。5 分データ解像度は 60/5*24=288 の daily 値を持つことを意味します。従って、先の 7*288 期間を予測することを望みます。
幾つかの常識を使用して、以下を設定します :
- 最初に、weekly 季節性を無効にします、自然は人間の週のカレンダーに従いません。
- 2 番目に、変化点を無効にします、データセットは 2 ヶ月のデータだけを含むからです。
m = NeuralProphet(
n_changepoints=0,
weekly_seasonality=False,
)
metrics = m.fit(df, freq='5min')
future = m.make_future_dataframe(df, periods=7*288, n_historic_predictions=len(df))
forecast = m.predict(future)
fig = m.plot(forecast)
# fig_comp = m.plot_components(forecast)
fig_param = m.plot_parameters()
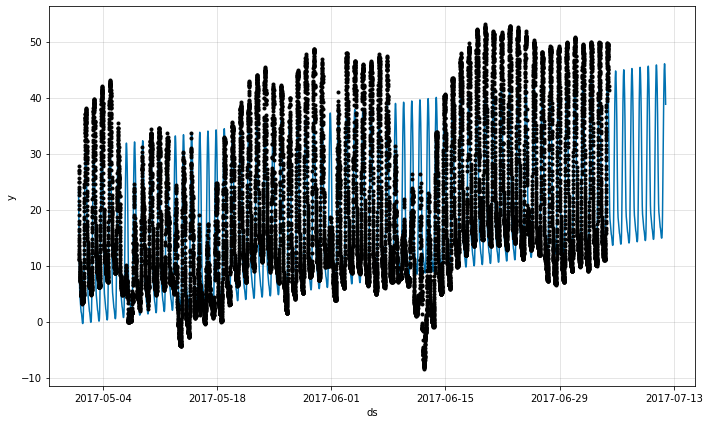
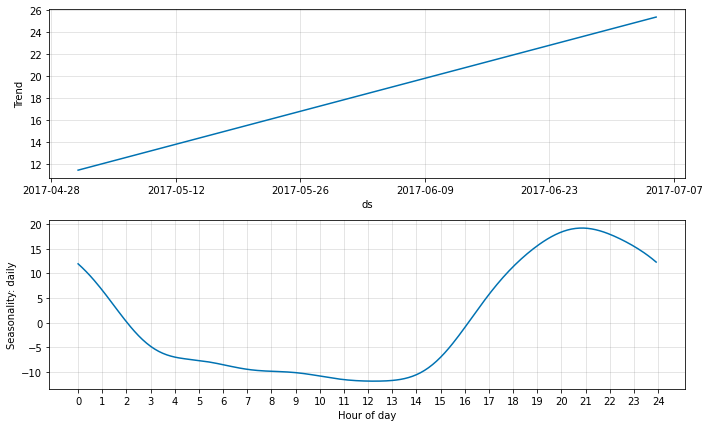
The daily seasonality seems to make sense, when we account for the time being recorded in GMT, while Yosemite local time is GMT-8.
トレンドと季節性を改良する
288 の記録された daily 値を持つので、過剰適合の危険性なしに、daily_seasonality の柔軟性を増やすことができます。
更に、天気で典型的であるように、データがトレンドで明瞭に変化を示していますので、変化点を無効にするという決定を再検討することを望むかもしれません。以下の変更を行ないます :
- 短期的な予測を行なっていますので、changepoints_range を増やします。
- トレンドの突然の変化に適合することを可能にするため n_changepoints を増やします。
- 過剰適合を回避するために trend_reg を設定することにより、トレンド変化点を注意深く正則化します。
m = NeuralProphet(
changepoints_range=0.95,
n_changepoints=50,
trend_reg=1.5,
weekly_seasonality=False,
daily_seasonality=10,
)
metrics = m.fit(df, freq='5min')
future = m.make_future_dataframe(df, periods=60//5*24*7, n_historic_predictions=len(df))
forecast = m.predict(future)
fig = m.plot(forecast)
# fig_comp = m.plot_components(forecast)
fig_param = m.plot_parameters()
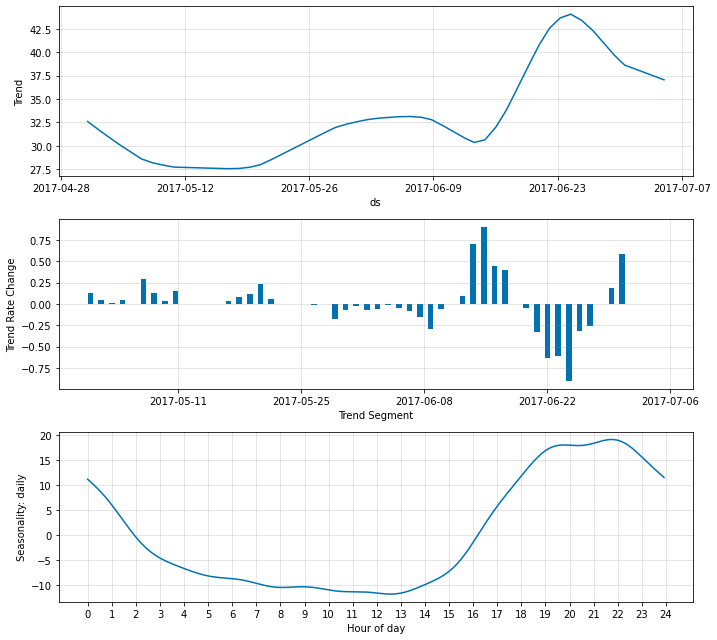
以上
NeuralProphet 0.2 : ノートブック : スパースな自己回帰
NeuralProphet 0.2 : ノートブック : スパースな自己回帰 (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 07/23/2021 (Beta 0.2.7)
* 本ページは、NeuralProphet の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。
- 人工知能研究開発支援
- 人工知能研修サービス(経営者層向けオンサイト研修)
- テクニカルコンサルティングサービス
- 実証実験(プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
- PoC(概念実証)を失敗させないための支援
- テレワーク & オンライン授業を支援
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |
NeuralProphet 0.2 : ノートブック : スパースな自己回帰
ここでは NeuralProphet を 5 分解像度のデータに適合させます (Yosemite の毎日の気温)。これはスパース性にフォーカスした、example ノートブック autoregression_yosemite_temps の続きです。
if 'google.colab' in str(get_ipython()):
!pip install git+https://github.com/ourownstory/neural_prophet.git # may take a while
#!pip install neuralprophet # much faster, but may not have the latest upgrades/bugfixes
data_location = "https://raw.githubusercontent.com/ourownstory/neural_prophet/master/"
else:
data_location = "../"
import pandas as pd
from neuralprophet import NeuralProphet, set_log_level
set_log_level("ERROR")
df = pd.read_csv(data_location + "example_data/yosemite_temps.csv")
# df.head(3)
AR 係数をスパース化する
NeuralProphet の自己回帰コンポーネントは AR-Net として定義されます (論文, github)。そして、AR 係数にスパース性を誘導したいのであれば ar_sparsity をより小さい数値に設定できます。
けれども、複数のコンポーネントと正則化でモデルを適合させるのは困難である可能性があり、訓練ハイパーパラメータを手動制御する必要があるかもしれません。
スパース性を 50% に設定することで開始します。
m = NeuralProphet(
