PyOD 0.8 : クイックスタート (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 06/25/2021 (0.8.9)
* 本ページは、PyOD の以下のドキュメントの一部を翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。

スケジュールは弊社 公式 Web サイト でご確認頂けます。
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
| 人工知能研究開発支援 | 人工知能研修サービス | テレワーク & オンライン授業を支援 |
| PoC(概念実証)を失敗させないための支援 (本支援はセミナーに参加しアンケートに回答した方を対象としています。) | ||
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |
PyOD 0.8 : クイックスタート
機能チュートリアル
PyOD は幾つかの特集された投稿とチュートリアルにより機械学習コミュニティにより良く認知されています。
- Analytics Vidhya : PyOD ライブラリを使用した Python で外れ値検知を学習する素晴らしいチュートリアル
- KDnuggets : 外れ値検知法の直観的可視化, PyOD からの外れ値検知法の概要
- Towards Data Science : ダミーのための異常検知
- Computer Vision News (March 2019) : 外れ値検知のための Python オープンソース・ツールボックス
- “examples/knn_example.py” は kNN 検出器を使用する基本的な API を実演します。総ての他のアルゴリズムに渡る API は一貫していて同様であることに注意してください。
外れ値検知のためのクイックスタート (kNN サンプル)
サンプルを実行するためのより詳細な手順は examples ディレクトリ で見つけられます。
Full example: knn_example.py
- モデルをインポートします。
from pyod.models.knn import KNN # kNN detector - pyod.utils.data.generate_data() でサンプルデータを生成します :
contamination = 0.1 # percentage of outliers n_train = 200 # number of training points n_test = 100 # number of testing points X_train, y_train, X_test, y_test = generate_data( n_train=n_train, n_test=n_test, contamination=contamination) - pyod.models.knn.KNN 検出器を初期化し、モデルを適合させ、そして予測を行ないます。
# train kNN detector clf_name = 'KNN' clf = KNN() clf.fit(X_train) # get the prediction labels and outlier scores of the training data y_train_pred = clf.labels_ # binary labels (0: inliers, 1: outliers) y_train_scores = clf.decision_scores_ # raw outlier scores # get the prediction on the test data y_test_pred = clf.predict(X_test) # outlier labels (0 or 1) y_test_scores = clf.decision_function(X_test) # outlier scores - ROC と Precision @ Rank n (p@n) によって予測を評価します pyod.utils.data.evaluate_print()。
from pyod.utils.data import evaluate_print # evaluate and print the results print("\nOn Training Data:") evaluate_print(clf_name, y_train, y_train_scores) print("\nOn Test Data:") evaluate_print(clf_name, y_test, y_test_scores) - 訓練とテストデータの両者でサンプル出力を見ます。
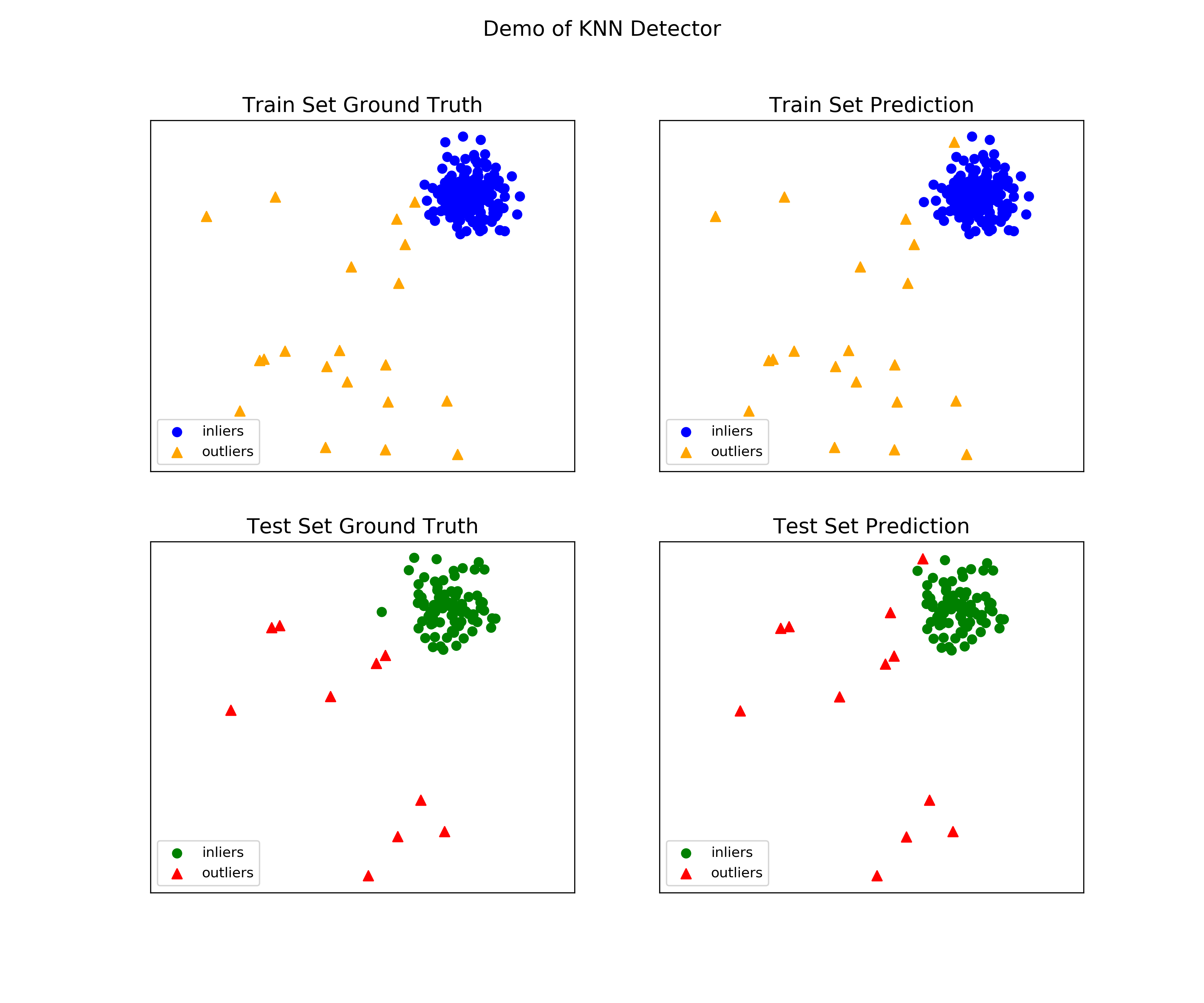
On Training Data: KNN ROC:1.0, precision @ rank n:1.0 On Test Data: KNN ROC:0.9989, precision @ rank n:0.9
- 総てのサンプルに含まれる visualize 関数により可視化を生成します。
