NeuralProphet 0.2 : ノートブック : 自己回帰 (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 07/19/2021 (Beta 0.2.7)
* 本ページは、NeuralProphet の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。

- 人工知能研究開発支援
- 人工知能研修サービス(経営者層向けオンサイト研修)
- テクニカルコンサルティングサービス
- 実証実験(プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
- PoC(概念実証)を失敗させないための支援
- テレワーク & オンライン授業を支援
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |
NeuralProphet 0.2 : ノートブック : 自己回帰
ここでは NeuralProphet を 5 分解像度のデータに適合させます (Yosemite の毎日の気温)。
if 'google.colab' in str(get_ipython()):
!pip install git+https://github.com/ourownstory/neural_prophet.git # may take a while
#!pip install neuralprophet # much faster, but may not have the latest upgrades/bugfixes
data_location = "https://raw.githubusercontent.com/ourownstory/neural_prophet/master/"
else:
data_location = "../"
import pandas as pd
from neuralprophet import NeuralProphet, set_log_level
# set_log_level("ERROR")
df = pd.read_csv(data_location + "example_data/yosemite_temps.csv")
df.head(3)
Next-step 予測
データとの最初のコンタクトに基づいて、以下を設定します :
- 最初に、weekly_seasonality を無効にします、自然は人間の週のカレンダーに従わないからです。
- 2 番目に、短期の予測を行なっていますので、n_changepoints を増やし、そして changepoints_range を増やします。
更に、明日の天気が昨日の天気と同様である可能性が高いという事実も利用できます。これは最も最近の過去の値で時系列を回帰することを意味し、自己回帰としても知られています。
n_lags を (それに渡り) 回帰させるための過去の観測値の望まれる数に設定することによりこれを実現できます。この値はまた ‘AR order’ としても知られます。
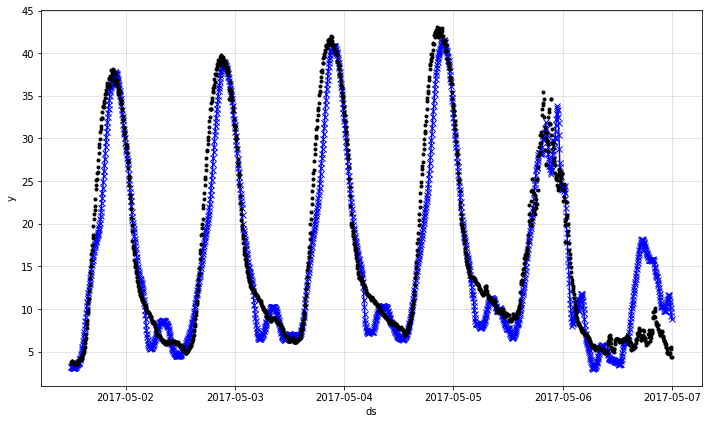
ここでは、最後の 1 時間に基づいて次の 5 分の気温を予測します :
m = NeuralProphet(
n_lags=12,
changepoints_range=0.95,
n_changepoints=30,
weekly_seasonality=False,
batch_size=64,
epochs=10,
learning_rate=1.0,
)
metrics = m.fit(df, freq='5min')
自己回帰コンポーネントを持つモデルは適合させることが困難な可能性があることに注意してください。ハイパーパラメータの自動選択は理想的な結果に繋がらないかもしれません。最善の結果のためには、(重要性の高い順に) これらを手動で変更することを考えてください。
- learning_rate
- epochs
- batch_size
自動的に設定されたハイパーパラメータ (‘INFO’ レベルログとしてプリント出力されます) は良い開始点として役立つことができます。
future = m.make_future_dataframe(df, n_historic_predictions=True)
forecast = m.predict(future)
fig = m.plot(forecast)
