Alibi Detect 0.7 : 概要 (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 06/30/2021 (0.7.0)
* 本ページは、Alibi Detect の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。

スケジュールは弊社 公式 Web サイト でご確認頂けます。
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
| 人工知能研究開発支援 | 人工知能研修サービス | テレワーク & オンライン授業を支援 |
| PoC(概念実証)を失敗させないための支援 (本支援はセミナーに参加しアンケートに回答した方を対象としています。) | ||
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |
Alibi Detect 0.7 : 概要
Alibi Detect は 外れ値、敵対的 そして ドリフト 検知にフォーカスしたオープンソース Python ライブラリです。このパッケージは表形式データ、テキスト、画像と時系列のためのオンラインとオフライン検知の両者をカバーすることが目的です。TensorFlow と PyTorch バックエンドの両者がドリフト検知のためにサポートされます。
プロダクション設定で外れ値と分布を監視する重要性の背景については、論文 Monitoring and explainability of models in production に基づく、Challenges in Deploying and Monitoring Machine Learning Systems ICML 2020 ワークショップからの このトーク をチェックしてください。
インストールと使用方法
alibi-detect は PyPI からインストールできます :
pip install alibi-detect
代わりに、開発バージョンをインストールすることもできます :
pip install git+https://github.com/SeldonIO/alibi-detect.git
Prophet 時系列外れ値検知器を利用するには :
pip install alibi-detect[prophet]
API を例示するために VAE 外れ値検知を使用します。
from alibi_detect.od import OutlierVAE
from alibi_detect.utils import save_detector, load_detector
# initialize and fit detector
od = OutlierVAE(threshold=0.1, encoder_net=encoder_net, decoder_net=decoder_net, latent_dim=1024)
od.fit(x_train)
# make predictions
preds = od.predict(x_test)
# save and load detectors
filepath = './my_detector/'
save_detector(od, filepath)
od = load_detector(filepath)
予測は meta と data をキーとする辞書で返されます。meta は検出器のメタデータを含む一方で、data は自身の内に実際の予測を持つ辞書です。それは外れ値、敵対的 or ドリフトスコアと閾値、更にはインスタンスが例えば外れ値であるか否かの予測を含みます。正確な詳細はメソッド間で僅かに異なる可能性がありますので、読者には サポートされるアルゴリズムのタイプ に精通することを勧めます。
Prophet 時系列外れ値検知器 のためのセーブとロード機能は現在 Python 3.6 で issue が起きていますが、Python 3.7 では動作します。
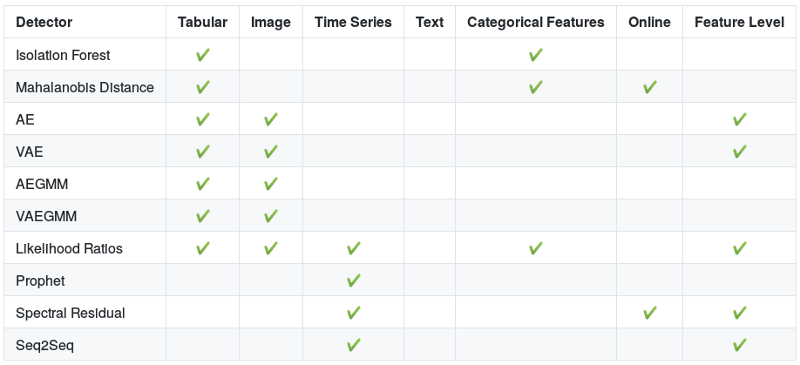
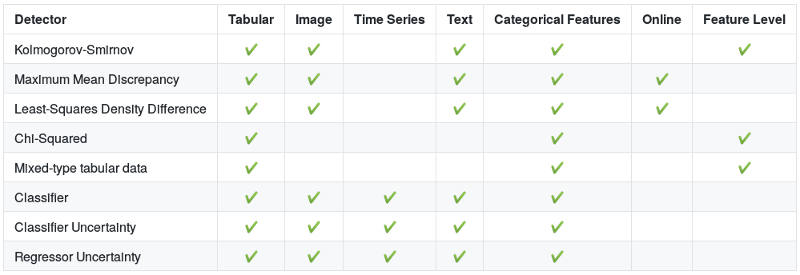
サポートされるアルゴリズム
次のテーブルは各アルゴリズムのための推奨ユースケースを示します。カラムの Feature Level (特徴レベル) は検出が特徴レベルで成されるか否かを示します、例えば画像に対してピクセル毎にです。より多くの情報についてはドキュメントと元の論文、そして各々の検出器のためのサンプルへのリンクを持つアルゴリズム参照リストを確認してください。
外れ値検知 (Outlier Detection)
敵対的検出

ドリフト検出
TensorFlow と PyTorch サポート
ドリフト検出器は TensorFlow と PyTorch バックエンドをサポートします。けれども Alibi Detect は PyTorch をインストールしません。これをどのように行なうかは PyTorch docs を確認してください。例えば :
from alibi_detect.cd import MMDDrift
cd = MMDDrift(x_ref, backend='tensorflow', p_val=.05)
preds = cd.predict(x)
PyTorch で同じ検出器 :
cd = MMDDrift(x_ref, backend='pytorch', p_val=.05)
preds = cd.predict(x)
組込みの前処理ステップ
Alibi Detect はまたランダムに初期化されたエンコーダ、transformers ライブラリを使用する際のドリフトを検出するための事前訓練済のテキスト埋め込み、そして機械学習モデルからの隠れ層の抽出のような様々な前処理ステップも装備しています。これは 共変量と予測された分布シフト のような様々なタイプのドリフトを検出することを可能にします。前処理ステップは再び TensorFlow と PyTorch でサポートされます。
