Alibi Detect 0.7 : Examples : 外れ値、敵対的 & ドリフト検知 on CIFAR10 (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 07/04/2021 (0.7.0)
* 本ページは、Alibi Detect の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。

スケジュールは弊社 公式 Web サイト でご確認頂けます。
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
| 人工知能研究開発支援 | 人工知能研修サービス | テレワーク & オンライン授業を支援 |
| PoC(概念実証)を失敗させないための支援 (本支援はセミナーに参加しアンケートに回答した方を対象としています。) | ||
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |
Alibi Detect 0.7 : Examples : 外れ値、敵対的 & ドリフト検知 on CIFAR10
0. データセット
CIFAR10 は 10 クラス : 飛行機、自動車、鳥、猫、鹿、犬、カエル、馬、船とトラック – に渡り均等に分配された 60,000 の 32 x 32 RGB 画像から成ります。
# imports and plot examples
import matplotlib.pyplot as plt
%matplotlib inline
import tensorflow as tf
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.cifar10.load_data()
X_train = X_train.astype('float32') / 255
X_test = X_test.astype('float32') / 255
y_train = y_train.astype('int64').reshape(-1,)
y_test = y_test.astype('int64').reshape(-1,)
print('Train: ', X_train.shape, y_train.shape)
print('Test: ', X_test.shape, y_test.shape)
plt.figure(figsize=(10, 10))
n = 4
for i in range(n ** 2):
plt.subplot(n, n, i + 1)
plt.imshow(X_train[i])
plt.axis('off')
plt.show();
Train: (50000, 32, 32, 3) (50000,) Test: (10000, 32, 32, 3) (10000,)

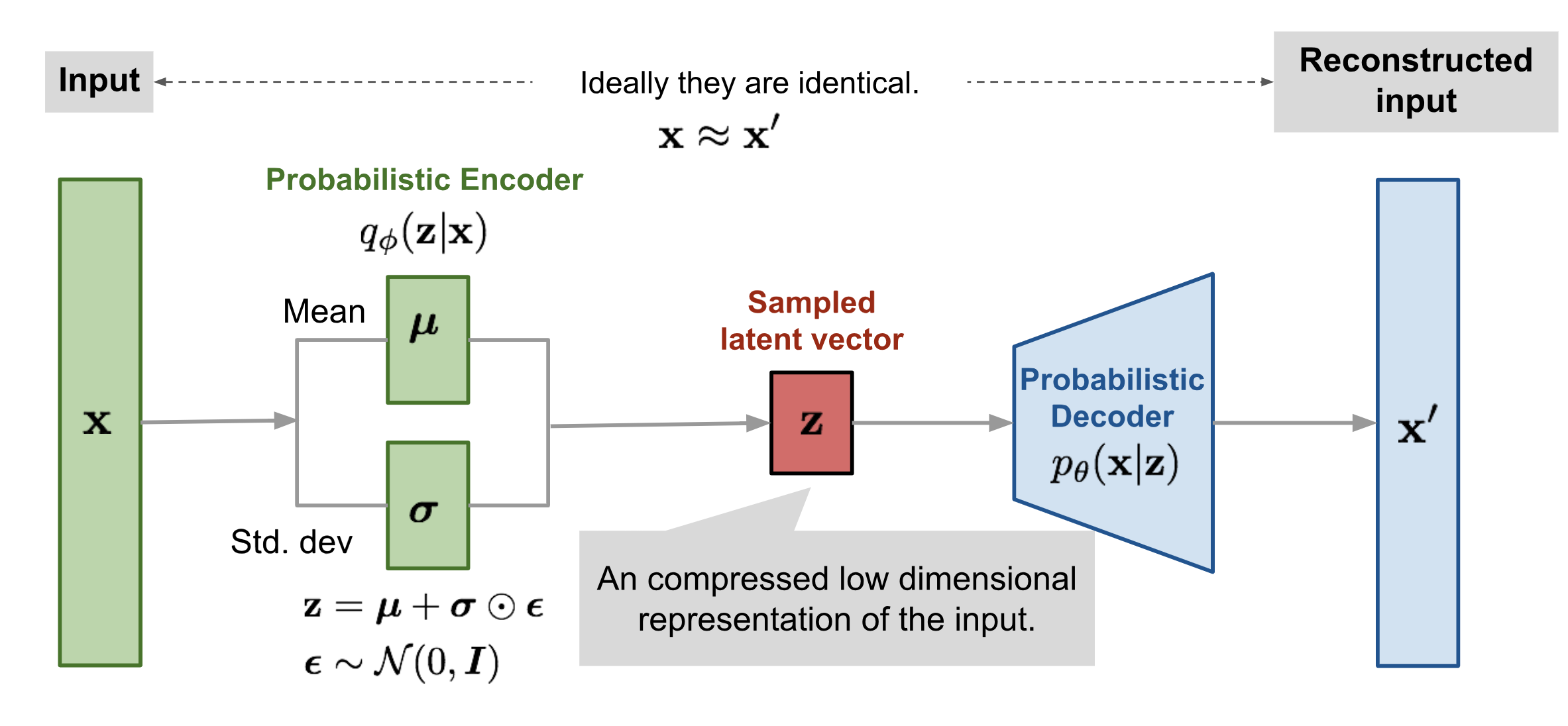
1. 変分オートエンコーダ (VAE) による外れ値検知
メソッド
簡単に言えば :
- 正常データ上で VAE を訓練するのでそれは inlier を上手く再構築できます。
- VAE が incoming リクエストを上手く再構築できないのであれば?外れ値です!
