ADTK (異常検知ツールキット) 0.6 : クイックスタート (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 06/21/2021 (0.6.2)
* 本ページは、ADTK の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。
★ 無料 Web セミナー開催中 ★ クラスキャット主催 人工知能 & ビジネス Web セミナー

人工知能とビジネスをテーマに WEB セミナーを定期的に開催しています。
スケジュールは弊社 公式 Web サイト でご確認頂けます。
スケジュールは弊社 公式 Web サイト でご確認頂けます。
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
クラスキャットは人工知能・テレワークに関する各種サービスを提供しております :
| 人工知能研究開発支援 | 人工知能研修サービス | テレワーク & オンライン授業を支援 |
| PoC(概念実証)を失敗させないための支援 (本支援はセミナーに参加しアンケートに回答した方を対象としています。) | ||
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |
ADTK (異常検知ツールキット) 0.6 : クイックスタート
このサンプルでは、周期的な (= seasonal) (weekly and daily) 交通量パターンの違反 (= violation) を検知するモデルを構築します。ここで使用されるデータは Numenta Anomaly ベンチマーク からの NYC タクシー交通データセットです。
1. 訓練のために時系列をロードして検証します。
training.csv
Datetime,Traffic 2014-07-01 00:00:00,10844 2014-07-01 00:30:00,8127 2014-07-01 01:00:00,6210 2014-07-01 01:30:00,4656 2014-07-01 02:00:00,3820 ... 2015-01-04 09:30:00,9284 2015-01-04 10:00:00,10955 2015-01-04 10:30:00,13348 2015-01-04 11:00:00,13517 2015-01-04 11:30:00,14443
>>> import pandas as pd
>>> s_train = pd.read_csv("./training.csv", index_col="Datetime", parse_dates=True, squeeze=True)
>>> from adtk.data import validate_series
>>> s_train = validate_series(s_train)
>>> print(s_train)
Time
2014-07-01 00:00:00 10844
2014-07-01 00:30:00 8127
2014-07-01 01:00:00 6210
2014-07-01 01:30:00 4656
2014-07-01 02:00:00 3820
...
2015-01-04 09:30:00 9284
2015-01-04 10:00:00 10955
2015-01-04 10:30:00 13348
2015-01-04 11:00:00 13517
2015-01-04 11:30:00 14443
Freq: 30T, Name: Traffic, Length: 9000, dtype: int64
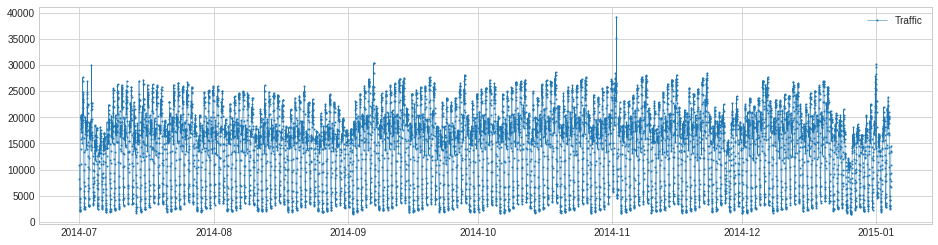
2. 訓練時系列を可視化する。
>>> from adtk.visualization import plot
>>> plot(s_train)
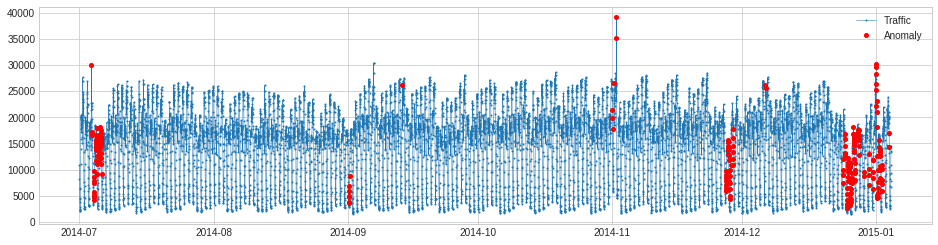
3. 周期パターンの violation を検知する。
>>> from adtk.detector import SeasonalAD
>>> seasonal_ad = SeasonalAD()
>>> anomalies = seasonal_ad.fit_detect(s_train)
>>> plot(s_train, anomaly=anomalies, anomaly_color="red", anomaly_tag="marker")
4. 既知の異常が利用可能であれば、検知結果と交差チェックします。
known_anomalies.csv