n_lags=6*12,
n_forecasts=3*12,
changepoints_range=0.95,
n_changepoints=30,
weekly_seasonality=False,
# batch_size=64,
# epochs=100,
# learning_rate=0.1,
ar_sparsity=0.5,
)
metrics = m.fit(df, freq='5min') # validate_each_epoch=True, plot_live_loss=True
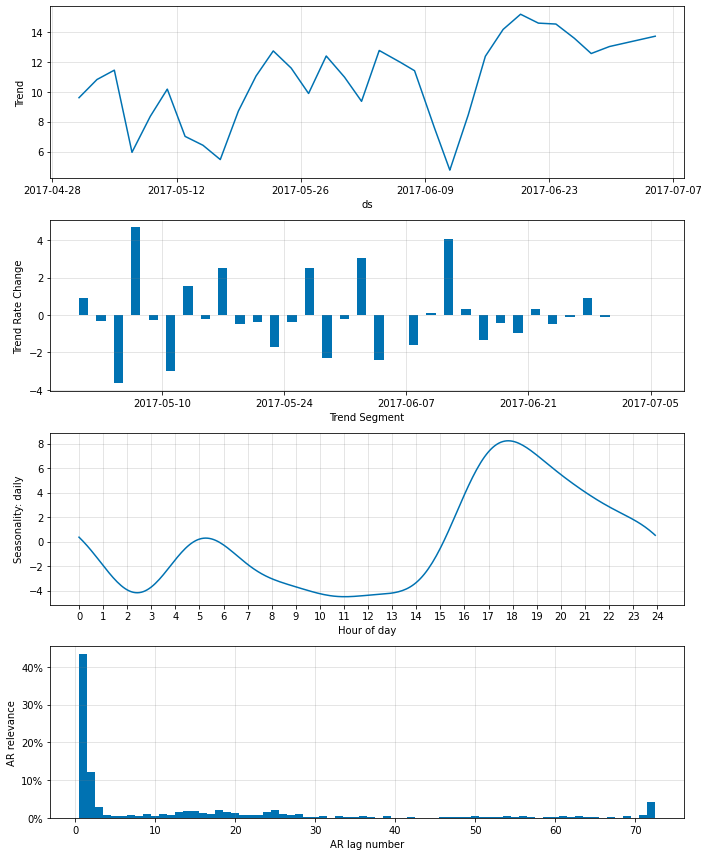
fig_param = m.plot_parameters()
m = m.highlight_nth_step_ahead_of_each_forecast(1)
fig_param = m.plot_parameters()
m = m.highlight_nth_step_ahead_of_each_forecast(36)
fig_param = m.plot_parameters()
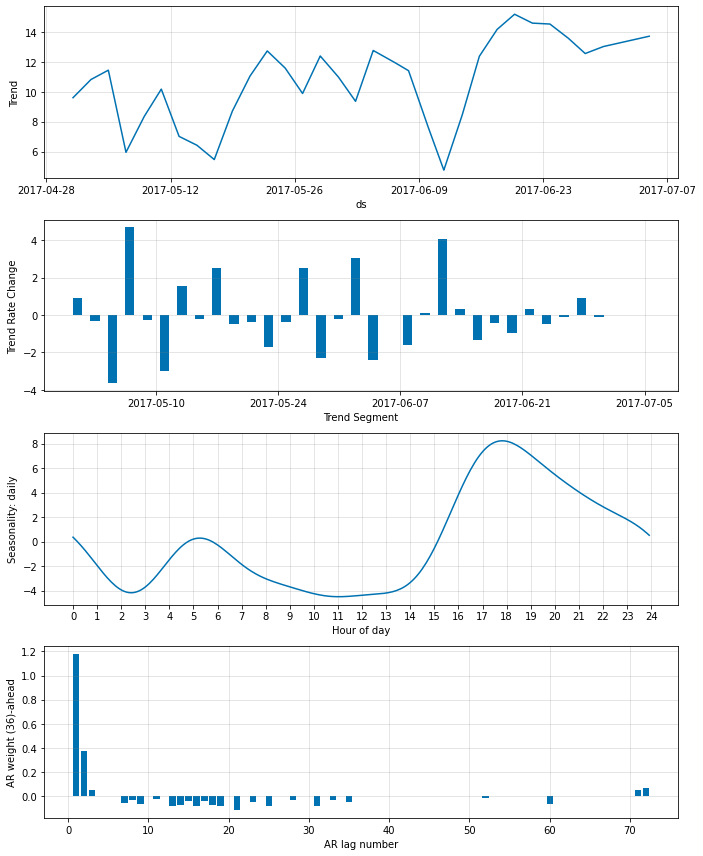
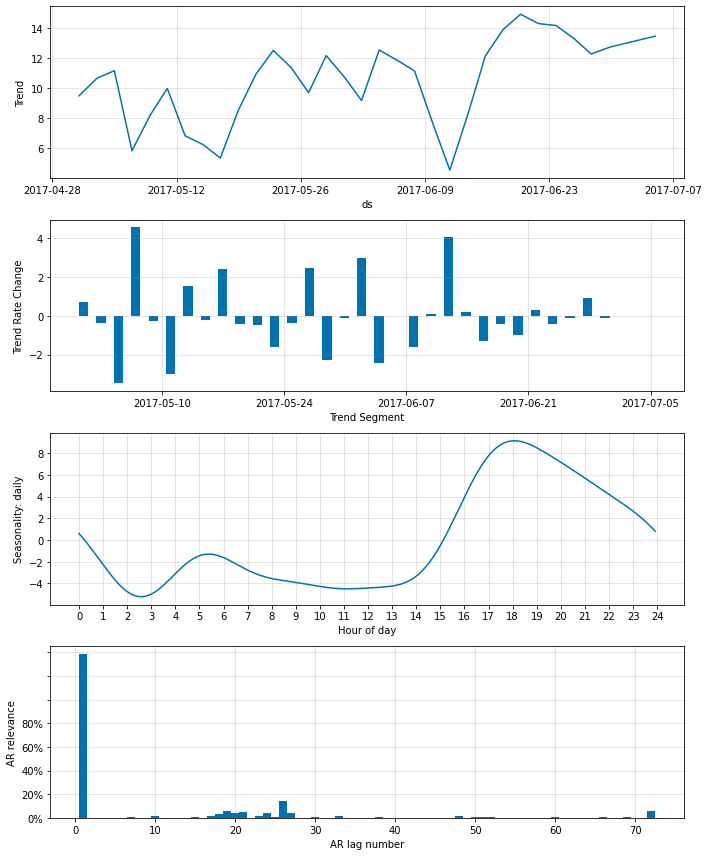
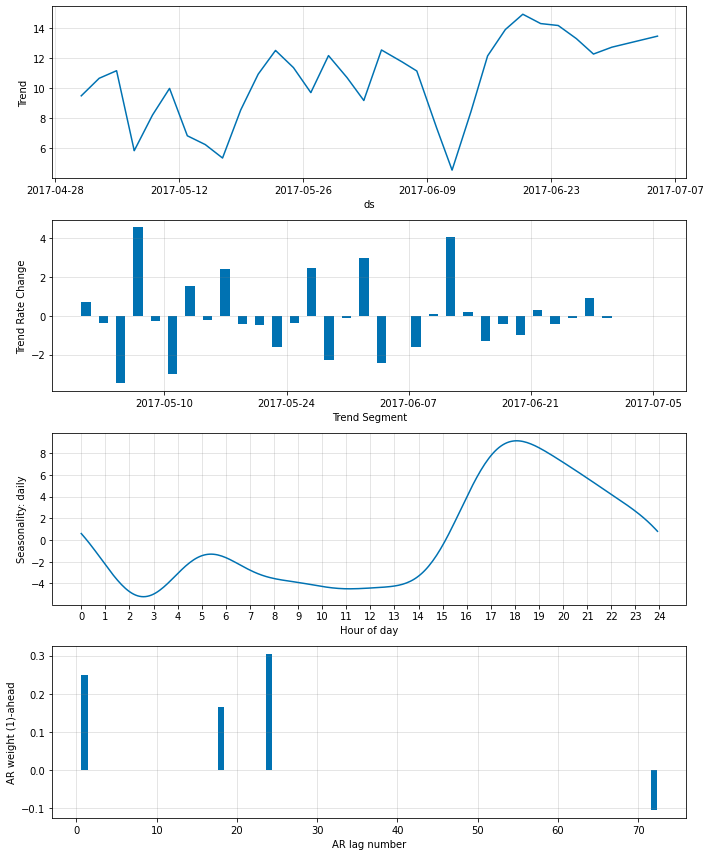
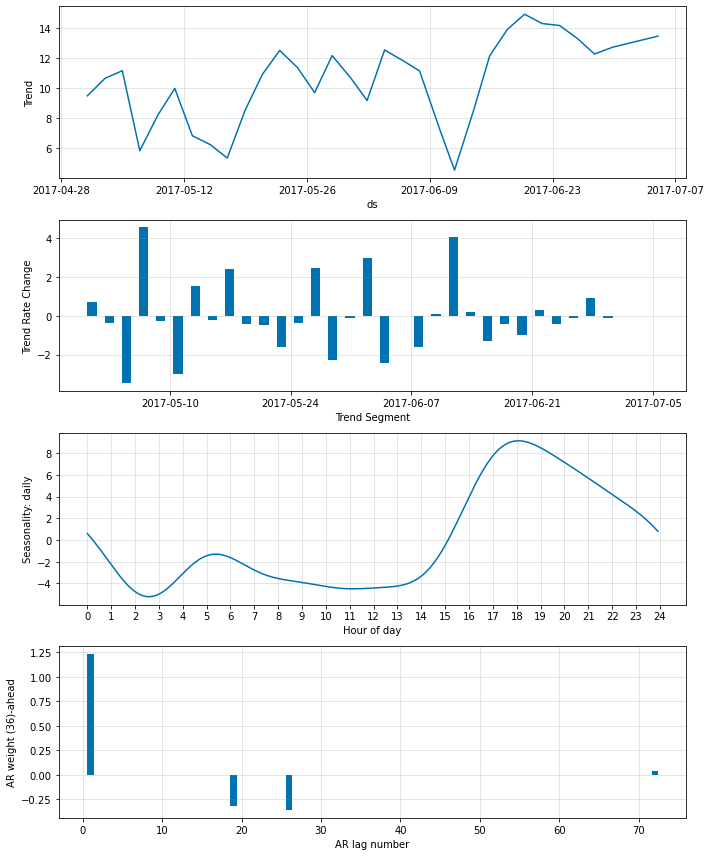
非ゼロ AR-係数を更に削減する
ar_sparsity を低く設定することで、非ゼロ重みの数を更に削減できます。ここではそれを 10 % に設定します :
m = NeuralProphet(
n_lags=6*12,
n_forecasts=3*12,
changepoints_range=0.95,
n_changepoints=30,
weekly_seasonality=False,
# batch_size=64,
# epochs=100,
# learning_rate=0.1,
ar_sparsity=0.1,
)
metrics = m.fit(df, freq='5min')
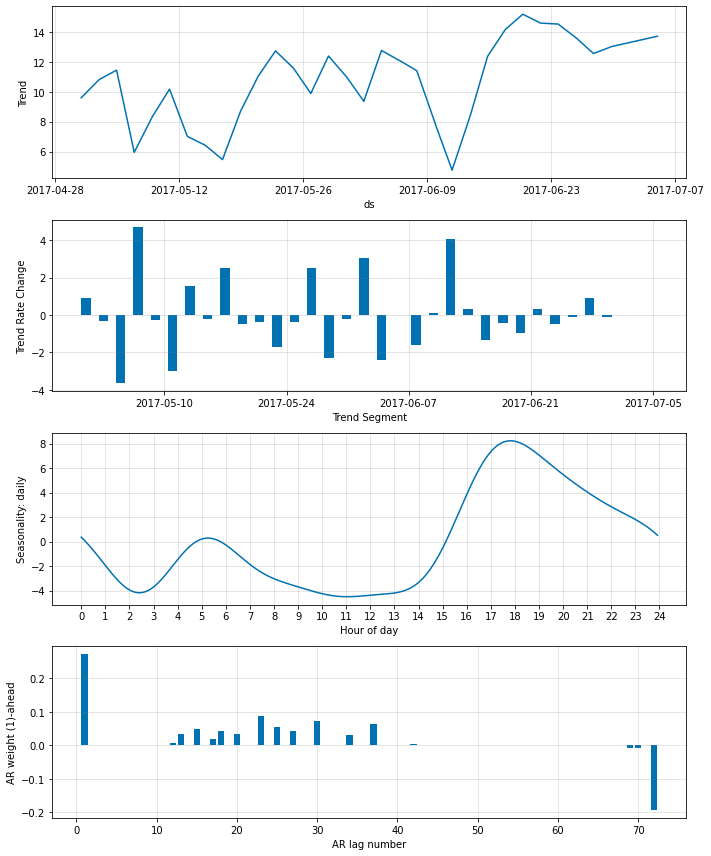
fig_param = m.plot_parameters()
m = m.highlight_nth_step_ahead_of_each_forecast(1)
fig_param = m.plot_parameters()
m = m.highlight_nth_step_ahead_of_each_forecast(36)
fig_param = m.plot_parameters()
極端なスパース性
より低く ar_sparsity を設定すれば、より少ない非ゼロ重みがモデルにより適合されます。ここではそれを 1 % に設定します、これは単一の非ゼロのラグに繋がるはずです。
Note : 極端な値は訓練の不安定性に繋がる可能性があります。
m = NeuralProphet(
n_lags=6*12,
n_forecasts=3*12,
changepoints_range=0.95,
n_changepoints=30,
weekly_seasonality=False,
# batch_size=64,
# epochs=100,
# learning_rate=0.1,
ar_sparsity=0.01,
)
metrics = m.fit(df, freq='5min')
fig_param = m.plot_parameters()
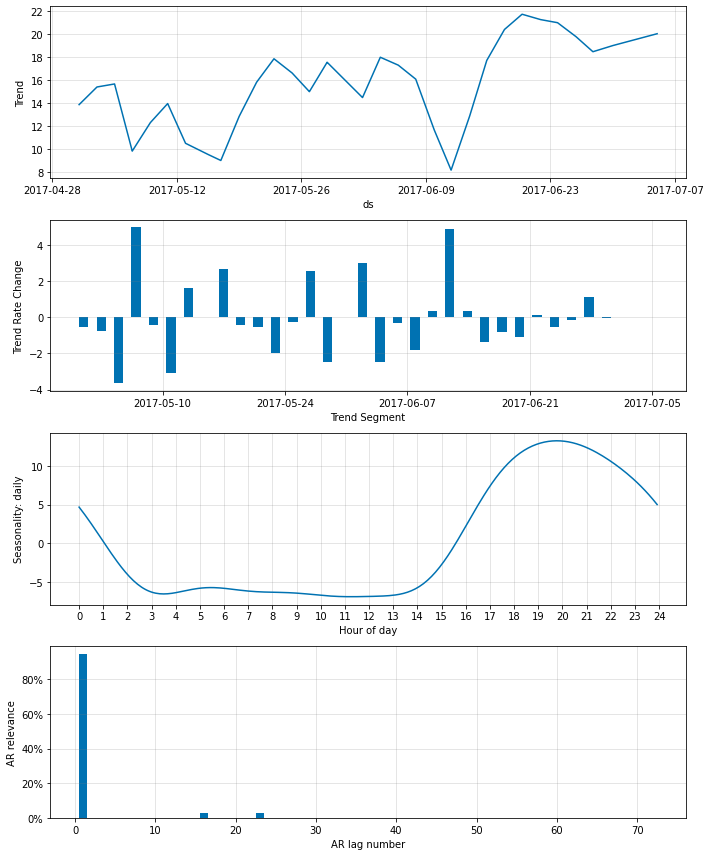
m = m.highlight_nth_step_ahead_of_each_forecast(1)
fig_param = m.plot_parameters()
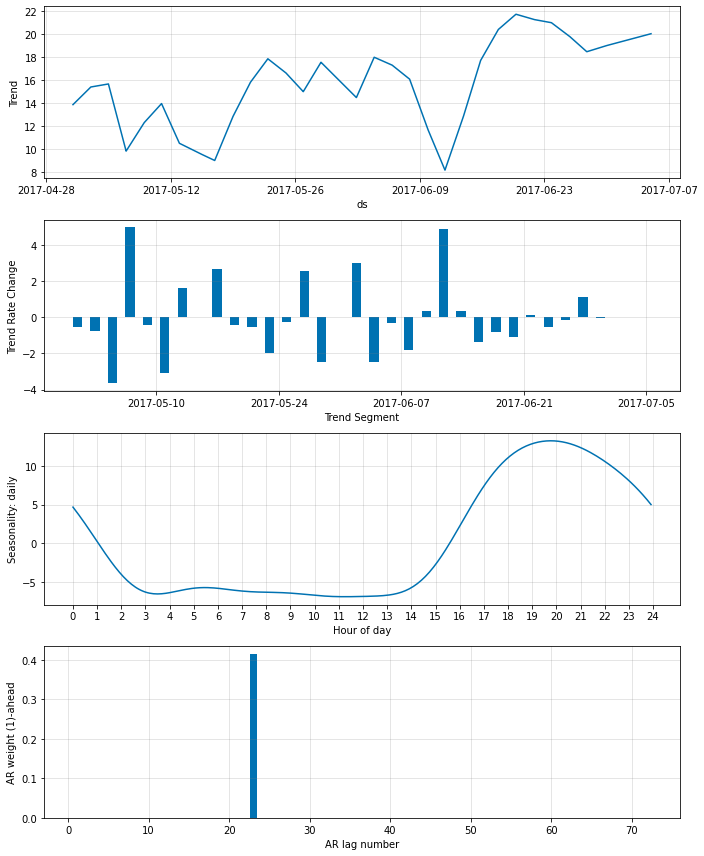
m = m.highlight_nth_step_ahead_of_each_forecast(36)
fig_param = m.plot_parameters()
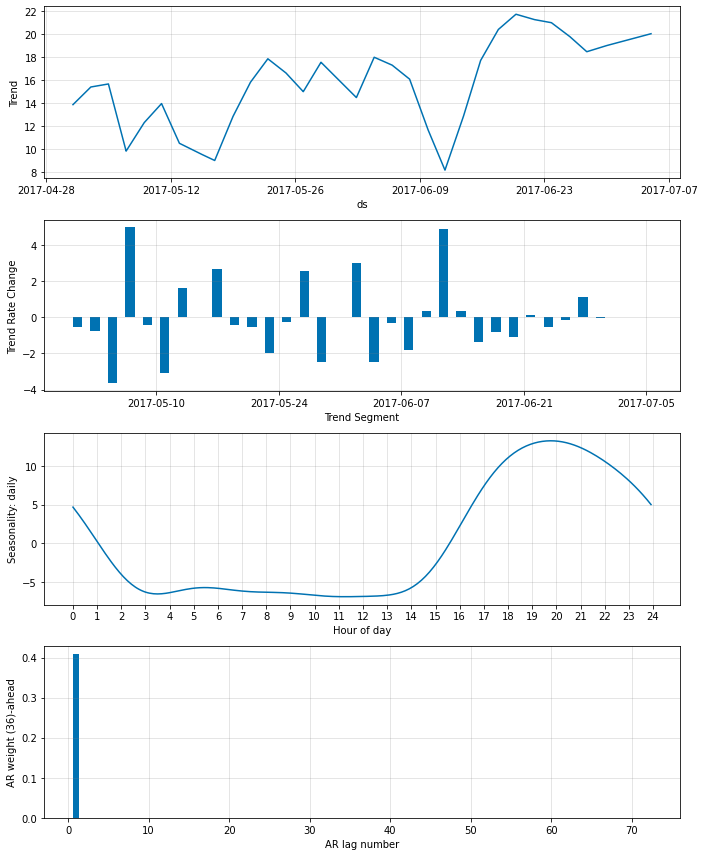
以上
NeuralProphet 0.2 : ノートブック : 乗法的季節性
NeuralProphet 0.2 : ノートブック : 乗法的季節性 (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 07/22/2021 (Beta 0.2.7)
* 本ページは、NeuralProphet の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。
- 人工知能研究開発支援
- 人工知能研修サービス(経営者層向けオンサイト研修)
- テクニカルコンサルティングサービス
- 実証実験(プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
- PoC(概念実証)を失敗させないための支援
- テレワーク & オンライン授業を支援
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |
NeuralProphet 0.2 : ノートブック : 乗法的季節性
デフォルトでは NeuralProphet は加法的季節性に適合します、これは予測を得るために季節効果がトレンドに追加されることを意味します。航空旅客数のこの時系列は加法的季節性が機能しない場合の例です :
if 'google.colab' in str(get_ipython()):
!pip install git+https://github.com/ourownstory/neural_prophet.git # may take a while
#!pip install neuralprophet # much faster, but may not have the latest upgrades/bugfixes
data_location = "https://raw.githubusercontent.com/ourownstory/neural_prophet/master/"
else:
data_location = "../"
import pandas as pd
