Alibi Detect 0.7 : Examples : マハラノビス外れ値検知 on KDD Cup ‘99 データセット (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 07/01/2021 (0.7.0)
* 本ページは、Alibi Detect の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。

スケジュールは弊社 公式 Web サイト でご確認頂けます。
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
| 人工知能研究開発支援 | 人工知能研修サービス | テレワーク & オンライン授業を支援 |
| PoC(概念実証)を失敗させないための支援 (本支援はセミナーに参加しアンケートに回答した方を対象としています。) | ||
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |
Alibi Detect 0.7 : Examples : マハラノビス外れ値検知 on KDD Cup ‘99 データセット
Mahalanobis 距離 – 概要
マハラノビス・オンライン外れ値検知器は表形式データの異常を予測することが目的です。アルゴリズムは外れ値スコアを計算します、これは特徴分布の中心からの距離の尺度です ( マハラノビス距離 )。外れ値スコアがユーザ定義された閾値より高い場合、観測は外れ値としてフラグ立てされます。このアルゴリズムはオンラインです、これはそれは特徴の分布についての知識なしに開始してリクエストが到着するにつれて学習することを意味しています。結果的に開始時には出力は悪くて時間につれて改良されることを想定するべきです。アルゴリズムは低次元から medium 次元の表形式データに適します。
アルゴリズムはまたカテゴリー (= categorical) 変数を含むこともできます。fit ステップは最初に各カテゴリー変数ののカテゴリー間の pairwise (ペア単位) な距離を計算します。pairwise な距離はモデル予測 (MVDM 法) か (データセットの他の変数により提供される) コンテキスト (ABDM 法) に基づきます。MVDM については、各カテゴリーの条件付きモデル予測確率間の差を使用します。この方法は Cost et al (1993) による Modified Value Difference Metric (MVDM) に基づいています。ABDM は Le et al (2005) により導入されたカテゴリー距離尺度、Association-Based Distance Metric を略しています。ABDM はデータの他の変数の存在からコンテキストを推論して Kullback-Leibler ダイバージェンス に基づいて非類似度 (= dissimilarity measure) を計算します。両者の方法はまた ABDM-MVDM としても結合できます。次に pairwaise 距離をユークリッド空間に射影するために多次元尺度構成法を適用することができます。
データセット
典型的な U.S. 空軍 LAN をシミュレートした LAN の TCP dump データを使用して、外れ値検知器はコンピュータ・ネットワーク侵入を検知する必要があります。コネクションは明確に定義された時間で開始して終了する TCP パケットのシークエンスで、その間にデータは明確に定義されたプロトコルのもとにソース IP とターゲット IP アドレス間で流れます。各コネクションは正常、また攻撃としてラベル付けされます。
データセットには 4 タイプの攻撃があります :
- DOS: denial-of-service, e.g. syn flood;
- R2L: 遠隔マシンからの権限のないアクセス、e.g. パスワードの推測 ;
- U2R: ローカルのスーパーユーザ (root) 特権への権限のないアクセス ;
- probing : 偵察と他の厳密な調査、e.g., ポートスキャン。
データセットは約 500 万のコネクション・レコードを含みます。
3 つのタイプの特徴があります :
- 個々のコネクションの基本的な特徴, e.g. 接続時間 (duration of connection)
- コネクション内のコンテンツ特徴, e.g. 失敗したログイン試行の数
- 2 秒 window 内の traffic 特徴, e.g. 現在の接続と同じホストへのコネクションの数
import matplotlib
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import os
import pandas as pd
import seaborn as sns
from sklearn.metrics import confusion_matrix, f1_score
from sklearn.preprocessing import OneHotEncoder, OrdinalEncoder
from alibi_detect.od import Mahalanobis
from alibi_detect.datasets import fetch_kdd
from alibi_detect.utils.data import create_outlier_batch
from alibi_detect.utils.fetching import fetch_detector
from alibi_detect.utils.mapping import ord2ohe
from alibi_detect.utils.saving import save_detector, load_detector
from alibi_detect.utils.visualize import plot_instance_score, plot_roc
データセットをロードする
幾つかの continuous (連続) な特徴 (41 の内から 18) だけを保持します。
kddcup = fetch_kdd(percent10=True) # only load 10% of the dataset
print(kddcup.data.shape, kddcup.target.shape)
Downloading https://ndownloader.figshare.com/files/5976042 (494021, 18) (494021,)
kddcup.data[0]
