NeuralProphet 0.2 : クイックスタート (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 07/17/2021 (Beta 0.2.7)
* 本ページは、NeuralProphet の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。

スケジュールは弊社 公式 Web サイト でご確認頂けます。
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
| 人工知能研究開発支援 | 人工知能研修サービス | テレワーク & オンライン授業を支援 |
| PoC(概念実証)を失敗させないための支援 (本支援はセミナーに参加しアンケートに回答した方を対象としています。) | ||
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |
NeuralProphet 0.2 : クイックスタート
このページは最小限の機能で NeuralProphet を使用して単純なモデルを構築する方法の詳細を含みます。
インストール
(git clone 経由で) コードレポジトリをダウンロードした後、レポジトリ・ディレクトリに移動して (cd neural_prophet) そして “pip install .” で python パッケージとして neuralprophet をインストールします。
Note : Jupyter ノートブックでパッケージを使用するつもりであれば、”pip install .[live]” で ‘live’ パッケージ・バージョンをインストールすることを勧めます。これは訓練 (と検証) 損失のライブ・プロットを取得するために train 関数で plot_live_loss を有効にすることを可能にします。
インポート
今ではコードで NeuralProphet を使用できます :
from neuralprophet import NeuralProphet
入力データ
neural_prophet パッケージにより想定される入力データ形式は元の prophet と同じです。それは 2 つのカラムを持つべきで、タイムスタンプを持つ ds と時系列の観測値を含む y カラムです。このドキュメントを通して、Peyton Manning Wikipedia ページのログ daily ページビューの時系列データを使用しています。データは次のようにインポートできます。
import pandas as pd
df = pd.read_csv('../example_data/example_wp_log_peyton_manning.csv')
データの形式は下のように見えます :
| ds | y |
| 2007-12-10 | 9.59 |
| 2007-12-11 | 8.52 |
| 2007-12-12 | 8.18 |
| 2007-12-13 | 8.07 |
| 2007-12-14 | 7.89 |
単純なモデル
このデータセットのための neural_prophet を使用する単純なモデルは次のように NeuralProphet クラスのオブジェクトを作成して fit 関数を呼び出すことで適合できます。これはモデルのデフォルト設定でモデルを適合します。これらのデフォルト設定の詳細については、ハイパーパラメータの選択 のセクションを参照してください。