from neuralprophet import NeuralProphet, set_log_level
# set_log_level("ERROR")
m = NeuralProphet()
df = pd.read_csv(data_location + "example_data/air_passengers.csv")
metrics = m.fit(df, freq="MS")
future = m.make_future_dataframe(df, periods=50, n_historic_predictions=len(df))
forecast = m.predict(future)
fig = m.plot(forecast)
# fig_param = m.plot_parameters()
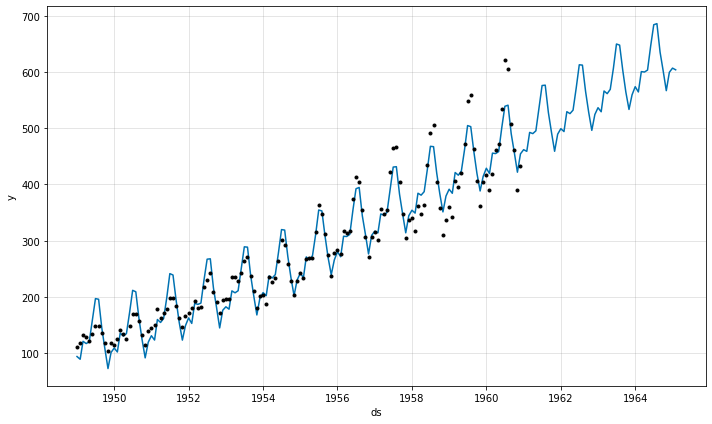
この時系列は明瞭な yearly サイクルを持ちますが、予測 の季節性は時系列の開始時には大きすぎて終了時には小さぎます。この時系列では、季節性は NeuralProphet により想定された定数値の加法的因子ではなく、それはトレンドとともに成長します。これは乗法的季節性です。
NeuralProphet は入力引数で seasonality_mode=”multiplicative” を設定することにより乗法的季節性をモデル化できます :
m = NeuralProphet(seasonality_mode="multiplicative")
metrics = m.fit(df, freq="MS")
future = m.make_future_dataframe(df, periods=50, n_historic_predictions=len(df))
forecast = m.predict(future)
fig = m.plot(forecast)
# fig_param = m.plot_parameters()
コンポーネント図は今は季節性をトレンドのパーセントで示します :
fig_param = m.plot_components(forecast)
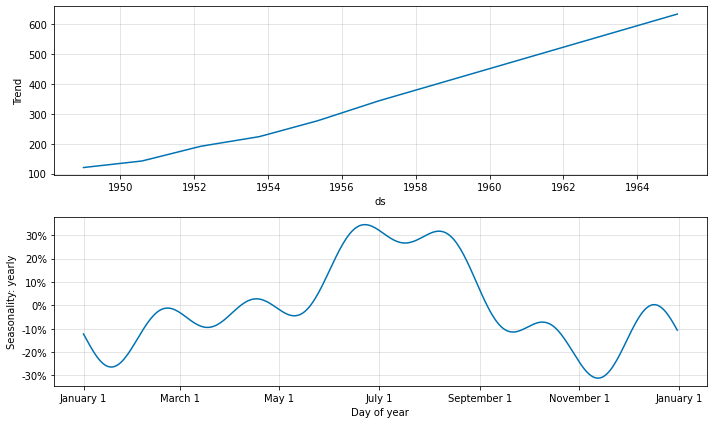
季節性は月の最初に発生するデータ上でのみ適合していることに注意してください。そのため、月の間の季節性のプロット値はランダム値を取るかもしれません。
Settingseasonality_mode=”multiplicative” は、add_seasonality で追加されたカスタム季節性を含め、総ての季節性を乗法的にモデル化します。
以上
NeuralProphet 0.2 : ノートブック : 休日と特殊イベントのモデリング
NeuralProphet 0.2 : ノートブック : 休日と特殊イベントのモデリング (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 07/22/2021 (Beta 0.2.7)
* 本ページは、NeuralProphet の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。
- 人工知能研究開発支援
- 人工知能研修サービス(経営者層向けオンサイト研修)
- テクニカルコンサルティングサービス
- 実証実験(プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
- PoC(概念実証)を失敗させないための支援
- テレワーク & オンライン授業を支援
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |
NeuralProphet 0.2 : ノートブック : 休日と特殊イベントのモデリング
モデル化したい休日や他の繰り返しイベントを持つ場合、それらからデータフレームを作成しなければなりません。それは 2 つのカラム (event と ds) と休日の各発生のための行を持ちます。それは過去 (履歴データが続く限り後方に) と未来 (予測が成されている限り) の両者の休日の総ての発生を含まなければなりません。それらが未来に繰り返されない場合、Prophet はそれらをモデル化してから予測に含ません。
イベントは加法的か乗法的コンポーネントのいずれかとして追加できます。
更にイベントの前後の日を含めるためにウィンドウを定義できます。
例として Peyton Manning の Wikipedia のログ daily ページビューの時系列を使用します。最初に、データをロードします :
if 'google.colab' in str(get_ipython()):
!pip install git+https://github.com/ourownstory/neural_prophet.git # may take a while
#!pip install neuralprophet # much faster, but may not have the latest upgrades/bugfixes
data_location = "https://raw.githubusercontent.com/ourownstory/neural_prophet/master/"
else:
data_location = "../"
import pandas as pd
from neuralprophet import NeuralProphet
df = pd.read_csv(data_location + "example_data/wp_log_peyton_manning.csv")
ここで過去のイベントと未来のイベントを含む、Peyton Manning のプレーオフ出場の総ての日付を含むデータフレームを作成します :
## user specified events
# history events
playoffs = pd.DataFrame({
'event': 'playoff',
'ds': pd.to_datetime([
'2008-01-13', '2009-01-03', '2010-01-16',
'2010-01-24', '2010-02-07', '2011-01-08',
'2013-01-12', '2014-01-12', '2014-01-19',
'2014-02-02', '2015-01-11', '2016-01-17',