array([8, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 9, 9, 1.0, 0.0, 0.11, 0.0,
0.0, 0.0, 0.0, 0.0], dtype=object)
機械学習モデルはデータセットの (外れ値ではなく) 正常インスタンス上で訓練されて標準化 (= standardization) が適用されていると仮定します :
np.random.seed(0)
normal_batch = create_outlier_batch(kddcup.data, kddcup.target, n_samples=100000, perc_outlier=0)
X_train, y_train = normal_batch.data.astype('float'), normal_batch.target
print(X_train.shape, y_train.shape)
print('{}% outliers'.format(100 * y_train.mean()))
(100000, 18) (100000,) 0.0% outliers
mean, stdev = X_train.mean(axis=0), X_train.std(axis=0)
print(mean)
print(stdev)
[1.0863280e+01 1.5947000e-03 1.7106000e-03 5.5465500e-02 5.5817000e-02 9.8513050e-01 1.8421100e-02 1.3076270e-01 1.4877551e+02 2.0196858e+02 8.4458450e-01 5.6967800e-02 1.3428810e-01 2.4221900e-02 2.1705000e-03 1.0195000e-03 5.7662200e-02 5.5782900e-02] [2.14829720e+01 2.82363937e-02 2.58780186e-02 2.28045718e-01 2.26992983e-01 9.38338264e-02 1.16618987e-01 2.74664995e-01 1.03392977e+02 8.70459243e+01 3.06054628e-01 1.81221847e-01 2.81216847e-01 5.00195618e-02 3.05085878e-02 1.51537329e-02 2.24991224e-01 2.18815943e-01]
外れ値検知器をロードまたは定義する
examples ノートブックで使用される事前訓練済みの外れ値と敵対的検知器は ここ で見つかります。組込みの fetch_detector 関数を利用できます、これは事前訓練モデルをローカルディレクトリ filepath にセーブして検知器をロードします。代わりに、スクラッチから検知器を初期化できます。
マハラノビスはオンライン、stateful な外れ値検知器であることに注意してください。従ってマハラノビス検知器のセーブやロードはまた検知器の状態もセーブしてロードします。これはユーザに検知器を (それをプロダクションで配備する前に) ウォームアップすることを可能にします。
load_outlier_detector = False
filepath = 'my_path' # change to directory where model is downloaded
if load_outlier_detector: # load initialized outlier detector
detector_type = 'outlier'
dataset = 'kddcup'
detector_name = 'Mahalanobis'
od = fetch_detector(filepath, detector_type, dataset, detector_name)
filepath = os.path.join(filepath, detector_name)
else: # initialize and save outlier detector
threshold = None # scores above threshold are classified as outliers
n_components = 2 # nb of components used in PCA
std_clip = 3 # clip values used to compute mean and cov above "std_clip" standard deviations
start_clip = 20 # start clipping values after "start_clip" instances
od = Mahalanobis(threshold,
n_components=n_components,
std_clip=std_clip,
start_clip=start_clip)
save_detector(od, filepath) # save outlier detector
No threshold level set. Need to infer threshold using `infer_threshold`. Directory ./models does not exist and is now created.
!ls model_mahalanobis -l
total 8 -rw-rw-r-- 1 ubuntu ubuntu 182 7月 2 02:39 Mahalanobis.pickle -rw-rw-r-- 1 ubuntu ubuntu 100 7月 2 02:39 meta.pickle
load_outlier_detector が False に等しい場合、警告が outlier threshold (外れ値閾値) を依然として設定する必要があることを教えてくれます。これは infer_threshold メソッドで成されます。インスタンスのバッチを渡してそれらの何パーセントを正常であると考えるかを threshold_perc を通して指定する必要があります。およそ 5% の外れ値を含むことを知るあるデータを持つと仮定しましょう。外れ値のパーセンテージは create_outlier_batch 関数で perc_outlier で設定できます。
np.random.seed(0)
perc_outlier = 5
