PyOD 0.8 : Examples : Isolation Forest (解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 06/28/2021 (0.8.9)
* 本ページは、PyOD の以下のドキュメントとサンプルを参考にして作成しています:
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。

スケジュールは弊社 公式 Web サイト でご確認頂けます。
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
| 人工知能研究開発支援 | 人工知能研修サービス | テレワーク & オンライン授業を支援 |
| PoC(概念実証)を失敗させないための支援 (本支援はセミナーに参加しアンケートに回答した方を対象としています。) | ||
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |
PyOD 0.8 : Examples : Isolation Forest
完全なサンプル : examples/iforest_example.py
合成データの生成と可視化
pyod.utils.data.generate_data() でサンプルデータを生成します :
from pyod.utils.data import generate_data
contamination = 0.1 # percentage of outliers
n_train = 200 # number of training points
n_test = 100 # number of testing points
X_train, y_train, X_test, y_test = generate_data(
n_train=n_train, n_test=n_test,
n_features=2,
contamination=contamination,
random_state=42
)
X_train, y_train の shape と値を確認します :
print(X_train.shape)
print(y_train.shape)
(200, 2) (200,)
X_train[:10]
array([[6.43365854, 5.5091683 ],
[5.04469788, 7.70806466],
[5.92453568, 5.25921966],
[5.29399075, 5.67126197],
[5.61509076, 6.1309285 ],
[6.18590347, 6.09410578],
[7.16630941, 7.22719133],
[4.05470826, 6.48127032],
[5.79978164, 5.86930893],
[4.82256361, 7.18593123]])
y_train[:200]
array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.])
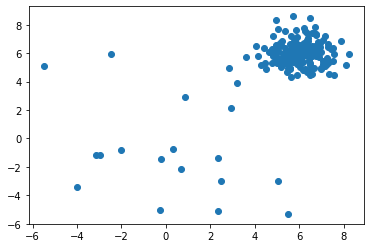
X_train の分布を可視化します :
import matplotlib.pyplot as plt
plt.scatter(X_train[:, 0], X_train[:, 1])
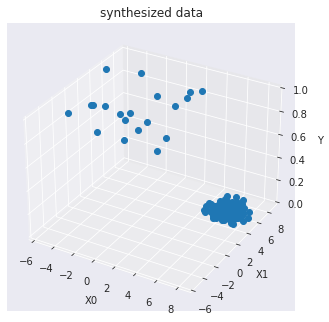
訓練データを可視化します :
import seaborn as sns
sns.set_style("dark")
from mpl_toolkits.mplot3d import Axes3D
X0 = X_train[:, 0]
X1 = X_train[:, 1]
Y = y_train
fig = plt.figure()
ax = Axes3D(fig)
ax.set_title("synthesized data")
ax.set_xlabel("X0")
ax.set_ylabel("X1")
ax.set_zlabel("Y")
ax.plot(X0, X1, Y, marker="o",linestyle='None')
モデル訓練
pyod.models.iforest.IForest 検出器をインポートして初期化し、そしてモデルを適合させます。
scikit-learn Isolation Forest のより多くの機能を持つラッパーです。
IsolationForest は、特徴をランダムに選択してから選択された特徴の最大値と最小値の間の分割値 (= split value) をランダムに選択することにより観測を「分離 (= isolate)」します。
参照 :
- Fei Tony Liu, Kai Ming Ting, and Zhi-Hua Zhou. Isolation forest. In Data Mining, 2008. ICDM’08. Eighth IEEE International Conference on, 413–422. IEEE, 2008.
- Fei Tony Liu, Kai Ming Ting, and Zhi-Hua Zhou. Isolation-based anomaly detection. ACM Transactions on Knowledge Discovery from Data (TKDD), 6(1):3, 2012.