予測は今では非常に正確ですが、これは大きな驚きではありません、すぐ次の 5 分間を予測しているだけだからです。
モデルパラメータをプロットするとき、パネル ‘AR weight’ は 12 の最後の観測値に与えられた重みを表示します、これらは ‘AR coefficients’ として解釈できます :
# fig_comp = m.plot_components(forecast)
m = m.highlight_nth_step_ahead_of_each_forecast(1) # temporary workaround to plot actual AR weights
fig_param = m.plot_parameters()
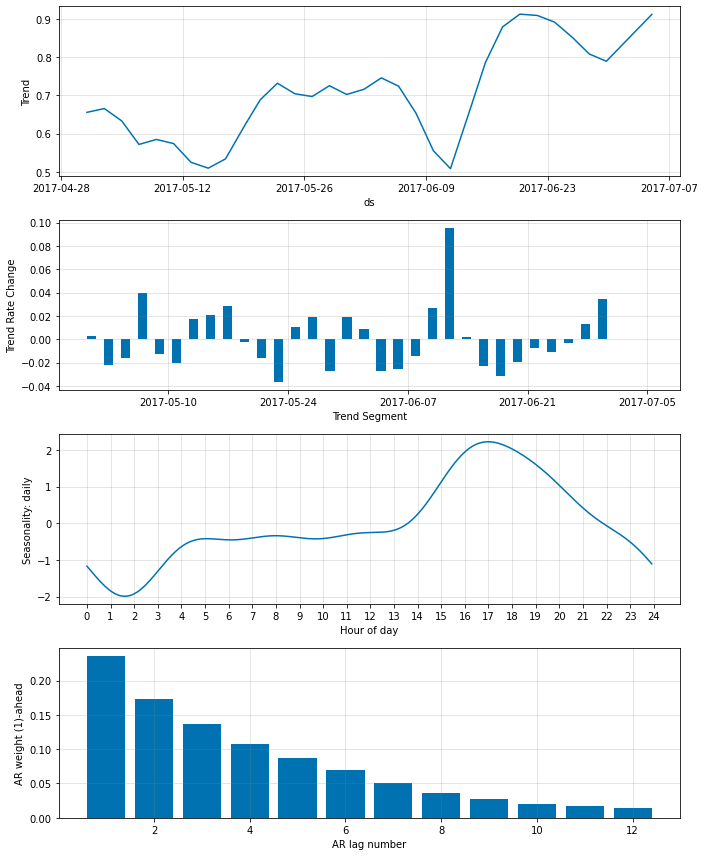
‘AR weight’ プロットは最も最近の観測はより離れた観測に比べてかなり多くの重みが与えられることを示しています。
マルチステップ予測
複数のステップを未来へ予測するためには、(一つの) ステップを前方に予測し、予測された値をデータに追加してから関心のある範囲に到達するまで次のステップを予測することによりシングルステップ・モデルを「展開」できます。けれども、これを行なうより良い方法があります : NeuralProphet で前方にマルチステップを直接予測できます。
n_forecasts を予測したいステップの望まれる数に設定できます (「予測区間」とも呼ばれます)。NeuralProphet は総ての単一ステップで、未来への n_forecasts ステップを予測します。従って、総ての履歴ポイントで n_forecasts の重なる予測を持ちます。
予測期間 n_forecasts を増やすとき、過去の観測 n_lags の数も少なくとも同じ値にまで増やすべきです。
ここでは、最後の観測 6 時間に基づいて次の 3 時間を 5 分ステップで予測します :
m = NeuralProphet(
n_lags=6*12,
n_forecasts=3*12,
changepoints_range=0.95,
n_changepoints=30,
weekly_seasonality=False,
batch_size=64,
epochs=10,
learning_rate=1.0,