threshold_batch = create_outlier_batch(kddcup.data, kddcup.target, n_samples=1000, perc_outlier=perc_outlier)
X_threshold, y_threshold = threshold_batch.data.astype('float'), threshold_batch.target
X_threshold = (X_threshold - mean) / stdev
print('{}% outliers'.format(100 * y_threshold.mean()))
5.0% outliers
od.infer_threshold(X_threshold, threshold_perc=100-perc_outlier)
print('New threshold: {}'.format(od.threshold))
threshold = od.threshold
New threshold: 10.67093404671951
外れ値を検知する
今は 10% の外れ値を持つデータのバッチを生成し、それらを正常データ (inliers) から得られた mean と stdev で標準化し、そしてバッチ内の外れ値を検知します。
np.random.seed(1)
outlier_batch = create_outlier_batch(kddcup.data, kddcup.target, n_samples=1000, perc_outlier=10)
X_outlier, y_outlier = outlier_batch.data.astype('float'), outlier_batch.target
X_outlier = (X_outlier - mean) / stdev
print(X_outlier.shape, y_outlier.shape)
print('{}% outliers'.format(100 * y_outlier.mean()))
(1000, 18) (1000,) 10.0% outliers
外れ値を予測します :
od_preds = od.predict(X_outlier, return_instance_score=True)
type(od_preds)
dict
od_preds.keys()
dict_keys(['data', 'meta'])
od_preds['data'].keys()
dict_keys(['instance_score', 'feature_score', 'is_outlier'])
od_preds['data']['is_outlier'][:10]
array([0, 0, 0, 1, 0, 1, 1, 0, 0, 0])
od_preds['data']['instance_score'][:10]
array([2.03266359e-02, 4.37259911e-02, 1.22390634e-02, 2.31468094e+01,
1.23040377e-01, 1.66272606e+02, 2.29750258e+01, 6.61924348e-02,
1.30512869e-01, 1.21724158e-01])
od_preds['data']['feature_score']
(nothing displayed)
今ではウォームアップされた外れ値検知器をセーブできます :
save_detector(od, filepath)
!ls model_mahalanobis -l
total 8 -rw-rw-r-- 1 ubuntu ubuntu 3521 7月 2 02:50 Mahalanobis.pickle -rw-rw-r-- 1 ubuntu ubuntu 100 7月 2 02:50 meta.pickle
結果を表示する
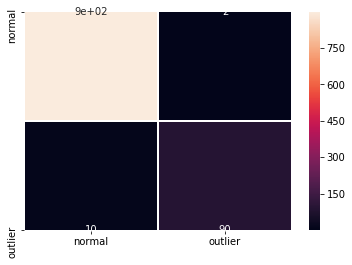
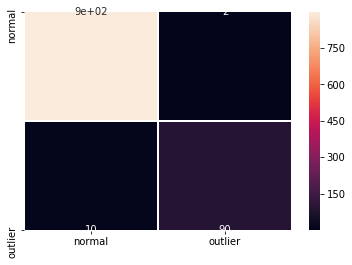
F1 スコアと混同行列 :
labels = outlier_batch.target_names
y_pred = od_preds['data']['is_outlier']
f1 = f1_score(y_outlier, y_pred)
print('F1 score: {}'.format(f1))
cm = confusion_matrix(y_outlier, y_pred)
df_cm = pd.DataFrame(cm, index=labels, columns=labels)
sns.heatmap(df_cm, annot=True, cbar=True, linewidths=.5)
plt.show()
F1 score: 0.9693877551020408

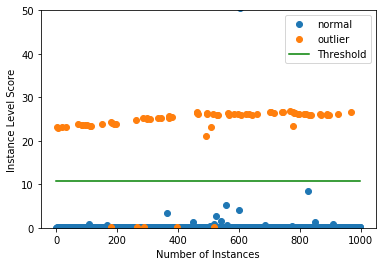
インスタンスレベルの外れ値スコア vs 外れ値閾値をプロットします :
plot_instance_score(od_preds, y_outlier, labels, od.threshold, ylim=(0,50))
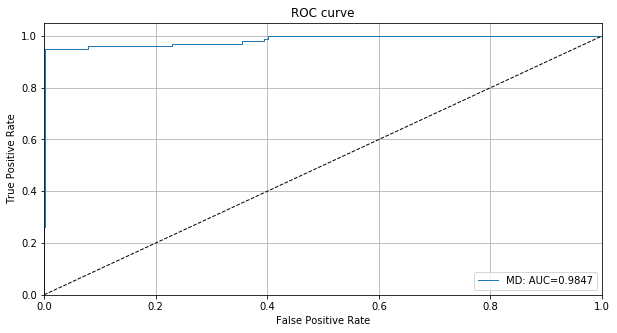
検知器の外れ値スコアのために ROC カーブをプロットできます :
roc_data = {'MD': {'scores': od_preds['data']['instance_score'], 'labels': y_outlier}}
plot_roc(roc_data)
カテゴリー変数を含める
ここまで連続変数だけを追跡しました。けれどもカテゴリー変数を含めることもできます。fit ステップは最初に各カテゴリー変数のカテゴリー間の pairwise 距離を計算します。pairwise 距離はモデル予測 (MVDM メソッド) かデータセットで他の変数により提供されるコンテキスト (ABDM メソッド) に基づいています。MVDM については、各カテゴリーの条件付きモデル予測確率間の差を使用します。この方法は Cost et al (1993) による Modified Value Difference Metric (MVDM) に基づいています。ABDM は Le et al (2005) により導入されたカテゴリー距離尺度、Association-Based Distance Metric を略しています。ABDM はデータの他の変数の存在からコンテキストを推論して Kullback-Leibler ダイバージェンスに基づいて非類似度 (= dissimilarity measure) を計算します。両者の方法はまた ABDM-MVDM としても結合できます。次に pairwaise 距離をユークリッド空間に射影するために多次元尺度構成法を適用することができます。