画像ソース: https://lilianweng.github.io/lil-log/2018/08/12/from-autoencoder-to-beta-vae.html
# more imports
import logging
import numpy as np
import os
from tensorflow.keras.layers import Conv2D, Conv2DTranspose, Dense
from tensorflow.keras.layers import Flatten, Layer, Reshape, InputLayer
from tensorflow.keras.regularizers import l1
from alibi_detect.od import OutlierVAE
from alibi_detect.utils.fetching import fetch_detector
from alibi_detect.utils.perturbation import apply_mask
from alibi_detect.utils.saving import save_detector, load_detector
from alibi_detect.utils.visualize import plot_instance_score, plot_feature_outlier_image
logger = tf.get_logger()
logger.setLevel(logging.ERROR)
検知器をロードまたはスクラッチから訓練する
ノートブックで使用される事前訓練済みの外れ値と敵対的検知器は ここ で見つかります。組込みの fetch_detector 関数を利用できます、これは事前訓練モデルをローカルディレクトリ filepath にセーブして検知器をロードします。代わりに、スクラッチから検知器を訓練することができます :
load_pretrained = False
%%time
filepath = os.path.join(os.getcwd(), 'outlier')
if load_pretrained: # load pre-trained detector
detector_type = 'outlier'
dataset = 'cifar10'
detector_name = 'OutlierVAE'
od = fetch_detector(filepath, detector_type, dataset, detector_name)
filepath = os.path.join(filepath, detector_name)
else: # define model, initialize, train and save outlier detector
# define encoder and decoder networks
latent_dim = 1024
encoder_net = tf.keras.Sequential(
[
InputLayer(input_shape=(32, 32, 3)),
Conv2D(64, 4, strides=2, padding='same', activation=tf.nn.relu),
Conv2D(128, 4, strides=2, padding='same', activation=tf.nn.relu),
Conv2D(512, 4, strides=2, padding='same', activation=tf.nn.relu)
]
)
decoder_net = tf.keras.Sequential(
[
InputLayer(input_shape=(latent_dim,)),
Dense(4*4*128),
Reshape(target_shape=(4, 4, 128)),
Conv2DTranspose(256, 4, strides=2, padding='same', activation=tf.nn.relu),
Conv2DTranspose(64, 4, strides=2, padding='same', activation=tf.nn.relu),
Conv2DTranspose(3, 4, strides=2, padding='same', activation='sigmoid')
]
)
# initialize outlier detector
od = OutlierVAE(
threshold=.015, # threshold for outlier score
encoder_net=encoder_net, # can also pass VAE model instead
decoder_net=decoder_net, # of separate encoder and decoder
latent_dim=latent_dim
)
# train
od.fit(X_train, epochs=50, verbose=True)
# save the trained outlier detector
save_detector(od, filepath)
782/782 [=] - 32s 36ms/step - loss: 3328.0921 782/782 [=] - 29s 36ms/step - loss: -2477.8159 782/782 [=] - 29s 36ms/step - loss: -3505.9077 782/782 [=] - 29s 36ms/step - loss: -4018.4684 782/782 [=] - 29s 36ms/step - loss: -4339.1812 782/782 [=] - 29s 36ms/step - loss: -4564.4784 782/782 [=] - 29s 36ms/step - loss: -4752.0325 782/782 [=] - 29s 36ms/step - loss: -4909.1439 782/782 [=] - 29s 36ms/step - loss: -5027.7148 782/782 [=] - 29s 36ms/step - loss: -5108.3359 782/782 [=] - 29s 36ms/step - loss: -5183.5322 782/782 [=] - 29s 36ms/step - loss: -5221.8213 782/782 [=] - 29s 36ms/step - loss: -5286.5078 782/782 [=] - 29s 36ms/step - loss: -5336.4698 782/782 [=] - 29s 36ms/step - loss: -5390.1145 782/782 [=] - 29s 36ms/step - loss: -5435.4759 782/782 [=] - 29s 36ms/step - loss: -5469.5508 782/782 [=] - 29s 36ms/step - loss: -5513.7060 782/782 [=] - 29s 