'2016-01-24', '2016-02-07',
]),
})
superbowls = pd.DataFrame({
'event': 'superbowl',
'ds': pd.to_datetime([
'2010-02-07', '2012-02-05', '2014-02-02',
'2016-02-07',
]),
})
events_df = pd.concat((playoffs, superbowls))
加法的イベント
ひとたびテーブルが作成されれば、イベント効果は add_events 関数でそれらを追加することでモデルに含まれます。
デフォルトでは、イベントは加法的イベントとしてモデル化されます。ここでは、プレーオフの両者を加法的イベントとしてモデル化します。
更に loss_func を ‘MSE’ に変更します、重みに適合しているイベントが幾つかの稀な外れ値であるためです。通常はモデルを少ない外れ値で歪めることを望まないので、デフォルトの損失関数は ‘Huber’ です。
# NeuralProphet Object
m = NeuralProphet(loss_func="MSE")
# set the model to expect these events
m = m.add_events(["playoff", "superbowl"])
# create the data df with events
history_df = m.create_df_with_events(df, events_df)
# fit the model
metrics = m.fit(history_df, freq="D")
# forecast with events
future = m.make_future_dataframe(history_df, events_df, periods=30, n_historic_predictions=len(df))
forecast = m.predict(df=future)
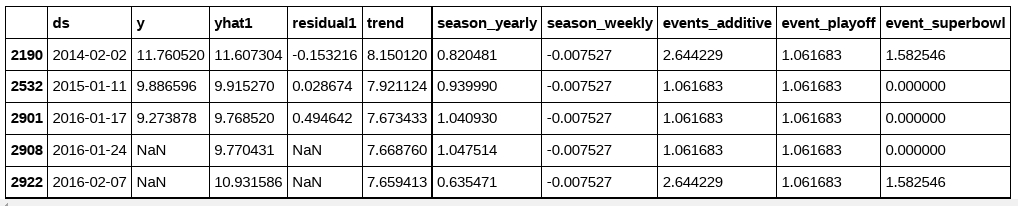
イベント効果は予測データフレームで確認することができます :
events = forecast[(forecast['event_playoff'].abs() + forecast['event_superbowl'].abs()) > 0]
events.tail()
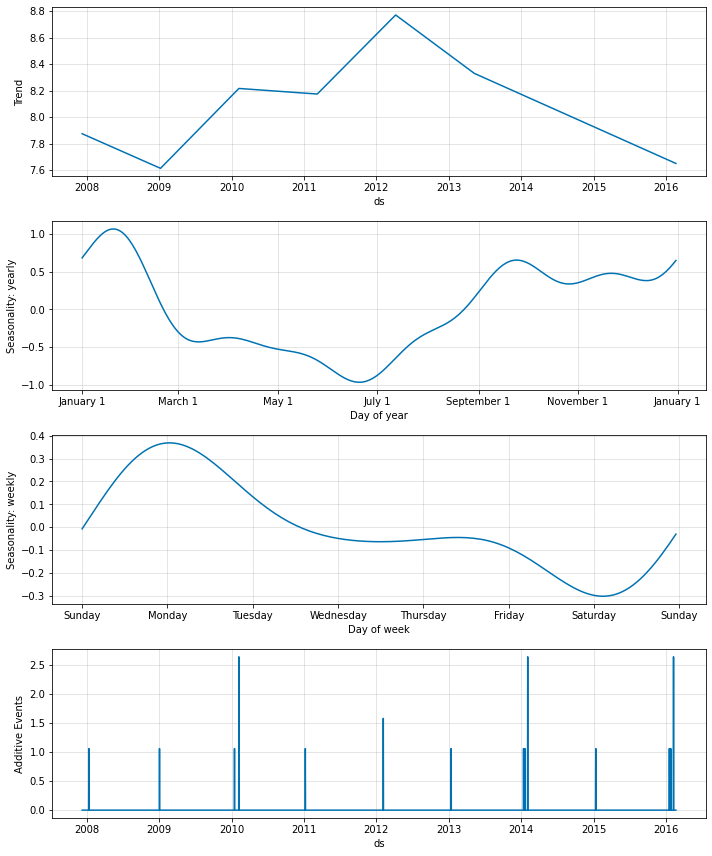
イベント効果はプロットにも現れます、そこではスーパーボウルのための特に大きなスパイクとともに、プレーオフ出場の前後の日々にスパイクがあることを見ます :
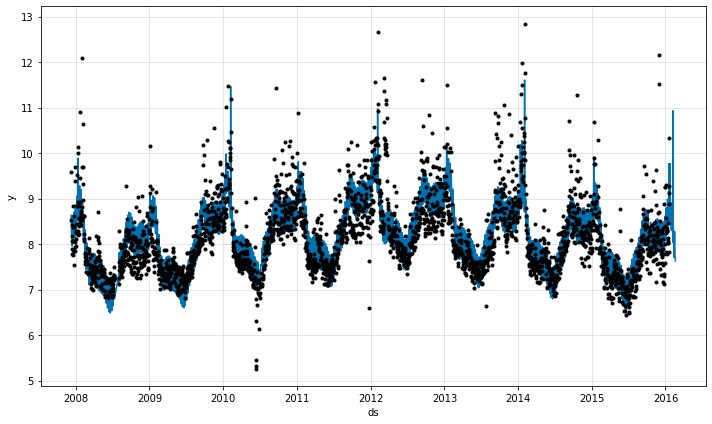
## plotting forecasts
fig = m.plot(forecast)
## plotting components
fig_comp = m.plot_components(forecast)
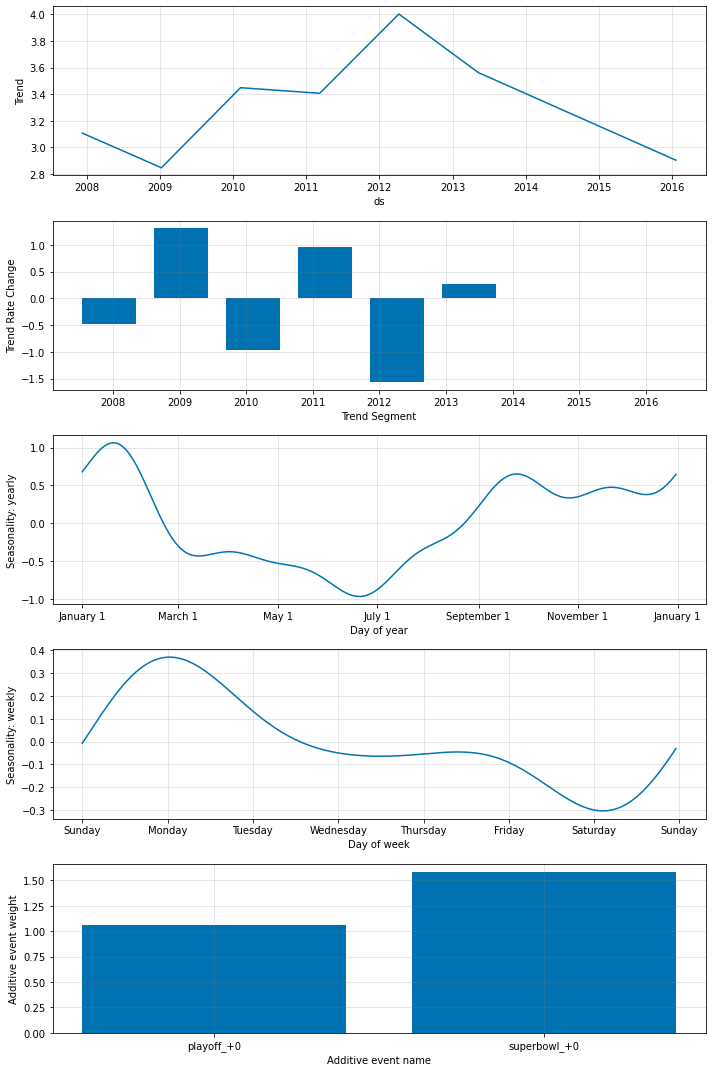
## plotting parameters
fig_param = m.plot_parameters()
イベント・ウィンドウ
引数 lower_window と upper_window を含めることもできます、これらは休日を日付前後の [lower_window, upper_window] days に拡張します。
例えば、クリスマスに加えてクリスマスイブを含めることを望む場合、lower_window=-1, upper_window=0 を含めます。感謝祭に加えてブラックフライデーを使用したい場合、lower_window=0, upper_window=1 を含めます。
m = NeuralProphet(loss_func="MSE")
# set event configs to NeuralProphet object with windows
m = m.add_events(["playoff"], upper_window=1)
m = m.add_events(["superbowl"], lower_window=-1, upper_window=1)
# create the data df with events
history_df = m.create_df_with_events(df, events_df)
# fit the model
metrics = m.fit(history_df, freq="D")
# make future dataframe with events known in future
future = m.make_future_dataframe(df=history_df, events_df=events_df, periods=365, n_historic_predictions=len(df))
forecast = m.predict(df=future)
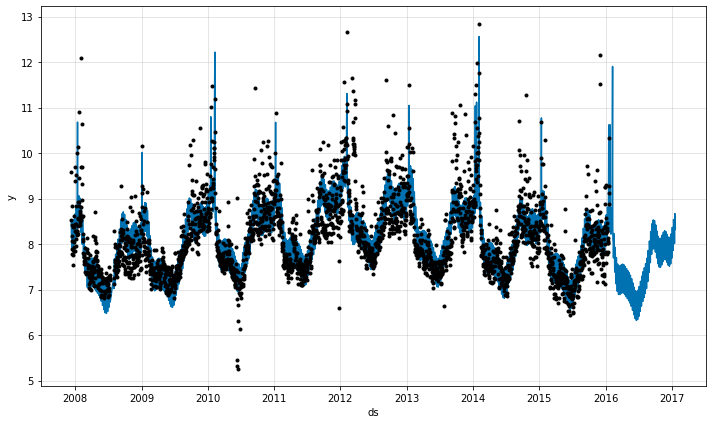
## plotting parameters
fig = m.plot(forecast)
fig_param = m.plot_parameters()
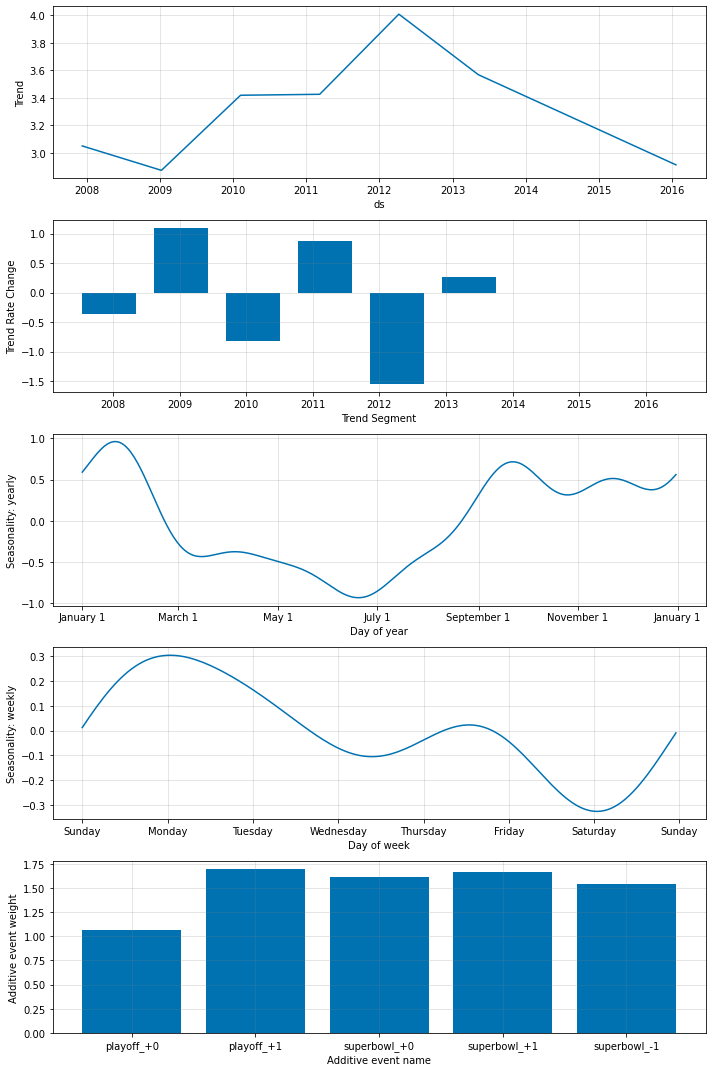
乗法的イベント
m = NeuralProphet(loss_func="MSE")
# set event configs to NeuralProphet object with windows
m = m.add_events(["playoff"], upper_window=1)
m = m.add_events(["superbowl"], lower_window=-1, upper_window=1, mode="multiplicative")
# create the data df with events
history_df = m.create_df_with_events(df, events_df)
# fit the model
metrics = m.fit(history_df, freq="D")