)
metrics = m.fit(df, freq='5min')
future = m.make_future_dataframe(df, n_historic_predictions=True)
forecast = m.predict(future)
fig = m.plot(forecast)
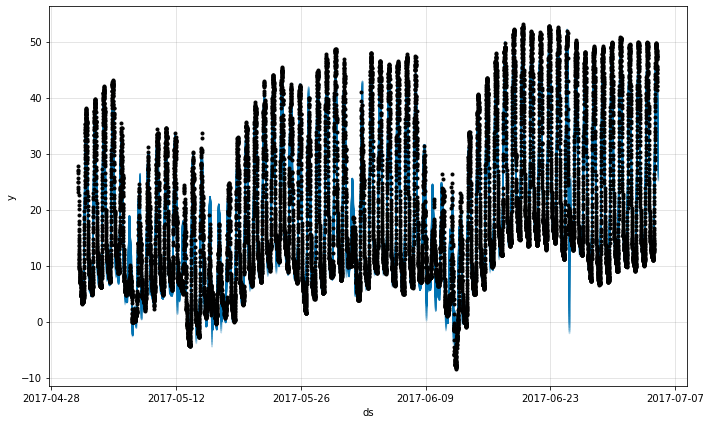
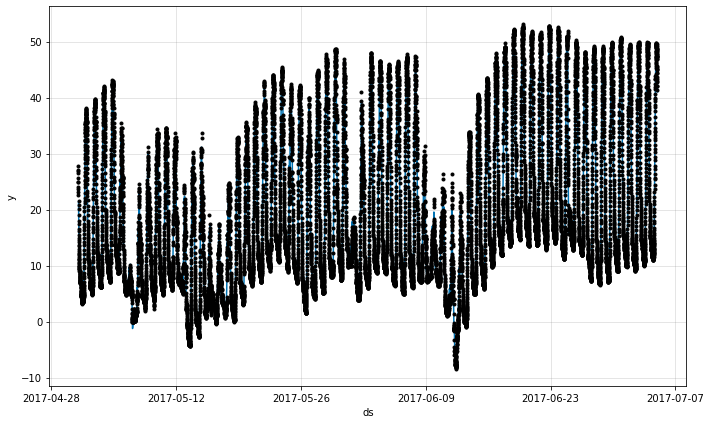
予測は時に一日のための予測を誤ってからより正確な予測に再度戻ることを見ます。データの 6 日目のその over-予測を詳しく見ましょう :
fig = m.plot(forecast[144:6*288])
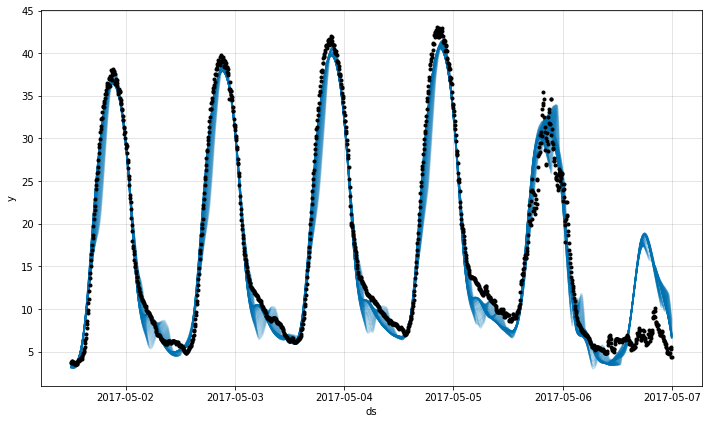
6 日目では、記録された気温は夜間に下がります。観測された低い夜間の気温に基づいて、モデルは低い日中のピークを予測します。けれども、実際の日中の気温は異常に低く、夜間よりもわずかに高くなっています。そのため、過大予測に繋がっています。
時間差 (= lag) の相対的な重要性を再度視覚化できます :
# fig_comp = m.plot_components(forecast)
fig_param = m.plot_parameters()
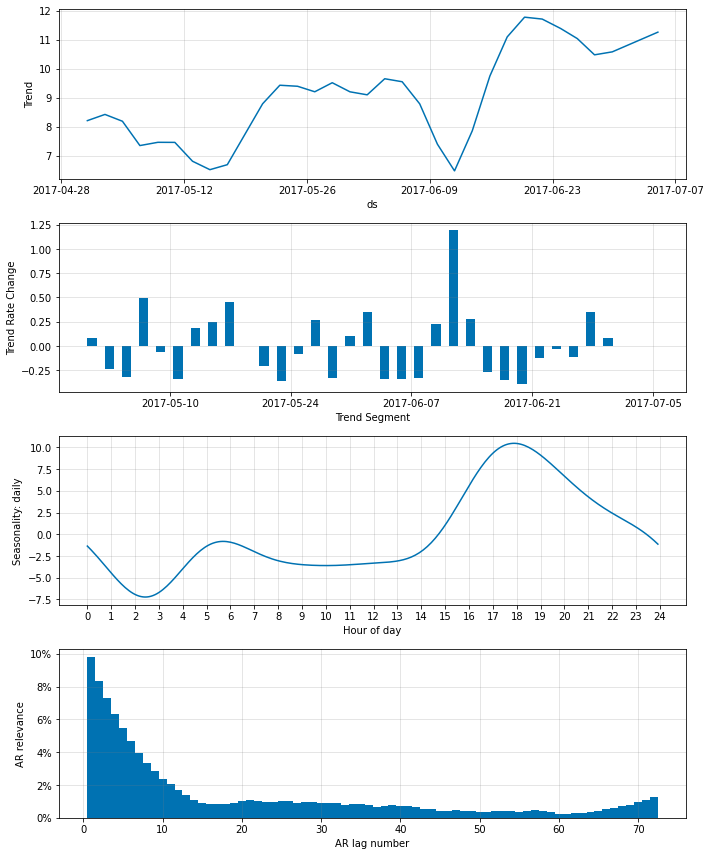
‘AR relevance’ は総ての n_forecasts に渡り平均化された、lag の相対的重要性であることに注意してください。
特定の予測ステップをレビューする
各予測の n-th ステップを強調することにより特定の予測期間を詳しく見ることができます。ここでは 3 時間先に予測される気温にフォーカスします (未来への最も離れた予測)。異なる 3 時間先の予測のための重みを詳しく見ましょう :
m = m.highlight_nth_step_ahead_of_each_forecast(3*12)
fig_param = m.plot_parameters()
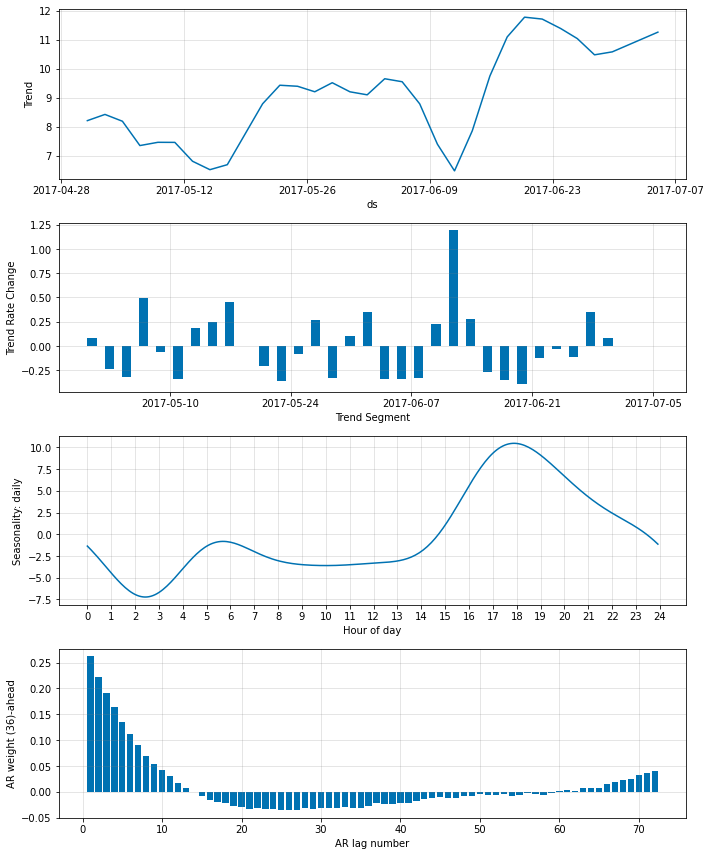