36ms/step - loss: -5546.3630 782/782 [=] - 29s 36ms/step - loss: -5586.9172 782/782 [=] - 29s 36ms/step - loss: -5604.6617 782/782 [=] - 29s 36ms/step - loss: -5638.2204 782/782 [=] - 29s 36ms/step - loss: -5657.4971 782/782 [=] - 29s 36ms/step - loss: -5684.9612 782/782 [=] - 29s 36ms/step - loss: -5706.7390 782/782 [=] - 29s 36ms/step - loss: -5719.2535 782/782 [=] - 29s 36ms/step - loss: -5742.7461 782/782 [=] - 29s 36ms/step - loss: -5760.9044 782/782 [=] - 29s 36ms/step - loss: -5777.8526 782/782 [=] - 29s 36ms/step - loss: -5793.0808 782/782 [=] - 29s 36ms/step - loss: -5803.5456 782/782 [=] - 29s 36ms/step - loss: -5822.1962 782/782 [=] - 29s 36ms/step - loss: -5821.3968 782/782 [=] - 29s 36ms/step - loss: -5847.5206 782/782 [=] - 29s 36ms/step - loss: -5855.4035 782/782 [=] - 29s 36ms/step - loss: -5866.9793 782/782 [=] - 29s 36ms/step - loss: -5879.4730 782/782 [=] - 29s 36ms/step - loss: -5885.7166 782/782 [=] - 29s 36ms/step - loss: -5895.9667 782/782 [=] - 29s 36ms/step - loss: -5905.9128 782/782 [=] - 29s 36ms/step - loss: -5913.2937 782/782 [=] - 29s 36ms/step - loss: -5922.4864 782/782 [=] - 29s 36ms/step - loss: -5930.4101 782/782 [=] - 29s 36ms/step - loss: -5935.5514 782/782 [=] - 29s 36ms/step - loss: -5942.9960 782/782 [=] - 29s 36ms/step - loss: -5953.9588 782/782 [=] - 29s 36ms/step - loss: -5959.2278 782/782 [=] - 29s 36ms/step - loss: -5962.3586 782/782 [=] - 29s 36ms/step - loss: -5967.2992 782/782 [=] - 29s 36ms/step - loss: -5975.1563 Directory /home/ubuntu/ws.alibi_detect/outlier does not exist and is now created. CPU times: user 24min 6s, sys: 22.3 s, total: 24min 28s Wall time: 24min 8s
モデルが in-distribution 訓練データを何とか再構築できるかを確認しましょう :
# plot original and reconstructed instance
idx = 8
X = X_train[idx].reshape(1, 32, 32, 3)
X_recon = od.vae(X)
plt.imshow(X.reshape(32, 32, 3)); plt.axis('off'); plt.show()
plt.imshow(X_recon.numpy().reshape(32, 32, 3)); plt.axis('off'); plt.show()


閾値を設定する
良い閾値を見つけることは技巧的であり得ます、何故ならばそれらは典型的には解釈することが容易でないからです。infer_threshold メソッドは sensible な値を見つけるのに役立ちます。インスタンスのバッチ X を渡してそれらの何パーセントを正常であると考えるかを threshold_perc を通して指定する必要があります。
print('Current threshold: {}'.format(od.threshold))
od.infer_threshold(X_train, threshold_perc=99, batch_size=128) # assume 1% of the training data are outliers
print('New threshold: {}'.format(od.threshold))
Current threshold: 0.015 New threshold: 0.00969364859163762
外れ値を作成して検知する
元のインスタンスにランダムノイズマスクを適用することにより幾つかの外れ値を作成できます :
np.random.seed(0)
i = 1
# create masked instance
x = X_test[i].reshape(1, 32, 32, 3)
x_mask, mask = apply_mask(
x,
mask_size=(8,8),
n_masks=1,
channels=[0,1,2],
mask_type='normal',
noise_distr=(0,1),
clip_rng=(0,1)
)
# predict outliers and reconstructions
sample = np.concatenate([x_mask, x])
preds = od.predict(sample)
x_recon = od.vae(sample).numpy()
# check if outlier and visualize outlier scores
labels = ['No!', 'Yes!']
print(f"Is original outlier? {labels[preds['data']['is_outlier'][1]]}")
print(f"Is perturbed outlier? {labels[preds['data']['is_outlier'][0]]}")
plot_feature_outlier_image(preds, sample, x_recon, max_instances=1)
Is original outlier? No! Is perturbed outlier? Yes!