from alibi_detect.cd.tensorflow import HiddenOutput, preprocess_drift
model = # TensorFlow model; tf.keras.Model or tf.keras.Sequential
preprocess_fn = partial(preprocess_drift, model=HiddenOutput(model, layer=-1), batch_size=128)
cd = MMDDrift(x_ref, backend='tensorflow', p_val=.05, preprocess_fn=preprocess_fn)
preds = cd.predict(x)
詳細については example ノートブック (e.g. CIFAR10, 映画レビュー) を確認してください。
参照リスト
外れ値検知
- Isolation Forest (FT Liu et al., 2008)
- サンプル: ネットワーク侵入
- マハラノビス距離 (Mahalanobis, 1936)
- サンプル: ネットワーク侵入
- Auto-Encoder (AE)
- サンプル: CIFAR10
- Variational Auto-Encoder (VAE) (Kingma et al., 2013)
- Auto-Encoding ガウス混合モデル (AEGMM) (Zong et al., 2018)
- サンプル: ネットワーク侵入
- 変分 Auto-Encoding ガウス混合モデル (VAEGMM)
- サンプル: ネットワーク侵入
- Likelihood Ratios (尤度比) (Ren et al., 2019)
- サンプル: Genome, Fashion-MNIST vs. MNIST
- Prophet 時系列外れ値検知 (Taylor et al., 2018)
- サンプル: 天気予報
- スペクトル残差 (Spectral Residual) 時系列外れ値検知 (Ren et al., 2019)
- サンプル: 合成データセット
- Sequence-to-Sequence (Seq2Seq) 外れ値検知 (Sutskever et al., 2014; Park et al., 2017)
敵対的検出
- Adversarial Auto-Encoder (Vacanti and Van Looveren, 2020)
- サンプル: CIFAR10
- Model distillation
- サンプル: CIFAR10
ドリフト検出
- Kolmogorov-Smirnov
- Least-Squares Density Difference (Bu et al, 2016)
- Maximum Mean Discrepancy (Gretton et al, 2012)
- Chi-Squared
- サンプル: Income 予測
- Mixed-type 表形式データ
- サンプル: Income 予測
- 分類器 (Lopez-Paz and Oquab, 2017)
- サンプル: CIFAR10
- 分類器と Regressor Uncertainty
- サンプル: CIFAR10 and Wine
- オンライン Maximum Mean Discrepancy
- サンプル: ワイン品質
- オンライン Least-Squares Density Difference (Bu et al, 2017)
- サンプル: ワイン品質
データセット
パッケージはまた様々な多様性のために多くのデータセットを簡単に取得できる alibi_detect.datasets の機能も含みます。各データセットについてデータとラベルか、データ、ラベルとオプションのメタデータを持つ Bunch オブジェクトが返されます。例えば :
from alibi_detect.datasets import fetch_ecg
(X_train, y_train), (X_test, y_test) = fetch_ecg(return_X_y=True)
シーケンシャル・データと時系列
- Genome データセット : fetch_genome
- 分布外分布検出のための尤度率 の一部としてリリースされた、分布外検出のための細菌ゲノム・データセット。オリジナルから TL;DR: データセットは訓練のために 10 in-distribution 細菌クラス、検証のために 60 OOD 細菌クラス、そしてテストのために別の 60 の異なる OOD 細菌クラスからの 250 塩基対のゲノム配列を含みます。訓練、検証とテストセット内にそれぞれ 1, 7 と再び 7 百万のシークエンスがあります。データセットの詳細については、README を確認してください。
from alibi_detect.datasets import fetch_genome (X_train, y_train), (X_val, y_val), (X_test, y_test) = fetch_genome(return_X_y=True)
- 分布外分布検出のための尤度率 の一部としてリリースされた、分布外検出のための細菌ゲノム・データセット。オリジナルから TL;DR: データセットは訓練のために 10 in-distribution 細菌クラス、検証のために 60 OOD 細菌クラス、そしてテストのために別の 60 の異なる OOD 細菌クラスからの 250 塩基対のゲノム配列を含みます。訓練、検証とテストセット内にそれぞれ 1, 7 と再び 7 百万のシークエンスがあります。データセットの詳細については、README を確認してください。