visualize(clf_name, X_train, y_train, X_test, y_test, y_train_pred, y_test_pred, show_figure=True, save_figure=False)
可視化 (knn_figure) :
様々なベース検出器からの外れ値スコアを組み合わせるためのクイックスタート
外れ値検知は教師なしの性質のためにしばしばモデルの不安定性に悩まされます。そのため、様々な検出器出力を組み合わせることが勧められます、例えば、その堅牢性を改良するために平均を取ることによって。検出器の組合せは外れ値アンサンブルの部分領域です ; より多くの情報については Aggarwal, C.C. and Sathe, S., 2017. Outlier ensembles: An introduction. Springer を参照してください。
4 つのスコアの組合せメカニズムがこのデモで示されます :
- Average : 総ての検出器のスコアを平均する。
- maximization : 総ての検出器に渡る最大スコア。
- Average of Maximum (AOM) : ベース検出器をサブグループに分割して各サブグループの最大スコアを取ります。最終的なスコアは総てのサブグループのスコアの平均です。
- Maximum of Average (MOA) : ベース検出器をサブグループに分割して各サブグループの平均スコアを取ります。最終的なスコアは総てのサブグループの最大値です。
“examples/comb_example.py” は複数のベース検出器の出力を組み合わせるための API を示します (comb_example.py, Jupyter Notebooks)。
Jupyter Noteboks については、”/notebooks/Model Combination.ipynb” をナビゲートしてください。
- モデルをインポートしてサンプルデータを生成する。
from pyod.models.knn import KNN from pyod.models.combination import aom, moa, average, maximization from pyod.utils.data import generate_data X, y = generate_data(train_only=True) # load data - 最初に異なる k (10 から 200) で 20kNN 外れ値検出器を初期化し、そして外れ値スコアを得ます。
# initialize 20 base detectors for combination k_list = [10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 110, 120, 130, 140, 150, 160, 170, 180, 190, 200] train_scores = np.zeros([X_train.shape[0], n_clf]) test_scores = np.zeros([X_test.shape[0], n_clf]) for i in range(n_clf): k = k_list[i] clf = KNN(n_neighbors=k, method='largest') clf.fit(X_train_norm) train_scores[:, i] = clf.decision_scores_ test_scores[:, i] = clf.decision_function(X_test_norm) - 次に出力スコアは組み合わせる前にゼロ平均と単位分散に標準化されます。このステップは検出器出力を同じスケールに調整するために重要です。
from pyod.utils.utility import standardizer # scores have to be normalized before combination train_scores_norm, test_scores_norm = standardizer(train_scores, test_scores) - そして上記のような 4 つの異なる組合せアルゴリズムが適用されます。
comb_by_average = average(test_scores_norm) comb_by_maximization = maximization(test_scores_norm) comb_by_aom = aom(test_scores_norm, 5) # 5 groups comb_by_moa = moa(test_scores_norm, 5)) # 5 groups - 最後に、総ての 4 つの組合せ方法が ROC と Precision @ Rank n で評価されます。
Combining 20 kNN detectors Combination by Average ROC:0.9194, precision @ rank n:0.4531 Combination by Maximization ROC:0.9198, precision @ rank n:0.4688 Combination by AOM ROC:0.9257, precision @ rank n:0.4844 Combination by MOA ROC:0.9263, precision @ rank n:0.4688
以上