検知器を配備する
このサンプルのオープンソース配備プラットフォーム Seldon Core と (サーバレス・コンポーネントがイベントストリームに接続されることを可能にする) イベント・ベースのプロジェクト Knative を使用します。Seldon Core payload logger はモデルリクエストを含むイベントを Knative に送ります、これはこれらを外れ値、ドリフトや敵対的検知モジュールのようなサーバレス・コンポーネントに委託することができます。更に例えばアラート or ストレージ・モジュールに前方に送るためにこれらのコンポーネントにより生成されたイベントを供給するためにイベント・コンポーネントが追加できます。これらは非同期に発生します。
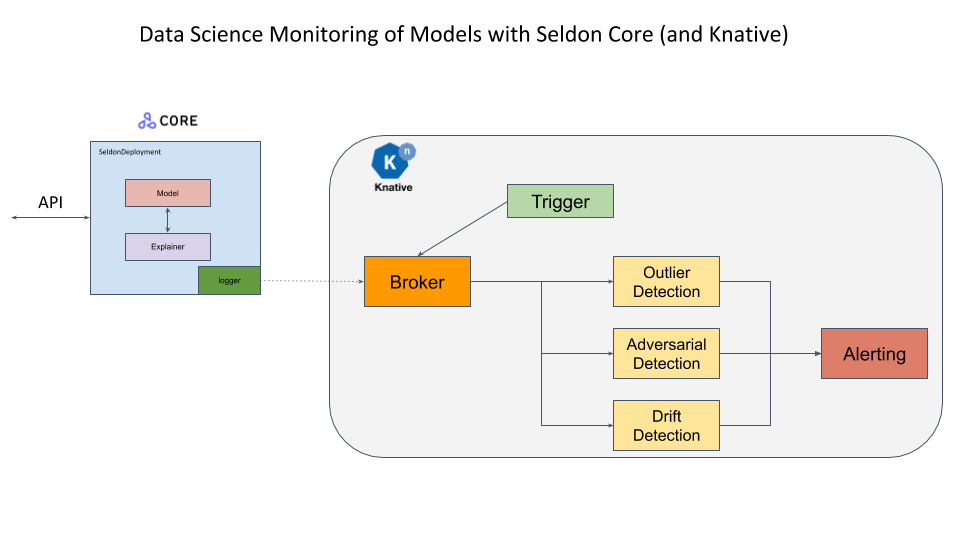
既に Seldon Core をインストールして DigitalOcean 上クラスタを構成しました。スクラッチから総てをセットアップする構成ステップは このサンプル・ノートブック で詳述されています。
最初に Istio Ingress Gatewaw の IP アドレスを取得します。これは Istio が LoadBalancer とともにインストールされていることを仮定しています。
CLUSTER_IPS=!(kubectl -n istio-system get service istio-ingressgateway -o jsonpath='{.status.loadBalancer.ingress[0].ip}')
CLUSTER_IP=CLUSTER_IPS[0]
print(CLUSTER_IP)
188.166.139.197
SERVICE_HOSTNAMES=!(kubectl get ksvc vae-outlier -o jsonpath='{.status.url}' | cut -d "/" -f 3)
SERVICE_HOSTNAME_VAEOD=SERVICE_HOSTNAMES[0]
print(SERVICE_HOSTNAME_VAEOD)
vae-outlier.default.example.com
配備されたモデルの予測のために幾つかのユティリティ関数を定義します。
import json
import requests
from typing import Union
classes = ('plane', 'car', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck')
def predict(x: np.ndarray) -> Union[str, list]:
""" Model prediction. """
formData = {
'instances': x.tolist()
}
headers = {}
res = requests.post(
'http://'+CLUSTER_IP+'/seldon/default/tfserving-cifar10/v1/models/resnet32/:predict',
json=formData,
headers=headers
)
if res.status_code == 200:
return classes[np.array(res.json()["predictions"])[0].argmax()]
else:
print("Failed with ",res.status_code)
return []
def outlier(x: np.ndarray) -> Union[dict, list]:
""" Outlier prediction. """
formData = {
'instances': x.tolist()
}
headers = {
"Alibi-Detect-Return-Feature-Score": "true",
"Alibi-Detect-Return-Instance-Score": "true"
}
headers["Host"] = SERVICE_HOSTNAME_VAEOD
res = requests.post('http://'+CLUSTER_IP+'/', json=formData, headers=headers)
if res.status_code == 200:
od = res.json()
od["data"]["feature_score"] = np.array(od["data"]["feature_score"])
od["data"]["instance_score"] = np.array(od["data"]["instance_score"])
return od
else:
print("Failed with ",res.status_code)
return []
def show(x: np.ndarray) -> None:
plt.imshow(x.reshape(32, 32, 3))
plt.axis('off')
plt.show()
元のインスタンス上で予測を行ないましょう :
show(x)
predict(x)

'ship'
外れ値検知器の出力のためにメッセージ dumper を確認しましょう :
res=!kubectl logs $(kubectl get pod -l serving.knative.dev/configuration=message-dumper -o jsonpath='{.items[0].metadata.name}') user-container
data = []
for i in range(0,len(res)):
if res[i] == 'Data,':
data.append(res[i+1])
j = json.loads(json.loads(data[0]))
print("Outlier?",labels[j["data"]["is_outlier"]==[1]])
Outlier? No!