transform データをロードする
cat_cols = ['protocol_type', 'service', 'flag']
num_cols = ['srv_count', 'serror_rate', 'srv_serror_rate',
'rerror_rate', 'srv_rerror_rate', 'same_srv_rate',
'diff_srv_rate', 'srv_diff_host_rate', 'dst_host_count',
'dst_host_srv_count', 'dst_host_same_srv_rate',
'dst_host_diff_srv_rate', 'dst_host_same_src_port_rate',
'dst_host_srv_diff_host_rate', 'dst_host_serror_rate',
'dst_host_srv_serror_rate', 'dst_host_rerror_rate',
'dst_host_srv_rerror_rate']
cols = cat_cols + num_cols
np.random.seed(0)
kddcup = fetch_kdd(keep_cols=cols, percent10=True)
print(kddcup.data.shape, kddcup.target.shape)
(494021, 21) (494021,)
キーとしてカテゴリーカラムをそして値としてデータセットの各変数のためのカテゴリー数として辞書を作成します。この辞書は後で外れ値検知器の fit ステップで使用されます。
cat_vars_ord = {}
n_categories = len(cat_cols)
for i in range(n_categories):
cat_vars_ord[i] = len(np.unique(kddcup.data[:, i]))
print(cat_vars_ord)
{0: 3, 1: 66, 2: 11}
カテゴリーデータ上で ordinal エンコーダを適合します :
enc = OrdinalEncoder()
enc.fit(kddcup.data[:, :n_categories])
OrdinalEncoder(categories='auto', dtype=<class 'numpy.float64'>)
スケールされた数値と ordinal 特徴を組合せます。X_fit はカテゴリー特徴間の距離を推論するために後で使用されます。簡単にするために、後で検知される必要がある外れ値を含め、データセット全体を既に変換しています。これは説明のためです :
X_num = (kddcup.data[:, n_categories:] - mean) / stdev # standardize numerical features
X_ord = enc.transform(kddcup.data[:, :n_categories]) # apply ordinal encoding to categorical features
X_fit = np.c_[X_ord, X_num].astype(np.float32, copy=False) # combine numerical and categorical features
print(X_fit.shape)
(494021, 21)
検知器を初期化して適合させる
連続データのためのものと同じ閾値を使用します。これは最適なパフォーマンスという結果にはならないかもしれません。代わりに、閾値を再度推論することもできます。
n_components = 2
std_clip = 3
start_clip = 20
od = Mahalanobis(threshold,
n_components=n_components,
std_clip=std_clip,
start_clip=start_clip,
cat_vars=cat_vars_ord,
ohe=False) # True if one-hot encoding (OHE) is used
Set fit parameters:
d_type = 'abdm' # pairwise distance type, 'abdm' infers context from other variables
disc_perc = [25, 50, 75] # percentiles used to bin numerical values; used in 'abdm' calculations
standardize_cat_vars = True # standardize numerical values of categorical variables
カテゴリー変数のために数値を見つけるために fit メソッドを適用します :
od.fit(X_fit,
d_type=d_type,
disc_perc=disc_perc,
standardize_cat_vars=standardize_cat_vars)
カテゴリー特徴のための数値は属性 od.d_abs にストアされます。これはキーとしてカテゴリー特徴のためのカラムをそして値としてカテゴリーの数値と同値のものを持つ辞書です。
cat = 0 # categorical variable to plot numerical values for
plt.bar(np.arange(len(od.d_abs[cat])), od.d_abs[cat])
plt.xticks(np.arange(len(od.d_abs[cat])))
plt.title('Numerical values for categories in categorical variable {}'.format(cat))
plt.xlabel('Category')
plt.ylabel('Numerical value')
plt.show()

もう一つのオプションはモデルラベル (or 代わりに予測) からカテゴリー変数のための数値を推論するために d_type を ‘mvdm’ にそして y を kddcup.target に設定することです。
外れ値検知器を実行して結果を表示する