# make future dataframe with events known in future
future = m.make_future_dataframe(history_df, events_df, periods=30, n_historic_predictions=len(df))
forecast = m.predict(df=future)
## plotting components
fig_comp = m.plot(forecast)
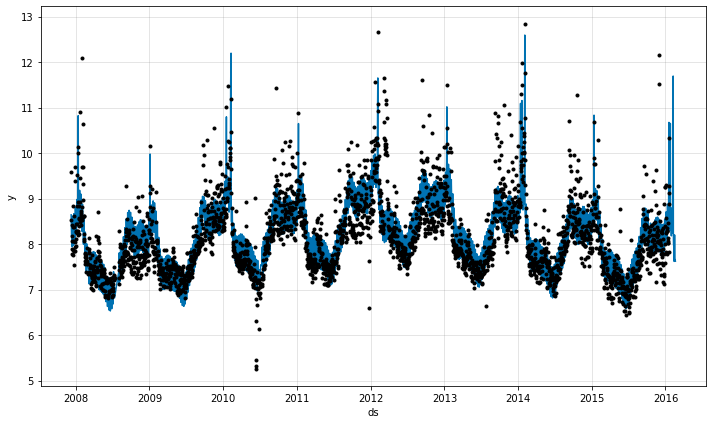
# plot parameters
fig_param = m.plot_parameters()
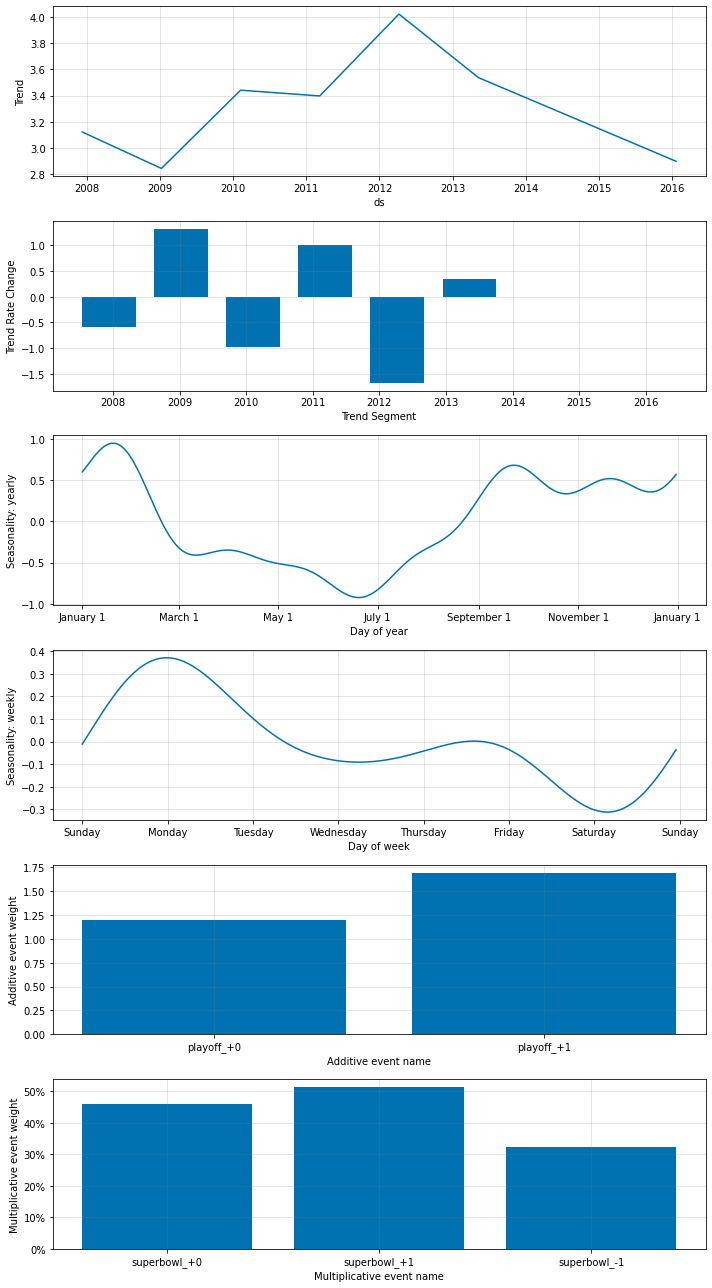
国固有の休日
m = NeuralProphet()
# add the country specific holidays
m = m.add_country_holidays("US")
# fit the model
metrics = m.fit(df, freq="D")
# make future dataframe with events known in future
future = m.make_future_dataframe(df=df, periods=30, n_historic_predictions=len(df))
forecast = m.predict(df=future)
## plotting components
fig = m.plot(forecast)
fig_param = m.plot_parameters()
以上
NeuralProphet 0.2 : ノートブック : PV 予測データセットの例
NeuralProphet 0.2 : ノートブック : PV 予測データセットの例 (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 07/21/2021 (Beta 0.2.7)
* 本ページは、NeuralProphet の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。
- 人工知能研究開発支援
- 人工知能研修サービス(経営者層向けオンサイト研修)
- テクニカルコンサルティングサービス
- 実証実験(プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
- PoC(概念実証)を失敗させないための支援
- テレワーク & オンライン授業を支援
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |
NeuralProphet 0.2 : ノートブック : PV 予測データセットの例
if 'google.colab' in str(get_ipython()):
!pip install git+https://github.com/ourownstory/neural_prophet.git # may take a while
#!pip install neuralprophet # much faster, but may not have the latest upgrades/bugfixes
data_location = "https://raw.githubusercontent.com/ourownstory/neural_prophet/master/energy/"
else:
data_location = "../"
この最初のセクションでは、太陽放射度データ (太陽 PV 生産のプロキシーになり得ます) の 1 ステップ先の予測器を訓練します。前の 24 ステップを考慮して neuralprophet に他のパラメータを自動的に選択させて、この予測器を訓練できます。
変更できるパラメータは AR スパース性とニューラルネットワーク・アーキテクチャのためです。
訓練はデータの 80% に存在し、最後の 20% は検証のために取っておきます。
import pandas as pd
from neuralprophet import NeuralProphet, set_log_level
# set_log_level("ERROR")
files = ['SanFrancisco_PV_GHI.csv', 'SanFrancisco_Hospital.csv']
raw = pd.read_csv(data_location + files[0])
df=pd.DataFrame()
df['ds'] = pd.date_range('1/1/2015 1:00:00', freq=str(60) + 'Min',
periods=(8760))
df['y'] = raw.iloc[:,0].values
df.head(3)
m = NeuralProphet(
n_lags=24,
ar_sparsity=0.5,
#num_hidden_layers = 2,
#d_hidden=20,
)
metrics = m.fit(df, freq='H', valid_p = 0.2)
df_train, df_val = m.split_df(df, freq='H',valid_p=0.2)
m.test(df_val)

future = m.make_future_dataframe(df_val, n_historic_predictions=True)
forecast = m.predict(future)
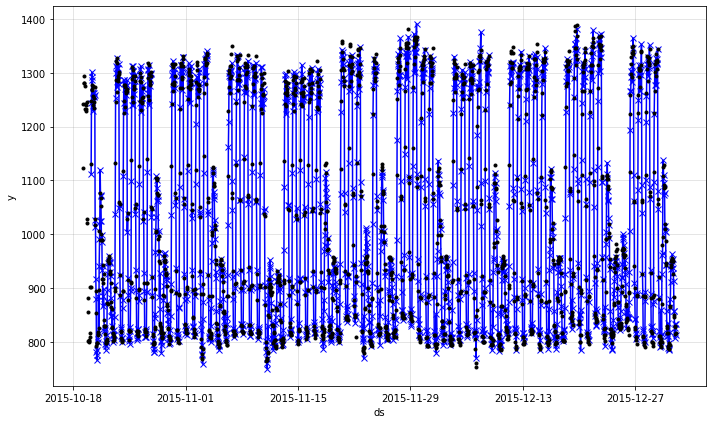
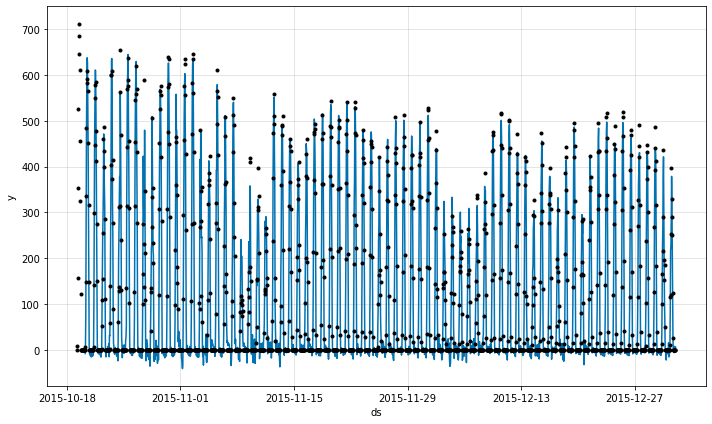
fig = m.plot(forecast)
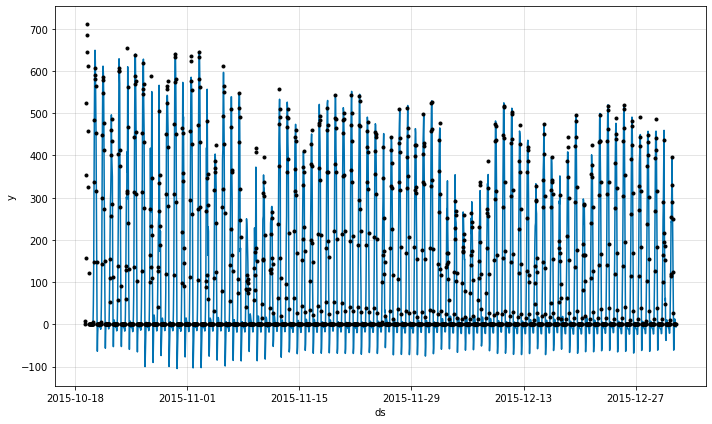
fig_comp = m.plot_components(forecast)
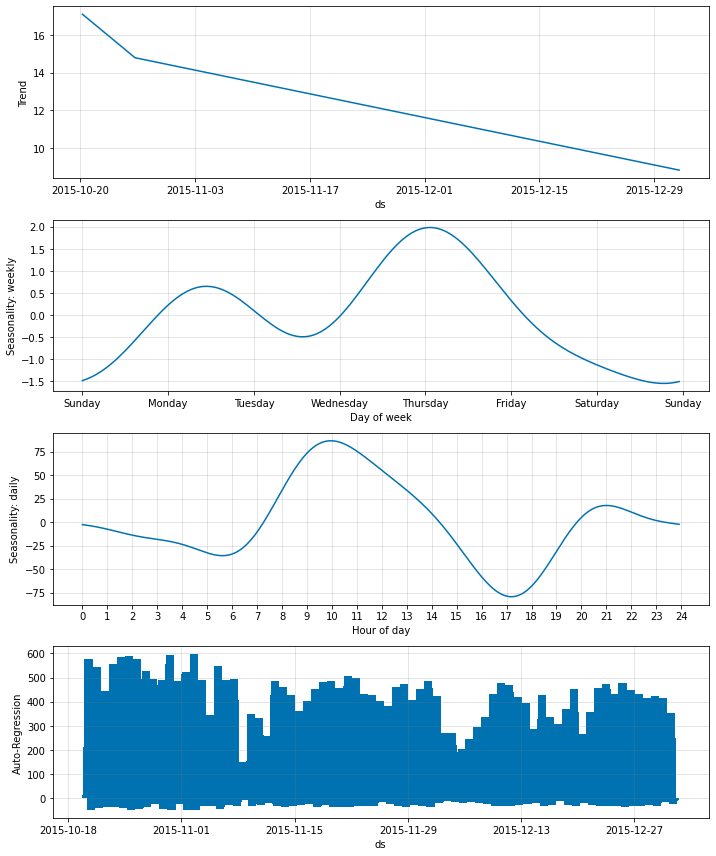
fig_param = m.plot_parameters()
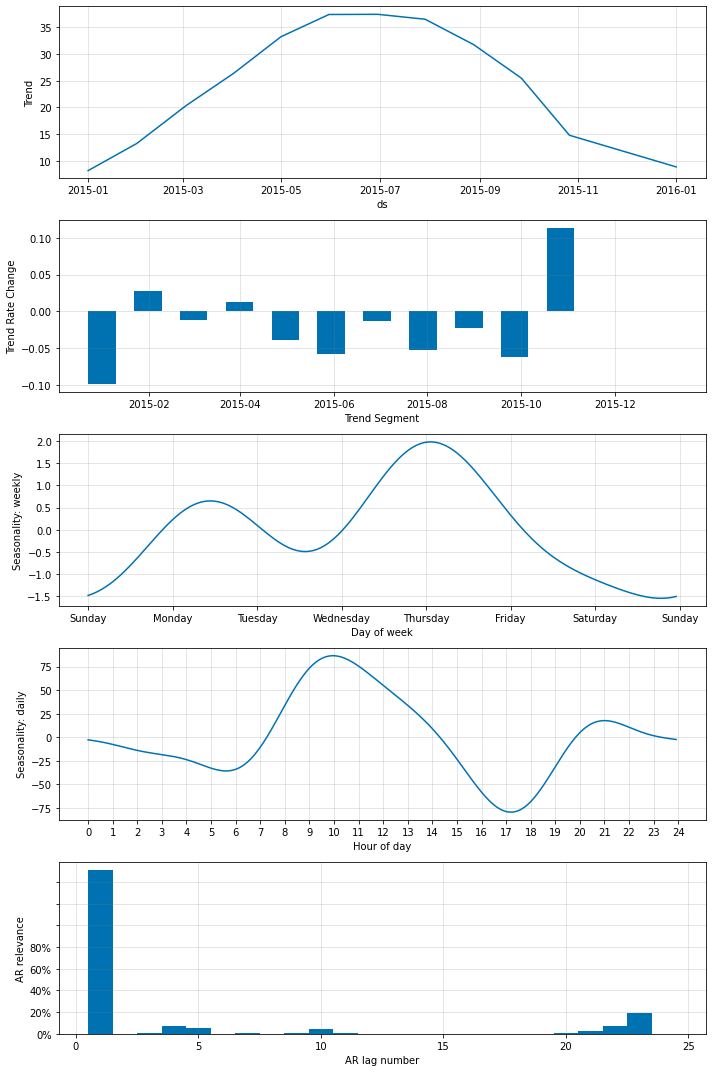
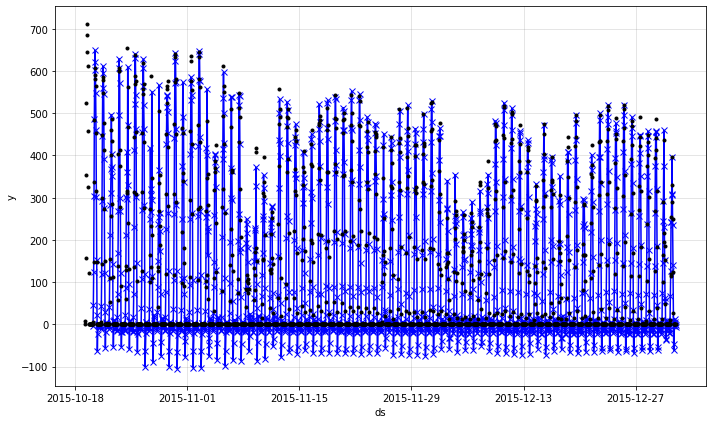
fig_fit = m.highlight_nth_step_ahead_of_each_forecast(1).plot(forecast)
