Prophet 1.0 : 外れ値 (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 07/13/2021 (1.0)
* 本ページは、Prophet の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。

スケジュールは弊社 公式 Web サイト でご確認頂けます。
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
| 人工知能研究開発支援 | 人工知能研修サービス | テレワーク & オンライン授業を支援 |
| PoC(概念実証)を失敗させないための支援 (本支援はセミナーに参加しアンケートに回答した方を対象としています。) | ||
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |
Prophet 1.0 : 外れ値
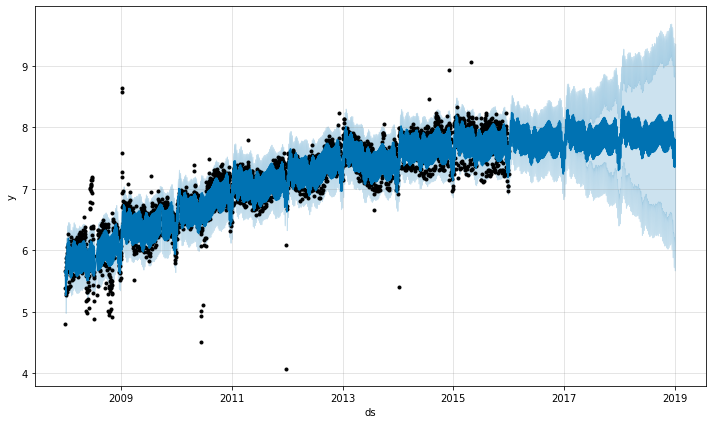
外れ値が Prophet の予測に影響を与えられる 2 つの主要な方法があります。ここでは前からの R ページへのログ記録された Wikipedia アクセスの予測を行ないますが、不良データのブロックを伴います。
df = pd.read_csv('../examples/example_wp_log_R_outliers1.csv')
m = Prophet()
m.fit(df)
future = m.make_future_dataframe(periods=1096)
forecast = m.predict(future)
fig = m.plot(forecast)
トレンド予測は合理的に見えますが、不確定区間は広すぎるようです。Prophet は履歴の外れ値を処理できますが、トレンド変化でそれらを適合させることによってのみです。そして不確実性モデルは同様の大きさの未来のトレンド変化を想定します。
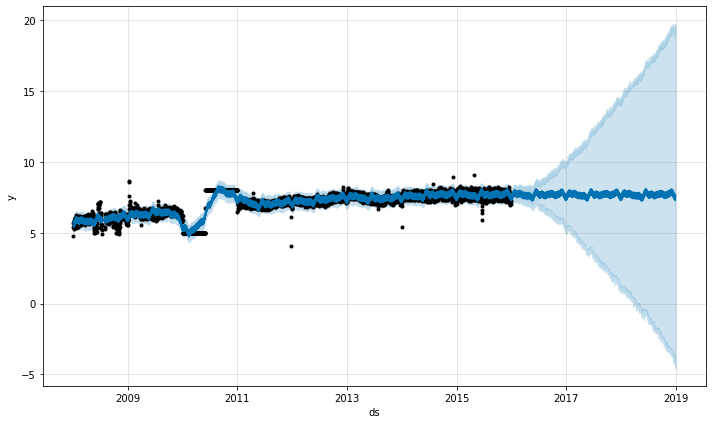
外れ値を扱う最善の方法はそれらを除去することです – Prophet はデータが欠落しても問題ありません。履歴でそれらの値を NA に設定してしかし未来の日付はそのままにする場合、Prophet はそれらの値の予測を与えます。
df.loc[(df['ds'] > '2010-01-01') & (df['ds'] < '2011-01-01'), 'y'] = None
model = Prophet().fit(df)
fig = model.plot(model.predict(future))

上の例では外れ値は不確実性推定を台無しにしましたが主要な予測 yhat には影響を与えませんでした。追加された外れ値をもつこの例でのように、これは常には当てはまりません :
df = pd.read_csv('../examples/example_wp_log_R_outliers2.csv')
m = Prophet()
m.fit(df)
future = m.make_future_dataframe(periods=1096)
forecast = m.predict(future)
fig = m.plot(forecast)
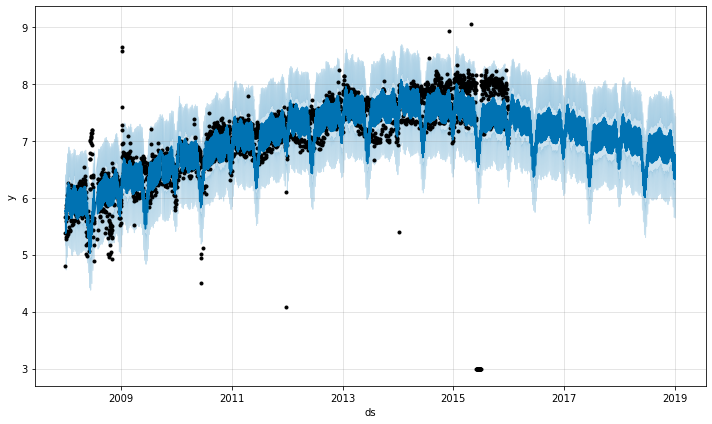
ここでは 2015年6月の極端な外れ値は季節性推定を台無しにしていますので、それらの効果は未来に永遠に響きます。再度、正しいアプローチはそれらを除去することです :
df.loc[(df['ds'] > '2015-06-01') & (df['ds'] < '2015-06-30'), 'y'] = None
m = Prophet().fit(df)
fig = m.plot(m.predict(future))
以上