10% 外れ値を持つデータのバッチを生成します :
np.random.seed(1)
outlier_batch = create_outlier_batch(kddcup.data, kddcup.target, n_samples=1000, perc_outlier=10)
data, y_outlier = outlier_batch.data, outlier_batch.target
print(data.shape, y_outlier.shape)
print('{}% outliers'.format(100 * y_outlier.mean()))
(1000, 21) (1000,) 10.0% outliers
外れ値バッチを前処理します :
X_num = (data[:, n_categories:] - mean) / stdev
X_ord = enc.transform(data[:, :n_categories])
X_outlier = np.c_[X_ord, X_num].astype(np.float32, copy=False)
print(X_outlier.shape)
(1000, 21)
外れ値を予測します :
od_preds = od.predict(X_outlier, return_instance_score=True)
F1 スコアと混同行列 :
y_pred = od_preds['data']['is_outlier']
f1 = f1_score(y_outlier, y_pred)
print('F1 score: {}'.format(f1))
cm = confusion_matrix(y_outlier, y_pred)
df_cm = pd.DataFrame(cm, index=labels, columns=labels)
sns.heatmap(df_cm, annot=True, cbar=True, linewidths=.5)
plt.show()
F1 score: 0.9375
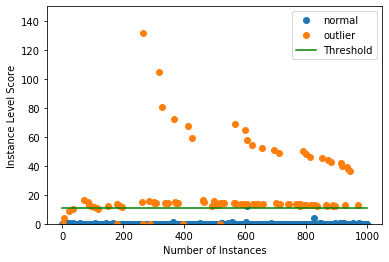
インスタンス・レベルで外れ値スコア vs 外れ値閾値をプロットします :
plot_instance_score(od_preds, y_outlier, labels, od.threshold, ylim=(0, 150))
カテゴリー変数のために ordinal エンコーディングの代わりに OHE を使用する
カテゴリー変数上 one-hot エンコーディング (OHE) を適用しますので、cat_vars_ord を ordinal から OHE 形式に変換します。alibi_detect.utils.mapping はこれを行なうためのユティリティ関数を含みます。cat_vars_ohe のキーは今では各 one-hot エンコードされたカテゴリー変数のための最初のカラム・インデックスを表します。この辞書は反事実の説明 (= counterfactual explanation) で後で使用されます。
cat_vars_ohe = ord2ohe(X_fit, cat_vars_ord)[1]
print(cat_vars_ohe)
{0: 3, 3: 66, 69: 11}
カテゴリーデータ上で one-hot エンコーダを適合させます :
enc = OneHotEncoder(categories='auto')
enc.fit(X_fit[:, :n_categories])
OneHotEncoder(categorical_features=None, categories='auto', drop=None,
dtype=<class 'numpy.float64'>, handle_unknown='error',
n_values=None, sparse=True)
X_fit を OHE に変換します :
X_ohe = enc.transform(X_fit[:, :n_categories])
X_fit = np.array(np.c_[X_ohe.todense(), X_fit[:, n_categories:]].astype(np.float32, copy=False))
print(X_fit.shape)
(494021, 98)
外れ値検知器を初期化して適合させる
Initialize:
od = Mahalanobis(threshold,
n_components=n_components,
std_clip=std_clip,
start_clip=start_clip,
cat_vars=cat_vars_ohe,
ohe=True)
fit メソッドを適用します :
od.fit(X_fit,
d_type=d_type,
disc_perc=disc_perc,
standardize_cat_vars=standardize_cat_vars)
外れ値検知器を実行して結果を表示する
外れ値バッチを OHE に変換します :
X_ohe = enc.transform(X_ord)
X_outlier = np.array(np.c_[X_ohe.todense(), X_num].astype(np.float32, copy=False))
print(X_outlier.shape)
(1000, 98)
外れ値を予測します :
od_preds = od.predict(X_outlier, return_instance_score=True)
F1 スコアと混同行列 :
y_pred = od_preds['data']['is_outlier']
f1 = f1_score(y_outlier, y_pred)
print('F1 score: {}'.format(f1))
cm = confusion_matrix(y_outlier, y_pred)
df_cm = pd.DataFrame(cm, index=labels, columns=labels)
sns.heatmap(df_cm, annot=True, cbar=True, linewidths=.5)
plt.show()
F1 score: 0.9375
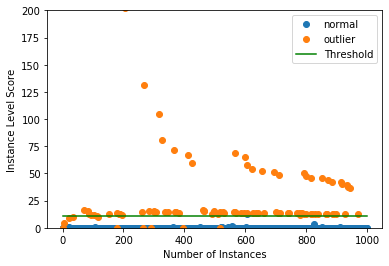
インスタンスレベルの外れ値スコア vs 外れ値の閾値をプロットします :
plot_instance_score(od_preds, y_outlier, labels, od.threshold, ylim=(0,200))
以上