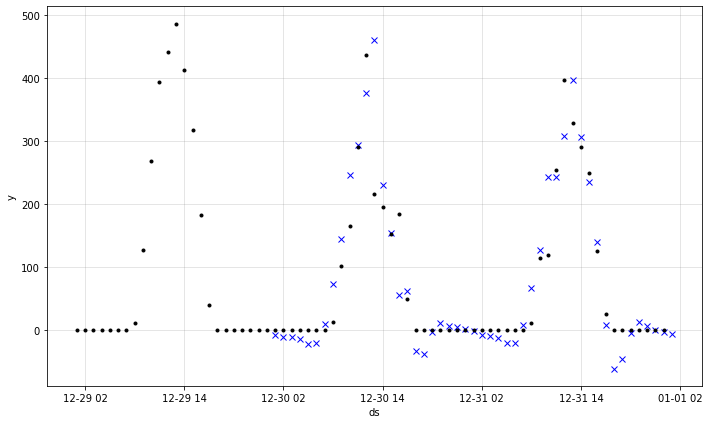
fig_prediction = m.plot_last_forecast(forecast, include_previous_forecasts=48)
少なくとも一つの隠れ層を持つニューラルネットワークを考える場合、ここで考慮すべきことがあります。十分に高い学習率 (多分 > 0.1) については、勾配は消失するようで AR ネット出力を 0 に強制します。
下から、予測出力が奇妙な動作を持つことがわかります。出力は正確に、トレンドを持つ weekly, daily 季節性の合計であるように見えます。ノイズも変化も全くありません。
m = NeuralProphet(
n_lags=24,
ar_sparsity=0.5,
num_hidden_layers = 2,
d_hidden=20,
learning_rate = 0.1
)
metrics = m.fit(df, freq='H', valid_p = 0.2)
future = m.make_future_dataframe(df_val, n_historic_predictions=True)
forecast = m.predict(future)
fig = m.plot(forecast)
簡単な修正は学習率を十分に低い値に設定することです。
m = NeuralProphet(
n_lags=24,
ar_sparsity=0.5,
num_hidden_layers = 2,
d_hidden=20,
learning_rate = 0.001
)
metrics = m.fit(df, freq='H', valid_p = 0.2)
future = m.make_future_dataframe(df_val, n_historic_predictions=True)
forecast = m.predict(future)
fig = m.plot(forecast)
(電気) 負荷予測の例
別の一般的なエネルギー問題で予測器を訓練することができます。この場合、建物の電気消費量を予測するために 1 ステップ先の予測器を訓練しています。PV 予測のために使用したのと同様の NeuralProphet モデルを使用します。
import pandas as pd
from neuralprophet import NeuralProphet, set_log_level
# set_log_level("ERROR")
files = ['SanFrancisco_PV_GHI.csv', 'SanFrancisco_Hospital.csv']
raw = pd.read_csv(data_location + files[1])
df=pd.DataFrame()
df['ds'] = pd.date_range('1/1/2015 1:00:00', freq=str(60) + 'Min',
periods=(8760))
df['y'] = raw.iloc[:,0].values
df.head(3)
print(raw)
print(raw)
Electricity:Facility [kW](Hourly)
0 778.007969
1 776.241750
2 779.357338
3 778.737196
4 787.835835
... ...
8755 845.563081
8756 827.530521
8757 829.256300
8758 813.937205
8759 815.588584
[8760 rows x 1 columns]
m = NeuralProphet(
n_lags=24,
ar_sparsity=0.5,
num_hidden_layers = 2,
d_hidden=20,
learning_rate=0.001
)
metrics = m.fit(df, freq='H', valid_p = 0.2)
df_train, df_val = m.split_df(df, freq='H',valid_p=0.2)
m.test(df_val)
future = m.make_future_dataframe(df_val, n_historic_predictions=True)
forecast = m.predict(future)
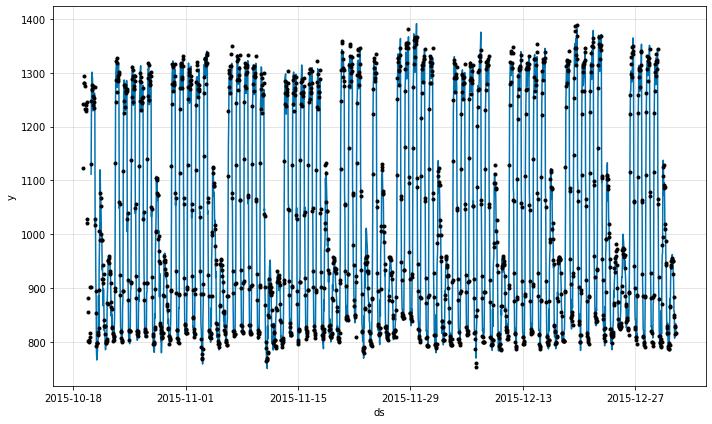
fig = m.plot(forecast)
fig_comp = m.plot_components(forecast)
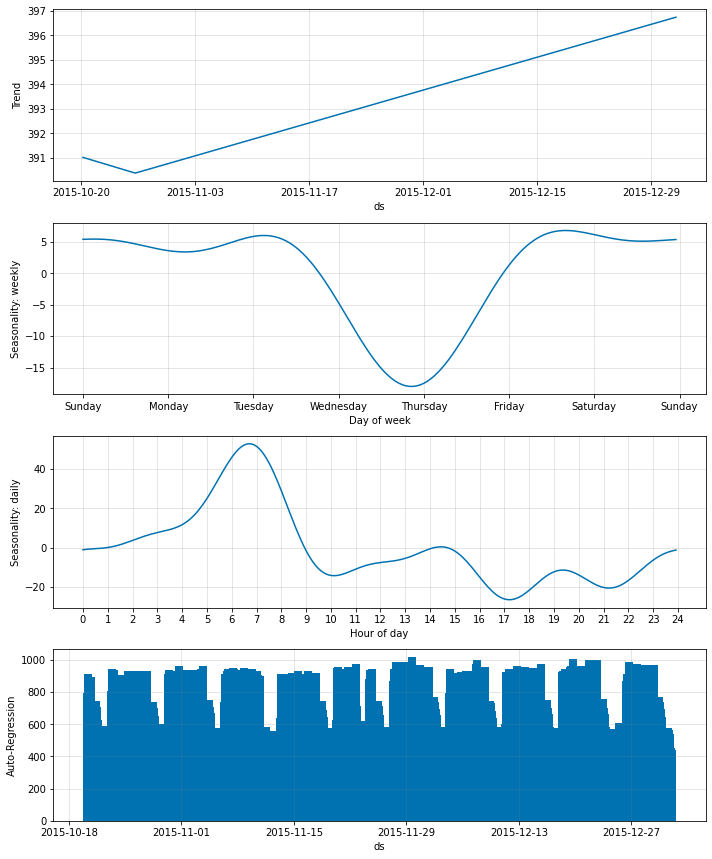
fig_param = m.plot_parameters()
fig_fit = m.highlight_nth_step_ahead_of_each_forecast(1).plot(forecast)
fig_prediction = m.plot_last_forecast(forecast, include_previous_forecasts=48)
以上
NeuralProphet 0.2 : ノートブック : 自己回帰
NeuralProphet 0.2 : ノートブック : 自己回帰 (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 07/19/2021 (Beta 0.2.7)
* 本ページは、NeuralProphet の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。
- 人工知能研究開発支援
- 人工知能研修サービス(経営者層向けオンサイト研修)
- テクニカルコンサルティングサービス
- 実証実験(プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
- PoC(概念実証)を失敗させないための支援
- テレワーク & オンライン授業を支援
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |
NeuralProphet 0.2 : ノートブック : 自己回帰
ここでは NeuralProphet を 5 分解像度のデータに適合させます (Yosemite の毎日の気温)。
if 'google.colab' in str(get_ipython()):