そして摂動されたインスタンスで予測を行ないます :
show(x_mask)
predict(x_mask)

'ship'
予測は依然として正しいですが、インスタンスは明らかに外れ値です :
res=!kubectl logs $(kubectl get pod -l serving.knative.dev/configuration=message-dumper -o jsonpath='{.items[0].metadata.name}') user-container
data= []
for i in range(0,len(res)):
if res[i] == 'Data,':
data.append(res[i+1])
j = json.loads(json.loads(data[1]))
print("Outlier?",labels[j["data"]["is_outlier"]==[1]])
Outlier? Yes!
preds = outlier(x_mask)
plot_feature_outlier_image(preds, x_mask, X_recon=None)

2. 予測確率のマッチングによる敵対的検知
メソッド
敵対的検知器は Adversarial Detection and Correction by Matching Prediction Distributions に基づいています。通常、オートエンコーダは平均二乗再構築誤差のような $x$ と $x’$ の間の類似性を捕捉するのに適する損失関数を用いて、入力インスタンス $x$ を出来る限り正確に再構築するような変換 $T$ を見つけるために訓練されます。敵対的オートエンコーダ (AE) 検知器の新奇性は、オートエンコーダネットワークを訓練するために、モデルの出力空間の距離尺度に基づいた分類モデル依存な損失関数の使用に依存していることです。分類モデル $M$ が与えられたとき、オートエンコーダの重みは $x$ と $x’$ のモデル予測間の KL-ダイバージェンス を最小化するように最適化されます。再構築損失項 $x’$ の存在がない場合には、$x$ と $x’$ の近接性を気に掛けることなく、単純に予測確率 $M(x’)$ と $M(x)$ が一致することを確かなものにしようとします。その結果、$x’$ はモデル $M$ に関する異なる決定境界 shape によって $x$ とは異なる入力特徴空間の異なる領域に存在することが可能になります。$x$ 周りで効果的な注意深く作成された敵対的摂動は特徴空間の $x’$ の新しい位置には転送されませんので、従って攻撃は無力化されます。オートエンコーダの訓練は教師なしです、何故ならばモデル予測確率と通常の訓練インスタンスへのアクセスだけを必要とするからです。基礎となる敵対的攻撃についての知識を必要としません、そして分類器の重みは訓練の間凍結されます。
検知器は以下のように利用できます :
- 敵対的スコア $S$ が計算されます。$S$ は $x$ と $x’$ のモデル予測間の K-L ダイバージェンスに等しいです。
- $S$ が (明示的に定義されたか訓練データから推論された) 閾値を越える場合、インスタンスは敵対的とフラグ立てされます。
- 敵対的インスタンスについては、モデル $M$ は予測を行なうために再構築されたインスタンス $x’$ を使用します。敵対的スコアが閾値の下であれば、モデルは元のインスタンス $x$ 上で予測を行ないます。
この手順は下の図で図示されます :
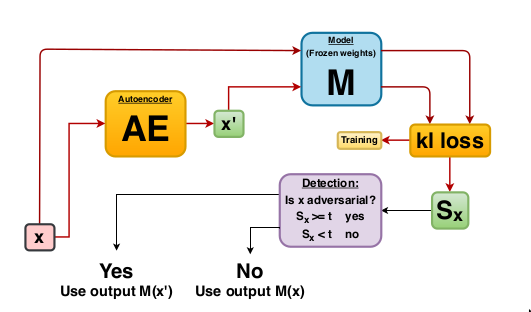
この方法は非常に柔軟で、モデル性能にネガティブな影響を与える一般的なデータ破損と摂動を検出するためにも使用できます。
# more imports
from sklearn.metrics import roc_curve, auc
from alibi_detect.ad import AdversarialAE
from alibi_detect.datasets import fetch_attack
from alibi_detect.utils.fetching import fetch_tf_model
from alibi_detect.utils.prediction import predict_batch
ユティリティ関数
# instance scaling and plotting utility functions
def scale_by_instance(X: np.ndarray) -> np.ndarray:
mean_ = X.mean(axis=(1, 2, 3)).reshape(-1, 1, 1, 1)
std_ = X.std(axis=(1, 2, 3)).reshape(-1, 1, 1, 1)
return (X - mean_) / std_, mean_, std_
def accuracy(y_true: np.ndarray, y_pred: np.ndarray) -> float:
return (y_true == y_pred).astype(int).sum() / y_true.shape[0]
def plot_adversarial(idx: list,
X: np.ndarray,
y: np.ndarray,
X_adv: np.ndarray,
y_adv: np.ndarray,
mean: np.ndarray,
std: np.ndarray,
score_x: np.ndarray = None,
score_x_adv: np.ndarray = None,
X_recon: np.ndarray = None,
y_recon: np.ndarray = None,
figsize: tuple = (10, 5)) -> None:
# category map from class numbers to names
cifar10_map = {0: 'airplane', 1: 'automobile', 2: 'bird', 3: 'cat', 4: 'deer', 5: 'dog',
6: 'frog', 7: 'horse', 8: 'ship', 9: 'truck'}
nrows = len(idx)
ncols = 3 if isinstance(X_recon, np.ndarray) else 2