- ECG 5000: fetch_ecg
- Physionet から元は得られた、5000 ECG。
- NAB: fetch_nab
- Numenta 異常値ベンチマーク からの DataFrame 内の単変量時系列。利用可能な時系列を持つリストは alibi_detect.datasets.get_list_nab() を使用して取得できます。使用可能な時系列のリストは、alibi_detect.datasets.get_list_nab()を使用して取得できます。
画像
- CIFAR-10-C: fetch_cifar10c
- CIFAR-10-C (Hendrycks & Dietterich, 2019) は CIFAR-10 のテストセットを含みますが、異なるレベルの重大度 (= severity) で様々なタイプのノイズ、不鮮明さ (=blur)、輝度 etc. により破損 (= corrupted) そして摂動されていて、CIFAR-10 上で訓練された分類モデルのパフォーマンスの段階的な劣化に繋がります。fetch_cifar10c は任意の severity レベルや corruption タイプを選択することを可能にします。利用可能な corruption タイプを持つリストは alibi_detect.datasets.corruption_types_cifar10c() で取得できます。データセットは堅牢性とドリフトの研究で利用できます。元のデータは ここ で見つけられます。例えば :
from alibi_detect.datasets import fetch_cifar10c corruption = ['gaussian_noise', 'motion_blur', 'brightness', 'pixelate'] X, y = fetch_cifar10c(corruption=corruption, severity=5, return_X_y=True)
- CIFAR-10-C (Hendrycks & Dietterich, 2019) は CIFAR-10 のテストセットを含みますが、異なるレベルの重大度 (= severity) で様々なタイプのノイズ、不鮮明さ (=blur)、輝度 etc. により破損 (= corrupted) そして摂動されていて、CIFAR-10 上で訓練された分類モデルのパフォーマンスの段階的な劣化に繋がります。fetch_cifar10c は任意の severity レベルや corruption タイプを選択することを可能にします。利用可能な corruption タイプを持つリストは alibi_detect.datasets.corruption_types_cifar10c() で取得できます。データセットは堅牢性とドリフトの研究で利用できます。元のデータは ここ で見つけられます。例えば :
- 敵対的 CIFAR-10: fetch_attack
- CIFAR-10 で訓練された ResNet-56 分類器上の敵対的インスタンスをロードします。利用可能な攻撃 : Carlini-Wagner (‘cw’) と SLIDE (‘slide’)。例えば :
from alibi_detect.datasets import fetch_attack (X_train, y_train), (X_test, y_test) = fetch_attack('cifar10', 'resnet56', 'cw', return_X_y=True)
- CIFAR-10 で訓練された ResNet-56 分類器上の敵対的インスタンスをロードします。利用可能な攻撃 : Carlini-Wagner (‘cw’) と SLIDE (‘slide’)。例えば :
表形式
- KDD Cup ’99: fetch_kdd
- 様々なタイプのコンピュータ・ネットワーク侵入を伴うデータセット。fetch_kdd はネットワーク侵入のサブセットをターゲットとして選択したり特定の特徴だけを選択することを可能にします。元のデータは ここ で見つけられます。
モデル
外れ値、敵対的あるいはドリフト検出以外で有用であり得るモデル and/or ビルディング・ブロックは alibi_detect.models の下で見つかります。主要な実装は :
- PixelCNN++: alibi_detect.models.pixelcnn.PixelCNN
- 変分 Autoencoder: alibi_detect.models.autoencoder.VAE
- Sequence-to-sequence モデル: alibi_detect.models.autoencoder.Seq2Seq
- ResNet: alibi_detect.models.resnet
- CIFAR-10 上の事前訓練済み ResNet-20/32/44 モデルは Google Cloud Bucket 上で見つけることができて次のように取得できます :
from alibi_detect.utils.fetching import fetch_tf_model model = fetch_tf_model('cifar10', 'resnet32')
- CIFAR-10 上の事前訓練済み ResNet-20/32/44 モデルは Google Cloud Bucket 上で見つけることができて次のように取得できます :
統合
Alibi-detect はオープンソース機械学習モデル配備プラットフォーム Seldon Core とモデルサービング・フレームワーク KFServing に統合されています。
Citations
(訳注 : 原文 を参照してください。)
以上