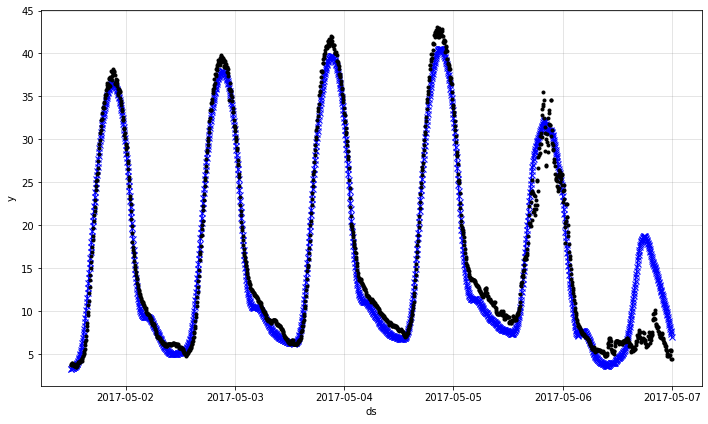
次に、最初の 6 日間を再プロットしてそれを 1 ステップ先の予測と比較します。単一ステップ先の予測が 3 時間先の予測と比較して遥かに正確であることを観測します。けれども、いずれも 6 日目の異常を予測することはできません。
fig = m.plot(forecast[144:6*288])
m = m.highlight_nth_step_ahead_of_each_forecast(1)
fig = m.plot(forecast[144:6*288])
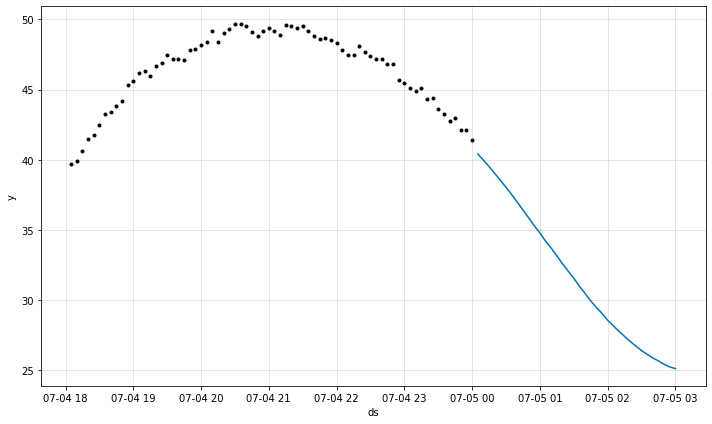
最近の予測をプロットする
モデル適合よりも実際の推測により関心があるとき、最も最近の推測をプロットできます :
m = m.highlight_nth_step_ahead_of_each_forecast(None) # reset highlight
fig = m.plot_last_forecast(forecast)
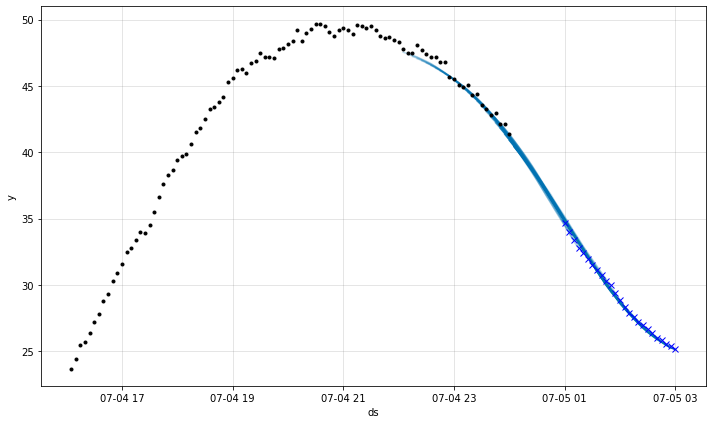
時間につれて予測がどのように変化したかを評価するために最後の幾つかの履歴予測が含められます。ここでは、最後の 2 時間に渡り与えられたとき、3 時間先の予測にフォーカスします。
m = m.highlight_nth_step_ahead_of_each_forecast(3*12)
fig = m.plot_last_forecast(forecast, include_previous_forecasts=2*12)
より大きな予測期間
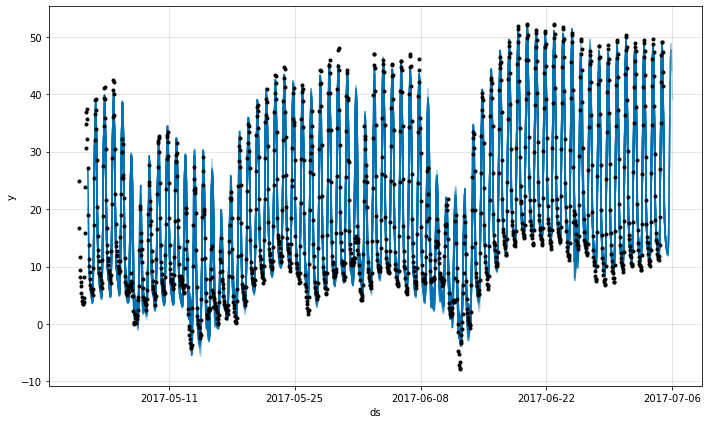
未来への更なる予測について、データの解像度を減じることができます。5 分解像度の使用は高解像度短期予測のために有用かもしれませんが、長期予測のためには逆効果かもしれません。データの制限された総量 (約 2 ヶ月) を持つだけですので、モデルを過剰に指定することは回避することを望みます。