m = NeuralProphet()
metrics = m.fit(df, freq="D")
モデルがひとたび最適化されれば、最適化されたモデルを使用して予測を行なうことができます。このため、そのために予測する必要がある未来への時間ステップから成る未来のデータフレームを最初に作成する必要があります。NeuralProphet はこの目的のためにヘルパー関数 make_future_dataframe を提供します。データの頻度はここでグローバルに設定されることに注意してください。妥当な時系列頻度設定は pandas 時系列オフセット・エイリアス です。
future = m.make_future_dataframe(df, periods=365)
forecast = m.predict(future)
プロット
モデルから得られた予測を使用して、それらを視覚化できます。
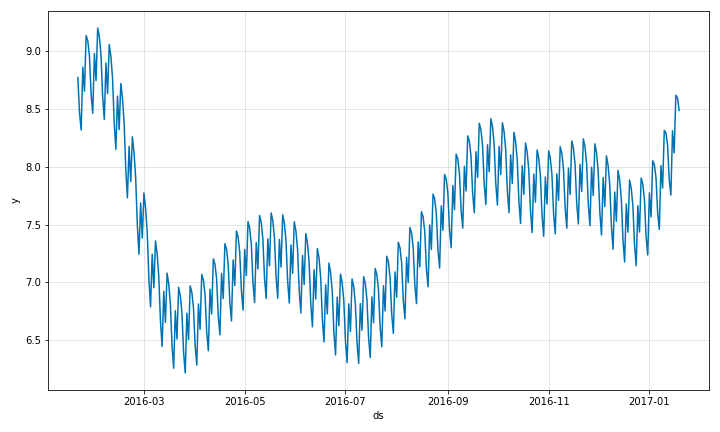
forecasts_plot = m.plot(forecast)
これはデフォルトで推定されたトレンド、weekly 季節性と yearly 季節性を持つ単純なモデルです。下のように個々の成分を別々に見ることもできます。
fig_comp = m.plot_components(forecast)
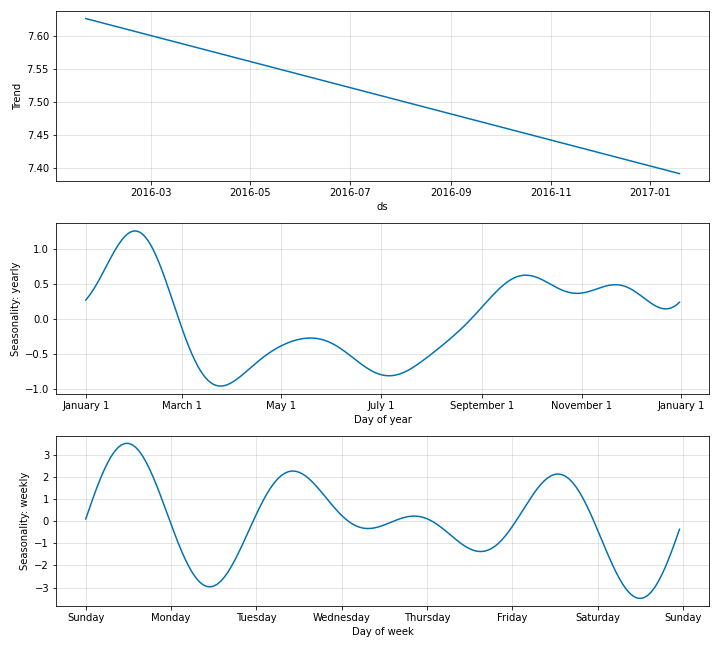
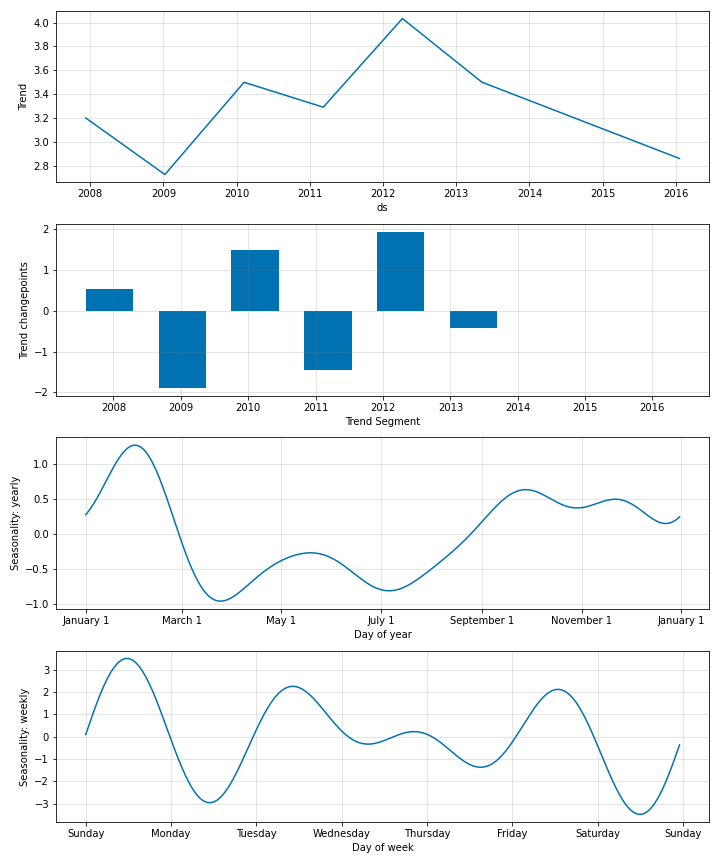
個々の係数値は更なる洞察を得るために下のようにプロットすることもできます。
fig_param = m.plot_parameters()
検証
NeuralProphet のモデル検証は 2 つの方法で成されます。ユーザは引数 valida_p で検証のために使用されるデータの割合を指定することにより以下のようにモデル適合の後検証するために手動でデータセットを分割できます。この検証セットは系列の最後から取っておかれます。
m = NeuralProphet()
df_train, df_val = m.split_df(df, valid_p=0.2)
今は以下のように訓練と検証メトリクスを別々に見ることができます。
train_metrics = m.fit(df_train)
val_metrics = m.test(df_val)
モデル適合の間に総てのエポック毎に検証を遂行することもできます。これは以下のように fit 関数呼び出しで validate_each_epoch 引数を設定することにより成されます。これはモデル訓練の間に貴方に検証メトリックを見させます。
# or evaluate while training
m = NeuralProphet()
metrics = m.fit(df, validate_each_epoch=True, valid_p=0.2)
再現性
結果の変動性は異なる実行の異なる最適条件を見つける SGD に由来します。ランダム性の大半は重みのランダム初期化、異なる学習率とデータローダの異なるシャッフリングに由来します。そのシードを設定することでランダム数 generator を制御できます :
from neuralprophet import set_random_seed
set_random_seed(0)
これはモデルを実行するたびに同一の結果に繋がるはずです。モデルを適合する前にランダム・シードを毎回同じランダム数に明示的に設定しなければならないことに注意してください。
以上