!pip install git+https://github.com/ourownstory/neural_prophet.git # may take a while
#!pip install neuralprophet # much faster, but may not have the latest upgrades/bugfixes
data_location = "https://raw.githubusercontent.com/ourownstory/neural_prophet/master/"
else:
data_location = "../"
import pandas as pd
from neuralprophet import NeuralProphet, set_log_level
# set_log_level("ERROR")
df = pd.read_csv(data_location + "example_data/yosemite_temps.csv")
df.head(3)
Next-step 予測
データとの最初のコンタクトに基づいて、以下を設定します :
- 最初に、weekly_seasonality を無効にします、自然は人間の週のカレンダーに従わないからです。
- 2 番目に、短期の予測を行なっていますので、n_changepoints を増やし、そして changepoints_range を増やします。
更に、明日の天気が昨日の天気と同様である可能性が高いという事実も利用できます。これは最も最近の過去の値で時系列を回帰することを意味し、自己回帰としても知られています。
n_lags を (それに渡り) 回帰させるための過去の観測値の望まれる数に設定することによりこれを実現できます。この値はまた ‘AR order’ としても知られます。
ここでは、最後の 1 時間に基づいて次の 5 分の気温を予測します :
m = NeuralProphet(
n_lags=12,
changepoints_range=0.95,
n_changepoints=30,
weekly_seasonality=False,
batch_size=64,
epochs=10,
learning_rate=1.0,
)
metrics = m.fit(df, freq='5min')
自己回帰コンポーネントを持つモデルは適合させることが困難な可能性があることに注意してください。ハイパーパラメータの自動選択は理想的な結果に繋がらないかもしれません。最善の結果のためには、(重要性の高い順に) これらを手動で変更することを考えてください。
- learning_rate
- epochs
- batch_size
自動的に設定されたハイパーパラメータ (‘INFO’ レベルログとしてプリント出力されます) は良い開始点として役立つことができます。
future = m.make_future_dataframe(df, n_historic_predictions=True)
forecast = m.predict(future)
fig = m.plot(forecast)
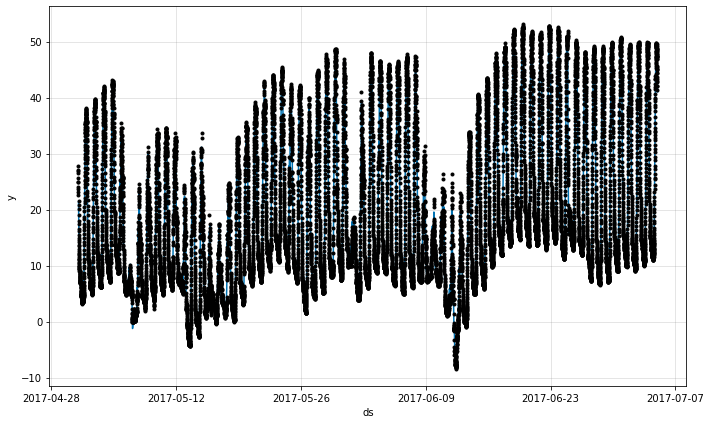
予測は今では非常に正確ですが、これは大きな驚きではありません、すぐ次の 5 分間を予測しているだけだからです。
モデルパラメータをプロットするとき、パネル ‘AR weight’ は 12 の最後の観測値に与えられた重みを表示します、これらは ‘AR coefficients’ として解釈できます :
# fig_comp = m.plot_components(forecast)
m = m.highlight_nth_step_ahead_of_each_forecast(1) # temporary workaround to plot actual AR weights
fig_param = m.plot_parameters()
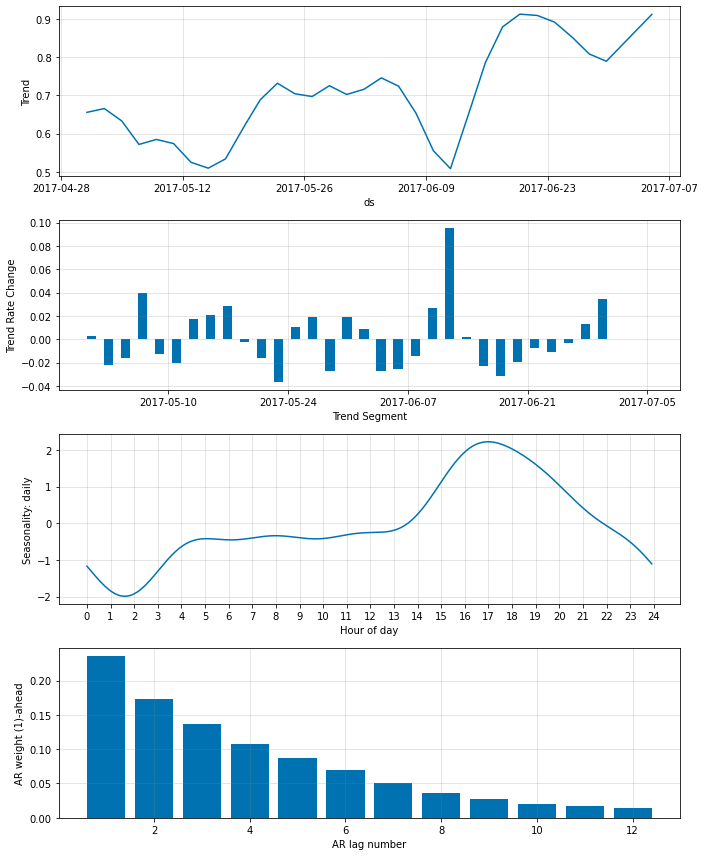
‘AR weight’ プロットは最も最近の観測はより離れた観測に比べてかなり多くの重みが与えられることを示しています。
マルチステップ予測
複数のステップを未来へ予測するためには、(一つの) ステップを前方に予測し、予測された値をデータに追加してから関心のある範囲に到達するまで次のステップを予測することによりシングルステップ・モデルを「展開」できます。けれども、これを行なうより良い方法があります : NeuralProphet で前方にマルチステップを直接予測できます。
n_forecasts を予測したいステップの望まれる数に設定できます (「予測区間」とも呼ばれます)。NeuralProphet は総ての単一ステップで、未来への n_forecasts ステップを予測します。従って、総ての履歴ポイントで n_forecasts の重なる予測を持ちます。
予測期間 n_forecasts を増やすとき、過去の観測 n_lags の数も少なくとも同じ値にまで増やすべきです。
ここでは、最後の観測 6 時間に基づいて次の 3 時間を 5 分ステップで予測します :
m = NeuralProphet(
n_lags=6*12,
n_forecasts=3*12,
changepoints_range=0.95,
n_changepoints=30,
weekly_seasonality=False,
batch_size=64,
epochs=10,
learning_rate=1.0,
)
metrics = m.fit(df, freq='5min')
future = m.make_future_dataframe(df, n_historic_predictions=True)
forecast = m.predict(future)
fig = m.plot(forecast)
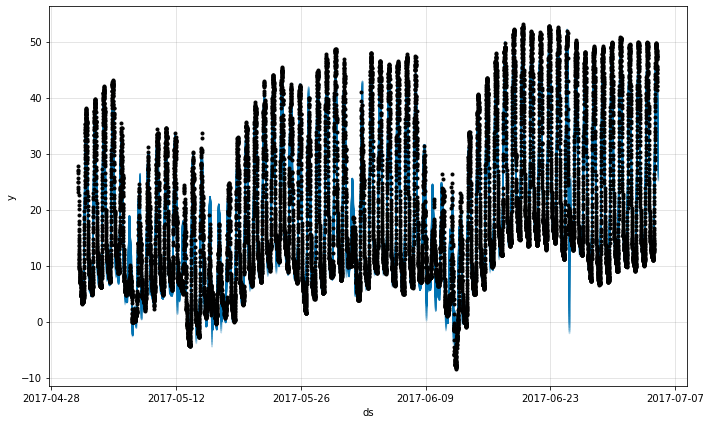
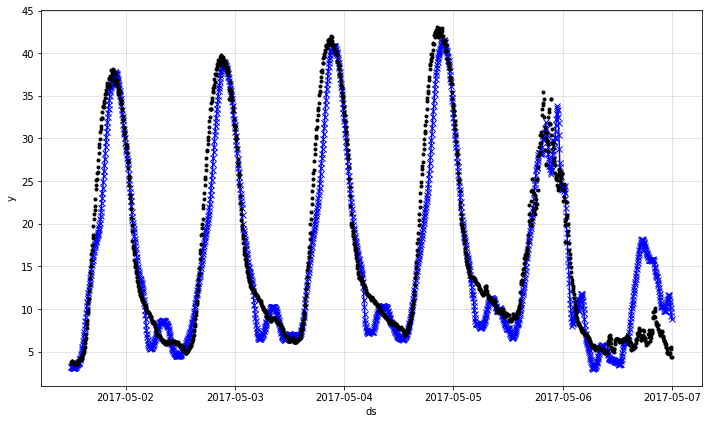
予測は時に一日のための予測を誤ってからより正確な予測に再度戻ることを見ます。データの 6 日目のその over-予測を詳しく見ましょう :
fig = m.plot(forecast[144:6*288])
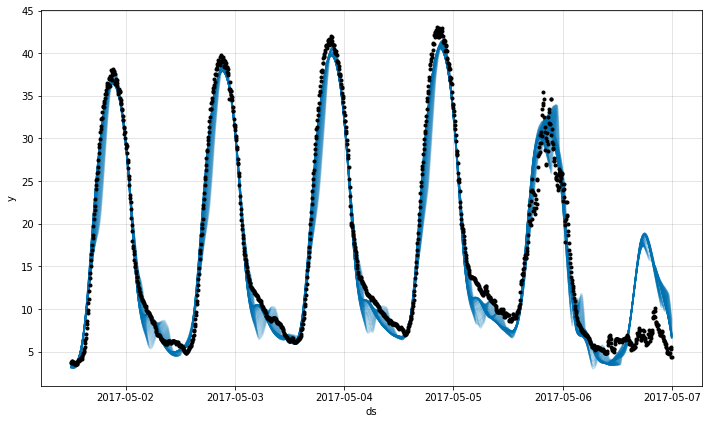