fig, ax = plt.subplots(nrows=nrows, ncols=ncols, figsize=figsize)
n_subplot = 1
for i in idx:
# rescale images in [0, 1]
X_adj = (X[i] * std[i] + mean[i]) / 255
X_adv_adj = (X_adv[i] * std[i] + mean[i]) / 255
if isinstance(X_recon, np.ndarray):
X_recon_adj = (X_recon[i] * std[i] + mean[i]) / 255
# original image
plt.subplot(nrows, ncols, n_subplot)
plt.axis('off')
if i == idx[0]:
if isinstance(score_x, np.ndarray):
plt.title('CIFAR-10 Image \n{}: {:.3f}'.format(cifar10_map[y[i]], score_x[i]))
else:
plt.title('CIFAR-10 Image \n{}'.format(cifar10_map[y[i]]))
else:
if isinstance(score_x, np.ndarray):
plt.title('{}: {:.3f}'.format(cifar10_map[y[i]], score_x[i]))
else:
plt.title('{}'.format(cifar10_map[y[i]]))
plt.imshow(X_adj)
n_subplot += 1
# adversarial image
plt.subplot(nrows, ncols, n_subplot)
plt.axis('off')
if i == idx[0]:
if isinstance(score_x_adv, np.ndarray):
plt.title('Adversarial \n{}: {:.3f}'.format(cifar10_map[y_adv[i]], score_x_adv[i]))
else:
plt.title('Adversarial \n{}'.format(cifar10_map[y_adv[i]]))
else:
if isinstance(score_x_adv, np.ndarray):
plt.title('{}: {:.3f}'.format(cifar10_map[y_adv[i]], score_x_adv[i]))
else:
plt.title('{}'.format(cifar10_map[y_adv[i]]))
plt.imshow(X_adv_adj)
n_subplot += 1
# reconstructed image
if isinstance(X_recon, np.ndarray):
plt.subplot(nrows, ncols, n_subplot)
plt.axis('off')
if i == idx[0]:
plt.title('AE Reconstruction \n{}'.format(cifar10_map[y_recon[i]]))
else:
plt.title('{}'.format(cifar10_map[y_recon[i]]))
plt.imshow(X_recon_adj)
n_subplot += 1
plt.show()
def plot_roc(roc_data: dict, figsize: tuple = (10,5)):
plot_labels = []
scores_attacks = []
labels_attacks = []
for k, v in roc_data.items():
if 'original' in k:
continue
score_x = roc_data[v['normal']]['scores']
y_pred = roc_data[v['normal']]['predictions']
score_v = v['scores']
y_pred_v = v['predictions']
labels_v = np.ones(score_x.shape[0])
idx_remove = np.where(y_pred == y_pred_v)[0]
labels_v = np.delete(labels_v, idx_remove)
score_v = np.delete(score_v, idx_remove)
scores = np.concatenate([score_x, score_v])
labels = np.concatenate([np.zeros(y_pred.shape[0]), labels_v]).astype(int)
scores_attacks.append(scores)
labels_attacks.append(labels)
plot_labels.append(k)
for sc_att, la_att, plt_la in zip(scores_attacks, labels_attacks, plot_labels):
fpr, tpr, thresholds = roc_curve(la_att, sc_att)
roc_auc = auc(fpr, tpr)
label = str('{}: AUC = {:.2f}'.format(plt_la, roc_auc))
plt.plot(fpr, tpr, lw=1, label='{}: AUC={:.4f}'.format(plt_la, roc_auc))
plt.plot([0, 1], [0, 1], color='black', lw=1, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('{}'.format('ROC curve'))
plt.legend(loc="lower right", ncol=1)
plt.grid()
plt.show()
データをリスケールする
ResNet 分類モデルはインスタンスにより標準化されたデータ上で訓練されます :
# rescale data
X_train, mean_train, std_train = scale_by_instance(X_train * 255.)