例として : 最後の日の気温 (n_lags=24*12) に基づいて未来への 24 時間 (nforecasts=24*12) を予測するように設定する場合、AR コンポーネントのパラメータ数は 24*12*24*12 = 82,944 に増大します。けれども、データセットにおよそ 2*30*24*12 = 17,280 サンプルを持つだけです。モデルは過剰指定されます。
最初にデータを hourly データにダウンサンプリングする場合、データセットを 2*30*24=1440 に、そしてモデルパラメータを 24*24=576 に減じます。こうして、モデルに適合させられます。けれども、より多くのデータを集めることがより良いです。
df.loc[:, "ds"] = pd.to_datetime(df.loc[:, "ds"])
df_hourly = df.set_index('ds', drop=False).resample('H').mean().reset_index()
len(df_hourly)
1561
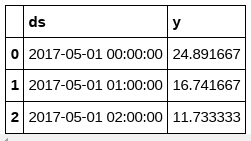
df_hourly.head(3)
m = NeuralProphet(
n_lags=24,
n_forecasts=24,
changepoints_range=0.95,
n_changepoints=30,
weekly_seasonality=False,
learning_rate=0.3,
)
metrics = m.fit(df_hourly, freq='H')
future = m.make_future_dataframe(df_hourly, n_historic_predictions=True)
forecast = m.predict(future)
fig = m.plot(forecast)
# fig_param = m.plot_parameters()
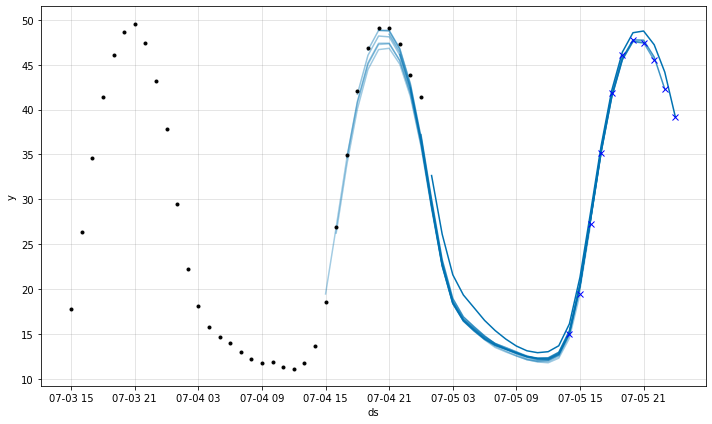
最後に、最も最近のそして最後の 10 履歴の 24 時間予測をプロットし、24-th 時間先を ‘x’ でマークします。
m = m.highlight_nth_step_ahead_of_each_forecast(24)
fig = m.plot_last_forecast(forecast, include_previous_forecasts=10)
以上