6 日目では、記録された気温は夜間に下がります。観測された低い夜間の気温に基づいて、モデルは低い日中のピークを予測します。けれども、実際の日中の気温は異常に低く、夜間よりもわずかに高くなっています。そのため、過大予測に繋がっています。
時間差 (= lag) の相対的な重要性を再度視覚化できます :
# fig_comp = m.plot_components(forecast)
fig_param = m.plot_parameters()
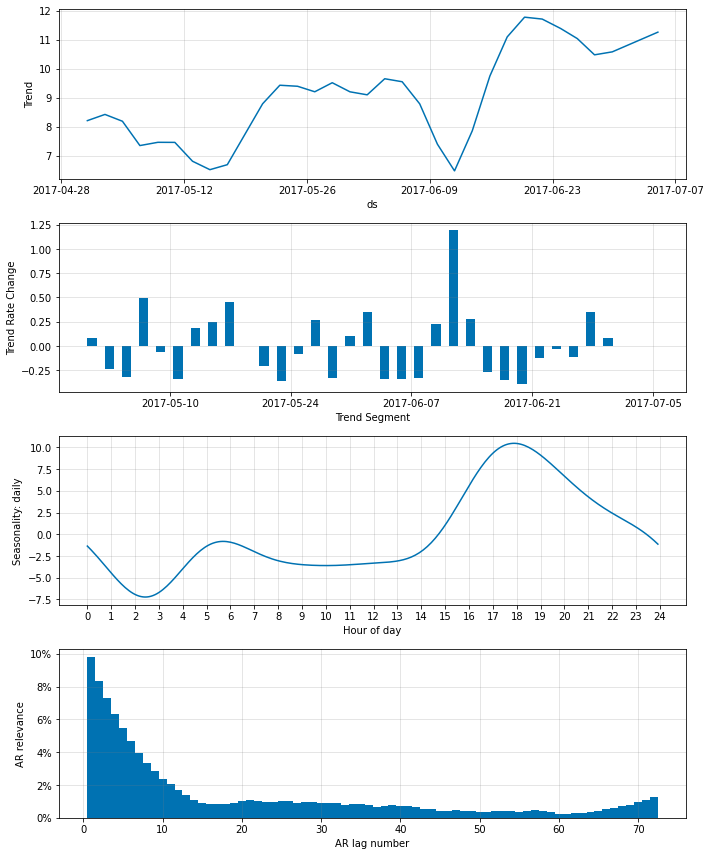
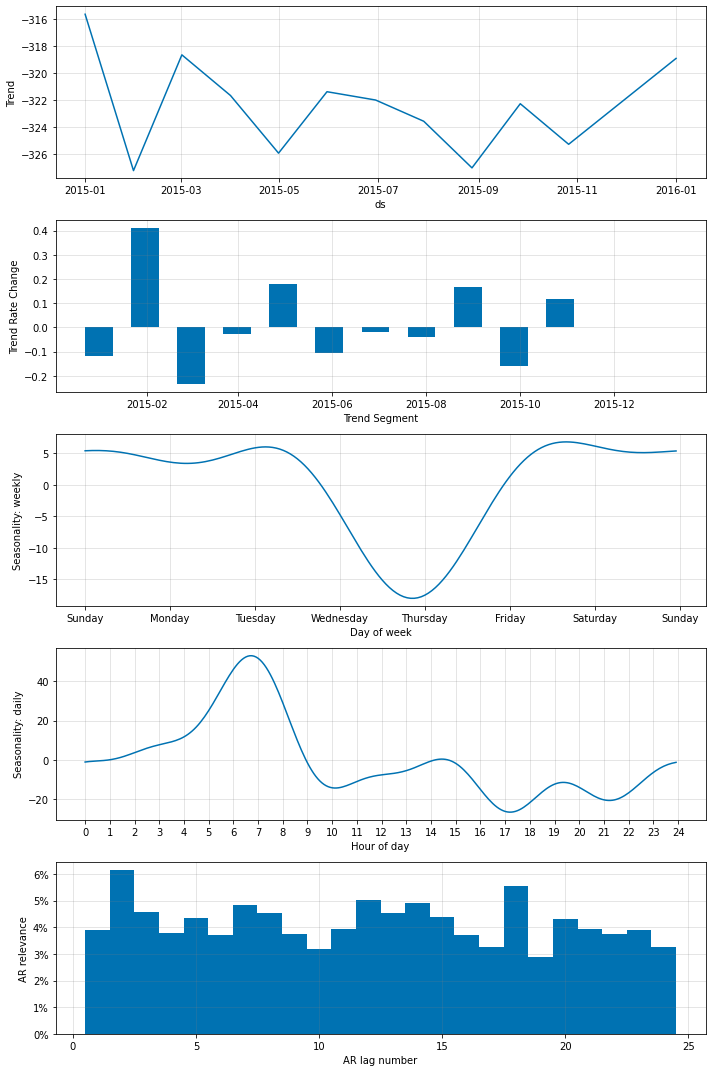
‘AR relevance’ は総ての n_forecasts に渡り平均化された、lag の相対的重要性であることに注意してください。
特定の予測ステップをレビューする
各予測の n-th ステップを強調することにより特定の予測期間を詳しく見ることができます。ここでは 3 時間先に予測される気温にフォーカスします (未来への最も離れた予測)。異なる 3 時間先の予測のための重みを詳しく見ましょう :
m = m.highlight_nth_step_ahead_of_each_forecast(3*12)
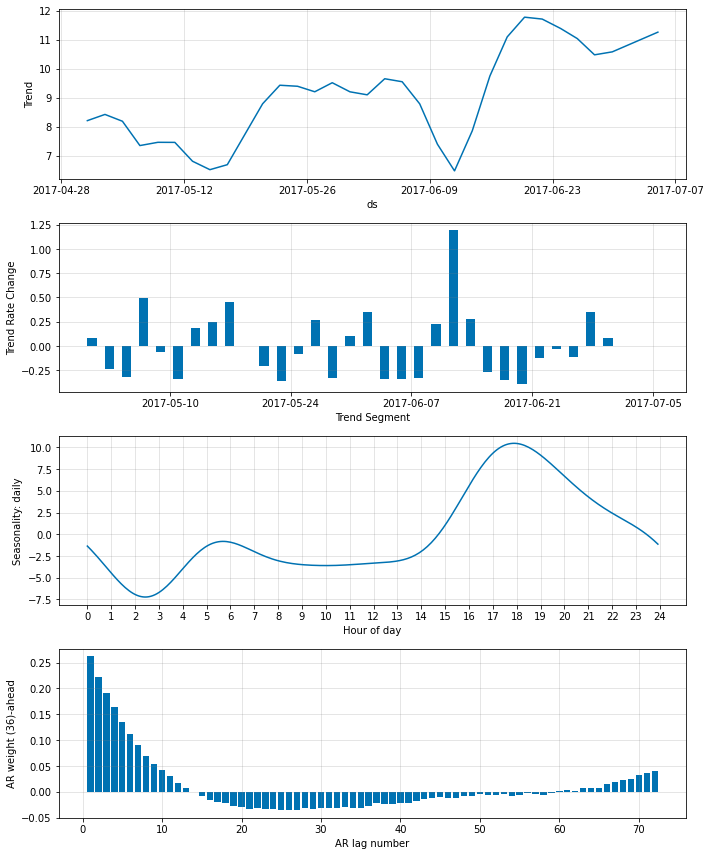
fig_param = m.plot_parameters()
次に、最初の 6 日間を再プロットしてそれを 1 ステップ先の予測と比較します。単一ステップ先の予測が 3 時間先の予測と比較して遥かに正確であることを観測します。けれども、いずれも 6 日目の異常を予測することはできません。
fig = m.plot(forecast[144:6*288])
m = m.highlight_nth_step_ahead_of_each_forecast(1)
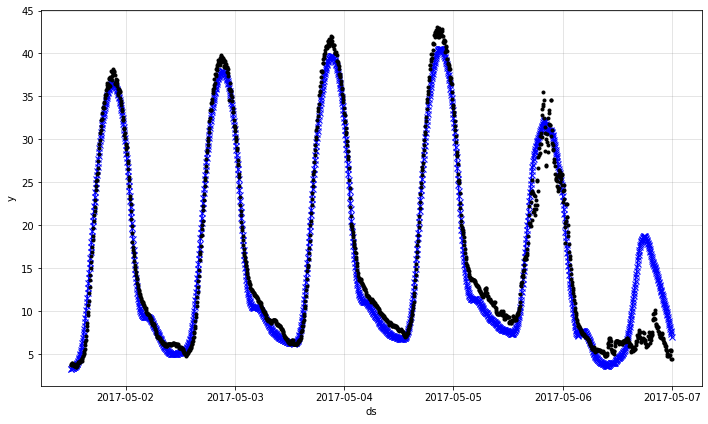
fig = m.plot(forecast[144:6*288])
最近の予測をプロットする
モデル適合よりも実際の推測により関心があるとき、最も最近の推測をプロットできます :
m = m.highlight_nth_step_ahead_of_each_forecast(None) # reset highlight
fig = m.plot_last_forecast(forecast)
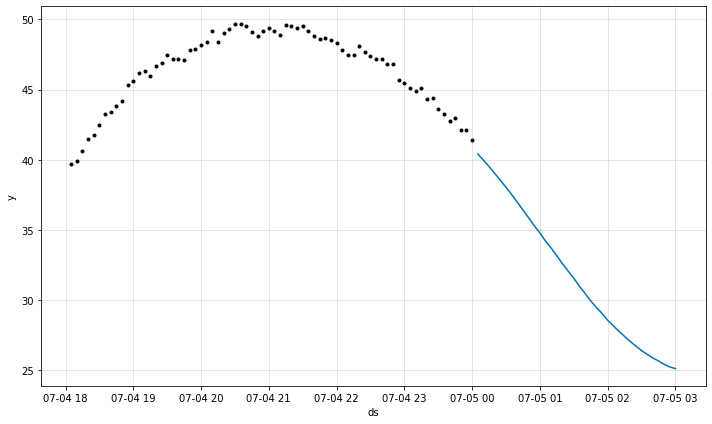
時間につれて予測がどのように変化したかを評価するために最後の幾つかの履歴予測が含められます。ここでは、最後の 2 時間に渡り与えられたとき、3 時間先の予測にフォーカスします。
m = m.highlight_nth_step_ahead_of_each_forecast(3*12)
fig = m.plot_last_forecast(forecast, include_previous_forecasts=2*12)
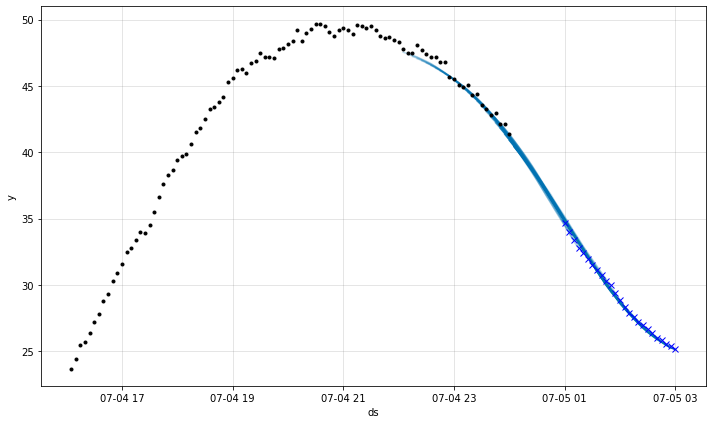
より大きな予測期間
未来への更なる予測について、データの解像度を減じることができます。5 分解像度の使用は高解像度短期予測のために有用かもしれませんが、長期予測のためには逆効果かもしれません。データの制限された総量 (約 2 ヶ月) を持つだけですので、モデルを過剰に指定することは回避することを望みます。
例として : 最後の日の気温 (n_lags=24*12) に基づいて未来への 24 時間 (nforecasts=24*12) を予測するように設定する場合、AR コンポーネントのパラメータ数は 24*12*24*12 = 82,944 に増大します。けれども、データセットにおよそ 2*30*24*12 = 17,280 サンプルを持つだけです。モデルは過剰指定されます。
最初にデータを hourly データにダウンサンプリングする場合、データセットを 2*30*24=1440 に、そしてモデルパラメータを 24*24=576 に減じます。こうして、モデルに適合させられます。けれども、より多くのデータを集めることがより良いです。
df.loc[:, "ds"] = pd.to_datetime(df.loc[:, "ds"])
df_hourly = df.set_index('ds', drop=False).resample('H').mean().reset_index()
len(df_hourly)
1561
df_hourly.head(3)
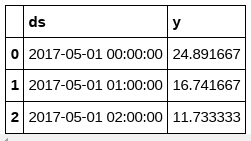
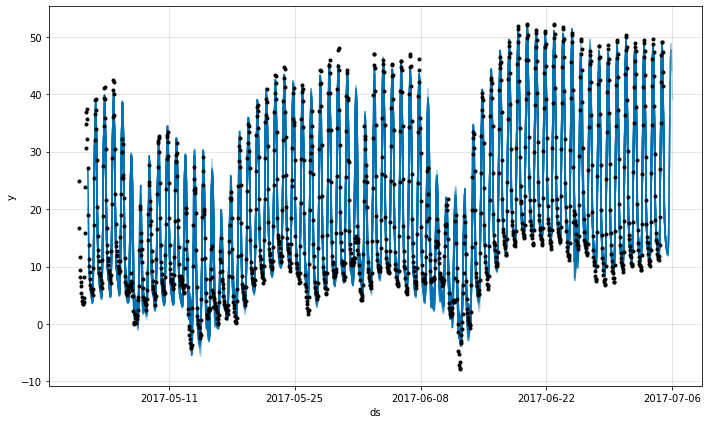
m = NeuralProphet(
n_lags=24,
n_forecasts=24,
changepoints_range=0.95,
n_changepoints=30,
weekly_seasonality=False,
learning_rate=0.3,
)
metrics = m.fit(df_hourly, freq='H')
future = m.make_future_dataframe(df_hourly, n_historic_predictions=True)
forecast = m.predict(future)
fig = m.plot(forecast)
# fig_param = m.plot_parameters()
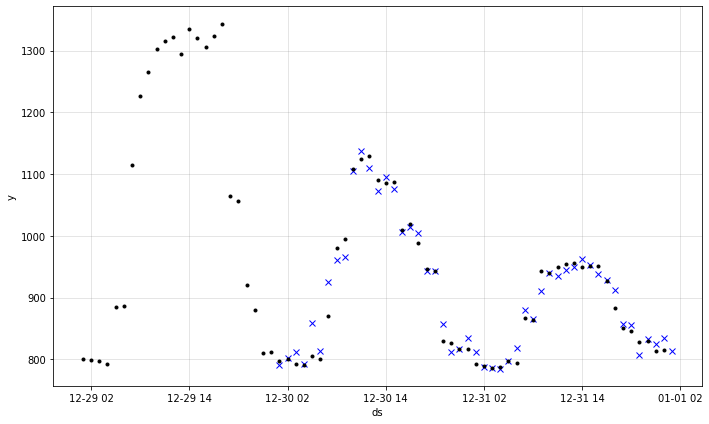
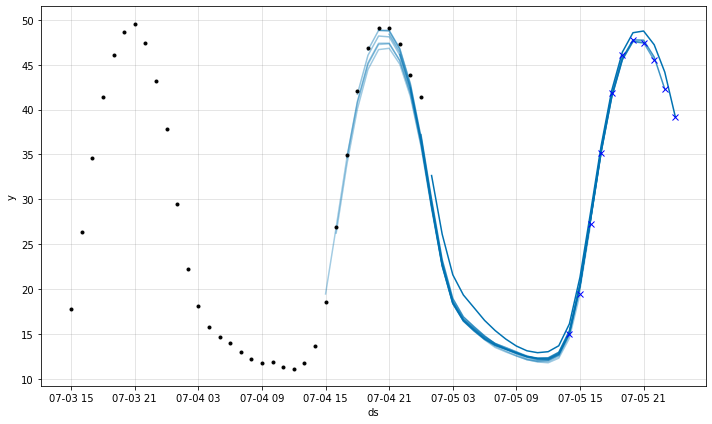
最後に、最も最近のそして最後の 10 履歴の 24 時間予測をプロットし、24-th 時間先を ‘x’ でマークします。
m = m.highlight_nth_step_ahead_of_each_forecast(24)
fig = m.plot_last_forecast(forecast, include_previous_forecasts=10)
以上
ClassCat® Chatbot
人工知能開発支援
- テクニカルコンサルティングサービス
- 実証実験 (プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
クラスキャット
セールス・インフォメーション
E-Mail:sales-info@classcat.com