X_test, mean_test, std_test = scale_by_instance(X_test * 255.)
scale = (mean_train, std_train), (mean_test, std_test)
事前訓練済みの分類器をロードする
dataset = 'cifar10'
model = 'resnet56'
clf = fetch_tf_model(dataset, model)
テスト上の予測を確認します :
y_pred = predict_batch(clf, X_test, batch_size=32, return_class=True)
acc_y_pred = accuracy(y_test, y_pred)
print('Accuracy: {:.4f}'.format(acc_y_pred))
Accuracy: 0.9315
敵対的攻撃
Carlini-Wagner (C&W) と SLIDE 攻撃の両者を調査します。以前に見つかった敵対的なインスタンスを事前訓練済みの ResNet-56 モデル上に単純にロードできます。攻撃は Foolbox を使用して生成されます :
# C&W attack
data_cw = fetch_attack(dataset, model, 'cw')
X_train_cw, X_test_cw = data_cw['data_train'], data_cw['data_test']
meta_cw = data_cw['meta'] # metadata with hyperparameters of the attack
# SLIDE attack
data_slide = fetch_attack(dataset, model, 'slide')
X_train_slide, X_test_slide = data_slide['data_train'], data_slide['data_test']
meta_slide = data_slide['meta']
分類器の精度が殆ど 0% に低下することを検証できます :
y_pred_cw = predict_batch(clf, X_test_cw, batch_size=32, return_class=True)
y_pred_slide = predict_batch(clf, X_test_slide, batch_size=32, return_class=True)
acc_y_pred_cw = accuracy(y_test, y_pred_cw)
acc_y_pred_slide = accuracy(y_test, y_pred_slide)
print('Accuracy: cw {:.4f} -- SLIDE {:.4f}'.format(acc_y_pred_cw, acc_y_pred_slide))
Accuracy: cw 0.0000 -- SLIDE 0.0001
幾つかの敵対的インスタンスを可視化しましょう :
# plot attacked instances
idx = [3, 4]
print('C&W attack...')
plot_adversarial(idx, X_test, y_pred, X_test_cw, y_pred_cw,
mean_test, std_test, figsize=(10, 10))
print('SLIDE attack...')
plot_adversarial(idx, X_test, y_pred, X_test_slide, y_pred_slide,
mean_test, std_test, figsize=(10, 10))
C&W 攻撃 …

SLIDE 攻撃 …

敵対的検知器をロードまたは訓練して評価する
Google Cloud Bucket から事前訓練済みの検知器を再度取得するかスクラッチから訓練できます :
load_pretrained = False
filepath = os.path.join(os.getcwd(), 'adversarial')
if load_pretrained:
detector_type = 'adversarial'
detector_name = 'base'
ad = fetch_detector(filepath, detector_type, dataset, detector_name, model=model)
filepath = os.path.join(filepath, detector_name)
else: # train detector from scratch
# define encoder and decoder networks
encoder_net = tf.keras.Sequential(
[
InputLayer(input_shape=(32, 32, 3)),
Conv2D(32, 4, strides=2, padding='same',
activation=tf.nn.relu, kernel_regularizer=l1(1e-5)),
Conv2D(64, 4, strides=2, padding='same',
activation=tf.nn.relu, kernel_regularizer=l1(1e-5)),
Conv2D(256, 4, strides=2, padding='same',
activation=tf.nn.relu, kernel_regularizer=l1(1e-5)),
Flatten(),
Dense(40)
]
)
decoder_net = tf.keras.Sequential(
[
InputLayer(input_shape=(40,)),
Dense(4 * 4 * 128, activation=tf.nn.relu),
Reshape(target_shape=(4, 4, 128)),
Conv2DTranspose(256, 4, strides=2, padding='same',
activation=tf.nn.relu, kernel_regularizer=l1(1e-5)),
Conv2DTranspose(64, 4, strides=2, padding='same',
activation=tf.nn.relu, kernel_regularizer=l1(1e-5)),
Conv2DTranspose(3, 4, strides=2, padding='same',
activation=None, kernel_regularizer=l1(1e-5))
]
)
# initialise and train detector
ad = AdversarialAE(
encoder_net=encoder_net,
decoder_net=decoder_net,
model=clf
)
ad.fit(X_train, epochs=40, batch_size=64, verbose=True)
# save the trained adversarial detector
save_detector(ad, filepath)
検知器は最初に敵対的であり得る入力インスタンスを再構築します。そして再構築された入力は敵対的スコアを計算するために分類器に供給されます。スコアが閾値より上の場合、インスタンスは敵対的と分類されて検知器は攻撃を正そうとします。攻撃されたインスタンスを再構築してその上で予測を行なうとき何が起きるかを調べましょう :
X_recon_cw = predict_batch(ad.ae, X_test_cw, batch_size=32)
X_recon_slide = predict_batch(ad.ae, X_test_slide, batch_size=32)
y_recon_cw = predict_batch(clf, X_recon_cw, batch_size=32, return_class=True)
y_recon_slide = predict_batch(clf, X_recon_slide, batch_size=32, return_class=True)
攻撃された (インスタンス) vs. 再構築されたインスタンスの精度 :
acc_y_recon_cw = accuracy(y_test, y_recon_cw)
acc_y_recon_slide = accuracy(y_test, y_recon_slide)
print('Accuracy after C&W attack {:.4f} -- reconstruction {:.4f}'.format(acc_y_pred_cw, acc_y_recon_cw))
print('Accuracy after SLIDE attack {:.4f} -- reconstruction {:.4f}'.format(acc_y_pred_slide, acc_y_recon_slide))
Accuracy after C&W attack 0.0000 -- reconstruction 0.8048 Accuracy after SLIDE attack 0.0001 -- reconstruction 0.8159
検知器は攻撃後の精度を殆ど 0 % から 80% を上手く越えるまでに復旧します!攻撃的スコアを計算して再構築されたインスタンスの幾つかを調査できます :
score_x = ad.score(X_test, batch_size=32)
score_cw = ad.score(X_test_cw, batch_size=32)
score_slide = ad.score(X_test_slide, batch_size=32)
# visualize original, attacked and reconstructed instances with adversarial scores
print('C&W attack...')