再帰的分割 (= partitioning) は木構造で表されますので、サンプルを分離するために必要な分割の数はルートノードから終端ノードへのパスの長さに等しいです。
そのようなランダムツリーの森 (= forest) に渡り平均された、このパスの長さは正常性と決定関数の尺度です。
ランダム分割は異常値のためには著しく短いパスを生成します。そのため、ランダムツリーの森が特定のサンプルのために短いパスの長さを集合的に生成するとき、それらは異常である可能性が高くなります。
from pyod.models.iforest import IForest
clf_name = 'IForest'
clf = IForest()
clf.fit(X_train)
IForest(behaviour='old', bootstrap=False, contamination=0.1, max_features=1.0,
max_samples='auto', n_estimators=100, n_jobs=1, random_state=None,
verbose=0)
訓練データの予測ラベルと外れ値スコアを取得します :
y_train_pred = clf.labels_ # binary labels (0: inliers, 1: outliers)
y_train_scores = clf.decision_scores_ # raw outlier scores
y_train_pred
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1,
0, 1])
y_train_scores[-40:]
array([-0.1846575 , -0.17420279, -0.16454624, -0.18313387, 0.00184097,
-0.16721463, -0.20881165, -0.12698201, -0.20432723, -0.19229842,
-0.18207002, -0.10462056, -0.21048142, -0.17633758, -0.18314583,
-0.17556592, -0.17987594, -0.20584378, -0.19802026, -0.15455344,
0.03418722, 0.05486257, 0.06756084, 0.04571578, 0.07418781,
-0.01109817, 0.03804931, 0.05553404, 0.11342275, 0.03541737,
-0.06930148, 0.04314033, 0.20286855, 0.08323074, 0.09318281,
0.14768482, 0.13077218, 0.03692 , -0.03166733, 0.11722839])
予測と評価
先に正解ラベルを確認しておきます :
y_test
array([0., array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.])
テストデータ上で予測を行ないます :
y_test_pred = clf.predict(X_test) # outlier labels (0 or 1)
y_test_scores = clf.decision_function(X_test) # outlier scores
y_test_pred
aarray([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1])
y_test_scores[-40:]
array([-0.12997412, -0.20032257, -0.17450527, -0.17089002, -0.10767756,
-0.13952181, -0.01800938, -0.14394372, -0.07613799, -0.15948458,
-0.19488334, -0.14925167, -0.20239421, -0.09349558, -0.1980245 ,
-0.10904396, -0.19059866, -0.00824005, -0.20500567, -0.1781156 ,
-0.1023197 , -0.20947508, -0.19867088, -0.13209401, -0.11648015,
-0.02002286, -0.17712404, -0.0594405 , -0.20782814, -0.20041835,
0.0692155 , 0.08597497, 0.0822211 , 0.1060188 , -0.01362171,
0.00519536, 0.08507602, 0.11226714, 0.07143067, 0.07464685])
ROC と Precision @ Rank n pyod.utils.data.evaluate_print() を使用して予測を評価します。
from pyod.utils.data import evaluate_print
# evaluate and print the results
print("\nOn Training Data:")
evaluate_print(clf_name, y_train, y_train_scores)
print("\nOn Test Data:")
evaluate_print(clf_name, y_test, y_test_scores)
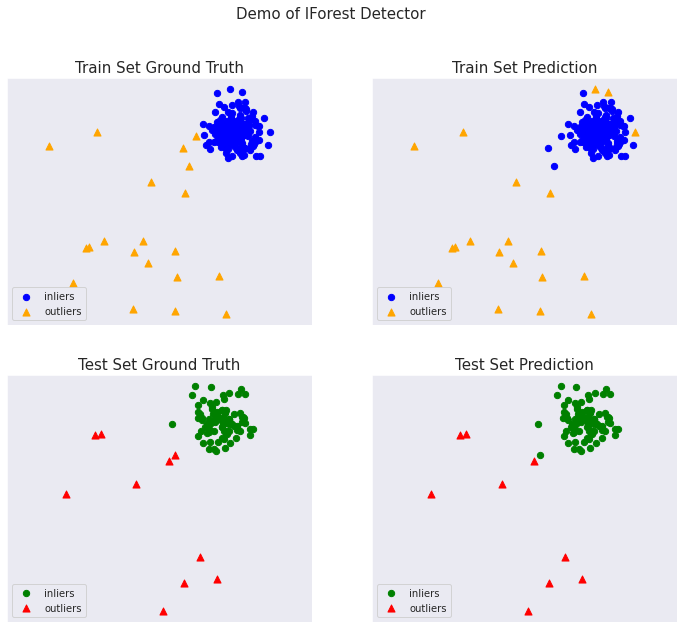
On Training Data: IForest ROC:0.9944, precision @ rank n:0.85 On Test Data: IForest ROC:0.9978, precision @ rank n:0.9
総ての examples に含まれる visualize 関数により可視化を生成します :
from pyod.utils.example import visualize
visualize(clf_name, X_train, y_train, X_test, y_test, y_train_pred,
y_test_pred, show_figure=True, save_figure=False)
以上