Datetime,Anomaly 2014-07-01 00:00:00,0 2014-07-01 00:30:00,0 2014-07-01 01:00:00,0 2014-07-01 01:30:00,0 2014-07-01 02:00:00,0 ... 2015-01-04 09:30:00,0 2015-01-04 10:00:00,0 2015-01-04 10:30:00,0 2015-01-04 11:00:00,0 2015-01-04 11:30:00,0
>>> known_anomalies = pd.read_csv("./known_anomalies.csv", index_col="Datetime", parse_dates=True, squeeze=True)
>>> from adtk.data import to_events
>>> known_anomalies = to_events(known_anomalies)
>>> print(known_anomalies)
[(Timestamp('2014-07-03 07:00:00', freq='30T'),
Timestamp('2014-07-06 14:59:59.999999999', freq='30T')),
(Timestamp('2014-08-31 18:30:00', freq='30T'),
Timestamp('2014-09-01 21:59:59.999999999', freq='30T')),
(Timestamp('2014-10-31 14:30:00', freq='30T'),
Timestamp('2014-11-02 13:59:59.999999999', freq='30T')),
(Timestamp('2014-11-26 19:00:00', freq='30T'),
Timestamp('2014-11-29 14:29:59.999999999', freq='30T')),
(Timestamp('2014-12-23 19:00:00', freq='30T'),
Timestamp('2014-12-28 13:59:59.999999999', freq='30T')),
(Timestamp('2014-12-28 19:30:00', freq='30T'),
Timestamp('2015-01-02 21:29:59.999999999', freq='30T'))]
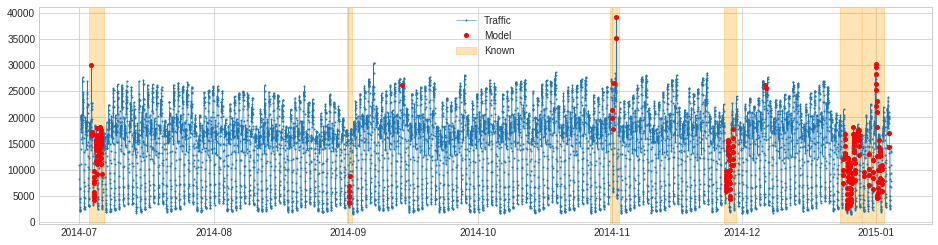
>>> plot(s_train,
anomaly={"Known": known_anomalies, "Model": anomalies},
anomaly_tag={"Known": "span", "Model": "marker"},
anomaly_color={"Known": "orange", "Model": "red"})
5. 新しいデータに訓練モデルを適用します。
>>> s_test = pd.read_csv("./testing.csv", index_col="Datetime", parse_dates=True, squeeze=True)
>>> s_test = validate_series(s_test)
>>> print(s_test)
Datetime
2015-01-04 12:00:00 15285
2015-01-04 12:30:00 16028
2015-01-04 13:00:00 16329
2015-01-04 13:30:00 15891
2015-01-04 14:00:00 15960
...
2015-01-31 21:30:00 24670
2015-01-31 22:00:00 25721
2015-01-31 22:30:00 27309
2015-01-31 23:00:00 26591
2015-01-31 23:30:00 26288
Freq: 30T, Name: Traffic, Length: 1320, dtype: int64
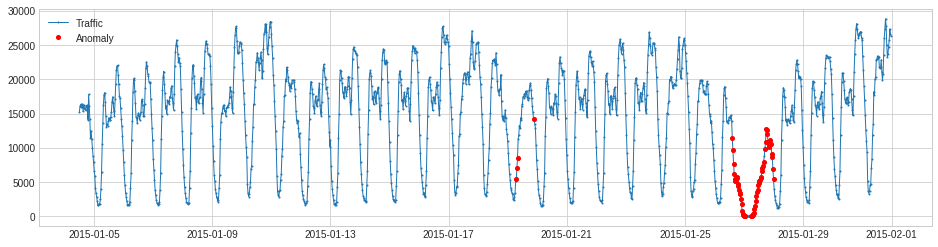
>>> anomalies_pred = seasonal_ad.detect(s_test)
>>> plot(s_test, anomaly=anomalies_pred,
ts_linewidth=1, anomaly_color='red', anomaly_tag="marker")
For more examples, please check Examples. But before that, we recommend you to read User Guide first.
以上