idx = [10, 13, 14, 16, 17]
plot_adversarial(idx, X_test, y_pred, X_test_cw, y_pred_cw, mean_test, std_test,
score_x=score_x, score_x_adv=score_cw, X_recon=X_recon_cw,
y_recon=y_recon_cw, figsize=(10, 15))
print('SLIDE attack...')
idx = [23, 25, 27, 29, 34]
plot_adversarial(idx, X_test, y_pred, X_test_slide, y_pred_slide, mean_test, std_test,
score_x=score_x, score_x_adv=score_slide, X_recon=X_recon_slide,
y_recon=y_recon_slide, figsize=(10, 15))
C&W 攻撃 …

SLIDE 攻撃 …

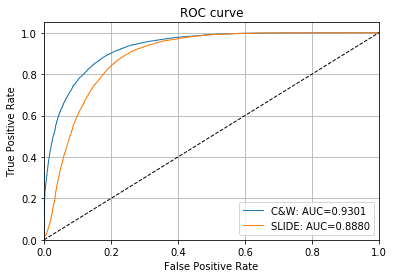
ROC カーブと AUC 値は敵対的インスタンスを検知するための敵対的スコアの有効性を示します :
# plot roc curve
roc_data = {
'original': {'scores': score_x, 'predictions': y_pred},
'C&W': {'scores': score_cw, 'predictions': y_pred_cw, 'normal': 'original'},
'SLIDE': {'scores': score_slide, 'predictions': y_pred_slide, 'normal': 'original'}
}
plot_roc(roc_data)
敵対的スコアのための閾値は infer_threshold を通して設定できます。インスタンスのバッチ X を渡してそれらの何パーセントを正常であると考えるかを threshold_perc を通して指定する必要があります。Assume we have only normal instances some of which the model has misclassified leading to a higher score if the reconstruction picked up features from the correct class or some might look adversarial in the first place. その結果、閾値を 95% に設定します :
ad.infer_threshold(X_test, threshold_perc=95, margin=0., batch_size=32)
print('Adversarial threshold: {:.4f}'.format(ad.threshold))
Adversarial threshold: 2.6722
検知器の正しい方法は Figure 1 の図を実行します。最初に敵対的スコアが計算されます。スコアが閾値を越えるインスタンスについては、再構築されたインスタンスの分類器予測が返されます。そうでなければ元の予測が保持されます。このメソッドは検知器のメタデータ、(バッチのインスタンスが敵対的であろうとなかろうと、) 訂正メカニズムを使用した分類器予測、そして元の予測と再構築された予測の両者を含む辞書を返します。幾つかの敵対的 (インスタンス) そして元のテストセットのインスタンスを含むバッチでこれを示しましょう :
n_test = X_test.shape[0]
np.random.seed(0)
idx_normal = np.random.choice(n_test, size=1600, replace=False)
idx_cw = np.random.choice(n_test, size=400, replace=False)
X_mix = np.concatenate([X_test[idx_normal], X_test_cw[idx_cw]])
y_mix = np.concatenate([y_test[idx_normal], y_test[idx_cw]])
print(X_mix.shape, y_mix.shape)
(2000, 32, 32, 3) (2000,)
モデル性能を確認しましょう :
y_pred_mix = predict_batch(clf, X_mix, batch_size=32, return_class=True)
acc_y_pred_mix = accuracy(y_mix, y_pred_mix)
print('Accuracy {:.4f}'.format(acc_y_pred_mix))
Accuracy 0.7380
これは訂正メカニズムで改良できます :
preds = ad.correct(X_mix, batch_size=32)
acc_y_corr_mix = accuracy(y_mix, preds['data']['corrected'])
print('Accuracy {:.4f}'.format(acc_y_corr_mix))
Accuracy 0.8205
論文 でハイライトされていて (temperature スケーリング と 隠れ層 K-L ダイバージェンス) Alibi Detect で実装されている幾つかの他のトリックがあります、これは敵対的検知器の性能を更にブーストできます。より詳細については この example ノートブック を確認してください。
以上